本文介绍了感知器,自适应线性单元以及误差反向传播算法相关知识。
系列文章:
- 【神经网络算法详解 01】-- 人工神经网络基础
- 【神经网络算法详解 02】 – 感知神经网络与反向传播算法(BP)
- 【神经网络算法详解 03】 – 竞争神经网络【SONN、SOFM、LVQ、CPN、ART】
- 【神经网络算法详解 04】 – 反馈神经网络 【Hopfield、DHNN、CHNN、BAM、BM、RBM】
- 【神经网络算法详解 05】-- 其它类型的神经网络简介【RBF NN、DNN、CNN、LSTM、RNN、AE、DBN、GAN】
1. 感知器模型
【 感知器(Perceptron) 】:用于线性可分模式分类的最简单的神经网络模型。由一个具有可调树突权值和偏置的神经元组成。1958年 Frank Rosenblatt 提出一种具有单层计算单元的神经网络,即为Perceptron。

- 本质:是一个非线性前馈网络,同层内无互联,不同层间无反馈,由下层向上层传递。
- 其输入、输出均为离散值,神经元对输入加权求和后,由阈值函数决定其输出。
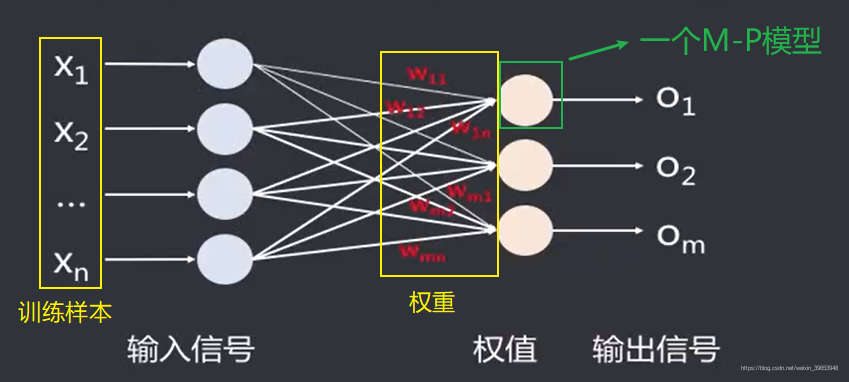
- 感知器实际上是一个简单的单层神经网络模型。单节点感知器就是MP模型,首次提出了习的概念。
回顾一下,在 之前的文章中 提到的M-P模型的概念。命名的由来是两位创立者的名字首字母(McCulloch & W.Pits)。
【 M-P模型 】:是把神经元视为二值开关元件,按照不同方式组合来完成各种逻辑运算。能够构成逻辑与、非、或,理论上可以进而组成任意复杂的逻辑关系,若将M-P模型按一定方式组织起来,可以构成具有逻辑功能的神经网络。
罗森布拉特给出感知机一个简单直观的学习方案:给定一个有输入输出实例的训练集,感知机「学习」一个函数:对每个例子,若感知机的输出值比实例低太多,则增加它的权重,若比实例高太多,则减少它的权重;感知器是整个神经网络的基础,神经元通过响应函数确定输出,神经元之间通过仅值进行传递信息,权重的确定根据误差来进行调节,这就是学习的过程。通俗地讲,我们说训练神经网络,其实就是我们搭建的神经网络在“学习”,可以理解成学习一个映射规则,其实就是去学习权重,当我们拿新的数据通过这个映射规则会给出我们期望的预测,比如分类问题的话,这个映射规则会给出每一类的概率。
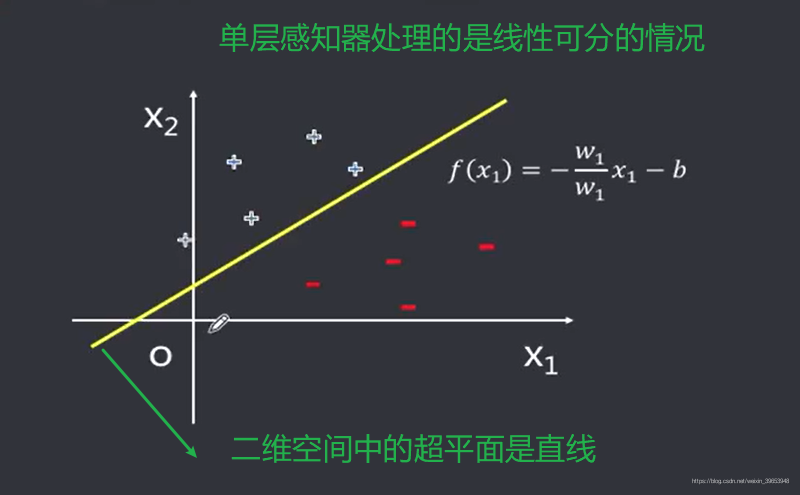
1.1 单层感知器:线性分类
单层感知器:通过计算权重和输入乘积的和
,根据和的正负来判断分类。
该感知器的分类逻辑:
- 计算各输入变量加权后的和 ;
- 的根据和 是否大于0得到分类结果;
对于任一个训练练样本,其输入特征为
求和:
当
时,为正类;
当
时,为负类;
即
为正负类的分界超平面;
上式中, 的下标“1”表示第一个样本,以此类推,将直线方程 整理成习惯的公式: 。
二维空间中的分隔超平面为一条直线,直线以上的点为正类(直线(二维空间的分隔超平面)法向量的方向为正方向),直线下的点为负类。
在之前的文章SVM中介绍了超平面的定义,我们再来复习一下【超平面】的相关知识:
- 定义:指n维线性空间中维度为n-1的子空间。它可以把线性空间分割成不相交的两部分。
- 比如,二维空间中,把平面分成了两部分的直线(一维)是超平面;三维空间中,把空间分成了两部分的平面(二维)是超平面。
- 法向量:垂直于超平面的向量。
1.2 单层感知器的学习算法
采用的是【 离散感知器算法 】:
离散感知器:
上式中,第一个式子是向量形式,第二个式子是分量表示形式。
在第一个式子中,
表示每次要更新权重的大小,
为学习率,[ ]中的部分为学习信号,其中
表示期望的输出,
表示实际的输出;
表示输入。
具体步骤:
- 初始化仅值,赋予较小的非零随机数。如果输入样本线性可分,无论初始值如何取都会稳定收敛;
- 输入样本
,其中
,i = 1,2,…,k,其中共
条
个分量的输入,输出为
条
个分量的向量:
,i = 1,2,…,k;其中“1”表示偏置(bias),所以输入变为
n+1维,“m”表示输出层的维度,如果是分类问题的话,m其实就是分类数,也是最后一层神经网络的输出数,如果写过这类算法的话,不难理解。 - 计算各输出节点的实际输出:
- 按照实际输出值和期望值之间的差更新权重: , 为学习率;
- 返回第二步,处理下一组输入样本;
- 循环上述过程,直到感知器对所有样本的实际输出和期望输出一致。注意,如果是线性可分的,可以实现;如果是非线性的,则不一定能保证一致。
1.3 单层感知器的例子
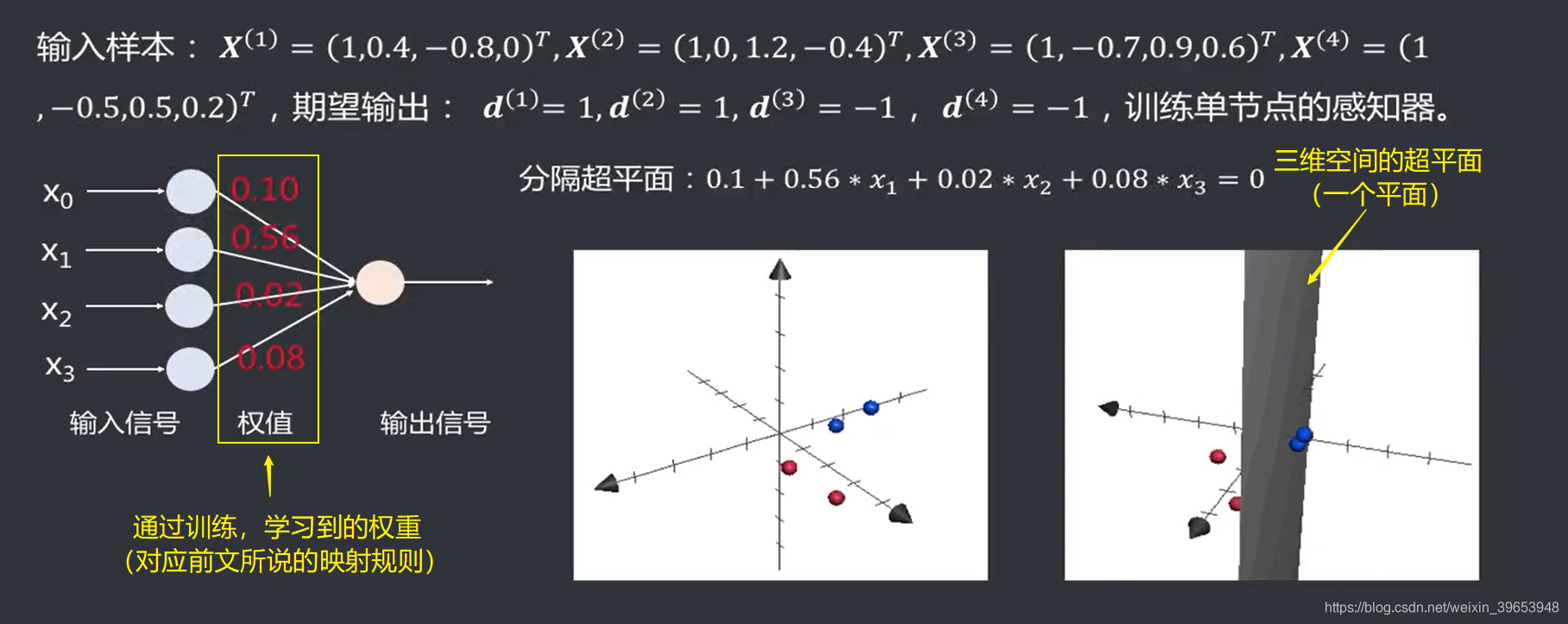
1.计算第一个样本,第一次更新权重。




经过以上第一轮(1个epoch)对所有四个样本进行训练之后,发现有两个样本的期望输出(标签)与实际输出(预测值)不一致,此时,我们需要再进行下一轮的训练,如此训练多轮(多个epoch),直到找出一组合适的权重能够把所有样本的期望输出和实际输出达到一致时,训练结束。此时,这组权重就是我们可以接受的一组解。结合下图,在当前的语境下(单层感知器,线性,三维空间),这组权重可以理解为:方程的系数,线性分类器,三维空间的超平面,按照前文所讲的定义,三维空间中的超平面为一个平面。下图中,分隔超平面将红色和蓝色两类样本完全分隔开。
1.4 线性与非线性
线性(Linear)的严格定义是一种映射关系,其映射关系满足可加性和齐次性。通俗理解就是两个变量之间存在一次方函数关系,在平面坐标系中表现为一条直线。不满足线性即为非线性〈non-linear)。回想之前讲得买袜子的例子。
1.5 线性与非线性分类器
线性可分,即可以用一个超平面将正负样本分开。以二维空间的二分类为例,是指可以通过一条直线将数据分成正负样本两类。分类器(算法)也有线性和非线性两类。
- 线性分类器使用超平面类型的边界,非线性分类器使用超曲面型的边界
- 线性分类器简单、容易理解,非线性分类器能解决更复杂的分类问题
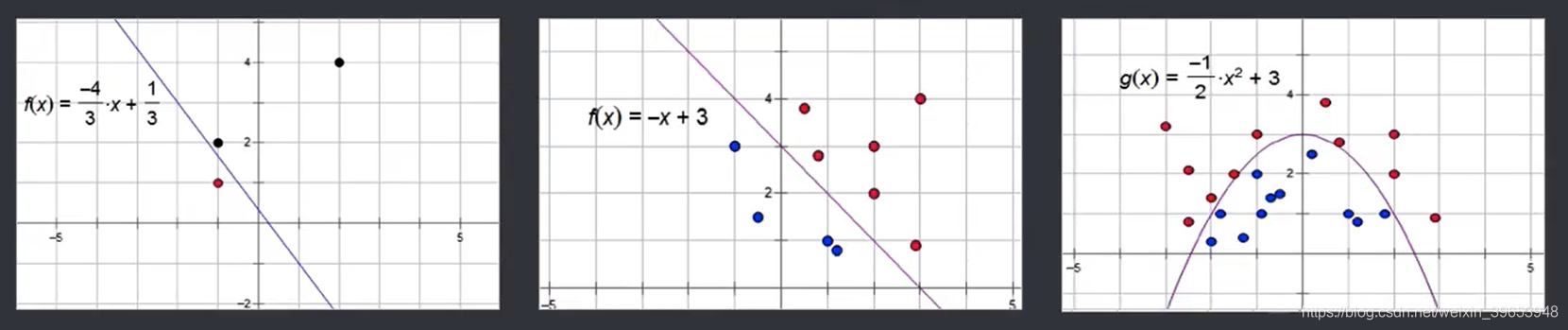
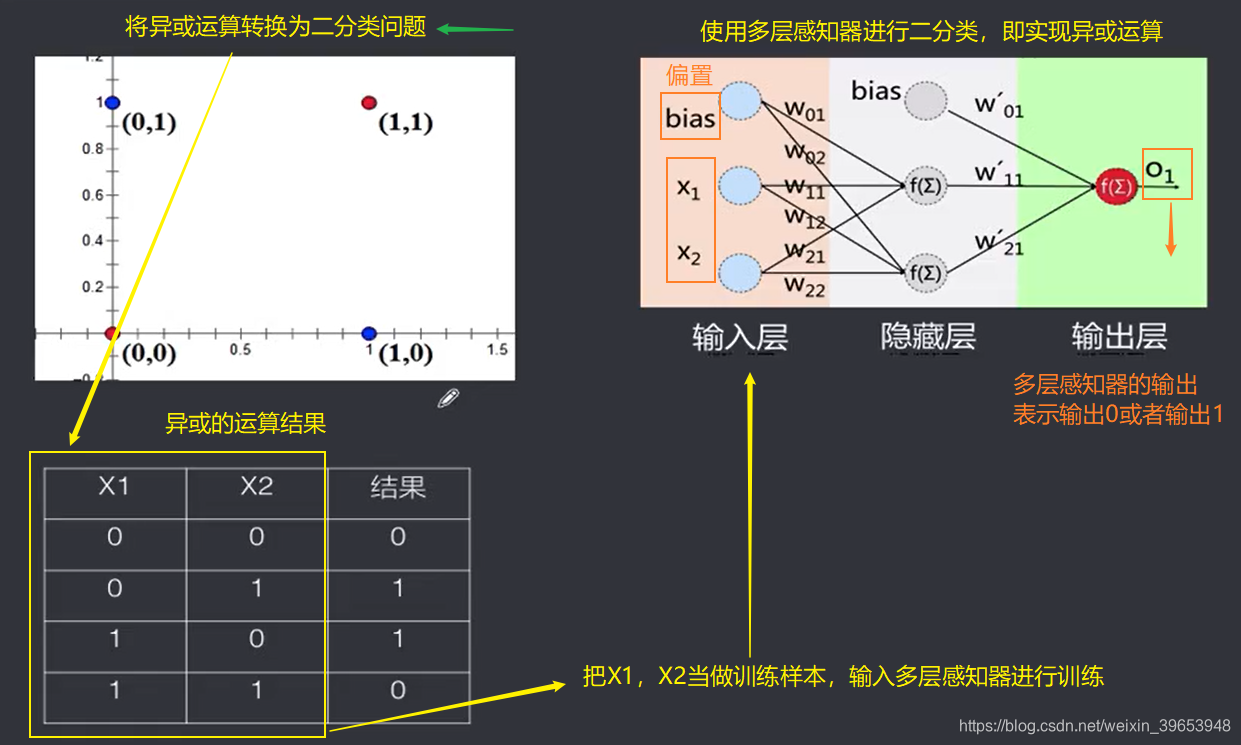
1.5 单层感知器:实现逻辑运算
聪明绝顶警告!

1969年《Perceptrons》(感知器)证明了无法使用感知器来表示异或。


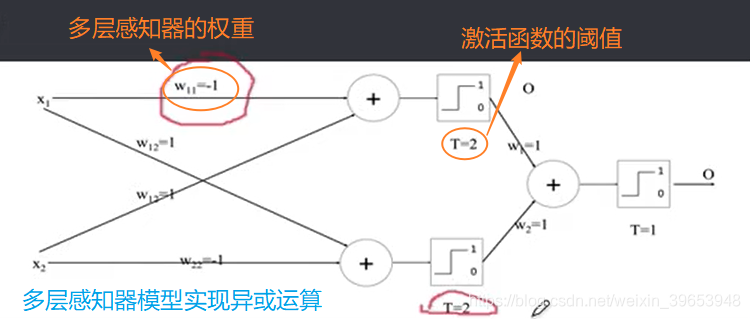
2. 多层感知器
多层感知器(MuIti Layer Perceptron,即MLP)是一种前馈人工神经网络模型,包括至少一个隐藏层(除了一个输入层和一个输出层以外),将输入的多个数据集映射到单一的输出的数据集上。
- 单和多是指有计算功能的节点所在的层数,输入层无计算功能,不计算在内。单层即只有输入层和输出层,多层至少包含一个藏层;
- 单层只能学习线性函数,多层可以学习非线性函数,适用于模式识别、图像处理、函数逼近等领域。
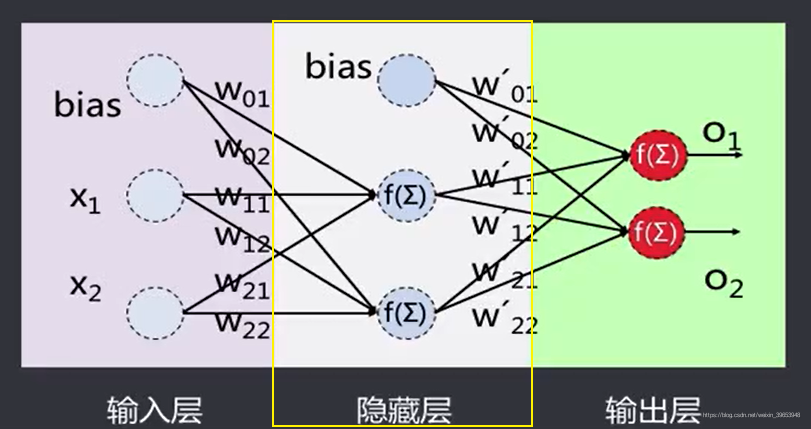
给出一系列特征 和目标Y,一个多层感知器可以以分类者回归为目的,学习到特征和目标之间的关系。简单的理解,分类输出是离散的值,比如苹果、西瓜…;回归输出是连续的值,比如预测房价等等。
加入的偏置(bias)可以理解为分类超平面的截距。
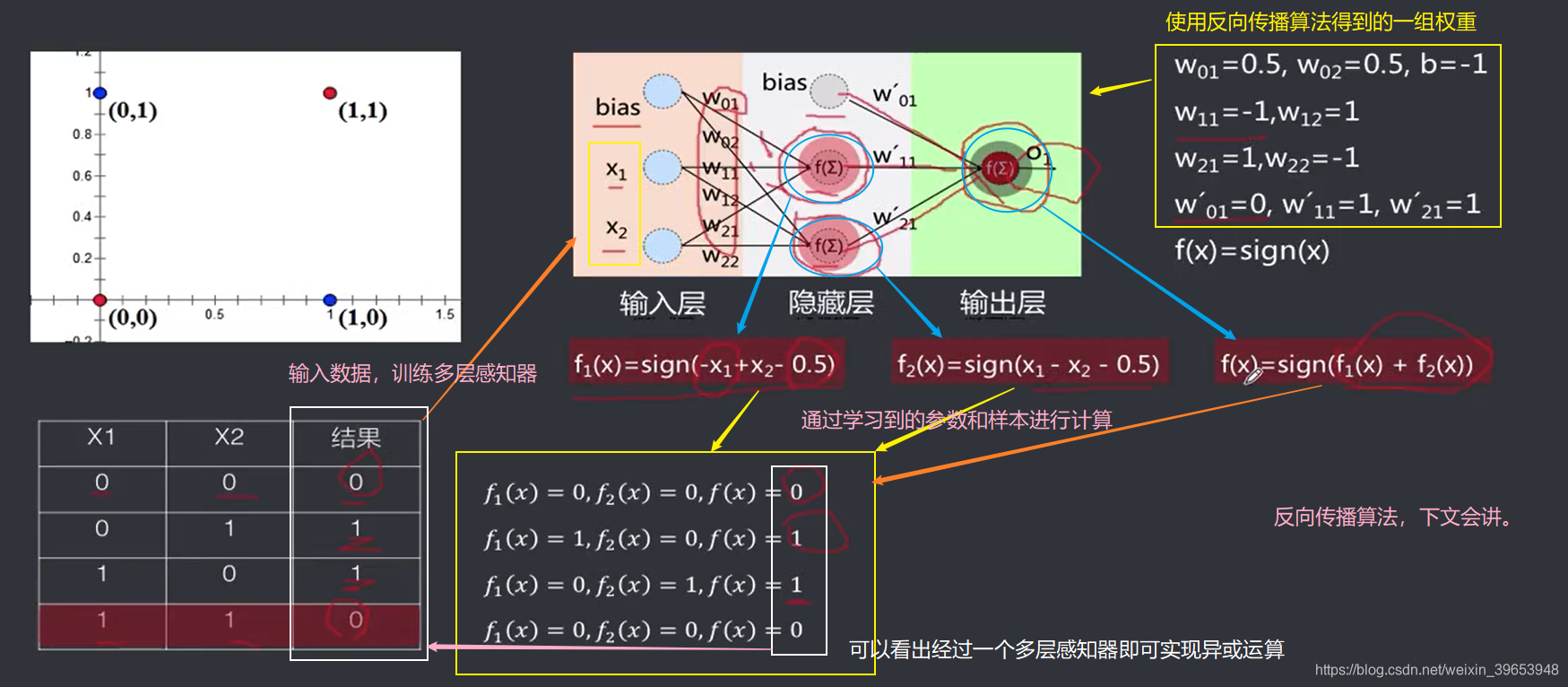
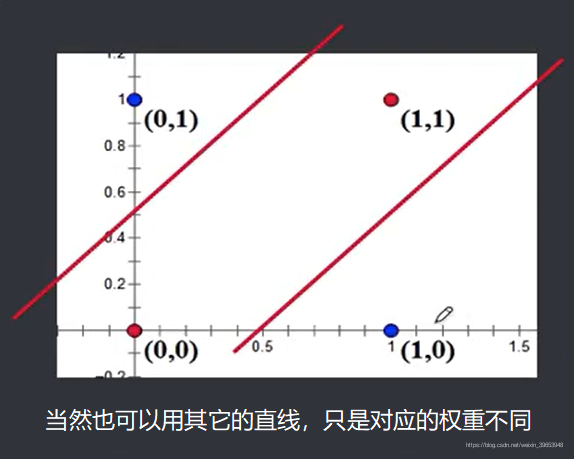
单个感知器为一个线性分类器,对应了一个分类超平面,对于二维空间,相当于一条直线,两个隐层节点对应了两条直线: 在样本空间中画出两条线,可以通过一个开域(或凸域)将不同类别的样本点分开。
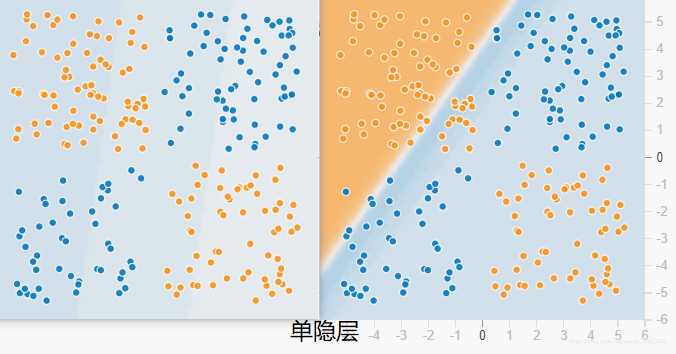
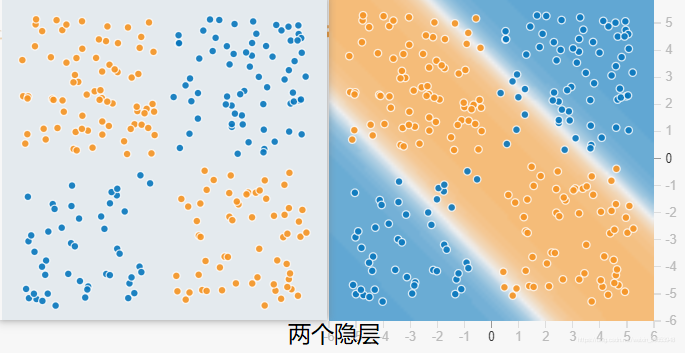
2.1 隐藏层的效果
可以查看tensorflow的playground网站,很好的演示了隐藏层的效果。网址:http://playground.tensorflow.org/
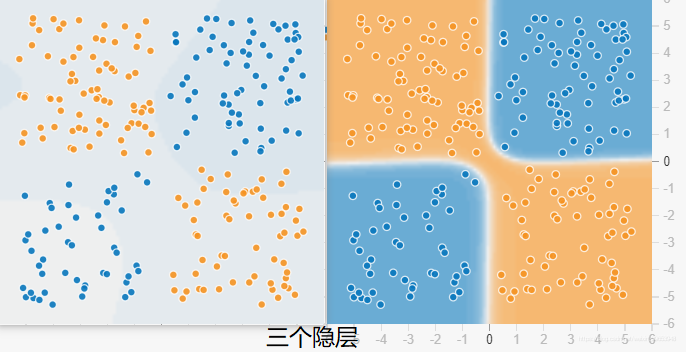
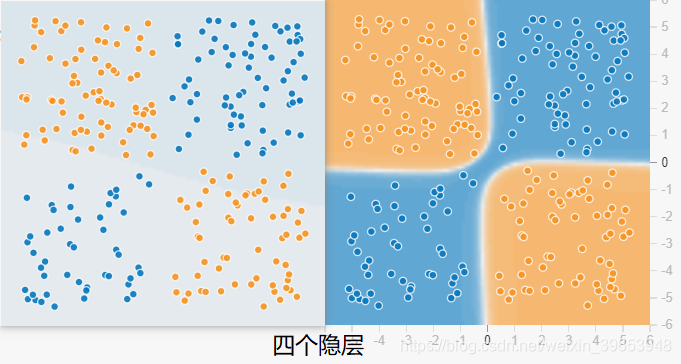
我分别用四个隐藏层和八个隐藏层做了测试,都训练了115个epoch,其它参数配置相同,对比如下图:


可以看出隐层数目增加以后,收敛速度明显加快,损失也更小,分类效果更好(八个隐层的分类超平面更精确)。
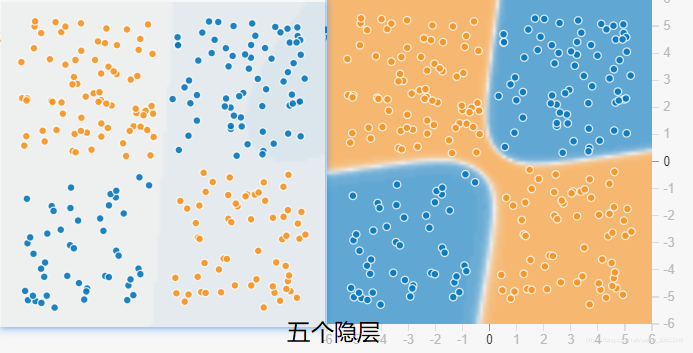
2.2 感知器对比

看一下对比,下例都是两个输入
,两个输出,只是隐层数目不同。
3. 自适应线性单元
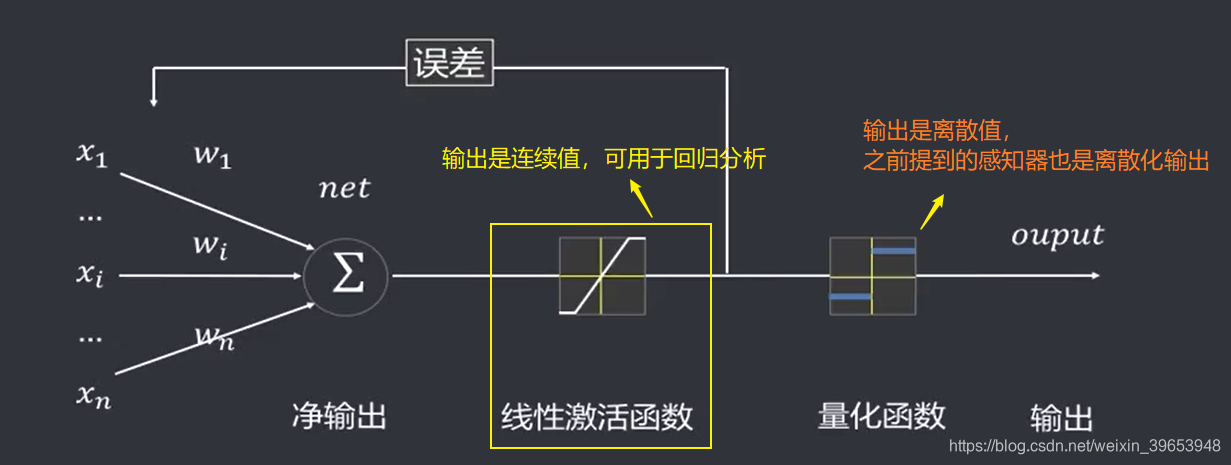
1962年,斯坦福大学教授Widrow提出一种自适应可调的神经网络,其基本构成单元称为【自适应线性单元( Adaptive Linear Neuron)】,具主要作用是线性逼近一个函数式而进行模式联想。该模型是最早用于实际工程解决实际问题的人工神经网络。这种自适应可调的神经网络主要适用于信号处理中的自适应滤波、预测、模式识别等。主要应用于语音识别、天气预报、心电图诊断、信号处理以及系统辨识等方面。
3.1 ADALINE与感知器对比

- 激活函数:ADALINE的激活函数为线性函数,感知器的为阈值函数;
- 误差更新:ADALINE在输出最终结果前根据误差更新权重,感知器在输出最终结果后更新;
- 损失函数:ADALINE使用均方误差SSE作为损失函数,可最小化损失函数,感知器没有损失函数;
- 计算方便:凸函数,可微,有多种快速求解的方法,比如梯度下降法等;
- 输出结果:ADALINE可以输出连续值或者分类值,感知器智能输出分类值。
3.2 回顾:最小均方学习规则
聪明绝顶警告。

3.3 ADALINE 例子




… … … … … …

3.4 MADALINE:多层自适应线性网络
Hoff 将 ADALINE 进行了改进和推广,提出 MADALINE 模型,即将多个 ADALINE 神经元互相连接形成一个多层网络,实际上是由 ADALINE 和 AND 逻辑器组成,可以对分线性数据进行划分。同样采取LMS的算法进行学习。但由于隐藏层的误差无法直接计算,即 LMS 算法不能直接用于含有隐藏层的神经元网络,故 MADALINE 一般不含隐藏层。对此,Widrow提出了一个需要微分的算法 MR II 用于解决多层网络的学习问题。
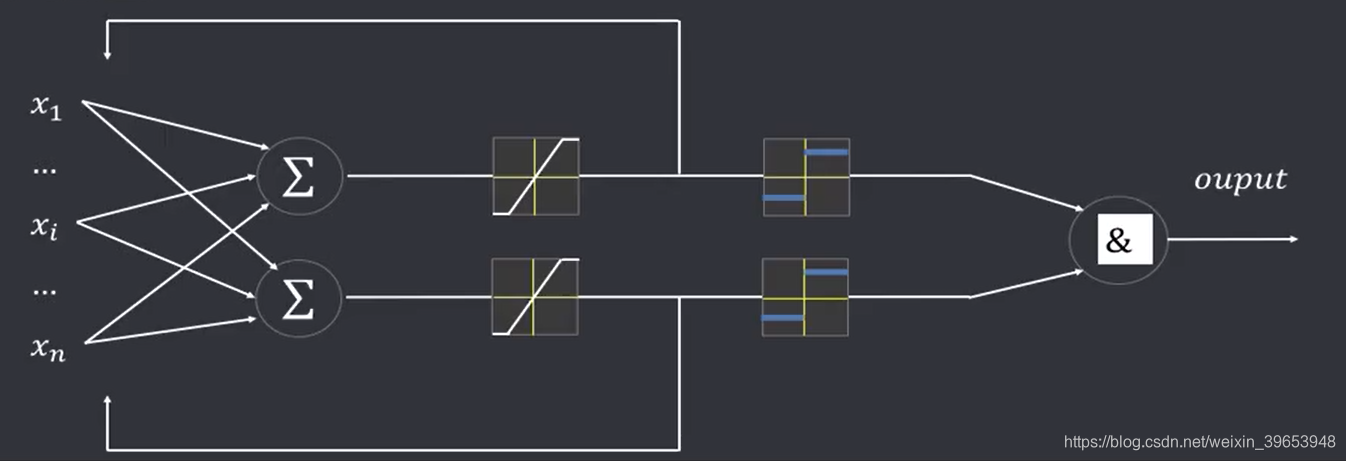
4. 误差反向传播算法
4.1 多层感知器的训练
单层感知器训练依照离散感知器学习规则或 学习规则,对于一组输入有一个预期输出,通过比较感知器输出结果和预期输出结果,调整感知器的权重和阈值,即可完成模型训练,得到一个比较满意的结果。
单层感知器学习规则的逻辑如下:
- 定义一个包含感知器参数的损失函数,用来衡量当前模型优劣;
- 调整参数的值,让损失函数逐步变小
- 损失函数小到一定程度,使得输出结果和预期输出结果的差可以接受
- 学习得到合乎要求的模型
伪代码:
Step1:初始化W,b
Step2:在训练据集中选取
Step3:计算损失函数
,如果
,则更新权重及偏置量:
step4:转至Step2
多层感知器的学习规则同样使用该逻辑,只是由于多层感知器的隐藏层的神经元,没有直接的预期输出结果,具预期输出体现在下一层(单隐藏层)或者下N层(多个隐藏层)的输出中,需要从整体考虑具体的损失函数。通俗的说就是,多层感知器权重的调整方向不像单层感知器那么明确,特别是如果有多个隐藏层的话,计算会越来越困难。没有办法定义隐藏层的损失函数,得到的损失函数是整体的损失函数。
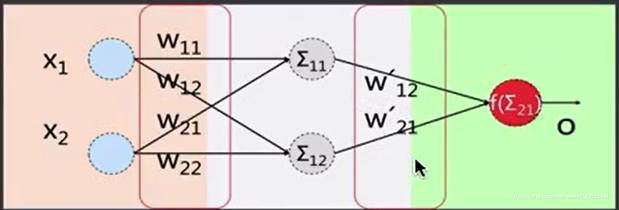
下面看一个例子:

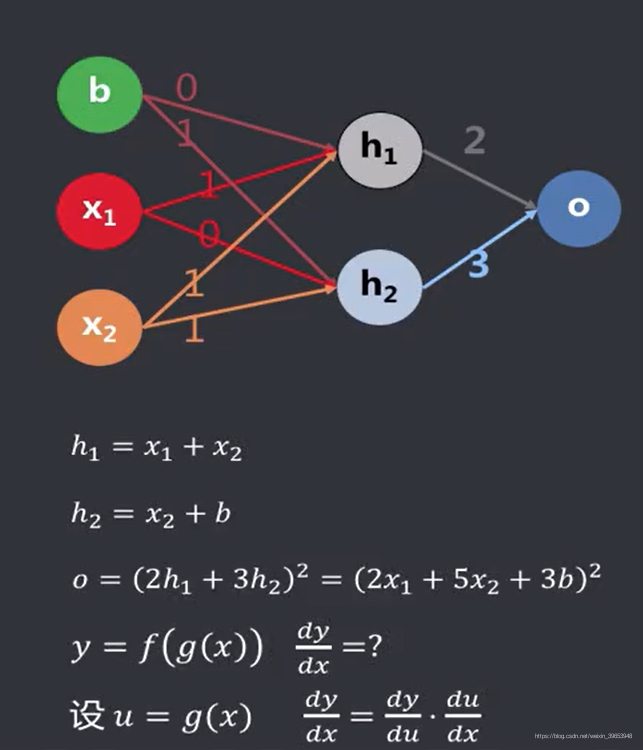
从输入建立到输出的关系,当网络结构简单时,遍历路径可控:
当输入变量增多、隐藏层增加或者隐藏层中的神经元增多时,求偏导的次数快速增加,与神经元个数的二次方成正比。计算量过大,使得学习过程变得仅仅理论上可行(这也是闵斯基看衰ANN的原因)。设想一个2个隐藏层,每个隐藏层10个节点的结构,输入变量 将会有 条路径影响到输出变量 。
从输入到输出的链式求导顺序,关注的是输入对输出的影响。事实上通过简单计算能得到模型输出和实际输出的差异,我们更想知道的是输出 o 的变化对前面的路径(输入+权重参数)有什么影响。换句话说就是,如果我们知道权重和输入样本,计算输出是很简单的;但是反过来,如果知道输出值和期望值的差异,那么我们应该调整权重,使得这个差异接近0,多层感知器的参数众多,使用正向求导去调整这些参数的话是很困难的,也就是很难训练,因此就要用到反向传播算法。
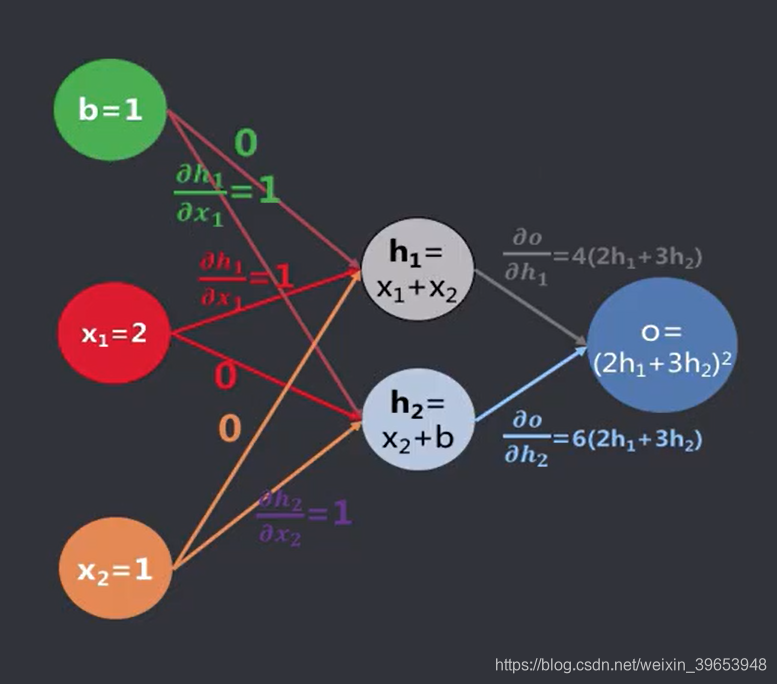


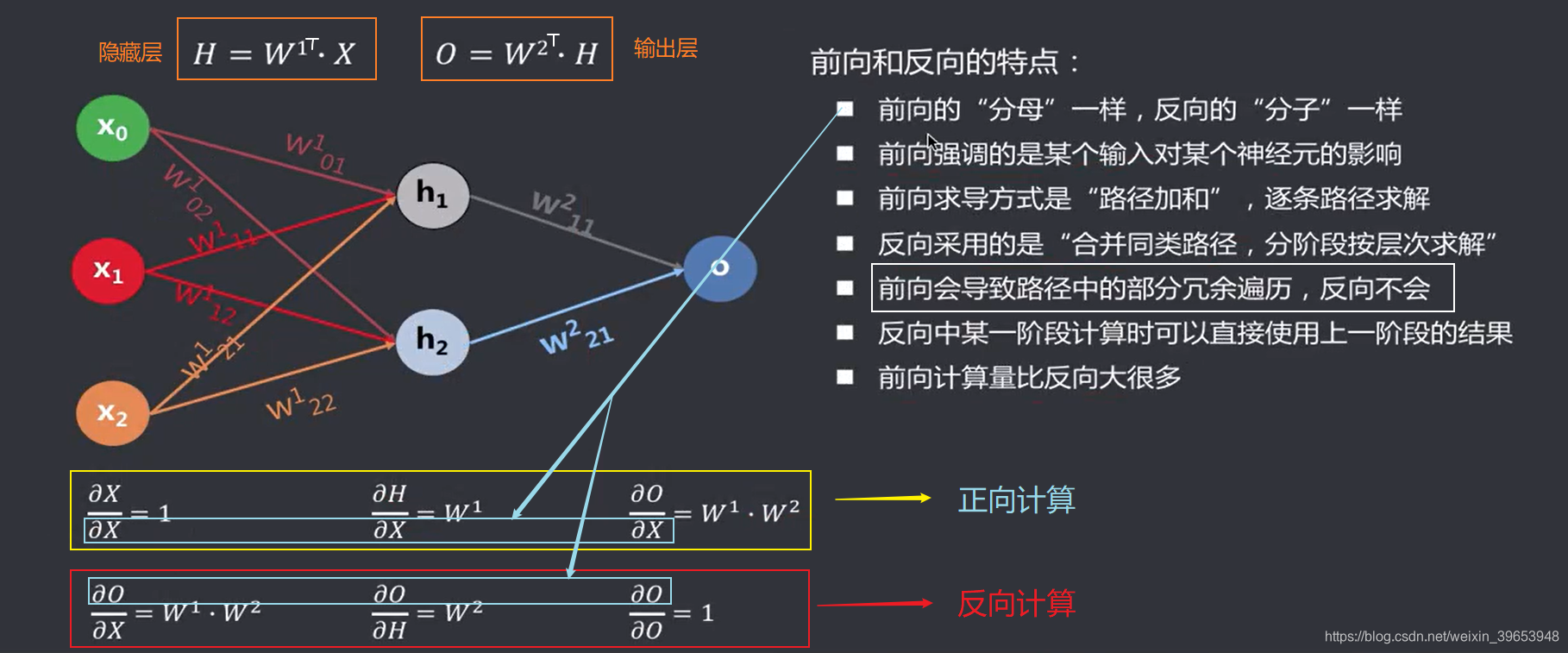
前向和反向的特点·
- 前向的“分母”一样,反向的“分子”一样;
- 前向强调的是某个输入对某个神经元的影响;
- 前向求导方式是“路径加和”,逐条路径求解;
- 反向采用的是“合并同类路径,分阶段按层次求解”;
- 前向会导致路径中的部分冗余遍历,反向不会;
- 反向中某一阶段计算时可以直接使用上一阶段的结果;
- 前向计算量比反向大很多;
4.2 BP算法
BP算法(Error Back Propagation,误差反向传播算法):是目前用来训练人工神经网络(ANN)最
常用、最有效的算法。由1974年 Paul Werbos 最早提出,未被重视,后由 Rumelhart 和 McCeIIand 发
表《并行分布式处理》正式提出。
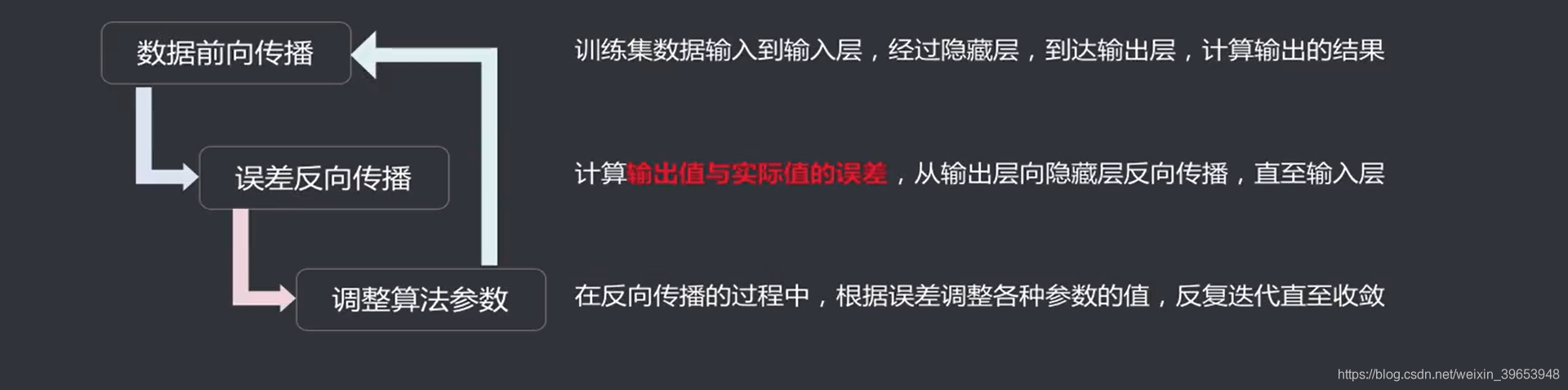
4.2.1 (回顾)损失函数优化:梯度下降法

4.2.2 简单推导:反向传播算法



4.3 BP网络训练步骤

4.4 激活函数的特点
一个好的激活函数通常会具有的特点:
- “非线性:导数不能是常数,否则网络会退化成单层网络;
- “处处可微:或者说几乎处处可微,保证能计算梯度,从而进行参数优化;
- 计算简单:降低计算难度和复杂程度;
- “非饱和性:饱和指在某些区间内,梯度接近于零(梯度消失),使得参数无法继续更新,即无法收敛;
- “单调性:即导数符号不变(朝一个方向变化),免梯度方向经常变化导致的不易收敛;
- 有限的输出范围,面对不同范围的输入也会保持输出的稳定性,但有时会导致梯度消失;
4.5 误差曲面存在的问题
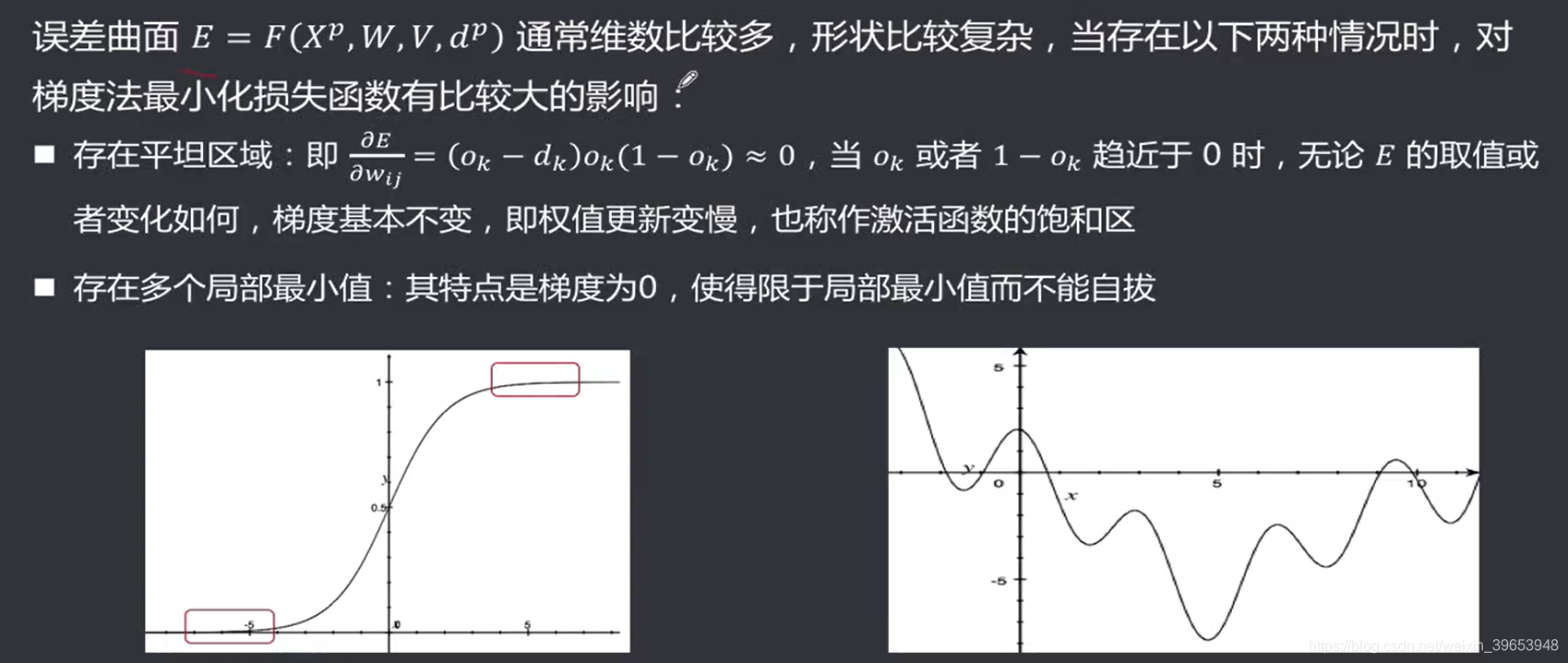
4.6 标准BP算法存在的问题
容易陷入局部最小,得不得到全局最优值饱和区导致训练次数多,收敛缓慢设计网络时,关键信息选取无明确依据。
- 隐层数
- 隐层节点数
- 学习涑率
训练顺序对训练有影响,有遗忘的特点。
4.7 标准BP算法改进
4.7.1 增加动量项
标准BP算法在更新权重时,只考虑了当前状态下的误差梯度,而未考虑之前的梯度变化情况,导致训练过程震荡,收敛过慢,为了提高训练速度,在权值调整公式中增加一项,用来保留之前的权重更新的信息,即权重更新公式变为:
其中 被称作动量项,从前一次的权重更新的量中取一部分叠加到当前的更新量中,从而增加了之前梯度变化的影响。
- 被称作动量系数,具取值一般在(0,1)之间。
- 动量项反映了以前积累的权重调整经验,使仅重调整有了“记忆“
- 动量项对当前调整起到了阻尼的作用。当误差变化起伏剧烈时,动量项可以减小震荡趋势,提高训练速度。
4.7.2 自适应调节学习率
标准BP算法中的 称作学习率、学习速率、步长等,通常定为常数,在仅重更新中起到了较大的作用,该值选择不合适,会严重影响学习过程和学习结果。
- 结合误差曲面,当在平坦区时,希望学习率大一些,达到同样的训练效果的同时,可以减少训练次数;
- 到当在误差变化剧烈的区域,希望学习率小一些,以免步子过大,迈过理想值,从而引起不合理的震荡;
- 可在学习过程中适当调整学习率,方法很多,如:
设置初始学习率
经过一批权值调整步骤后,如果总误差上升,说明学习率大了,需要减小,则: 。如果总误差下降,说明学习率小了,可以增加,则:
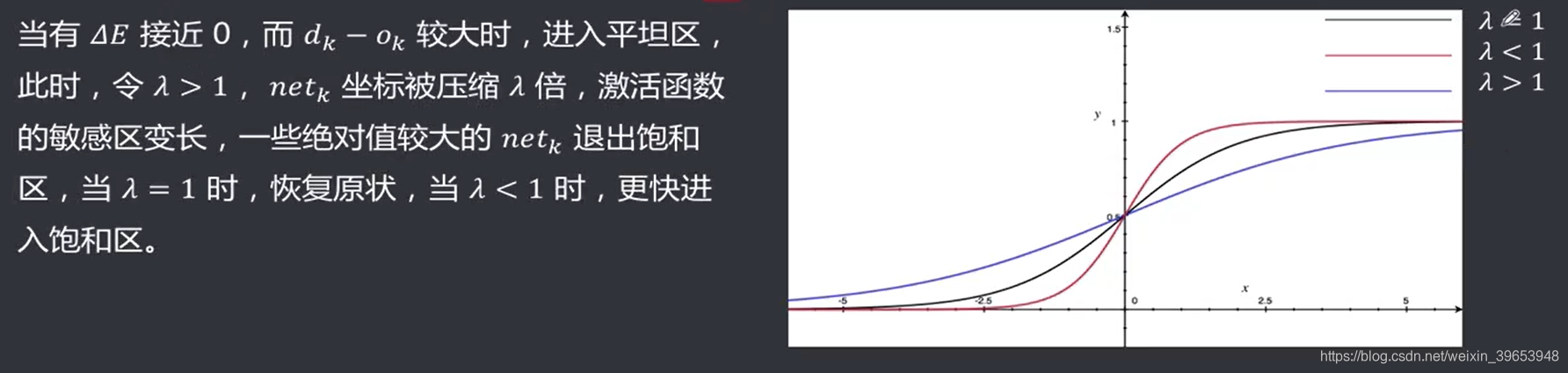
4.7.3 陡度因子
进入误差曲面的平坦区,通常是因为神经元进入了激活函数的饱和区,如果能设法在饱和区内对激活函数进行调整,比如压缩神经元的净输入,使其输出退出饱和区,就可以脱离当前的平坦区。可以在原激活函数中引入陡度因子 :