本文转载自:https://blog.csdn.net/qq_32865355/article/details/80260212
Instructions:
Backpropagation is usually the hardest (most mathematical) part in deep learning. To help you, here again is the slide from the lecture on backpropagation. You’ll want to use the six equations on the right of this slide, since you are building a vectorized implementation.

- Tips:
- To compute dZ1 you’ll need to compute
. Since
is the tanh activation function, if
then
. So you can compute
using(1 - np.power(A1, 2)).
- To compute dZ1 you’ll need to compute
. Since
is the tanh activation function, if
then
. So you can compute
1 反向传播算法和BP网络简介
误差反向传播算法简称反向传播算法(即BP算法)。使用反向传播算法的多层感知器又称为BP神经网络。BP算法是一个迭代算法,它的基本思想为:(1)先计算每一层的状态和激活值,直到最后一层(即信号是前向传播的);(2)计算每一层的误差,误差的计算过程是从最后一层向前推进的(这就是反向传播算法名字的由来);(3)更新参数(目标是误差变小)。迭代前面两个步骤,直到满足停止准则(比如相邻两次迭代的误差的差别很小)。
本文的记号说明:

下面以三层感知器(即只含有一个隐藏层的多层感知器)为例介绍“反向传播算法(BP 算法)”。
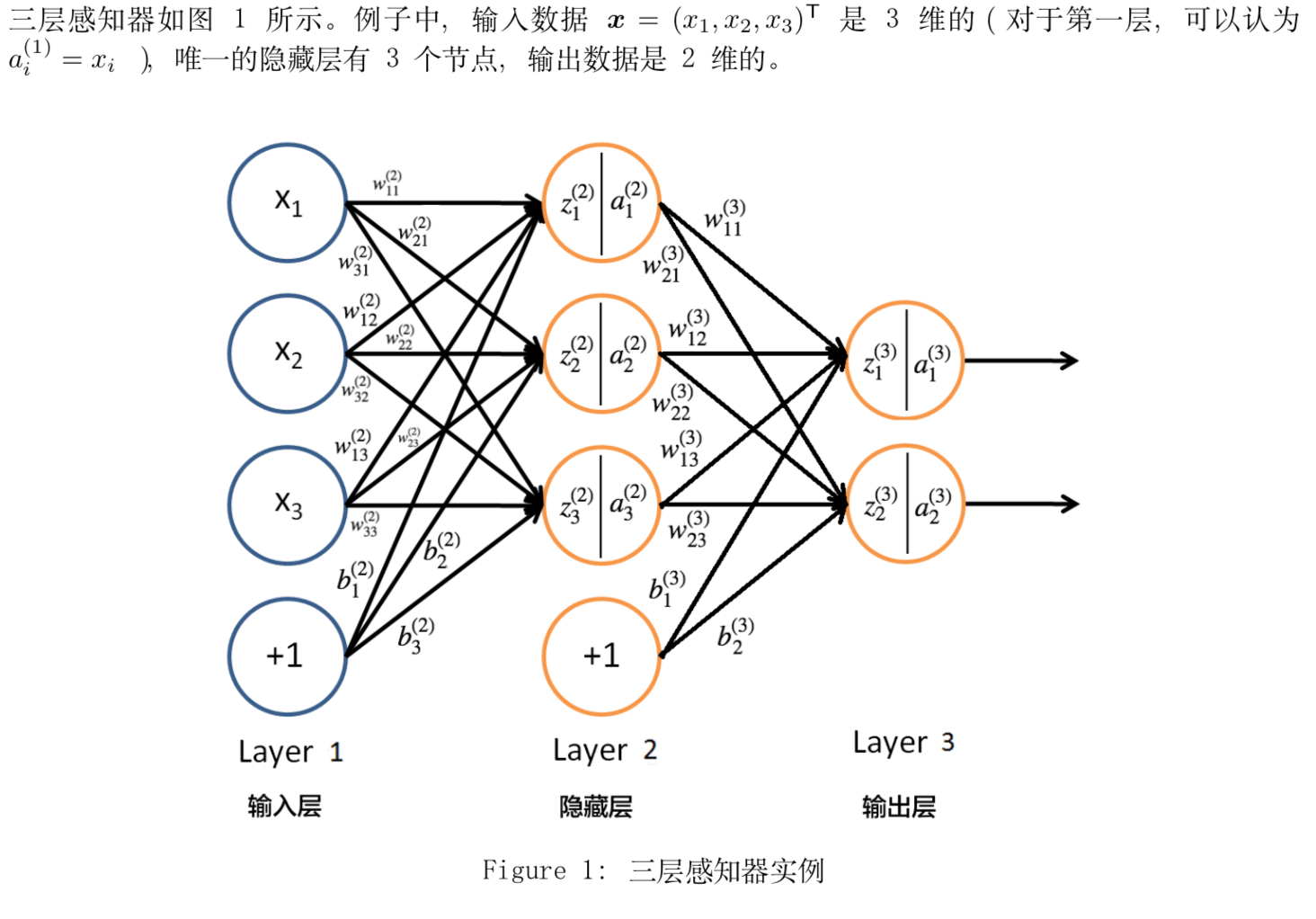
2 信息前向传播

3 误差反向传播



3.1 输出层的权重参数更新



3.2 隐藏层的权重参数更新


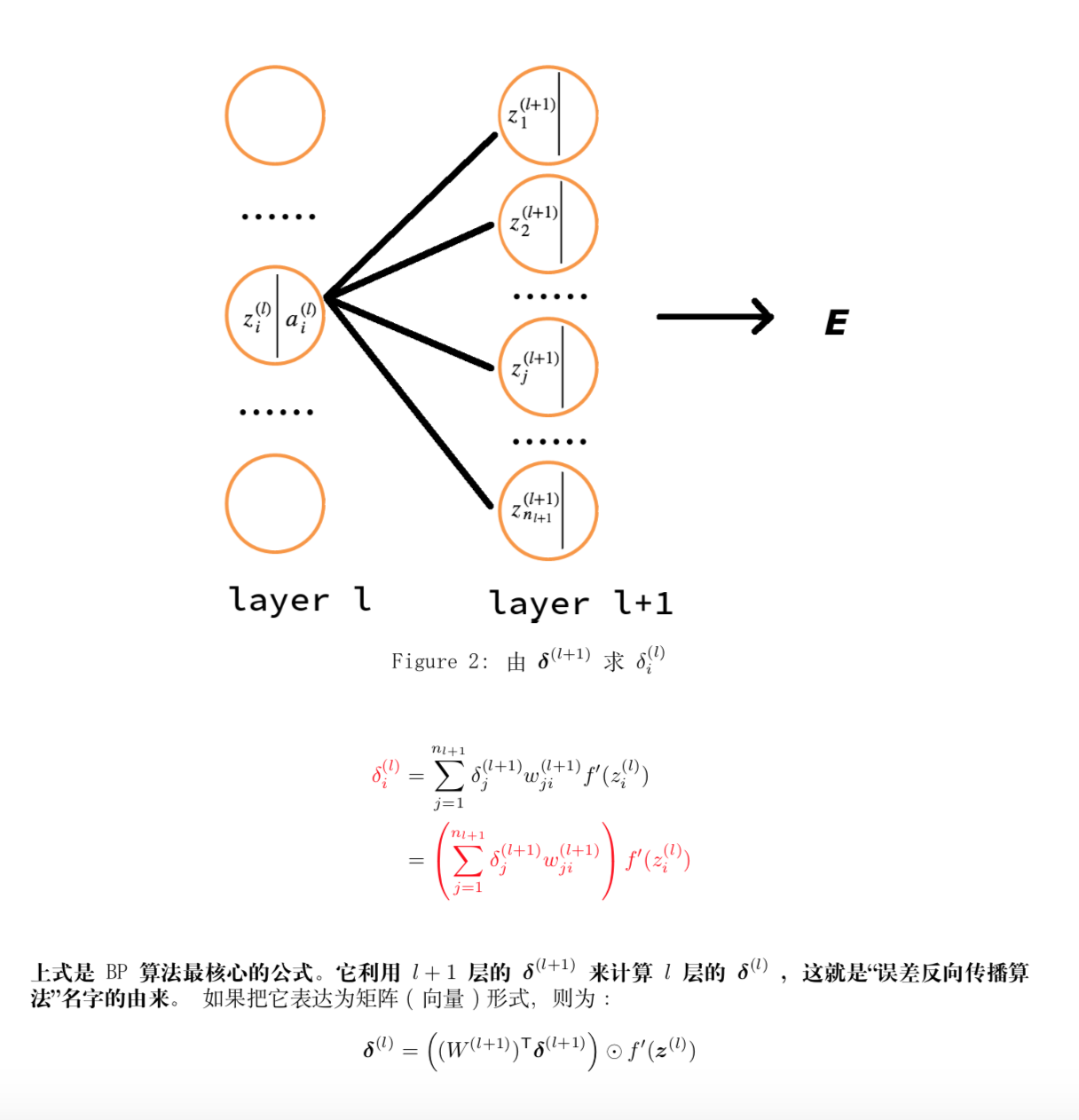
3.3输出层和隐藏层的偏置参数更新
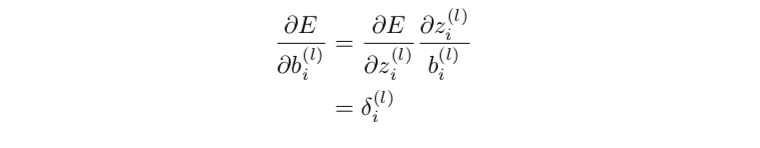
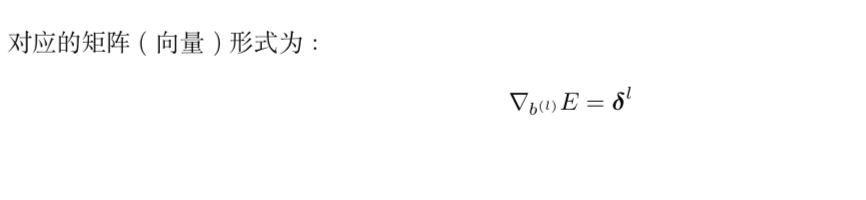
3.4 BP算法四个核心公式

3.5 BP 算法计算某个训练数据的代价函数对参数的偏导数



3.6 BP 算法总结:用“批量梯度下降”算法更新参数


4 梯度消失问题及其解决办法

5 加快 BP 网络训练速度:Rprop 算法

1 反向传播算法和BP网络简介
误差反向传播算法简称反向传播算法(即BP算法)。使用反向传播算法的多层感知器又称为BP神经网络。BP算法是一个迭代算法,它的基本思想为:(1)先计算每一层的状态和激活值,直到最后一层(即信号是前向传播的);(2)计算每一层的误差,误差的计算过程是从最后一层向前推进的(这就是反向传播算法名字的由来);(3)更新参数(目标是误差变小)。迭代前面两个步骤,直到满足停止准则(比如相邻两次迭代的误差的差别很小)。
本文的记号说明:
下面以三层感知器(即只含有一个隐藏层的多层感知器)为例介绍“反向传播算法(BP 算法)”。
2 信息前向传播
3 误差反向传播
3.1 输出层的权重参数更新
3.2 隐藏层的权重参数更新
3.3输出层和隐藏层的偏置参数更新
3.4 BP算法四个核心公式
3.5 BP 算法计算某个训练数据的代价函数对参数的偏导数
3.6 BP 算法总结:用“批量梯度下降”算法更新参数
4 梯度消失问题及其解决办法
5 加快 BP 网络训练速度:Rprop 算法