主要使用request库和beautifulSoup库爬取今日热榜的数据。
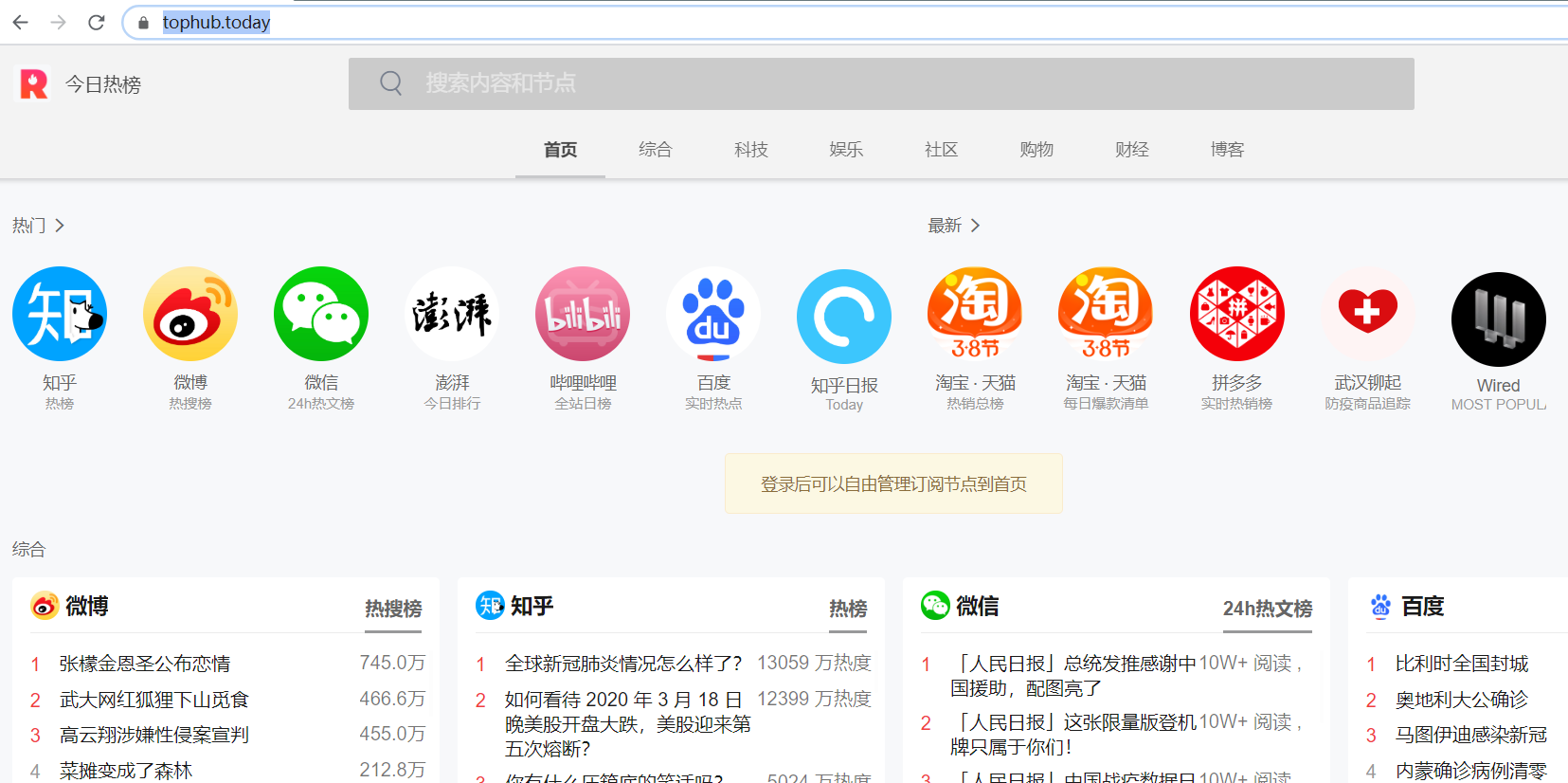
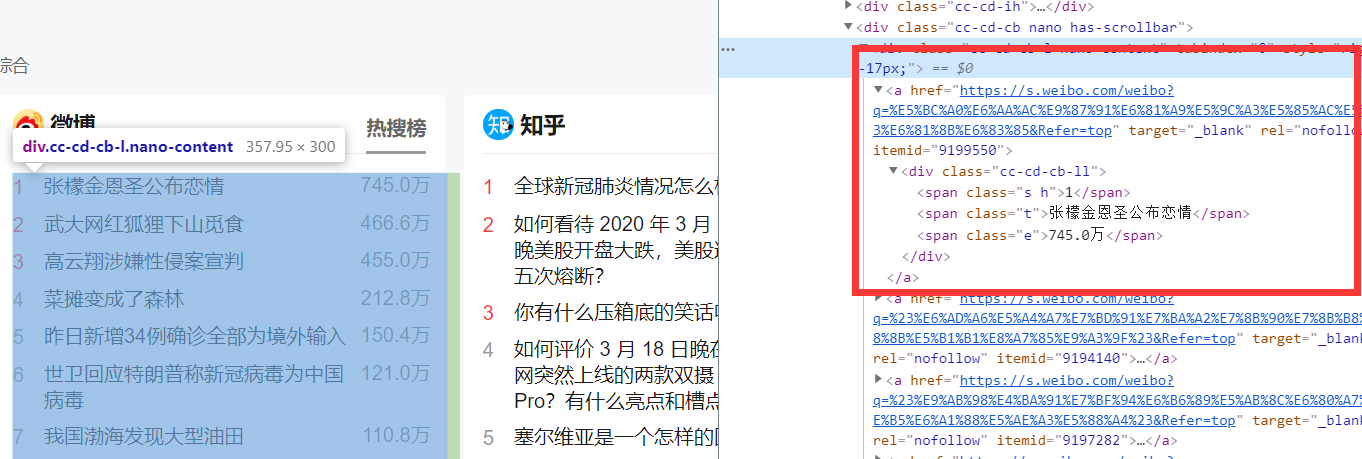
具体代码实现:
1 import requests 2 from bs4 import BeautifulSoup 3 import time 4 import pandas 5 import re 6 7 def get_html(url): 8 headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'} 9 resp = requests.get(url, headers=headers) 10 return resp.text 11 12 13 def get_data(html): 14 soup = BeautifulSoup(html, 'html.parser') 15 nodes = soup.find_all('div', class_='cc-cd') 16 return nodes 17 18 19 def get_node_data(df, nodes): 20 now = int(time.time()) 21 for node in nodes: 22 source = node.find('div', class_='cc-cd-lb').text.strip() 23 messages = node.find('div', class_='cc-cd-cb-l nano-content').find_all('a') 24 for message in messages: 25 content = message.find('span', class_='t').text.strip() 26 if source == '微信': 27 reg = '「.+?」(.+)' 28 content = re.findall(reg, content)[0] 29 30 if df.empty or df[df.content == content].empty: 31 data = { 32 'content': [content], 33 'url': [message['href']], 34 'source': [source], 35 'start_time': [now], 36 'end_time': [now] 37 } 38 39 item = pandas.DataFrame(data) 40 df = pandas.concat([df, item], ignore_index=True) 41 42 else: 43 index = df[df.content == content].index[0] 44 df.at[index, 'end_time'] = now 45 46 return df 47 48 49 url = 'https://tophub.today' 50 html = get_html(url) 51 data = get_data(html) 52 res = pandas.read_excel('今日热榜.xlsx') 53 res = get_node_data(res, data) 54 res.to_excel('今日热榜.xlsx')
扫描二维码关注公众号,回复:
9958882 查看本文章
