版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
—— 个人笔记
- 一系列:
python爬虫(一)
python爬虫(二)
python爬虫(三)
python爬虫(五)
python爬虫(六)
python爬虫(七)
python爬虫(八)
python爬虫(九)
python爬虫(十)
python爬虫(十一)
-
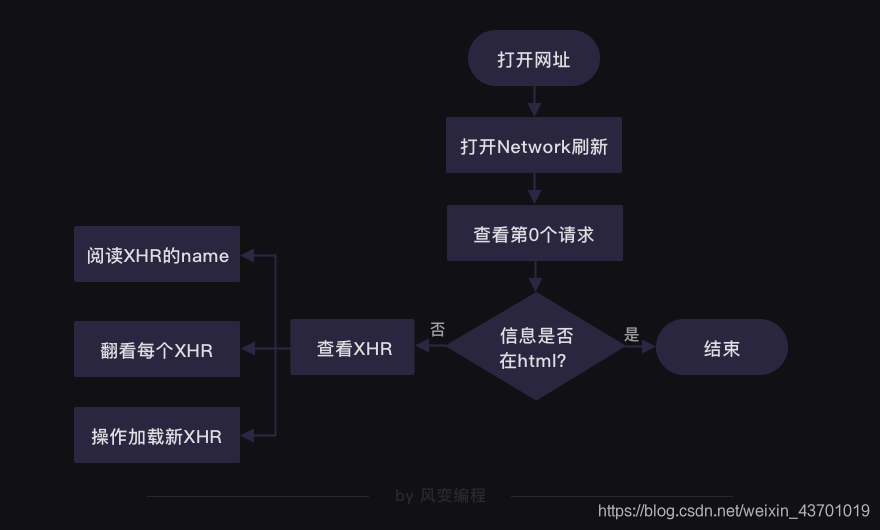
我们爬取时,首先查看网页信息所在的URL,然后看其XHR哪个才是包含我们所需信息,然后我们可以看其Query String Parametres(network中点开相关的XHR,里面的headers),有什么属性时变化的根据变化值可以进行翻页,继续爬取的操作,必要时我们还要对Request Headers(和Query String Parametres同个位置)伪装一下。
-
本来我们请求的url直接就复制,很长一大串完全看不懂,其实url时一个固定部分(访问的网址)+参数(Query String Parametres),两者通常用?连接。我们复制的url后面部分其实就是参数的utf-8编码,可观性不高。
-
下面时把请求开头和参数封装为字典完整代码(对三的补充):
import requests
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
headers = {
'origin':'https://y.qq.com',
# 请求来源,本案例中其实是不需要加这个参数的,只是为了演示
'referer':'https://y.qq.com/n/yqq/song/004Z8Ihr0JIu5s.html',
# 请求来源,携带的信息比“origin”更丰富,本案例中其实是不需要加这个参数的,只是为了演示
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
# 标记了请求从什么设备,什么浏览器上发出
}
# 伪装请求头
params = {
'ct':'24',
'qqmusic_ver': '1298',
'new_json':'1',
'remoteplace':'sizer.yqq.song_next',
'searchid':'64405487069162918',
't':'0',
'aggr':'1',
'cr':'1',
'catZhida':'1',
'lossless':'0',
'flag_qc':'0',
'p':1,
'n':'20',
'w':'周杰伦',
'g_tk':'5381',
'loginUin':'0',
'hostUin':'0',
'format':'json',
'inCharset':'utf8',
'outCharset':'utf-8',
'notice':'0',
'platform':'yqq.json',
'needNewCode':'0'
}
# 将参数封装为字典
res_music = requests.get(url,headers=headers,params=params)
# 发起请求,填入请求头和参数
# 后面操作一样参考(三)
总结:
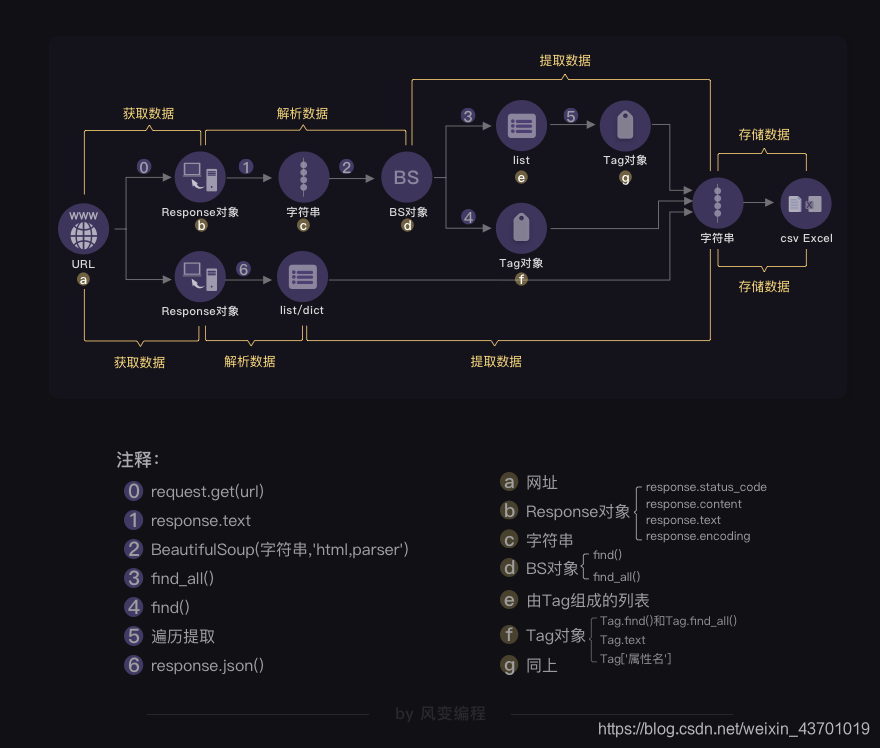
比较简单的直接右键检查就能看到的而且能爬取下来有效信息,那么就会用上面的BS路线,如果这个方法行不通,那么我们就会去network找到相对应的服务,找到所对应的url来获取信息(记得伪装爬虫表头哦),通常都会用到第二条路。看图: