FFT算法介绍及OAI中FFT的实现
OAI中FFT的实现
FFT介绍
FFT是DFT(离散傅立叶变换)的一种快速算法。
DFT是一种常用的信号处理方式,可以将时域信号转换到频域。它的原理在《信号与系统》课程中有详细阐述。
但是因为DFT的运算复杂度太高,在实际应用中都是采用FFT的快速算法。
快速傅立叶变换算法(FFT)最开始是由库利(T.W.Cooley)和图基(J.W.Tukey)于1965年提出。其基本思想就是分治。从时域或者频域序列中抽取出不同的子序列从而降低计算复杂度。
根据抽取对象的不同又细分为不同的算法:基于时域的数据做抽取的称为DIT(Decimation in Time), 基于频域的抽取就称为DIF(Decimation in Frequency)。
另外一个区分不同FFT算法的标准称为基(radix)。嗯,基无处不在。
基决定FFT算法的最小组成单位,这个最小组成单位一般是用被称为蝶形图的方式来表示的。
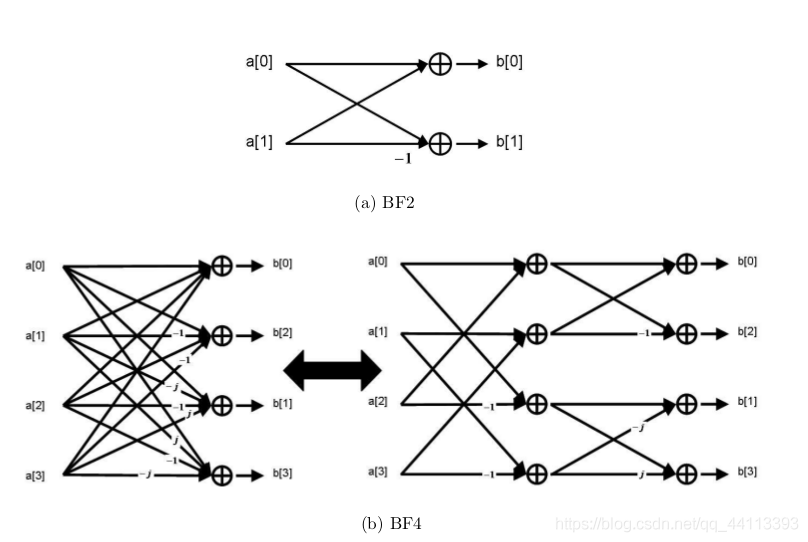
图1
图中,(a)表示一个基-2的基本蝶形图,(b)的左半部分表示一个基-4的基本蝶形图。
可以看到,基数决定来基本蝶形图的输入数据数。除了2和4之外,当然也有可能是其他的基数,或者混合使用几种不同的基数。
库利和图基当时提出的就是时域的基-2算法,因此这个算法又被称为库利-图基算法。
下面我们举几个FFT的例子,来形象的理解一下这个伟大的算法。
DIT radix-2 FFT(时域抽取基-2 FFT)
先给出离散傅立叶变换的一般形式:
其中,
是时域离散序列
的长度,并且是2的指数倍。
称为旋转因子,有如下性质:
1)周期性
2)对称性
3)可约性
所谓radix-2 DIT就是把时域的序列按照奇偶抽取为2个子序列,这2个子序列的长度都是原序列的一半长度,使得计算复杂度减小到原序列的一半。把这个分治过程递归应用到这两个子序列,直到最后剩下2点的DFT。(其实2点DFT还可以继续递归这个过程到1点)
用公式表示,就是把时域序列按照奇偶划分为两个子序列,如下:
(公式没有对齐,LaTex的对齐语法老是提示错误。)
上式中等号右边第一部分是偶数部分,第二部分是奇数部分,两者合起来正好是原时域离散数列。
如果我们令:
再令:
那么利用前面提到的旋转因子的性质,
式就可以表示为:
注意
都是
为周期的周期函数,并且
, 于是可以得到:
如果把这个结论应用到8点DFT,我们可以得到下面这张图:
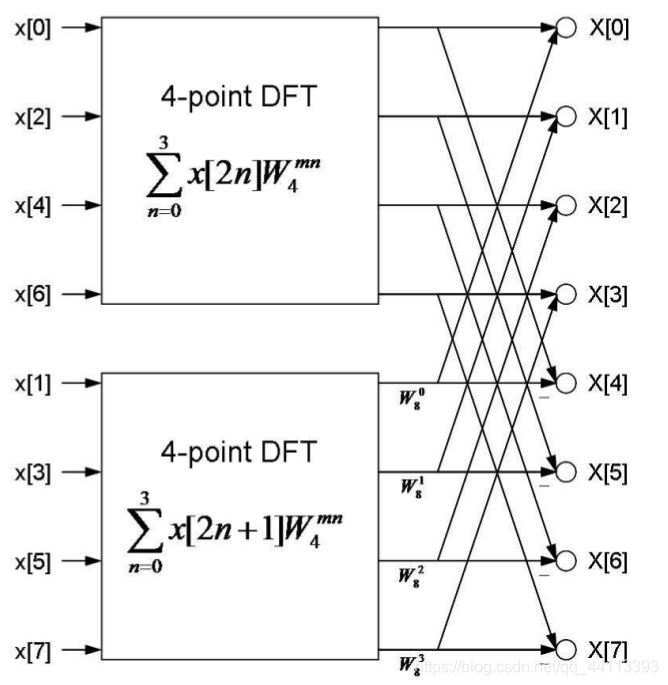
图2
图2中,第一个4点DFT得出的是
,第二个4点DFT得出的是
。注意,旋转因子只在第二部分有,并且与
值相关。
可以继续对这两个4点DFT继续递归使用上述分治方法,从而得到下面的结果:
其中
表示傅立叶变换,我们把这个结论再应用到上述8点DFT的流程图得到下面的结果:
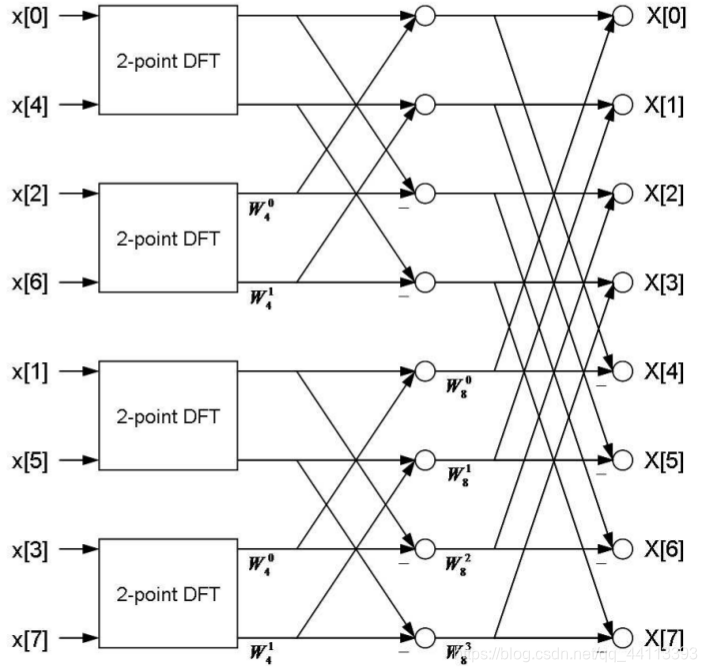
图3
基-2的FFT算法,最终目的就是要把输入数据划分成2点的蝶形图。2点蝶形图替换上图中的2点DFT得到最终的8点DIT radix-2 FFT蝶形图。
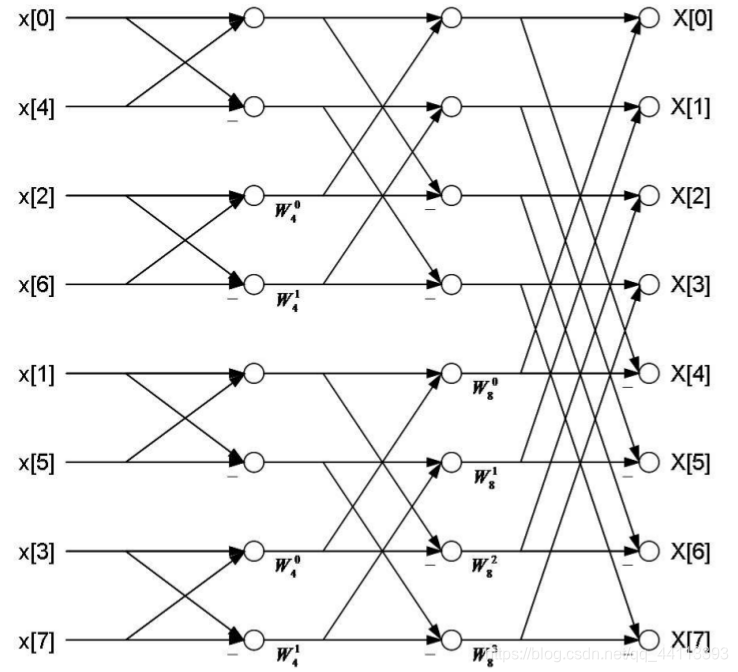
图4
图4表示了完整的8点FFT流程,但是这其中有一个问题:由于对时域数据不断应用分治策略,导致最后要使用的时域数据的顺序是被打乱的。
实际上,被打乱后的序号与最开始的序号是bit-reverse的关系。如下图:

图5
因此,在实际编码时,需要预先把输入数据按照bit-reverse后的顺序重新排列再输入计算。
DIF radix-2 FFT (频域抽取基-2 FFT)
另一种重要的FFT算法是基于对频域序列的抽取的,称为DIF FFT。
DIF radix-2 FFT的算法与DIT radix-2FFT的区别是,它把频域数据分成两个子序列。
先将式
中的
划分成如下两部分:
因为
, 所以上式可以写成:
然后,把
分成偶数和奇数两个子序列,因为
,所以我们得到:
令
,
, 那么
和
可以看成是
和
在
上的傅立叶变换。
将上式应用于8点DFT,得到如下流程图:
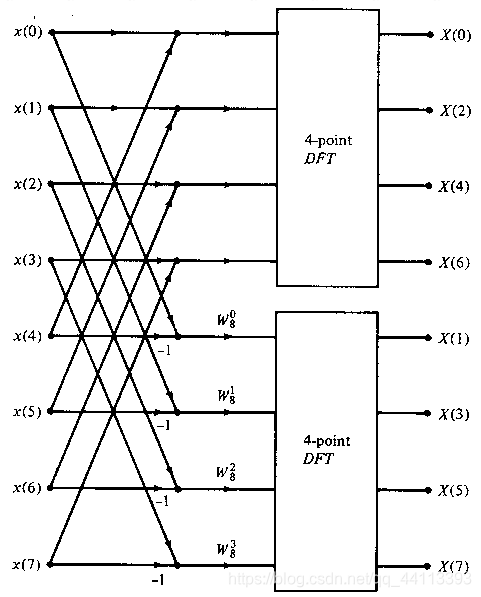
图6
注意旋转因子在每组蝶形图中只作用于下半部分的蝶形图,即
部分的
需要多乘一个旋转因子。
将上述分治过程递归应用于
和
,即上图中的两个4点DFT,并画出最后一层的2点DFT,可以得到最终的蝶形图如下:
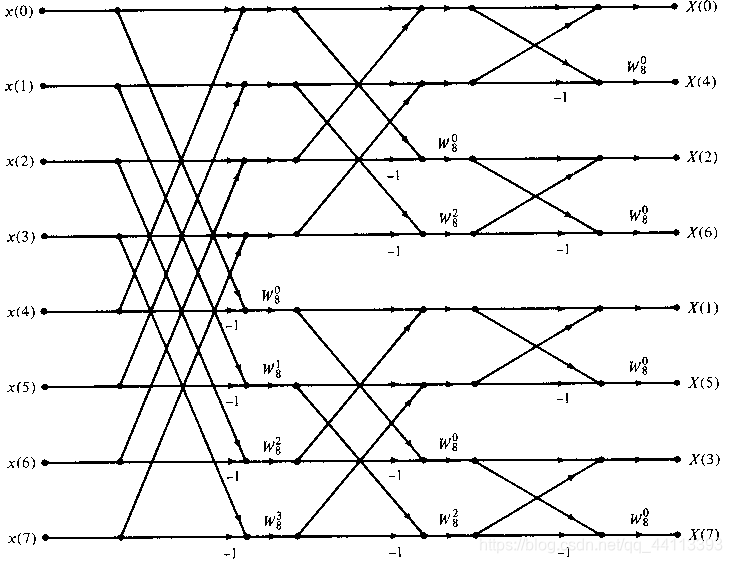
图7
DIF的好处在于它的输入数据不需要bit-reverse,这样在实际应用中就不需要对输入数据进行存储,有利于硬件实现。
DIF radix-4 FFT (频域抽取基-4 FFT)
最后再来看一个radix-4的DIF算法,这也是为了方便分析OAI中dft()函数的实现。
利用旋转因子的性质,经过推导可以把频域序列
划分成如下4个子序列:
如果令:
那么
就分别是
在
上的傅立叶变换。把上述简化应用于16点DFT,可以得到如下蝶形图:
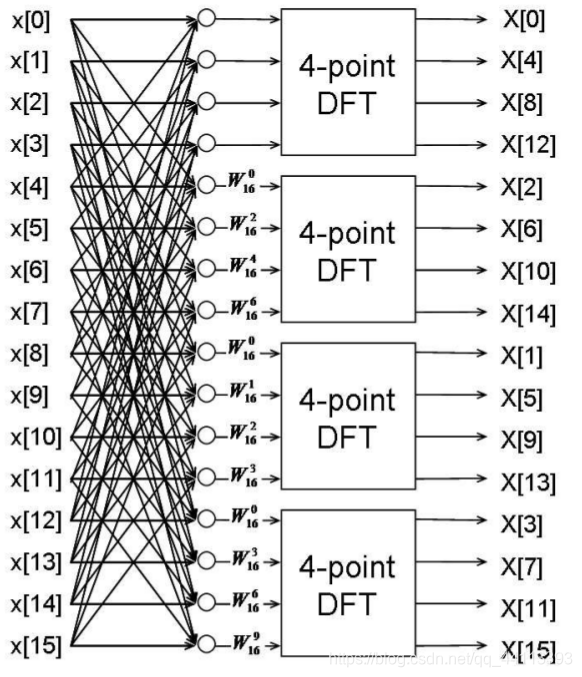
图8
图中没有标出时域数据对应的系数。
Radix-4的FFT基本运算单元是4点DFT,把上图中的4点DFT用蝶形图替代,得到最终的16点蝶形图,如下:

图9
同样没有标出输入数据的系数。
这就是DIF radix-4的16点FFT完整蝶形图。
OAI中FFT的实现
下面我们来看OAI中对FFT的实现方式。
5G中因为使用的调制方式仍然是OFDM,因此同样需要FFT。(OFDM和FFT之间的关系教材上应该有,如果有时间以后可以补一篇直观的解释)
只是5G的带宽更大,所需要的FFT size也更大,如下是LTE与5G的对比。
LTE:
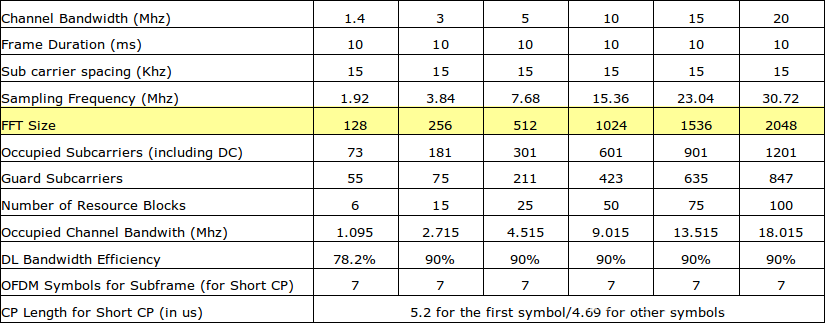
图10
5G:
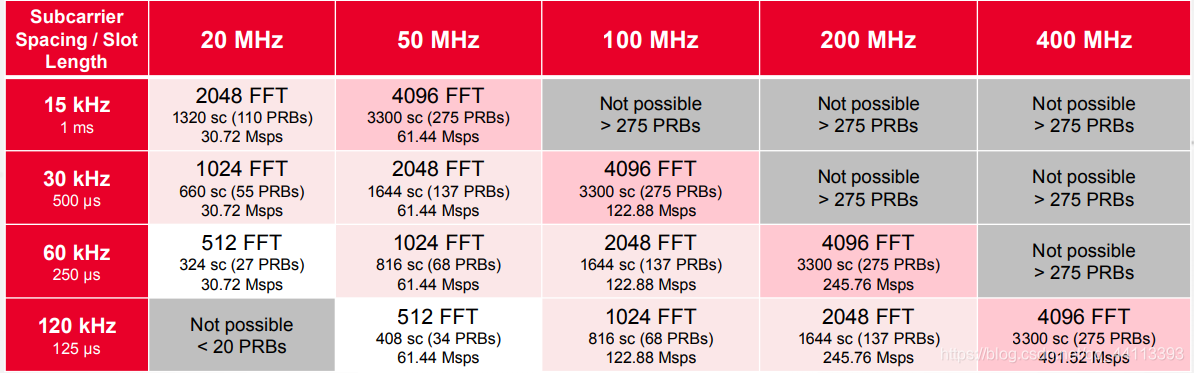
图11
可以看出来,5G在LTE的基础上又一次提高了FFT size到4096。但是FFT就是FFT,在算法上还是一样的。
OAI中实现了很多size的FFT,最基本的实现是16点DFT。4096点的DFT,最终也是通过调用dft16()实现的。因此,我们通过dft16()这个函数来分析OAI实现FFT的算法和代码。
先看会用到的全局变量:
//计算过程中符号反转用
const static int16_t conjugatedft[32] __attribute__((aligned(32))) = {-1,1,-1,1,-1,1,-1,1,-1,1,-1,1,-1,1,-1,1,-1,1};
//旋转因子*32767
const static int16_t tw16a[24] __attribute__((aligned(32))) = {32767,0,30272,12540,23169 ,23170,12539 ,30273,
32767,0,23169,23170,0 ,32767,-23170,23170,
32767,0,12539,30273,-23170,23170,-30273,-12539
};
const static int16_t tw16b[24] __attribute__((aligned(32))) = { 0,32767,-12540,30272,-23170,23169 ,-30273,12539,
0,32767,-23170,23169,-32767,0 ,-23170,-23170,
0,32767,-30273,12539,-23170,-23170,12539 ,-30273
};
dft16()函数的实现,第一阶段与上述radix-4的分析保持一致,可以参考图9蝶形图。不同点在于dft16()将输入数据分成4组,每次计算一组,这样无疑进一步加快了运算速度。
// First stage : 4 Radix-4 butterflies without input twiddles
//第一阶段的蝶形图计算,没有使用旋转因子,每一个x128[]的元素顺序存储4个输入数据的实部和虚部,即8个16位整数
x02t = _mm_adds_epi16(x128[0],x128[2]); //x[0]+x[8], x[1]+x[9], x[2]+x[10], x[3]+x[11]
x13t = _mm_adds_epi16(x128[1],x128[3]); //x[4]+x[12], x[5]+x[13], x[6]+x[14], x[7]+x[15]
xtmp0 = _mm_adds_epi16(x02t,x13t); //x[0]+x[4]+x[8]+x[12], x[1]+x[5]+x[9]+x[13], x[2]+x[6]+x[10]+x[14], x[3]+x[7]+x[11]+x[15],相当于上图中第一个4点DFT的输入
xtmp2 = _mm_subs_epi16(x02t,x13t); //x[0]+x[8]-x[4]-x[12], x[1]+x[9]-x[5]-x[13], x[2]+x[10]-x[6]-x[14], x[3]+x[11]-x[7]-x[15]
x1_flip = _mm_sign_epi16(x128[1],*(__m128i*)conjugatedft); //将x[4], x[5], x[6], x[7]的实部和虚的符号按照conjugatedft设置
x1_flip = _mm_shuffle_epi8(x1_flip,complex_shuffle); //将x[4], x[5], x[6], x[7]的实部和虚的符号的位置互换,与上一步合起来相当于*(-j)
x3_flip = _mm_sign_epi16(x128[3],*(__m128i*)conjugatedft);
x3_flip = _mm_shuffle_epi8(x3_flip,complex_shuffle); //与上一步合起来相当于x[12], x[13], x[14], x[15]分别*(-j)
x02t = _mm_subs_epi16(x128[0],x128[2]); //x[0]-x[8], x[1]-x[9], x[2]-x[10], x[3]-x[11]
x13t = _mm_subs_epi16(x1_flip,x3_flip); //-jx[4]+jx[12], -jx[5]+jx[13], -jx[6]+jx[14], -jx[7]+jx[15]
xtmp1 = _mm_adds_epi16(x02t,x13t); // x0 + x1f - x2 - x3f=(x[0],x[1],x[2],x[3])-j(x[4],x[5],x[6],x[7])-(x[8],x[9],x[10],x[11])+j(x[12],x[13],x[14],x[15])
xtmp3 = _mm_subs_epi16(x02t,x13t); // x0 - x1f - x2 + x3f=(x[0],x[1],x[2],x[3])+j(x[4],x[5],x[6],x[7])-(x[8],x[9],x[10],x[11])-j(x[12],x[13],x[14],x[15])
dft16()函数,在完成第一阶段的计算后,为了使输出结果保持顺序,同时也是为了重复使用第一阶段的计算过程,把第一阶段的输出结果进行了重新排序。这里的实现有些特殊,如果按照正常时域抽取DIT,这个重排序应该放到第一阶段之前; 而如果是频域抽取DIF,这个重排序应该放到最后结果出来之后。特殊实现的结果,就是代码重用性更佳。
参照radix-4的蝶形图,重新排序第一阶段输出结果的流程如下:
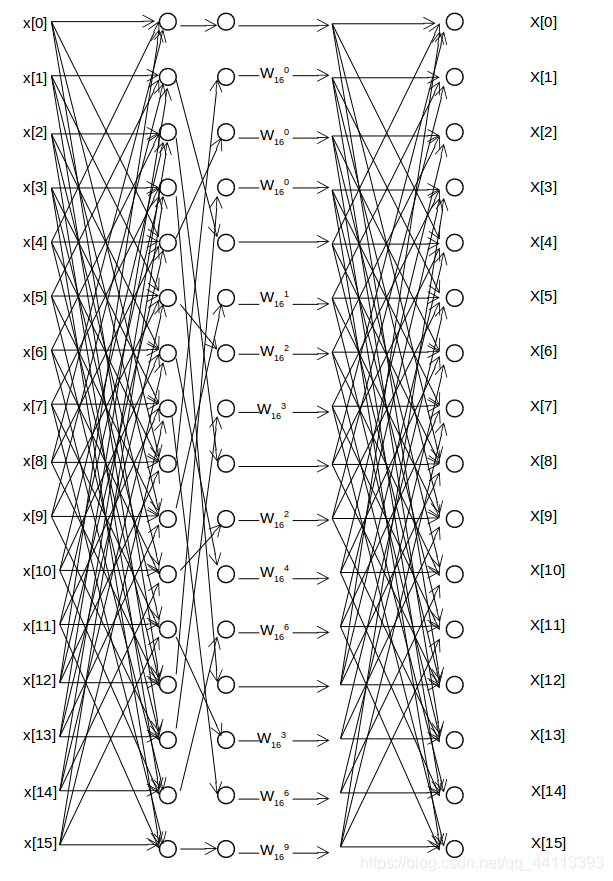
图12
可见,重新排序中间结果后,第二阶段的计算过程与第一阶段完全相同,因此可以复用第一阶段的代码。
对中间结果重新排序的代码:
//正常输出应该是bit-reverse的,但是这里调整了stage1的输出序列的顺序,使得stage2的输出序列是顺序的
ytmp0 = _mm_unpacklo_epi32(xtmp0,xtmp1);
ytmp1 = _mm_unpackhi_epi32(xtmp0,xtmp1);
ytmp2 = _mm_unpacklo_epi32(xtmp2,xtmp3);
ytmp3 = _mm_unpackhi_epi32(xtmp2,xtmp3);
xtmp0 = _mm_unpacklo_epi64(ytmp0,ytmp2);
xtmp1 = _mm_unpackhi_epi64(ytmp0,ytmp2);
xtmp2 = _mm_unpacklo_epi64(ytmp1,ytmp3);
xtmp3 = _mm_unpackhi_epi64(ytmp1,ytmp3);
然后是第二阶段蝶形图计算过程:
// Second stage : 4 Radix-4 butterflies with input twiddles
xtmp1 = packed_cmult2(xtmp1,tw16a_128[0],tw16b_128[0]);
xtmp2 = packed_cmult2(xtmp2,tw16a_128[1],tw16b_128[1]);
xtmp3 = packed_cmult2(xtmp3,tw16a_128[2],tw16b_128[2]);
x02t = _mm_adds_epi16(xtmp0,xtmp2);
x13t = _mm_adds_epi16(xtmp1,xtmp3);
y128[0] = _mm_adds_epi16(x02t,x13t);
y128[2] = _mm_subs_epi16(x02t,x13t);
x1_flip = _mm_sign_epi16(xtmp1,*(__m128i*)conjugatedft);
x1_flip = _mm_shuffle_epi8(x1_flip,_mm_set_epi8(13,12,15,14,9,8,11,10,5,4,7,6,1,0,3,2));
x3_flip = _mm_sign_epi16(xtmp3,*(__m128i*)conjugatedft);
x3_flip = _mm_shuffle_epi8(x3_flip,_mm_set_epi8(13,12,15,14,9,8,11,10,5,4,7,6,1,0,3,2));
x02t = _mm_subs_epi16(xtmp0,xtmp2);
x13t = _mm_subs_epi16(x1_flip,x3_flip);
y128[1] = _mm_adds_epi16(x02t,x13t); // x0 + x1f - x2 - x3f
y128[3] = _mm_subs_epi16(x02t,x13t); // x0 - x1f - x2 + x3f
可以看出来,除了需要乘上旋转因子之外,剩下的计算代码与第一阶段的计算过程完全一致。
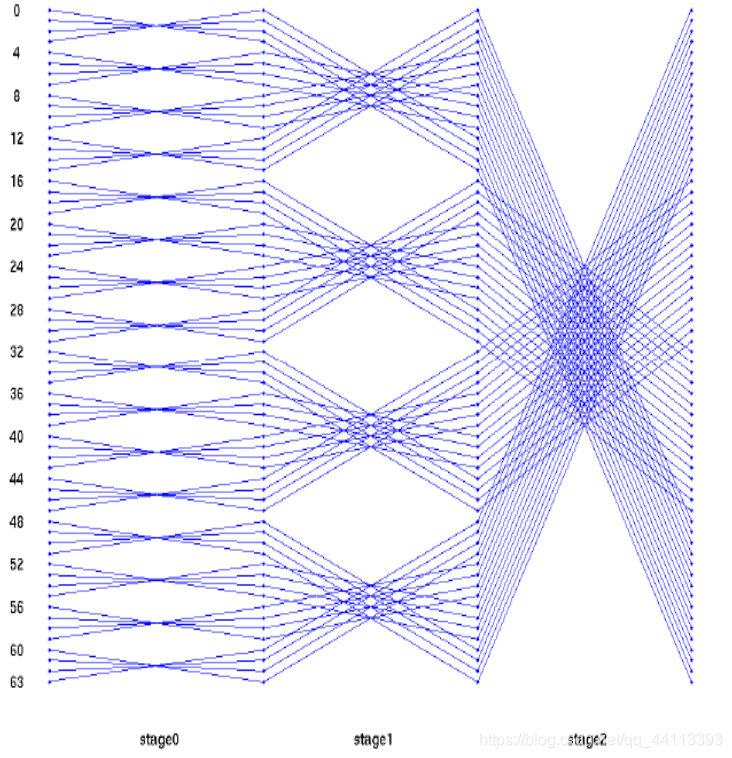
OAI中更高阶的DFT计算是中dft16()的基础上采用时域抽取的方法实现的,以dft4096为例:
void dft4096(int16_t *x,int16_t *y,int scale)
{
simd_q15_t xtmp[1024],ytmp[1024],*tw4096_128p=(simd_q15_t *)tw4096,*x128=(simd_q15_t *)x,*y128=(simd_q15_t *)y,*y128p=(simd_q15_t *)y;
simd_q15_t *ytmpp = &ytmp[0];
int i,j;
for (i=0,j=0; i<1024; i+=4,j++) {
transpose16_ooff(x128+i,xtmp+j,256); //输入数据重排序
}
//计算4个dft2014
dft1024((int16_t*)(xtmp),(int16_t*)(ytmp),1);
dft1024((int16_t*)(xtmp+256),(int16_t*)(ytmp+256),1);
dft1024((int16_t*)(xtmp+512),(int16_t*)(ytmp+512),1);
dft1024((int16_t*)(xtmp+768),(int16_t*)(ytmp+768),1);
//计算蝶形图
for (i=0; i<256; i++) {
bfly4(ytmpp,ytmpp+256,ytmpp+512,ytmpp+768,
y128p,y128p+256,y128p+512,y128p+768,
tw4096_128p,tw4096_128p+256,tw4096_128p+512);
tw4096_128p++;
y128p++;
ytmpp++;
}
放一个基-4的DIT FFT蝶形图,对照代码直观上感受一下吧:
参考来源:
http://www.sharetechnote.com/
http://www.cmlab.csie.ntu.edu.tw/cml/dsp/training/coding/transform/fft.html
http://face2ai.com/DIP-2-3-FFT算法理解与c语言的实现/
https://www.semanticscholar.org/paper/The-Hybrid-Architecture-Parallel-Fast-Fourier-Palmer-Nelson/e6867a85e61e1228063b4a6e40d0af8c8f20de08
https://www.keysight.com/upload/cmc_upload/All/5GRadioValidation.pdf
http://www.iraj.in/journal/journal_file/journal_pdf/6-33-139038874964-67.pdf