前言
大学毕业到现在已经快一年了,这一年时间里,我在家里待了半年。科班出身的我不太适合做销售,最后还是决定做一名程序员,虽然大学里C、java、JavaScript、switf学得不咋的,但是我现在的头发挺多的。这半年时间里,我有每天学Python到凌晨3、4点时候,也有天天熬夜写Bug的时候。
到现在为止,我都还没学到Python爬虫阶段。但我对爬虫充满了好奇,想要快速掌握点知识,我就尝试着一点点百度一点点摸索。今天为大家分享一下,我这个爬虫渣渣师是如何写爬虫项目的。
注:本文只做技术交流,爬取到的图片切勿用于商业用途。
1. 网页分析
对于爬虫程序来说,首先是要先确定方向。我想要的是网易LOFTER上,摄影师的图片,不仅是图片而且还是为压缩的原图。注:网易LOFTER上面的图片有些是无法手动保存在,因为作者设置了权限,及时手动保存了也不是原图,它会有网易LOFTER的水印。
获取用户的图片我们会遇到这些问题:
- 如何获取一位用户的所有图片?
答:网易LOFTER提供了用户归档页,我们可以轻松地进行数据分析 - 那我们是从归档页获取用户的所有图片吗?
答:不是,归档页只是我们获取用户图片的目录,我们真正要需要的是用户发表图片的详情页面 - 那我们在归档页分析什么?
答:我们需要详情页面的url,在这里能够获取到 - 如何获取不同用户的归档页
答:不同用户拥有着不同的三级域名 - 爬虫过程中是否需要各种验证?
答:从用户归档页面采集数据不需要验证 - 如何防止爬虫遇到的403错误?
答:设置请求延时,或使用代理IP。这里我们使用了请求延时
1.1 HTML分析
不同用户拥有不同的三级域名,例如:___.lofter.com/view
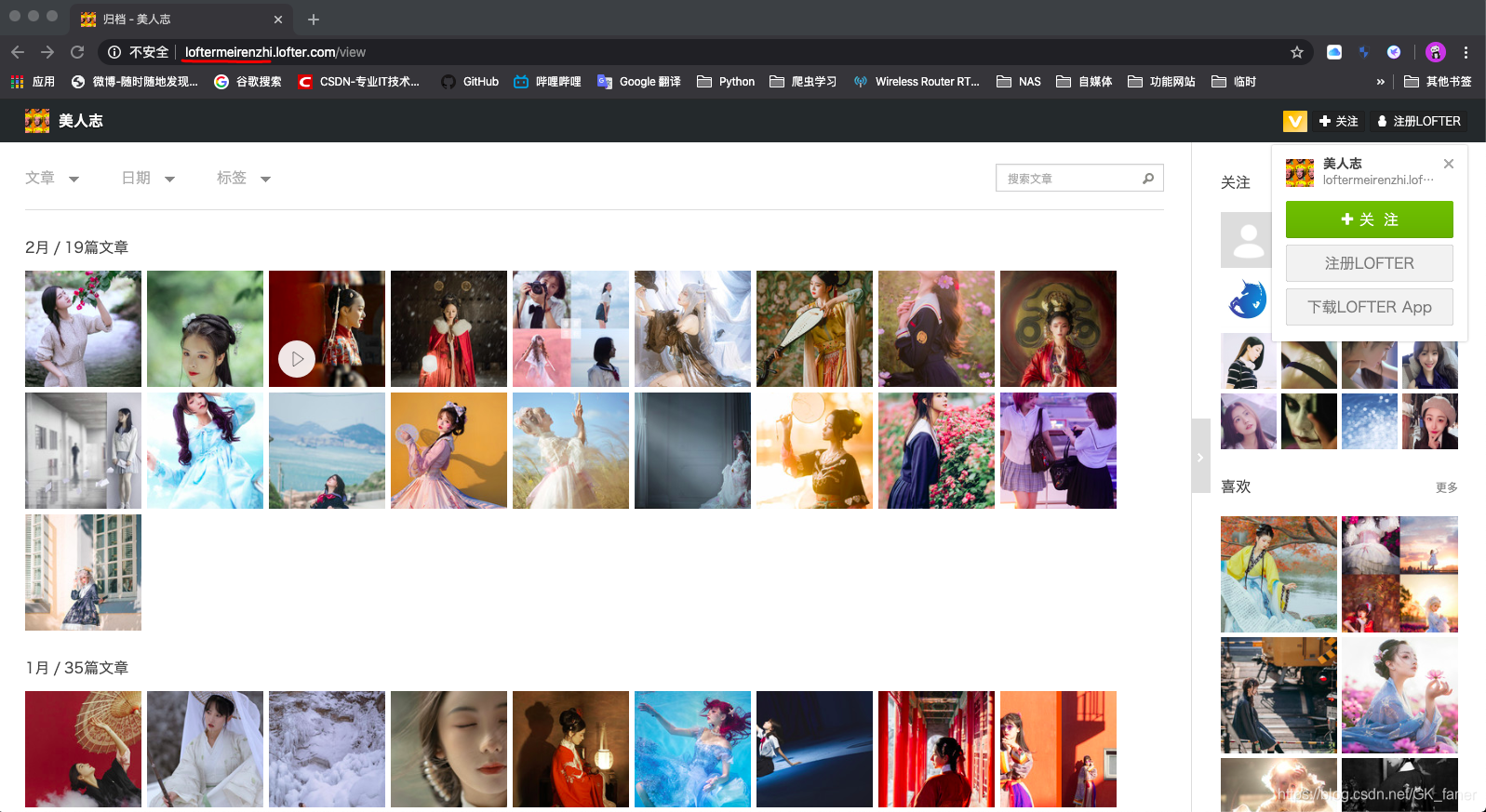
用户图片太多,打开归档页时,所有图片不会全部加载出来,网易使用了DWR技术,当我们往下浏览网页时,会自动加载DWR数据,这样我们就能看到其他图片了。

小结:DWR包含图片数据
1.2 DWR分析
分析第一个DWR数据,可以知道刚打开归档页面的数据情况,不难发现,每一个dwr最多显示50条页面数据。我取几条数据展示一下:
//#DWR-INSERT
//#DWR-REPLY
var s0={};var s50={};var s1={};var s51={};var s2={};var s52={};var s3={};var s53={};var s4={};var s54={};var s5={};var s55={};var s6={};var s56={};var s7={};var s57={};var s8={};var s58={};var s9={};var s59={};var s10={};var s60={};var s11={};var s61={};var s12={};var s62={};var s13={};var s63={};var s14={};var s64={};var s15={};var s65={};var s16={};var s66={};var s17={};var s67={};var s18={};var s68={};var s19={};var s69={};var s20={};var s70={};var s21={};var s71={};var s22={};var s72={};var s23={};var s73={};var s24={};var s74={};var s25={};var s75={};var s26={};var s76={};var s27={};var s77={};var s28={};var s78={};var s29={};var s79={};var s30={};var s80={};var s31={};var s81={};var s32={};var s82={};var s33={};var s83={};var s34={};var s84={};var s35={};var s85={};var s36={};var s86={};var s37={};var s87={};var s38={};var s88={};var s39={};var s89={};var s40={};var s90={};var s41={};var s91={};var s42={};var s92={};var s43={};var s93={};var s44={};var s94={};var s45={};var s95={};var s46={};var s96={};var s47={};var s97={};var s48={};var s98={};var s49={};var s99={};s0.blogId=487177737;s0.cctype=1;s0.collectionId=0;s0.dayOfMonth=26;s0.id=7652677484;s0.month=1;s0.noteCount=36;s0.reblog=true;s0.tagCount=9;s0.time=1582713720000;s0.type=2;s0.valid=0;s0.values=s50;s0.year=2020;
s50.imgurl="http://imglf6.nosdn0.126.net/img/Y3RDR3J2WmlKOHRxakNIMjBMVWg1V0lwVnVMQ08zMWI5SCsvcER4WWY4TTRPc0MrS0xvY0NRPT0.jpg?imageView&thumbnail=164y164&enlarge=1&quality=90&type=jpg";s50.permalink="1d09be09_1c822976c";s50.noticeLinkTitle="\u5927\u738B\u4E5D\u5343\u5C81: \u7EA2\u82B1\u7EFF\u53F6\u548C\u7F8E\u4EBA";
s1.blogId=487177737;s1.cctype=1;s1.collectionId=0;s1.dayOfMonth=26;s1.id=7652682322;s1.month=1;s1.noteCount=35;s1.reblog=true;s1.tagCount=7;s1.time=1582709760000;s1.type=2;s1.valid=0;s1.values=s51;s1.year=2020;
s51.imgurl="http://imglf3.nosdn0.126.net/img/Q2xScm9YbUlkREp0c1QxdjkyalJ6ZFl2S3E5aDRYZkhxM2d2aTBaektSaXRQbS9UQUNsM1JBPT0.jpg?imageView&thumbnail=164y164&enlarge=1&quality=90&type=jpg";s51.permalink="1d09be09_1c822aa52";s51.noticeLinkTitle="\u6DF3Mirai: / \u5C4F \u8749 /...";
s2.blogId=487177737;s2.cctype=3;s2.collectionId=0;s2.dayOfMonth=26;s2.id=7652686417;s2.month=1;s2.noteCount=67;s2.reblog=true;s2.tagCount=6;s2.time=1582708163906;s2.type=4;s2.valid=0;s2.values=s52;s2.year=2020;
s52.imgurl="http://imglf5.nosdn0.126.net/img/ZWZ4OTlOUU9kYng4L2RZRmxhTmY0bDMxcVFNWkVmcGtFbllLUjlTSDRuY2NrUWRWU0dhdW9nPT0.jpg?imageView&thumbnail=164y164&enlarge=1&quality=90&type=jpg";s52.permalink="1d09be09_1c822ba51";s52.noticeLinkTitle="\u963F\u73C2\u662F\u53EA\u6444\u5F71\u72EE\u5440: \u4E3A\u5F97\u4F0A\u4EBA\u4E00...";
分析第一条DWR数据:
s50.imgurl="http://imglf6.nosdn0.126.net/img/Y3RDR3J2WmlKOHRxakNIMjBMVWg1V0lwVnVMQ08zMWI5SCsvcER4WWY4TTRPc0MrS0xvY0NRPT0.jpg?imageView&thumbnail=164y164&enlarge=1&quality=90&type=jpg";s50.permalink="1d09be09_1c822976c";s50.noticeLinkTitle="\u5927\u738B\u4E5D\u5343\u5C81: \u7EA2\u82B1\u7EFF\u53F6\u548C\u7F8E\u4EBA";
s1.blogId=487177737;s1.cctype=1;s1.collectionId=0;s1.dayOfMonth=26;s1.id=7652682322;s1.month=1;s1.noteCount=35;s1.reblog=true;s1.tagCount=7;s1.time=1582709760000;s1.type=2;s1.valid=0;s1.values=s51;s1.year=2020;
我们可以得到:
s50.imgurl="http://imglf6.nosdn0.126.net/img/Y3RDR3J2WmlKOHRxakNIMjBMVWg1V0lwVnVMQ08zMWI5SCsvcER4WWY4TTRPc0MrS0xvY0NRPT0.jpg?imageView&thumbnail=164y164&enlarge=1&quality=90&type=jpg";
# 压缩图片url--->http://imglf6.nosdn0.126.net/img/Y3RDR3J2WmlKOHRxakNIMjBMVWg1V0lwVnVMQ08zMWI5SCsvcER4WWY4TTRPc0MrS0xvY0NRPT0.jpg?imageView&thumbnail=164y164&enlarge=1&quality=90&type=jpg
# 原图url--->http://imglf6.nosdn0.126.net/img/Y3RDR3J2WmlKOHRxakNIMjBMVWg1V0lwVnVMQ08zMWI5SCsvcER4WWY4TTRPc0MrS0xvY0NRPT0.jpg
s50.permalink="1d09be09_1c822976c"
# 详情页面url数据:1d09be09_1c822976c
# 完整的详情页url:http://loftermeirenzhi.lofter.com/post/1d09be09_1c822976c
s50.noticeLinkTitle="\u5927\u738B\u4E5D\u5343\u5C81:\u7EA2\u82B1\u7EFF\u53F6\u548C\u7F8E\u4EBA";
# Unicode编码标题
# 大王九千岁:红花绿叶和美人
s1.blogId=487177737; # 用户博客id
s1.time=1582709760000; # Unix时间(用户发表) 2020-02-26 17:36:00
小结:这一步我们得到了这些有用的数据(s50.permalink、s1.time)
1.3 数据整合
有了第一个DWR的数据,我们就可以获取到其他DWR数据,以及所有详情页的url。为了获取到其他DWR数据我们又要进行分析了。
当我们浏览用户归档页时,可以通过鼠标、触摸板、键盘等手动方式获取到其他的DWR数据,在程序中我们可以这样获取。
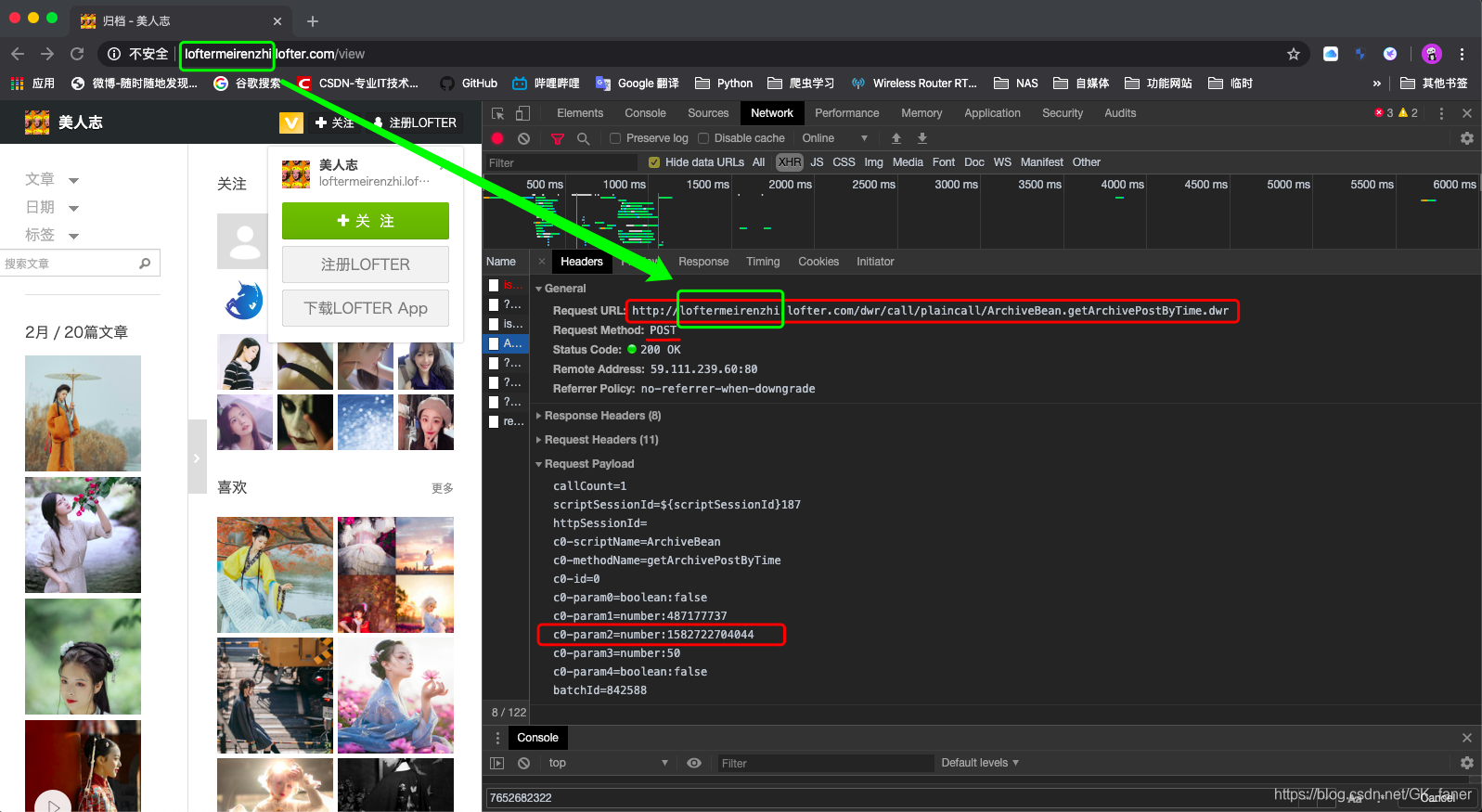
通过获取当前的时间来获取最新(第一个)DWR数据,最后再通过第一个DWR中最后一个时间来获取其他的DWR,直到无DWR数据为止。
获取第一个DWR数据:
import time
import requests
url = 'http://loftermeirenzhi.lofter.com/dwr/call/plaincall/ArchiveBean.getArchivePostByTime.dwr'
payload = {
"callCount": "1",
"scriptSessionId": "${scriptSessionId}187",
# "httpSessionId": "",
"c0-scriptName": "ArchiveBean",
"c0-methodName": "getArchivePostByTime",
"c0-id": "0",
"c0-param2": "number:%s" % str(time.time() * 1000)[:13], # 获取当前时间
"c0-param0": "boolean:false",
"c0-param1": "number:487177737", # 用户博客id
"c0-param3": "number:50",
"c0-param4": "boolean:false",
"batchId": "1"
}
headers = {
# "Content-Type": "text/plain",
'Referer': 'https://loftermeirenzhi.lofter.com/view',
# "Host": "loftermeirenzhi.lofter.com",
# "Origin": "https://loftermeirenzhi.lofter.com",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36 ",
}
dwr = requests.post(url, data=payload, headers=headers).text
小结:我们通过所有的DWR数据可以获取到所有详情页url
2. 采集图片URL
当我们拥有了详情页的url,就可以获取到详情页数据了。为了避免403错误,我们需要设置等待时间来获取网页。
import time
time.sleep(0.5) # 设置延时
这里我们简单分析一下详情页html:
无论是a标签还是img标签,这里都有我们需要的图片url,那我们就直接盘它吧。
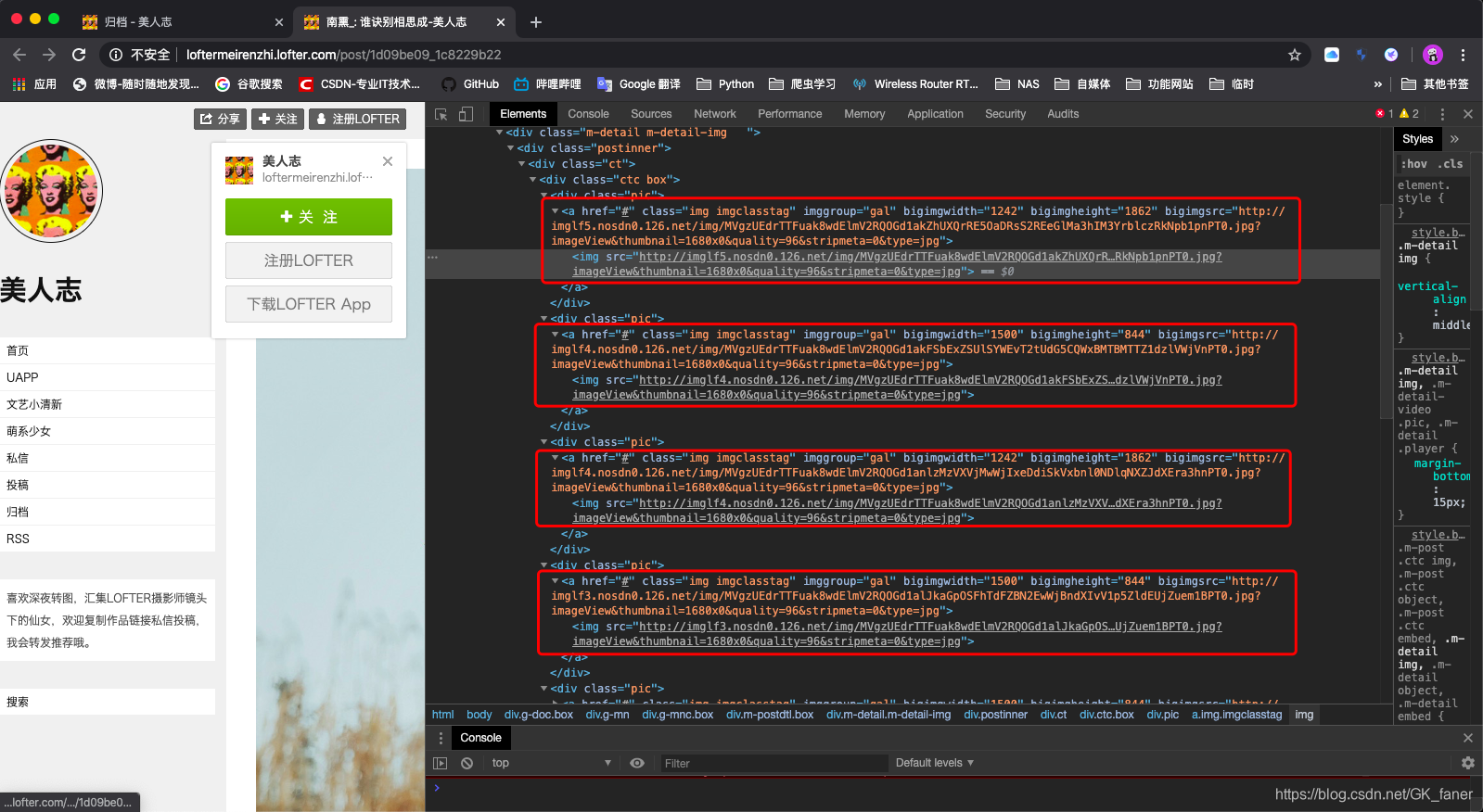
# 这里使用了两条xpath来匹配,因为有些网页的html代码有差异
images1 = html.xpath("//a[@class='imgclasstag']") # <class 'list'>
images2 = html.xpath("//a[@class='img imgclasstag']") # <class 'list'>
# 获取原图url
# 图片 .jpg、.png、.gif、.jpeg
image_url = re.search(r"(.*net/img/.*\.[jnpegif]{3,4})?",image.attrib['bigimgsrc']).group(1)
有了原图url就可以下载了。
3. 部分代码分享
我的爬虫流程:
- 获取归档页html,获取其中的用户id(并把html保存在本地,方便第二次运行)
- 通过用户id,以及当前时间,获取第一个dwr数据
- 通过第一个dwr数据中的最后一个时间获取其他的dwr数据(这里我保存了dwr数据,但是意义不大。当用户更新内容后,dwr数据将被重写)
- 提取dwr数据并匹配所有详情页url(并把html保存在本地,方便第二次运行)
- 获取所有详情页面html(并把html保存在本地,方便第二次运行)
- 获取所有原图url(并把url保存在本地,方便第二次运行)
- 下载原图
def collection_details_page_url_module(self):
"""采集归档页html-DWR-详情页URL"""
for user_info in self.user_info_list:
self.init_path(user_info) # 初始化路径
self.create_directory(self.g_parent_path) # 检查或创建目录
self.create_directory(self.parent_path) # 检查或创建目录
print("\n----开始获取%s-【归档页】-【DWR】-【详情页URL】----" % self.user_info)
# TODO 获取id
if not self.check_file(self.archive_html_path):
self.write_html()
# 读取本地信息
html = self.read_file(self.archive_html_path)
html = etree.HTML(html)
try:
self.get_id(html)
except BaseException:
print("再次获取html及id")
self.write_html()
html = self.read_file(self.archive_html_path)
html = etree.HTML(html)
self.get_id(html)
else:
pass
print("\n开始采集dwr...")
url = self.dwr_headers(self.user_id)
self.get_new_dwr(url)
self.get_other_dwr(url)
# TODO 匹配url
print("\n获取详情页面url...")
dwr = self.read_file(self.dwr_path)
permalinks = re.findall("""permalink="([0-9a-z_]*)";""", dwr)
# 检查是否有文件存在
# 为了保证获取到最新数据,每次运行建议删除本地的详情页url数据(htmlURL.json)
if not self.check_file(self.url_path):
self.write_permalink_dict(permalinks)
# 验证数据完整性
if not len(json.load(open(self.url_path))) == len(permalinks):
print("数据不完整...再次采集...")
self.write_permalink_dict(permalinks)
print("%s :\n【归档页html】\n【DWR】\n【详情页URL】\n全部获取成功!" % user_info)
总结
注:本文只做技术交流,爬取到的图片切勿用于商业用途。
这是一个很简单的爬虫项目,通过分析,我们只要有用户的三级域名就可以爬取多个用户的原图了。
如果你对这个项目感兴趣,欢迎一起交流学习,为了方便学习我将这个项目放在了GitHub上面,欢迎下载。
