文章参考来源六尺帐篷,其中加入了一些自己的理解。
本文将从一个下山的场景开始,先提出梯度下降算法的基本思想,进而从数学上解释梯度下降算法的原理,最后实现一个简单的梯度下降算法的实例!
梯度下降的场景假设
梯度下降法的基本思想可以类比为一个下山的过程。假设这样一个场景:一个人被困在山上,需要从山上下来(i.e. 找到山的最低点,也就是山谷)。但此时山上的浓雾很大,导致可视度很低。因此,下山的路径就无法确定,他必须利用自己周围的信息去找到下山的路径。这个时候,他就可以利用梯度下降算法来帮助自己下山。具体来说就是,以他当前的所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着山的高度下降的地方走,同理,如果我们的目标是上山,也就是爬到山顶,那么此时应该是朝着最陡峭的方向往上走。然后每走一段距离,都反复采用同一个方法,最后就能成功的抵达山谷。
image.png
我们同时可以假设这座山最陡峭的地方是无法通过肉眼立马观察出来的,而是需要一个复杂的工具来测量,同时,这个人此时正好拥有测量出最陡峭方向的能力。所以,此人每走一段距离,都需要一段时间来测量所在位置最陡峭的方向,这是比较耗时的。那么为了在太阳下山之前到达山底,就要尽可能的减少测量方向的次数。这是一个两难的选择,如果测量的频繁,可以保证下山的方向是绝对正确的,但又非常耗时,如果测量的过少,又有偏离轨道的风险。所以需要找到一个合适的测量方向的频率,来确保下山的方向不错误,同时又不至于耗时太多!

梯度下降
梯度下降的基本过程就和下山的场景很类似。
首先,我们有一个可微分的函数。这个函数就代表着一座山。我们的目标就是找到这个函数的最小值,也就是山底。根据之前的场景假设,最快的下山的方式就是找到当前位置最陡峭的方向,然后沿着此方向向下走,对应到函数中,就是找到给定点的梯度 ,然后朝着梯度相反的方向,就能让函数值下降的最快!因为梯度的方向就是函数之变化最快的方向(在后面会详细解释)
所以,我们重复利用这个方法,反复求取梯度,最后就能到达局部的最小值,这就类似于我们下山的过程。而求取梯度就确定了最陡峭的方向,也就是场景中测量方向的手段。那么为什么梯度的方向就是最陡峭的方向呢?接下来,我们从微分开始讲起
微分
看待微分的意义,可以有不同的角度,最常用的两种是:
- 函数图像中,某点的切线的斜率
-
函数的变化率
几个微分的例子:
image.png
上面的例子都是单变量的微分,当一个函数有多个变量的时候,就有了多变量的微分,即分别对每个变量进行求微分

image.png
梯度
梯度实际上就是多变量微分的一般化。
下面这个例子:

image.png
我们可以看到,梯度就是分别对每个变量进行微分,然后用逗号分割开,梯度是用<>包括起来,说明梯度其实一个向量。
梯度是微积分中一个很重要的概念,之前提到过梯度的意义
- 在单变量的函数中,梯度其实就是函数的微分,代表着函数在某个给定点的切线的斜率
- 在多变量函数中,梯度是一个向量,向量有方向,梯度的方向就指出了函数在给定点的上升最快的方向
这也就说明了为什么我们需要千方百计的求取梯度!我们需要到达山底,就需要在每一步观测到此时最陡峭的地方,梯度就恰巧告诉了我们这个方向。梯度的方向是函数在给定点上升最快的方向,那么梯度的反方向就是函数在给定点下降最快的方向,这正是我们所需要的。所以我们只要沿着梯度的方向一直走,就能走到局部的最低点!

image.png
梯度下降算法的数学解释
上面我们花了大量的篇幅介绍梯度下降算法的基本思想和场景假设,以及梯度的概念和思想。下面我们就开始从数学上解释梯度下降算法的计算过程和思想!

image.png
此公式的意义是:J是关于Θ的一个函数,我们当前所处的位置为Θ0点,要从这个点走到J的最小值点,也就是山底。首先我们先确定前进的方向,也就是梯度的反向,然后走一段距离的步长,也就是α,走完这个段步长,就到达了Θ1这个点!

image.png
下面就这个公式的几个常见的疑问:
- α是什么含义?
α在梯度下降算法中被称作为学习率或者步长,意味着我们可以通过α来控制每一步走的距离,以保证不要步子跨的太大扯着蛋,哈哈,其实就是不要走太快,错过了最低点。同时也要保证不要走的太慢,导致太阳下山了,还没有走到山下。所以α的选择在梯度下降法中往往是很重要的!α不能太大也不能太小,太小的话,可能导致迟迟走不到最低点,太大的话,会导致错过最低点!

image.png
- 为什么要梯度要乘以一个负号?
梯度前加一个负号,就意味着朝着梯度相反的方向前进!我们在前文提到,梯度的方向实际就是函数在此点上升最快的方向!而我们需要朝着下降最快的方向走,自然就是负的梯度的方向,所以此处需要加上负号
梯度下降算法的实例
我们已经基本了解了梯度下降算法的计算过程,那么我们就来看几个梯度下降算法的小实例,首先从单变量的函数开始
单变量函数的梯度下降
我们假设有一个单变量的函数

image.png
函数的微分

image.png
初始化,起点为

image.png
学习率为

image.png
根据梯度下降的计算公式
image.png
我们开始进行梯度下降的迭代计算过程:

image.png
如图,经过四次的运算,也就是走了四步,基本就抵达了函数的最低点,也就是山底

image.png
多变量函数的梯度下降
我们假设有一个目标函数

image.png
现在要通过梯度下降法计算这个函数的最小值。我们通过观察就能发现最小值其实就是 (0,0)点。但是接下来,我们会从梯度下降算法开始一步步计算到这个最小值!
我们假设初始的起点为:

image.png
初始的学习率为:

image.png
函数的梯度为:

image.png
进行多次迭代:

image.png
我们发现,已经基本靠近函数的最小值点

image.png
梯度下降算法的实现
下面我们将用python实现一个简单的梯度下降算法。场景是一个简单的线性回归的例子:假设现在我们有一系列的点,如下图所示

image.png
我们将用梯度下降法来拟合出这条直线!
首先,我们需要定义一个代价函数,在此我们选用均方误差代价函数

image.png
此公示中
- m是数据集中点的个数
- ½是一个常量,这样是为了在求梯度的时候,二次方乘下来就和这里的½抵消了,自然就没有多余的常数系数,方便后续的计算,同时对结果不会有影响
- y 是数据集中每个点的真实y坐标的值
-
h 是我们的预测函数,根据每一个输入x,根据Θ 计算得到预测的y值,即

image.png
我们可以根据代价函数看到,代价函数中的变量有两个,所以是一个多变量的梯度下降问题,求解出代价函数的梯度,也就是分别对两个变量进行微分

到这儿所有的原理都已经说明白了,之前我还有点糊涂,没搞清楚梯度下降算法是干嘛的,其实明白一个算法这是最基本的,必j要知道其作用。
这儿就目前来说,我们在描绘一条一次直线,直线方程一般是y=ax+b,a和b也就是需要我们预测的theta1和theta2,我们要预测的a和b要能尽量拟合所有的点,这里采用代价函也就是损失函数选用的是均方误差,也就是我们预测的值减去实际的值,所有的差值求其平方和,再除以点的个数,当然损失函数的值越小越好,所以用到了梯度下降算法来求其最小值,其实这个算法的思想我们高中就学到过,只不过现在给了一个机器学习里面更为学术的官方词,称之为梯度下降,求一个函数的最小值,无非就是对其求导,再求极值,多元函数求其微分。那么使得损失函数最小的两个参数a,b就能求出,也就是这一条需yige预测的直线了。
再举一个简单的应用,比如说利用梯度下降算法求y=cosx的最小值的x会是多少,这里不涉及损失函数,那么自然沿着斜率方向是最快的方向,斜率也就是y`=-sinx,每一次我们都让其沿着这个方向下降,给定初始x0=3,学习率为0.01,学习率不宜太大也不宜太小,x1=x0-0.01*(-sinx0),x2=x1-0.01*(-sinx1),一直持续计算下去,到最后如果到达了最小值,那么该点的导数为0,xn=x(n-1)-0.01*(sin(x(n-1)))也就不会再变化了,会在最小值这一点停住,而我们也得到了需要的x的值。这是梯度下降算法最简单的应用。实现代码如下:
import numpy as up
x=5
learning_rate=0.01
for i in range(1000):
x=x-learning_rate*(-(np.sinx))
print(i,x)最后发现x基本上会在3.14170883622停下来,而事实上我们知道y=cosx的最小值在x=pi的时候取得,基本上结果也很接近了。
絮叨了这么多,下面我们再次回到我们之前需要拟合的那条直线问题上面来。
明确了代价函数和梯度,以及预测的函数形式。我们就可以开始编写代码了。但在这之前,需要说明一点,就是为了方便代码的编写,我们会将所有的公式都转换为矩阵的形式,python中计算矩阵是非常方便的,同时代码也会变得非常的简洁。
为了转换为矩阵的计算,我们观察到预测函数的形式
image.png
我们有两个变量,为了对这个公式进行矩阵化,我们可以给每一个点x增加一维,这一维的值固定为1,这一维将会乘到Θ0上。这样就方便我们统一矩阵化的计算

image.png
然后我们将代价函数和梯度转化为矩阵向量相乘的形式

image.png
coding time
首先,我们需要定义数据集和学习率
import numpy as np
# Size of the points dataset.
m = 20
# Points x-coordinate and dummy value (x0, x1).
X0 = np.ones((m, 1))
X1 = np.arange(1, m+1).reshape(m, 1)
X = np.hstack((X0, X1))
# Points y-coordinate
y = np.array([
3, 4, 5, 5, 2, 4, 7, 8, 11, 8, 12,
11, 13, 13, 16, 17, 18, 17, 19, 21
]).reshape(m, 1)
# The Learning Rate alpha.
alpha = 0.01
接下来我们以矩阵向量的形式定义代价函数和代价函数的梯度
def error_function(theta, X, y):
'''Error function J definition.'''
diff = np.dot(X, theta) - y
return (1./2*m) * np.dot(np.transpose(diff), diff)
def gradient_function(theta, X, y):
'''Gradient of the function J definition.'''
diff = np.dot(X, theta) - y
return (1./m) * np.dot(np.transpose(X), diff)
最后就是算法的核心部分,梯度下降迭代计算
def gradient_descent(X, y, alpha):
'''Perform gradient descent.'''
theta = np.array([1, 1]).reshape(2, 1)
gradient = gradient_function(theta, X, y)
while not np.all(np.absolute(gradient) <= 1e-5):
theta = theta - alpha * gradient
gradient = gradient_function(theta, X, y)
return theta
当梯度小于1e-5时,说明已经进入了比较平滑的状态,类似于山谷的状态,这时候再继续迭代效果也不大了,所以这个时候可以退出循环!
完整的代码如下
import numpy as np
# Size of the points dataset.
m = 20
# Points x-coordinate and dummy value (x0, x1).
X0 = np.ones((m, 1))
X1 = np.arange(1, m+1).reshape(m, 1)
X = np.hstack((X0, X1))
# Points y-coordinate
y = np.array([
3, 4, 5, 5, 2, 4, 7, 8, 11, 8, 12,
11, 13, 13, 16, 17, 18, 17, 19, 21
]).reshape(m, 1)
# The Learning Rate alpha.
alpha = 0.01
def error_function(theta, X, y):
'''Error function J definition.'''
diff = np.dot(X, theta) - y
return (1./2*m) * np.dot(np.transpose(diff), diff)
def gradient_function(theta, X, y):
'''Gradient of the function J definition.'''
diff = np.dot(X, theta) - y
return (1./m) * np.dot(np.transpose(X), diff)
def gradient_descent(X, y, alpha):
'''Perform gradient descent.'''
theta = np.array([1, 1]).reshape(2, 1)
gradient = gradient_function(theta, X, y)
while not np.all(np.absolute(gradient) <= 1e-5):
theta = theta - alpha * gradient
gradient = gradient_function(theta, X, y)
return theta
optimal = gradient_descent(X, y, alpha)
print('optimal:', optimal)
print('error function:', error_function(optimal, X, y)[0,0])
运行代码,计算得到的结果如下

image.png
所拟合出的直线如下

image.png
小结
至此,我们就基本介绍完了梯度下降法的基本思想和算法流程,并且用python实现了一个简单的梯度下降算法拟合直线的案例!
最后,我们回到文章开头所提出的场景假设:
这个下山的人实际上就代表了反向传播算法,下山的路径其实就代表着算法中一直在寻找的参数Θ,山上当前点的最陡峭的方向实际上就是代价函数在这一点的梯度方向,场景中观测最陡峭方向所用的工具就是微分 。在下一次观测之前的时间就是有我们算法中的学习率α所定义的。
可以看到场景假设和梯度下降算法很好的完成了对应!
今天学习到numpy基本的运算方法,遇到了一个让我比较难理解的问题。就是dot函数是如何对矩阵进行运算的。
一、dot()的使用
参考文档:https://docs.scipy.org/doc/numpy/reference/generated/numpy.dot.html
dot()返回的是两个数组的点积(dot product)
1.如果处理的是一维数组,则得到的是两数组的內积(顺便去补一下数学知识)

In : d = np.arange(0,9)
Out: array([0, 1, 2, 3, 4, 5, 6, 7, 8])
In : e = d[::-1] Out: array([8, 7, 6, 5, 4, 3, 2, 1, 0]) In : np.dot(d,e) Out: 84
2.如果是二维数组(矩阵)之间的运算,则得到的是矩阵积(mastrix product)。
In : a = np.arange(1,5).reshape(2,2)
Out:
array([[1, 2],
[3, 4]])
In : b = np.arange(5,9).reshape(2,2)
Out: array([[5, 6],
[7, 8]])
In : np.dot(a,b)
Out:
array([[19, 22],
[43, 50]])
所得到的数组中的每个元素为,第一个矩阵中与该元素行号相同的元素与第二个矩阵与该元素列号相同的元素,两两相乘后再求和。
这句话有点难理解,但是这句话里面没有哪个字是多余的。结合下图理解这句话。
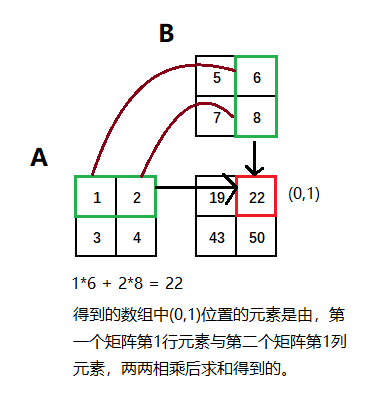
3.dot()函数可以通过numpy库调用,也可以由数组实例对象进行调用。a.dot(b) 与 np.dot(a,b)效果相同。
矩阵积计算不遵循交换律,np.dot(a,b) 和 np.dot(b,a) 得到的结果是不一样的。
