简介
在现实生活中,连续值预测问题是非常常见的,比如股价的走势预测、天气预报中温
度和湿度等的预测、年龄的预测、交通流量的预测等。对于预测值是连续的实数范围,或
者属于某一段连续的实数区间,我们把这种问题称为回归(Regression)问题。特别地,如果使用线性模型去逼近真实模型,那么我们把这一类方法叫做线性回归(Linear Regression,简称 LR)
下面举例一个简单的线性回归问题
问题
从指定的w=1.477, b=0.089的真实模型y=1.477*x+0.0889中直接采样数据。
程序清单
import tensorflow as tf
import numpy as np
# 1.采集数据
data = [] # 保存样本集的列表
for i in range(100): # 循环采样100个点
x = np.random.uniform(-10., 10.) # 从[-10,10]的均匀分布中随机采样一个数
eps = np.random.normal(0., 0.1) # 从均值为0.1,方差为0.1^2的高斯分布中随机采样噪声
y = 1.477*x+0.089+eps # 得到模拟的输出
data.append([x, y]) # 保存样本点
data = np.array(data) # 转换为2D Numpy数组
# 2.计算误差
def mse(b, w, points): # 根据当前轮的w,b参数,计算均方差损失
totalError = 0
for i in range(0, len(points)): # 循环迭代所有点
x = points[i, 0] # 获得第i个点的横坐标x
y = points[i, 1] # 获得第i个点的纵坐标y
totalError += (y-(w*x+b))**2 # 计算累计误差
return totalError/float(len(points)) # 得到均方差
# 3.计算梯度
def step_gradient(b_current, w_current, points, learning_rate):
b_gradient = 0
w_gradient = 0
M = float(len(points)) # 总样本数
for i in range(0, len(points)):
x = points[i, 0]
y = points[i, 1]
b_gradient += (2/M) * ((w_current * x + b_current) - y) # 误差函数对b的导数
w_gradient += (2/M) * x * ((w_current * x + b_current) - y) # 误差函数对w的导数
# 根据梯度下降法算法更新w,b
new_b = b_current - (learning_rate * b_gradient)
new_w = w_current - (learning_rate * w_gradient)
return [new_b, new_w]
# 4.梯度更新
def gradient_descent(points, starting_b, starting_w, learning_rate, epos):
b = starting_b # 初始化b
w = starting_w
for step in range(epos):
b, w = step_gradient(b, w, np.array(points), learning_rate)
loss = mse(b, w, points)
if step % 50 == 0:
print('epos', step, ':loss', loss, '; w', w, '; b', b) # 每50epos打印一遍
return {b, w}
def main():
lr = 0.01
init_b = 0
init_w = 0
epos = 10000
[b, w] = gradient_descent(data, init_b, init_w, lr, epos)
loss = mse(b, w, data)
print('Final loss:', loss, ' w:', w, ' b:', b)
return 0
if __name__ == "__main__":
main()
训练结果:
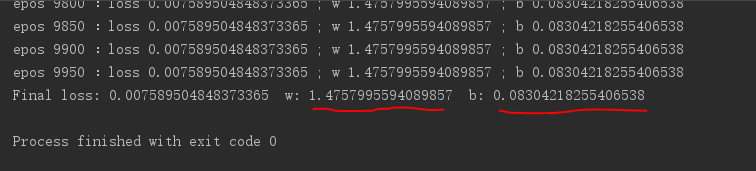
从训练结果可以发现,通过建立的线性模型训练出来的w,b已经很接近真实模型了
