版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/a786150017/article/details/82953158
BP反向传播
基本原理
利用输出后的误差来估计输出层前一层的误差,再用这个误差估计更前一层的误差,如此一层一层地反传下去,从而获得所有其他各层的误差
对网络的连接权重做动态调整
核心:梯度下降法
推导过程
输入层相关变量:下标i
隐藏层相关变量:下标h
输出层相关变量:下标j
激励函数输入为a, 激励函数输出为z, 结点误差为δ
预测值是z, 目标值是t
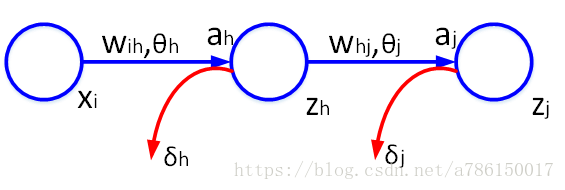
【前向传播】
ah=i∑wihxi+θhzh=f(ah)
aj=h∑whjzh+θjzj=f(aj)
损失函数
E(W)=21j∑(tj−zj)2
【反向传播】
链式法则,误差 × 输入
隐藏层-输出层
∂whj∂E=δjzh
∂θj∂E=δj
δj=∂aj∂E=∂zj∂E∂aj∂zj=−(tj−zj)f′(aj)
输入层-隐藏层
∂wih∂E=δhxi
∂θh∂E=δh
δh=∂ah∂E=j∑∂aj∂E∂zh∂aj∂ah∂zh=j∑δjwhjf′(ah)
【更新权重】
Δw=α∂w∂Ewt+1=wt−Δw
Δθ=α∂θ∂Eθt+1=θt−Δθ