版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
—— 个人笔记
一系列:
python爬虫(二)
python爬虫(三)
python爬虫(四)
python爬虫(五)
python爬虫(六)
python爬虫(七)
python爬虫(八)
python爬虫(九)
python爬虫(十)
python爬虫(十一)
爬虫概念

- 解析:
第0步:获取数据。爬虫程序会根据我们提供的网址,向服务器发起请求,然后返回数据。
第1步:解析数据。爬虫程序会把服务器返回的数据解析成我们能读懂的格式。
第2步:提取数据。爬虫程序再从中提取出我们需要的数据。
第3步:储存数据。爬虫程序把这些有用的数据保存起来,便于你日后的使用和分析。
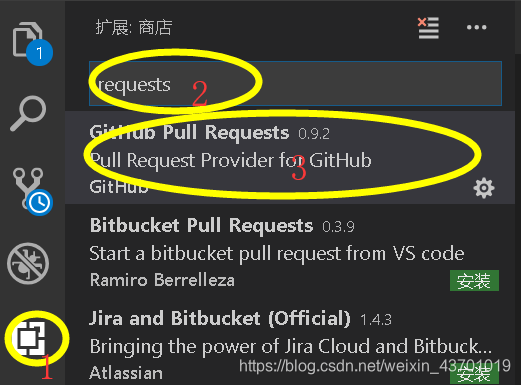
首先要在vscode(这个自己去官网下载就行了)还要加python的解析器下载requests库:
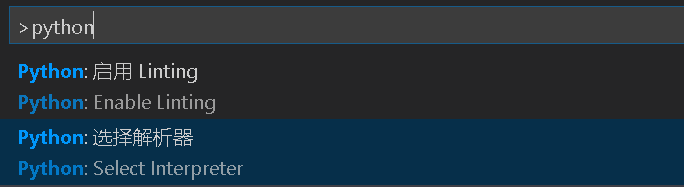
- shift+ctrl+p 然后按照下图,选择解析器
- 这个是下载requests包的步骤
-
获取数据
-
用requests.get(‘URL’)来从URL(地址)中获取数据,并返回Response对象。
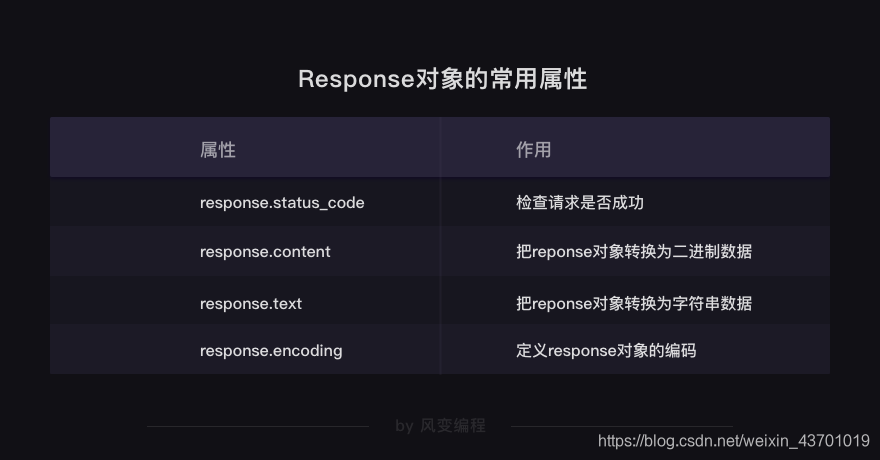
-
下载一个图片
import requests res = requests.get('https://xxxx.com/xxx.png') #发出请求,并把返回的结果放在变量res中 pic=res.content #把Reponse对象的内容以二进制数据的形式返回 photo = open('ppt.jpg','wb') #新建了一个文件ppt.jpg,这里的文件没加路径,它会被保存在程序运行的当前目录下。 #图片内容需要以二进制wb读写。 photo.write(pic) #获取pic的二进制内容 photo.close() -
下载一个文本
import requests res = requests.get('https://xxxx.com/xxx') #发出请求,并把返回的结果放在变量res中 novel=res.text #把Reponse对象的内容以字符串的形式返回 #这假设下载一个小说 novelfile = open('novel.text','w') #新建了一个文件novel.text,这里的文件没加路径,它会被保存在程序运行的当前目录下。 novelfile.write(novel) #获取pic的二进制内容 novelfile.close()
-
别随意就去爬,这是有Robots协议的哦,规定了哪些能给你爬哪些不行。
爬之前都去看看网址的协议规定哦,查找网址的Robots协议。