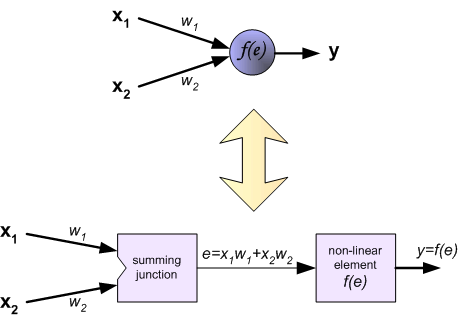
每个神经元有两个单元组成。一个是权重和输入信号。另一个是非线性单元,叫做激励函数。信号e是激励信号。y = f(e) 是非线性单元的输出,即是神经元的输出。
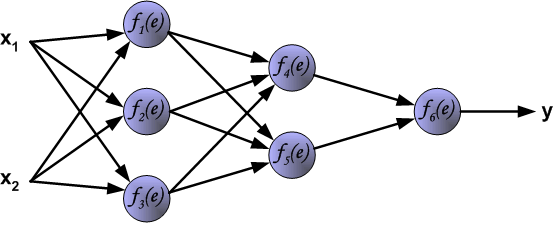
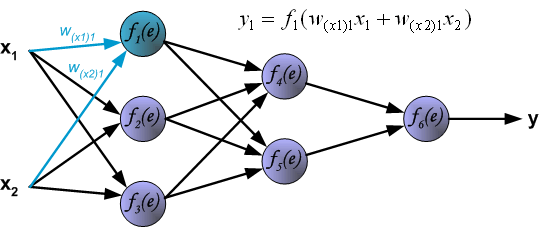
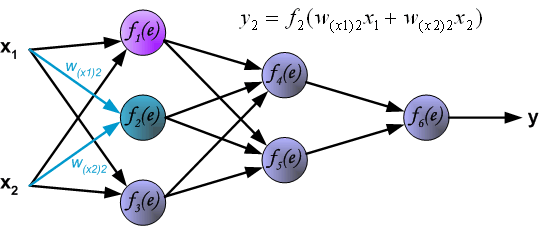
为了训练神经网络,我们需要训练数据。训练数据由输入信号(x1 and x2 )和期望输出z组成。网络的训练过程是一个迭代处理的过程。训练数据集用来在每次迭代过程中更新神经元的权重。每次学习过程由来自训练数据的输入信号开始。我们可以得出每一层的输出。下图说明信号在神经网络的传输路线。w(xm)n 是神经元xm 在第n层输入的连接权重。 yn 表示神经元n的输出。
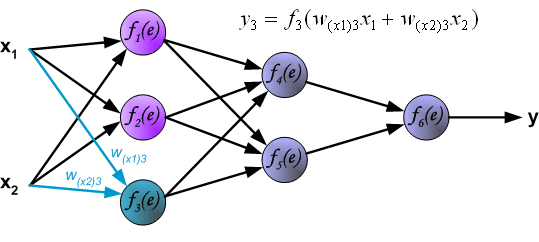
隐层的信号传播路线如下图所示: wmn 代表输出神经元m和输入神经元n的连接权重。
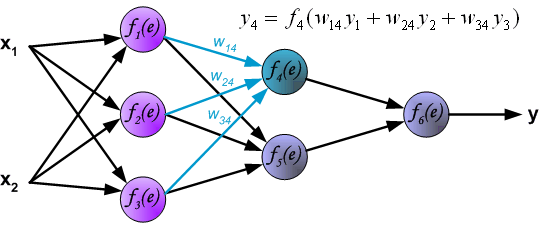
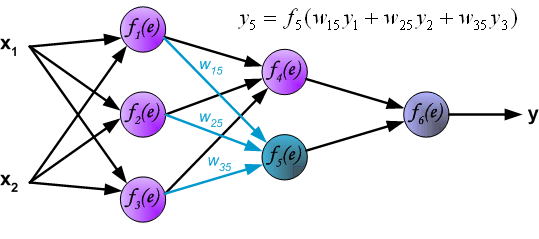
输出层的信号传导:
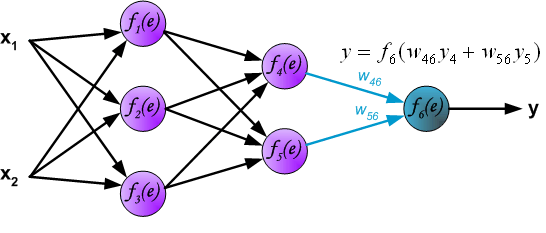
在接下来的计算过程中,输出信号y同训练数据集中的期望输出结果z做对比。他们之间的差异用d 表示。
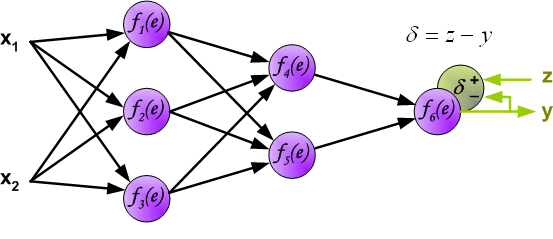
由于这些神经元的输出不知道,所以直接计算损失信号不太可能。很多年前训练多层感知器的有效方法已经被发现了。仅仅后向传播算法被广泛应用。其主要思想是计算损失信号d反向传播所有神经元。
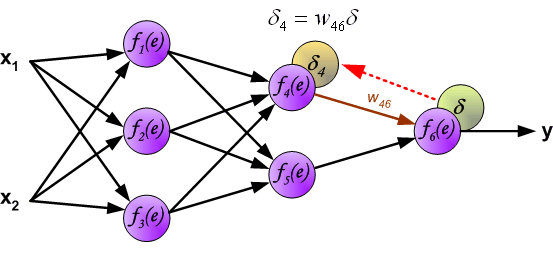
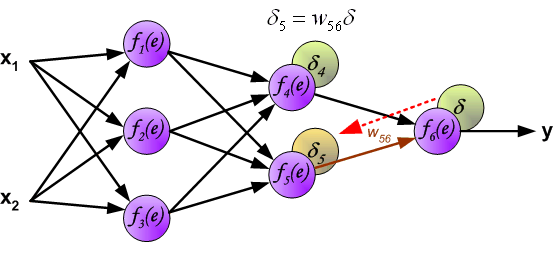
权重系数wmn 用来计算损失信号。神经网络的所有层都按照此过程计算。
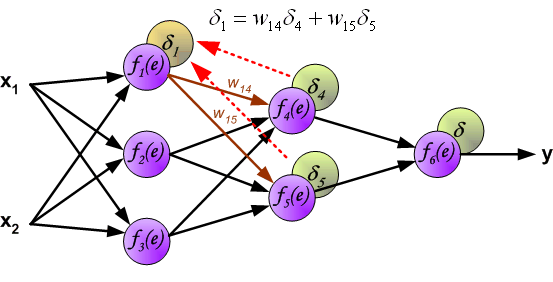
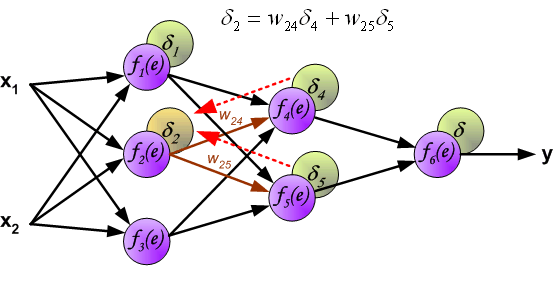
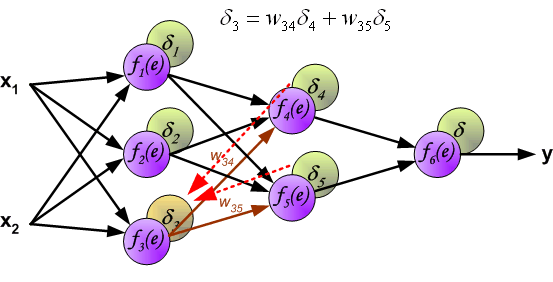
当计算每个神经元的损失信号的时候。每个神经元的输入节点权重系数被修改。公式df(e)/de代表每隔神经元激励函数的梯度。
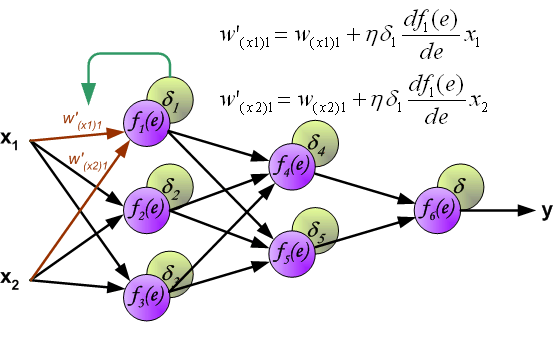
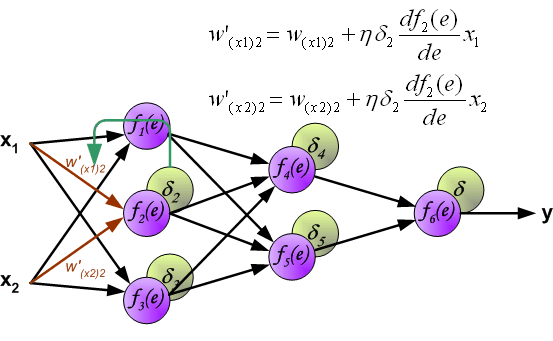
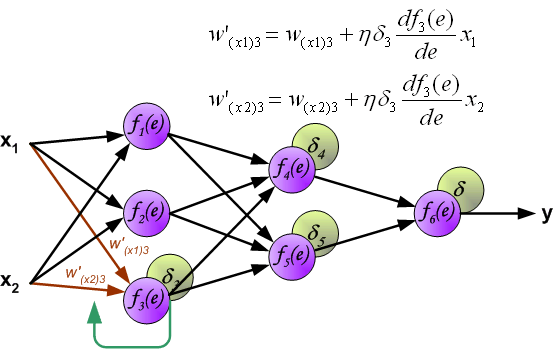
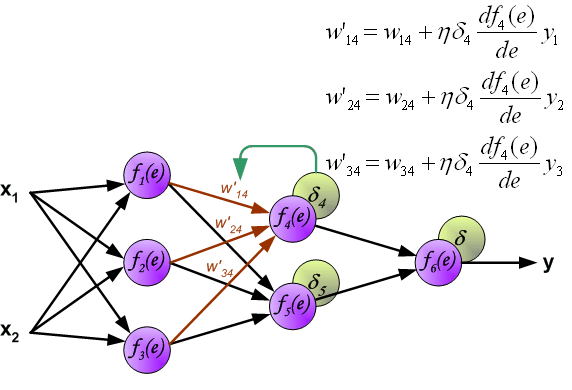
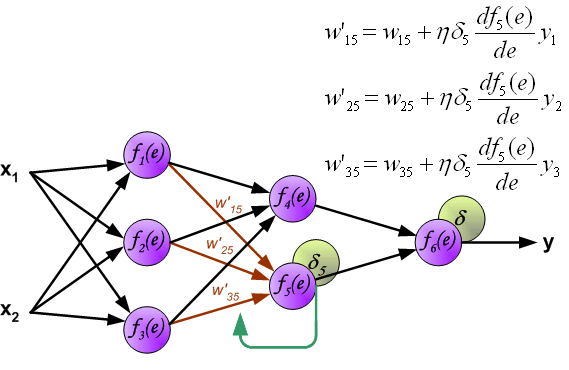
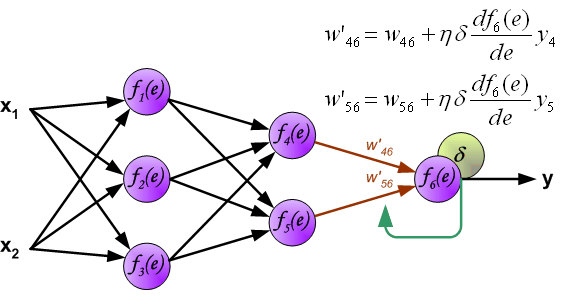
系数h 决定了学习的速率。有一些选择参数的方法。第一种方法是选择较大的值开始网络训练。然而,当权重系数确定之后,参数值急剧减小。第二种方法比较复杂,参数值从较小开始。在学习的过程中,参数值增加,然后在最后阶段再一次减小参数值。用小参数值训练网络能够决定权重系数。
原文链接:https://blog.csdn.net/yunpiao123456/article/details/52526907