——个人笔记
——个人笔记
一系列:
python爬虫(一)
python爬虫(二)
python爬虫(三)
python爬虫(四)
python爬虫(五)
python爬虫(六)
python爬虫(七)
python爬虫(八)
python爬虫(九)
python爬虫(十一)
爬虫框架Scrapy
-
我们可以爬虫框架Scrapy,Scrapy的整个结构:
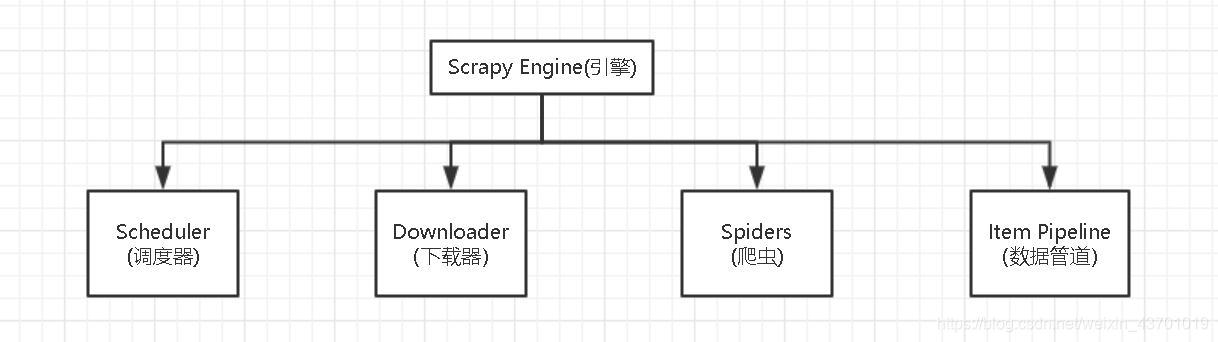
下面大概介绍一下结构:
Scheduler(调度器)部门主要负责处理引擎发送过来的requests对象(即网页请求的相关信息集合,包括params,data,cookies,request headers…等),会把请求的url以有序的方式排列成队,并等待引擎来提取(功能上类似于gevent库的queue模块)。Downloader(下载器)部门则是负责处理引擎发送过来的requests,进行网页爬取,并将返回的response(爬取到的内容)交给引擎。它对应的是爬虫流程【获取数据】这一步。
Spiders(爬虫)部门是公司的核心业务部门,主要任务是创建requests对象和接受引擎发送过来的response(Downloader部门爬取到的内容),从中解析并提取出有用的数据。它对应的是爬虫流程【解析数据】和【提取数据】这两步。
Item Pipeline(数据管道)部门则是公司的数据部门,只负责存储和处理Spiders部门提取到的有用数据。这个对应的是爬虫流程【存储数据】这一步。
Downloader Middlewares(下载中间件)的工作相当于下载器部门的秘书,比如会提前对引擎大boss发送的诸多requests做出处理。
Spider Middlewares(爬虫中间件)的工作则相当于爬虫部门的秘书,比如会提前接收并处理引擎大boss发送来的response,过滤掉一些重复无用的东西。
-
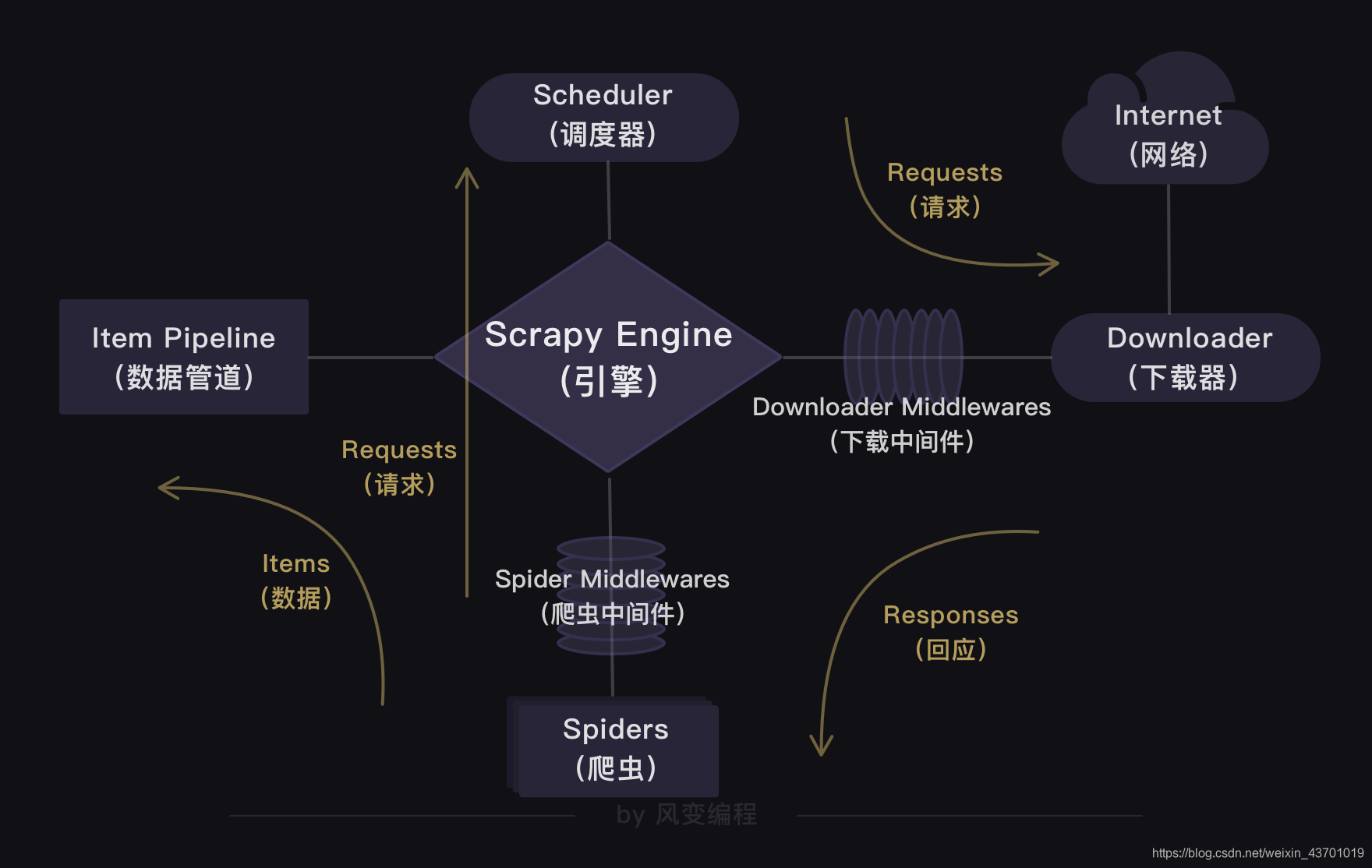
大致流程:
准备工作
-
导入
在终端输入命令:pip install scrapy。 -
创建Scrapy项目
接着在本地电脑终端(windows:Win+R,输入cmd)跳转到你想要保存项目的目录下。比如你想跳转到E盘里名为Python文件夹中的Pythoncode子文件夹。你需要输入e:,就会跳转到e盘,再输入cd Python,就能跳转到Python文件夹。接着输入cd Pythoncode,就能跳转到Python文件夹里的Pythoncode子文件夹。最后,再输入一行能帮我们创建Scrapy项目的命令:scrapy startproject douban,douban就是Scrapy项目的名字(可以自己命名也就是命令中的douban可以自己修改)。按下enter键,一个Scrapy项目就创建成功了。你打开文件夹就可以找到刚刚创建的Scrapy项目了:

-
创建爬虫文件(spiders)
在我们创建的Scrapy项目中spiders是放置爬虫的目录。我们可以在spiders这个文件夹里创建爬虫文件。
-
修改设置
点击settings.py文件,你能在里面找到如下的默认设置代码:# Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'douban (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = True把USER _AGENT的注释取消(删除#),然后替换掉user-agent的内容,就是修改了请求头。和把ROBOTSTXT_OBEY=True改成ROBOTSTXT_OBEY=False,就是把遵守robots协议换成无需遵从robots协议,这样Scrapy就能不受限制地运行。
修改后如下:# Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36' # Obey robots.txt rules ROBOTSTXT_OBEY = False
我们需要取消DOWNLOAD_DELAY = 0这行的注释(删掉#)。DOWNLOAD_DELAY翻译成中文是下载延迟的意思,这行代码可以控制爬虫的速度。最好设置一下这个。
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 0.5#这里本来是被注释了
-
Scrapy的大概过程图示(0和3我们已经在准备工作完成了):

-
定义item(数据)
我们点击items.py,我们看见里面让我们定义数据,形式如name = scrapy.Field()那么我们就可以定义自己的要爬取的数据的名字。直接写自己定义数据名字 = scrapy.Field()就行了。 -
编写spiders文件(爬虫文件)
创建我们已经在准备工作完成了,现在就要编写他了。首先我们要导入:import scrapy import bs4 from ..items import DoubanItem前两个不用说,第三个就是导入刚刚我们item里面的DoubanItem类(也就似乎我们刚刚写的数据类型。而且因为是items在pachong.py的上一级目录,所以要用
..items,这是一个固定用法。定义一个爬虫类:
class DoubanSpider(scrapy.Spider): #定义一个爬虫类DoubanSpider。 name = 'douban' #定义爬虫的名字为douban。 allowed_domains = [url(不包含http://)] #定义爬虫爬取网址的域名,防止弹出广告之类的东西,影响爬取数据 #比如我下面 start_urls是要爬取豆瓣里面的书籍,那么这里直接 #就写book.douban.com,这里不要加上https://, start_urls = [] #定义起始网址,即要爬取的网址 for x in range(3): url = (利用循环改变url某个参数实现翻页爬取) start_urls.append(url) #把所有要爬取的网址添加进start_urls。 #下面是处理爬取的信息的函数,下面会再具体实现 def parse(self, response): print(response.text)实现爬虫类里面的parse函数:
def parse(self, response): #parse是默认处理response的方法。 bs = bs4.BeautifulSoup(response.text,'html.parser') #用BeautifulSoup解析response。 datas = bs.find_all('tr',class_="item") #用find_all提取<tr class="item">元素 。 for data in datas: #遍历data。 item = DoubanItem() #实例化DoubanItem这个类。 item['title'] = data.find_all('a')[1]['title'] #提取出数据放回DoubanItem类的title属性里。 item['publish'] = data.find('p',class_='pl').text #提取出数据放回DoubanItem类的publish里。 item['score'] = data.find('span',class_='rating_nums').text #提取出放回DoubanItem类的score属性里。 #可以用print输出一下 yield item #yield item是把获得的item传递给引擎。yield语句不会结束函数,且能多次返回信息。
如果从第一个网站爬取到链接继续爬取,那么我们可以用到yield scrapy.Request(real_url, callback=self.parse_job),第一个参数是继续爬取的url,第二个参数是更改调用的默认处理response。 -
运行方式
想要运行Scrapy有两种方法,一种是在本地电脑的终端跳转到scrapy项目的文件夹(跳转方法:cd+文件夹的路径名),然后输入命令行:scrapy crawl douban(douban 就是我们爬虫的名字)。另一种运行方式需要我们在最外层的大文件夹里新建一个main.py文件(与scrapy.cfg同级)。我们只需要在这个main.py文件里,输入以下代码,点击运行,Scrapy的程序就会启动。from scrapy import cmdline #导入cmdline模块,可以实现控制终端命令行。 cmdline.execute(['scrapy','crawl','douban']) #用execute()方法,输入运行scrapy的命令。