0. 前言
上篇文章 通过一个实际的例子说明了神经网络正向传播以及反向传播是如何实现的,以及这个计算的过程是怎么来的,下面想通过代码来实现这个过程 !
1. 代码实现神经网络BP算法
1.1 网络结构
这里的网络结构和相关的数据还是采用上一节中举的例子:
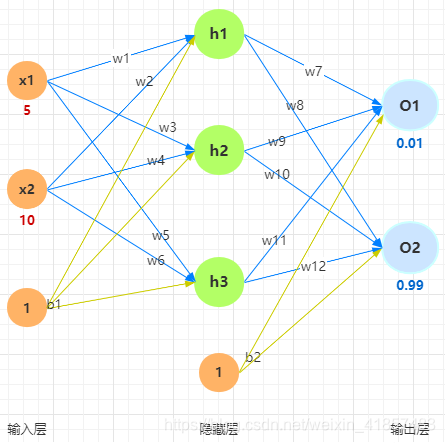
1.2 代码实现
- 数据准备
import numpy as np
# 权重
w = [0, 0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4, 0.45, 0.5, 0.55, 0.6, 0.65]
# 偏移
b = [0, 0.35, 0.65]
# 输入数据
x = [0, 5, 10]
# 实际输出
real_o1 = 0.01
real_o2 = 0.99
由于在上边的网络结构的图中, w 、 b w、b w、b 和 x x x 的下标都是从1开始的,但在数组中下标是从0开始的,所以这里就把数组中的第0项都设置为0.
- 激活函数
激活函数还是选择使用sigmoid函数:
def sigmoid(z):
"""激活函数"""
result = 1.0 / (1 + np.exp(-z))
return result
如果想要验证激活函数写对了没有,可以选择打印自变量为0时的函数值print(sigmoid(0)),如果输出为0.5,就表明是正确的 !
- BP过程
这个BP将正向传播糅合在一起了,即先通过正向传播计算误差(损失),再反向调整权重,代码中的求偏导这些过程,没有用偏导的函数,而是直接求解的,与上篇文章中的整个过程是对应的 !
def bp(w, b, x):
"""正向传播:计算误差 + 反向传播:更新权重w"""
# 1. 正向传播:计算误差
h1 = sigmoid(w[1] * x[1] + w[2] * x[2] + b[1])
h2 = sigmoid(w[3] * x[1] + w[4] * x[2] + b[1])
h3 = sigmoid(w[5] * x[1] + w[6] * x[2] + b[1])
o1 = sigmoid(w[7] * h1 + w[9] * h2 + w[11] * h3 + b[2])
o2 = sigmoid(w[8] * h1 + w[10] * h2 + w[12] * h3 + b[2])
# 总误差
error = 0.5 * np.square(real_o1 - o1) + 0.5 * np.square(real_o2 - o2)
# 2. 反向传播:更新权重w
alpha = 0.5 # 学习率
partial_1 = -(real_o1 - o1) * o1 * (1 - o1)
partial_2 = -(real_o2 - o2) * o2 * (1 - o2)
# 隐藏层到输出层更新后的w
w[7] = w[7] - alpha * (partial_1 * h1)
w[9] = w[9] - alpha * (partial_1 * h2)
w[11] = w[11] - alpha * (partial_1 * h3)
w[8] = w[8] - alpha * (partial_2 * h1)
w[10] = w[10] - alpha * (partial_2 * h2)
w[12] = w[12] - alpha * (partial_2 * h3)
# 输入层到隐藏层更新后的w
w[1] = w[1] - alpha * (partial_1 * w[7] + partial_2 * w[8]) * h1 * (1 - h1) * x[1]
w[2] = w[2] - alpha * (partial_1 * w[7] + partial_2 * w[8]) * h1 * (1 - h1) * x[2]
w[3] = w[3] - alpha * (partial_1 * w[9] + partial_2 * w[10]) * h2 * (1 - h2) * x[1]
w[4] = w[4] - alpha * (partial_1 * w[9] + partial_2 * w[10]) * h2 * (1 - h2) * x[2]
w[5] = w[5] - alpha * (partial_1 * w[11] + partial_2 * w[12]) * h3 * (1 - h3) * x[1]
w[6] = w[6] - alpha * (partial_1 * w[11] + partial_2 * w[12]) * h3 * (1 - h3) * x[2]
return o1, o2, error, w
- 训练预测
上面相当于是神经网络的一次训练过程(正向+反向),当然一次的训练显然是不够的,只有多次训练后才会愈来愈接近真实值,这里我们进行1000次的迭代,为了更好地观察变化,打印每一次的预测值、总误差以及权重
for i in range(1000):
"""迭代1000次并查看结果"""
o1, o2, error, w = bp(w, b, x)
print("第{}次迭代:,预测值为:({},{}),总误差为:{},权重为:{}".format(i + 1, o1, o2, error, w))
- 部分输出
第10次迭代:,预测值为:(0.6628660388080178,0.9081950647466669),总误差为:0.21646305603033708,权重为:[0, 0.07610804313549309, 0.10221608627098615, 0.190408353976401, 0.230816707952802, 0.2966262198756943, 0.34325243975138864, -0.10761926674458068, 0.48082572625849623, -0.08313002065013501, 0.5851569288735385, 0.004809785641267411, 0.6858692203369033]
第100次迭代:,预测值为:(0.07434400783631397,0.945689792404305),总误差为:0.003051772920806612,权重为:[0, 0.1864089921965286, 0.3228179843930571, 0.23965760338038153, 0.3293152067607631, 0.3108135454268529, 0.3716270908537057, -1.0850594180486732, 0.6369390234749703, -1.0964255065626485, 0.7437262476913241, -1.021016770363603, 0.8457592597174984]
第1000次迭代:,预测值为:(0.022980751228480648,0.9776666549668452),总误差为:0.0001603056510812724,权重为:[0, 0.21491564150393844, 0.3798312830078768, 0.2628474338690681, 0.3756948677381351, 0.3231962973308205, 0.3963925946616401, -1.489582973447391, 0.9415807254516165, -1.5016742512504941, 1.0488846306039166, -1.4274137106156801, 1.1517468039990286]
这里截取了迭代到10、100、1000次时的对应的数据,可以观察到时越发趋近于真实值的,且总的误差也在变小 !