专栏——TensorFlow学习笔记
一、什么是RNN
循环神经网络(Recurrent Neural Network, RNN) 是一种适宜于处理 序列数据 的神经网络,被广泛用于语言模型、文本生成、机器翻译等。基础知识可以看一下这个英文博客——Recurrent Neural Networks Tutorial, Part 1 – Introduction to RNNs,比较热门的就是最近大火的 NLP,感兴趣的小伙伴可以入一下门看看。
什么是RNN?
严格意义上来说, RNN 是一个处理时间序列数据的神经网络结构,也就是说,需要在脑海里有一根时间轴,循环神经网络具有初始状态 ,在每个时间点 t 迭代对当前时间的输入 进行处理,修改自身的状态 ,并进行输出 。
循环神经网络的核心是状态 ,是一个特定维数的向量,类似于神经网络的 “记忆”。在 的初始时刻, 被赋予一个初始值(常用的为全 向量)。然后,用类似于递归的方法来描述循环神经网络的工作过程,即在 时刻,假设 已经求出,关注如何在此基础上求出 :
-
对输入向量 通过矩阵 进行线性变换, 与状态 具有相同的维度;
-
对 通过矩阵 进行线性变换, 与状态 具有相同的维度;
-
将上述得到的两个向量相加并通过激活函数,作为当前状态 的值,即 。也就是说,当前状态的值是上一个状态的值和当前输入进行某种信息整合而产生的;
-
对当前状态 通过矩阵 进行线性变换,得到当前时刻的输出 。
这是典型的 RNN 的工作过程:
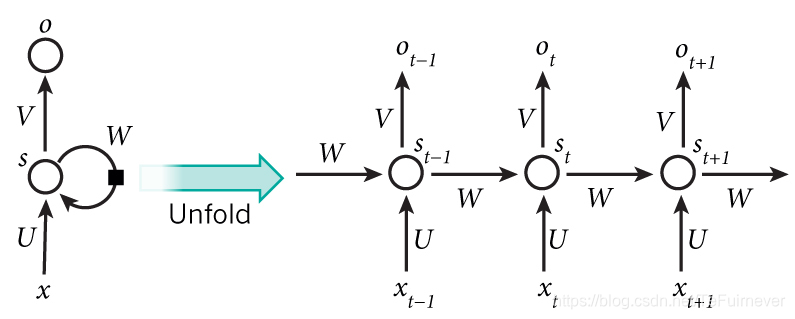
循环神经网络及其正向计算涉及计算的时间展开。Source: Nature
二、文本生成
这里通过一个简单的例子来进行 RNN 的介绍学习,即文本的生成。这个任务的本质其实预测一段英文文本的接续字母的概率分布,比如,有以下句子:
I am a studen
这个句子(序列)一共有 13 个字符(包含空格)。
当阅读到这个由 13 个字符组成的序列后,根据多年学习英语的经验,你可以很容易地预测出下一个字符是什么?没错,应该很大概率是 t,因为 student。我们希望建立的正是这样的一个模型,逐个输入一段长为 seq_length 的序列,输出这些序列接续的下一个字符的概率分布,再进行采样作为预测值,然后滚雪球式地生成下两个字符,下三个字符等等,即可完成文本的生成任务。
1_读取文本
首先要实现一个简单的 DataLoader 类来读取文本,并以字符为单位进行编码。设字符种类数为 num_chars ,则每种字符赋予一个 0 到 num_chars - 1 之间的唯一整数编号 i。
class DataLoader():
def __init__(self):
path = tf.keras.utils.get_file('nietzsche.txt',
origin='https://s3.amazonaws.com/text-datasets/nietzsche.txt')
with open(path, encoding='utf-8') as f:
self.raw_text = f.read().lower()
self.chars = sorted(list(set(self.raw_text)))
self.char_indices = dict((c, i) for i, c in enumerate(self.chars))
self.indices_char = dict((i, c) for i, c in enumerate(self.chars))
self.text = [self.char_indices[c] for c in self.raw_text]
def get_batch(self, seq_length, batch_size):
seq = []
next_char = []
for i in range(batch_size):
index = np.random.randint(0, len(self.text) - seq_length)
seq.append(self.text[index:index+seq_length])
next_char.append(self.text[index+seq_length])
return np.array(seq), np.array(next_char) # [batch_size, seq_length], [num_batch]
2_模型实现
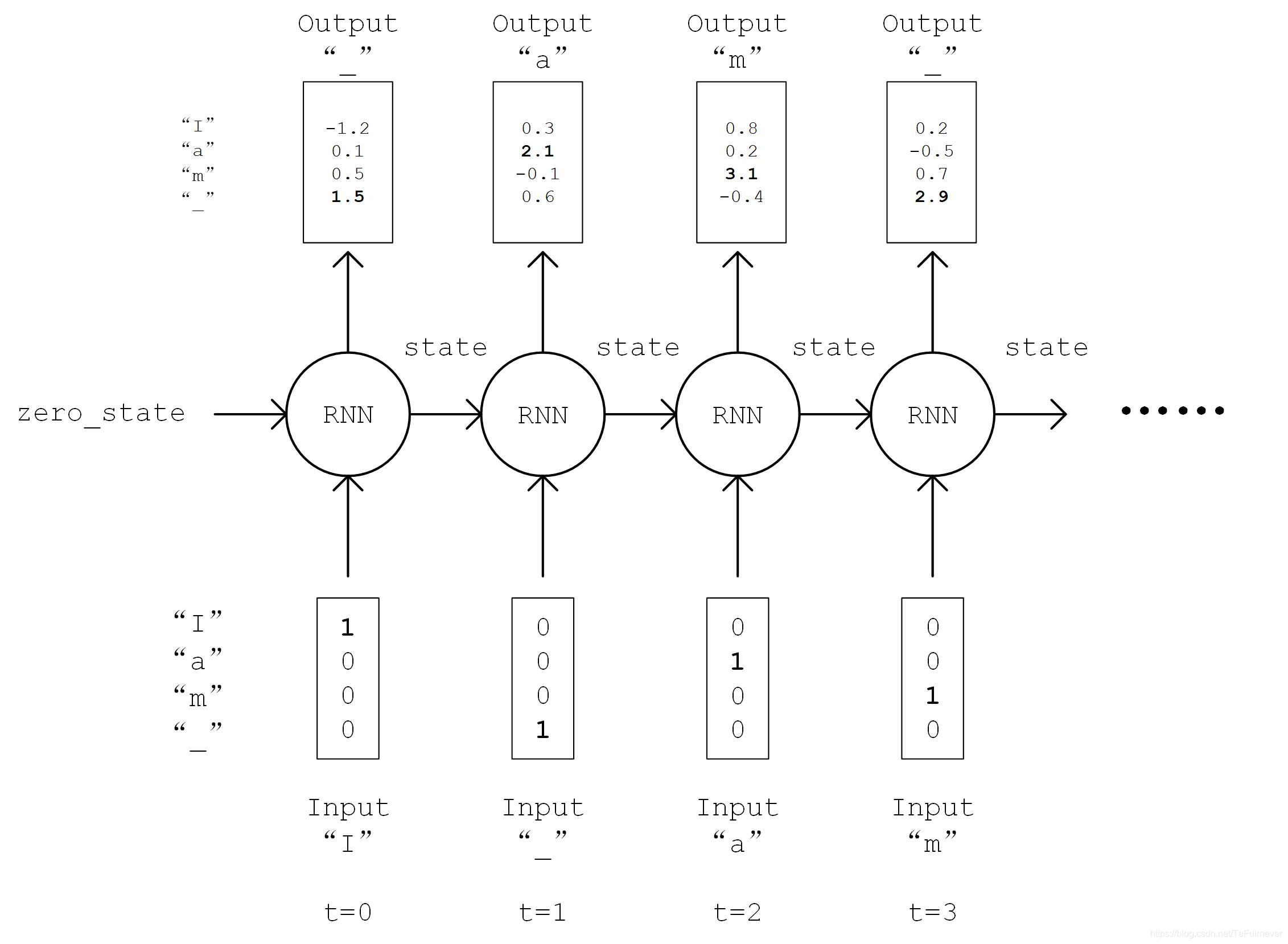
在 __init__ 方法中实例化一个常用的 LSTMCell 单元,以及一个线性变换用的全连接层。
- 首先对序列进行
One Hot操作,即将序列中的每个字符的编码i均变换为一个num_char维向量,其第i位为1,其余均为0,变换后的序列张量形状为[seq_length, num_chars]; - 然后,初始化 RNN 单元的状态,存入变量
state中; - 接下来,将序列从头到尾依次送入 RNN 单元,即在
t时刻,将上一个时刻t-1的 RNN 单元状态state和序列的第t个元素 inputs[t, :] 送入 RNN 单元,得到当前时刻的输出output和 RNN 单元状态。 - 最后,取 RNN 单元最后一次的输出,通过全连接层变换到
num_chars维,即作为模型的输出。
流程图如下:
具体实现代码如下:
class RNN(tf.keras.Model):
def __init__(self, num_chars, batch_size, seq_length):
super().__init__()
self.num_chars = num_chars
self.seq_length = seq_length
self.batch_size = batch_size
self.cell = tf.keras.layers.LSTMCell(units=256)
self.dense = tf.keras.layers.Dense(units=self.num_chars)
def call(self, inputs, from_logits=False):
inputs = tf.one_hot(inputs, depth=self.num_chars) # [batch_size, seq_length, num_chars]
state = self.cell.get_initial_state(batch_size=self.batch_size, dtype=tf.float32)
for t in range(self.seq_length):
output, state = self.cell(inputs[:, t, :], state)
logits = self.dense(output)
if from_logits:
return logits
else:
return tf.nn.softmax(logits)
output, state = self.cell(inputs[:, t, :], state) 图示:

3_超参数
照常规CNN,定义一些模型超参数:
# 训练轮数
num_batches = 1000
# 序列长度
seq_length = 40
# 批大小
batch_size = 50
# 学习率
learning_rate = 1e-3
4_模型训练
-
用
DataLoader中随机取一批batch_size大小训练数据; -
将数据送入模型,计算出模型的预测值;
-
将模型预测值与真实值进行比较,计算损失函数
loss; -
计算损失函数
loss关于模型变量的导数; -
使用优化器更新模型参数以最小化损失函数。
data_loader = DataLoader()
model = RNN(num_chars=len(data_loader.chars), batch_size=batch_size, seq_length=seq_length)
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
for batch_index in range(num_batches):
X, y = data_loader.get_batch(seq_length, batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("batch %d: loss %f" % (batch_index, loss.numpy()))
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
5_模型预测
关于 文本生成 的过程有一点需要特别注意!!!
之前对于图像数据,我们一直使用 tf.argmax() 函数,将对应概率最大的值作为预测值。然而对于文本生成而言,这样的预测方式过于绝对,会使得生成的文本失去丰富性。于是,使用 np.random.choice() 函数按照生成的概率分布取样。这样,即使是对应概率较小的字符,也有机会被取样到。同时,还加入一个 temperature 参数控制分布的形状,参数值越大则分布越平缓(最大值和最小值的差值越小),生成文本的丰富度越高;参数值越小则分布越陡峭,生成文本的丰富度越低。
def predict(self, inputs, temperature=1.):
batch_size, _ = tf.shape(inputs)
logits = self(inputs, from_logits=True)
prob = tf.nn.softmax(logits / temperature).numpy()
return np.array([np.random.choice(self.num_chars, p=prob[i, :])
for i in range(batch_size.numpy())])
通过这种方式进行 滚雪球 式的连续预测,即可得到生成文本。
X_, _ = data_loader.get_batch(seq_length, 1)
for diversity in [0.2, 0.5, 1.0, 1.2]:
X = X_
print("diversity %f:" % diversity)
for t in range(400):
y_pred = model.predict(X, diversity)
print(data_loader.indices_char[y_pred[0]], end='', flush=True)
X = np.concatenate([X[:, 1:], np.expand_dims(y_pred, axis=1)], axis=-1)
print("\n")
6_完整代码
import tensorflow as tf
import numpy as np
# 数据读取
class DataLoader():
def __init__(self):
path = tf.keras.utils.get_file(
'nietzsche.txt',
origin='https://s3.amazonaws.com/text-datasets/nietzsche.txt')
with open(path, encoding='utf-8') as f:
self.raw_text = f.read().lower()
self.chars = sorted(list(set(self.raw_text)))
self.char_indices = dict((c, i) for i, c in enumerate(self.chars))
self.indices_char = dict((i, c) for i, c in enumerate(self.chars))
self.text = [self.char_indices[c] for c in self.raw_text]
def get_batch(self, seq_length, batch_size):
seq = []
next_char = []
for i in range(batch_size):
index = np.random.randint(0, len(self.text) - seq_length)
seq.append(self.text[index:index + seq_length])
next_char.append(self.text[index + seq_length])
# [batch_size, seq_length], [num_batch]
return np.array(seq), np.array(next_char)
# 网络结构
class RNN(tf.keras.Model):
def __init__(self, num_chars, batch_size, seq_length):
super().__init__()
self.num_chars = num_chars
self.seq_length = seq_length
self.batch_size = batch_size
self.cell = tf.keras.layers.LSTMCell(units=256)
self.dense = tf.keras.layers.Dense(units=self.num_chars)
def call(self, inputs, from_logits=False):
# [batch_size, seq_length, num_chars]
inputs = tf.one_hot(inputs, depth=self.num_chars)
state = self.cell.get_initial_state(
batch_size=self.batch_size, dtype=tf.float32)
for t in range(self.seq_length):
output, state = self.cell(inputs[:, t, :], state)
logits = self.dense(output)
if from_logits:
return logits
else:
return tf.nn.softmax(logits)
def predict(self, inputs, temperature=1.):
batch_size, _ = tf.shape(inputs)
logits = self(inputs, from_logits=True)
prob = tf.nn.softmax(logits / temperature).numpy()
return np.array([np.random.choice(self.num_chars, p=prob[i, :])
for i in range(batch_size.numpy())])
# 超参数
num_batches = 5000
seq_length = 50
batch_size = 50
# learning_rate = 1e-2
# 实例化
data_loader = DataLoader()
model = RNN(
num_chars=len(
data_loader.chars),
batch_size=batch_size,
seq_length=seq_length)
optimizer = tf.keras.optimizers.Adam()
for batch_index in range(num_batches):
X, y = data_loader.get_batch(seq_length, batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(
y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("batch %d: loss %f" % (batch_index, loss.numpy()))
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
# 生成结果文本
X_, _ = data_loader.get_batch(seq_length, 1)
for diversity in [0.2, 0.5, 1.0, 1.2]:
X = X_
print("diversity %f:" % diversity)
for t in range(400):
y_pred = model.predict(X, diversity)
print(data_loader.indices_char[y_pred[0]], end='', flush=True)
X = np.concatenate([X[:, 1:], np.expand_dims(y_pred, axis=1)], axis=-1)
print("\n")
diversity 0.200000:
f the contreation of the contrention of the self the contrention of the farter the perion of the sere the porer the contrest of the fare the comprest of the every and the inselled the sere the concertion of the contrest of the concerition of the forer the inselferent of the contrenter and the self the sore the contrering and and the concount of the contrention of the contering to the concering the
diversity 0.500000:
rd in the bealy the gererally to the rest of the bearasian it is a frearing to the well a andertally are the sour to the to the for the sinfition to the geralle elient may in the farter of this conceect--as the fore
to the comprenter compotion and to hich self of the ralien not has of the our in the persurity the some not an a conter it a treen to the mure as the instinly the deeling and conting t
diversity 1.000000:
liment, and tor
a mostly comanvs, the in, abtialivele! hinser will would ull--and findill with the abloy pellotayron, if
atain the piosopay a sedincelen act aglict abquins at
acassing is a tay or of such the gore is and moce, of gure
on to a nition as natury of deingeved in, crelle, of chersing pectone--and abl the go
ond to pecnle docart notimatiane
escornd evar mote of the tarhongure and the mis
diversity 1.200000:
on loweve halien godequentr's quefycal to reeing, the touthverwimality cond;eving-mey, and geato hivinitiousiat of canly meghing
aid his
a to r
a6. bytal"vesem n_arkee, logoin ond freoms, hacy eyiens)-it podsend--ef womave
[91er that ony breaple.
2ne imover, tien sucfly; we precout
ormaishgatest ad
ad aukly sellitt, a dtencion now, ne varts be stofun. ruy, the alony hamegher mepont at such as
a
三、神奇的应用
包括机器翻译、语义理解及情感分析在内的等等都可以用 RNN 进行实现。
下面左边这张图描述了各大公司都在不断地提高各自语音机器翻译的水准和技术,右边这张图展示的是去年12月微软发布了Microsoft Translator 的一个新功能,它支持50多种语言,可以实现多个人多种语言的实时翻译,比如大家每个人可能来自不同的国家,只要拿着手机用这个 APP 我们就可以互相交流。你说一句话或者输入文字,对方听到/看到的就是他的母语。这是不是让你想起了流浪地球中的高科技?

引用自微软亚洲研究院,知乎,链接:https://www.zhihu.com/question/46563853/answer/153380355
除此之外,还有语音合成,近日,一段歌声听起来像佐藤莎莎拉演唱的 Rolling in the Deep 的声音,让微博上的二次元粉丝惊呼:我的老婆要重生了!

引用自量子位(ID:QbitAI)的文章 郭一璞 晓查 乾明 发自 凹非寺 出品《你听不出是AI在唱歌!这个日本虚拟歌姬,横扫中英日 三种语言》
以下是语音合成的英文歌《Rolling In The Deep》和《Everytime》两首,英文版的清唱已经听起来跟正常人类唱歌没什么区别了。
英文歌
再就是语音合成的中文歌,陈奕迅的《爱情转移》,虽然是现在的状态是一个字一个字的蹦,还有一些跑调,但潜力是有的。
中文歌
当然要注意的是,唱歌跟说话不同,对情感表达的要求非常高,嗓音、气息都会影响到最后的效果,所以如何更具情感是唱歌合成的难点,但 AI 也有独特的优势,它可以唱得调子高啊,再也不用担心唱歌唱不上去了,哈哈 ?。
再就是 AI 写作,就如同上面的文本生成一样,以结构化数据为输入,智能写作算法按照人类习惯的方式描述数据中蕴含的主要信息。由于机器对数据的处理速度远超人类,因此非常擅长完成时效性新闻的报道任务。
微软有一个人工智能叫少女小冰,它可以根据你上传的图片和文字写出配套的诗歌,我就去试了下 少女小冰。

图片源自人工智能少女小冰的主页
自己操作的话,步骤如下:
-
配的图片是

-
配的文字是

-
点击开始创作

-
生成结果中

-
最终的结果有三种可供选择,可以复制初稿或者生成卡片

虽然不是特别的完美,但是那种凄冷的意境,真真的让我感觉到了 AI 的强大。
推荐阅读
- TensorFlow2.0 学习笔记(一):TensorFlow 2.0 的安装和环境配置以及上手初体验
- TensorFlow2.0 学习笔记(二):多层感知机(MLP)
- TensorFlow2.0 学习笔记(三):卷积神经网络(CNN)
- TensorFlow2.0 学习笔记(四):迁移学习(MobileNetV2)
- TensorFlow2.0 学习笔记(五):循环神经网络(RNN)
参考文章
- TensorFlow 官方文档
- 简单粗暴 TensorFlow 2.0
- Recurrent Neural Networks Tutorial, Part 1 – Introduction to RNNs
- https://mp.weixin.qq.com/s/EUcXgow4tUyc5hwVdcG90w
