一、性能分析工具简介
Brendan Gregg是算机性能设计、分析和调优专家,编写开源大量性能测试工具。
http://www.brendangregg.com
1、性能分析工具
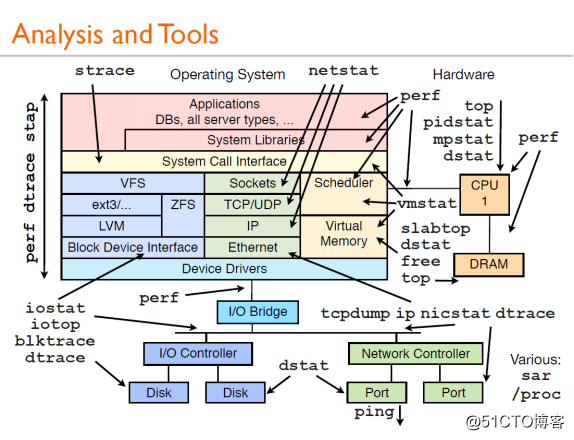
2、性能观测工具
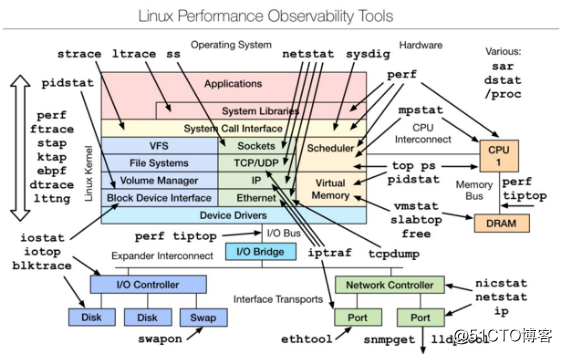
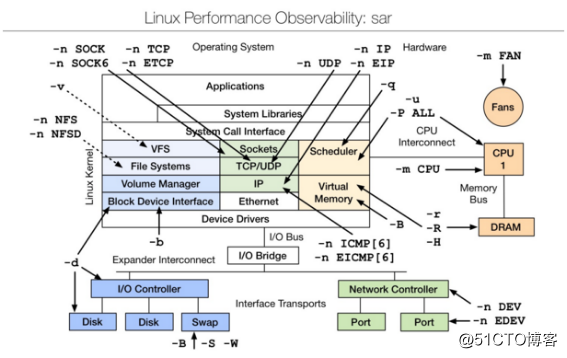
3、性能测评工具

4、性能调优工具
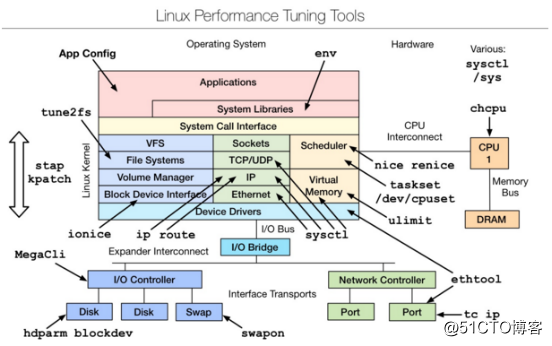
二、常用工具
1、free
free指令会显示内存的使用情况,包括实体内存、虚拟的交换文件内存、共享内存区段以及系统核心使用的缓冲区等。free [-bkmotV][-s <间隔秒数>]
-b 以Byte为单位显示内存使用情况。
-k 以KB为单位显示内存使用情况。
-m 以MB为单位显示内存使用情况。
-h 以合适的单位显示内存使用情况,最大为三位数,自动计算对应的单位值。单位有:
-o 不显示缓冲区调节列。
-s<间隔秒数> 持续观察内存使用状况。
-t 显示内存总和列。
-V 显示版本信息。
free -h
total:表示计物理内存的大小,used+free+buff/cache。
used:表示已使用多少。
free:表示可用内存多少。
Shared:表示多个进程共享的内存总额。
buffer/cache:表示磁盘缓存的大小。buffer cache比较小,即缓存经常访问块设备的元数据;cache比较大,page cache,即缓存文件内容+slab。
available: 剩余可用内存。
2、top
top命令的汇总区域显示了五个方面的系统性能信息:
(1)负载:时间,登陆用户数,系统平均负载;
(2)进程:运行,睡眠,停止,僵尸;
(3)CPU:用户态,核心态,NICE,空闲,等待IO,中断等;
(4)内存:总量,已用,空闲(系统角度),缓冲,缓存;
(5)交换分区:总量,已用,空闲;
任务区域默认显示:进程ID,有效用户,进程优先级,NICE值,进程使用的虚拟内存,物理内存和共享内存,进程状态,CPU占用率,内存占用率,累计CPU时间,进程命令行信息。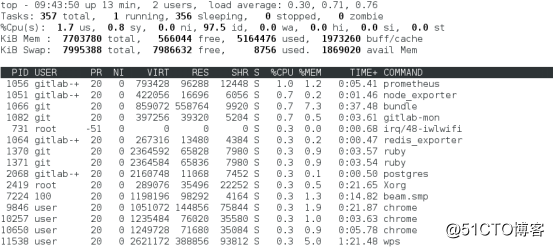
3、ps
ps命令是Process Status缩写,用来查看系统中当前运行的进程。
a:显示所有进程
-a:显示同一终端下的所有程序
-A:显示所有进程
c:显示进程的真实名称
-N:反向选择
-e:等于“-A”
e:显示环境变量
f:显示程序间的关系
-H:显示树状结构
r:显示当前终端的进程
T:显示当前终端的所有程序
u:指定用户的所有进程ps aux | grep mysqld | grep –v grep | awk ‘{print $2 }’ xargs kill -9
杀掉应用程序ps –eal | awk ‘{if ($2 == “Z”){print $4}}’ | xargs kill -9
杀掉僵尸进程ps -ef
显示所有进程,包括命令行ps aux
列出目前正在内存当中的程序ps -u username
查看特定用户的进程ps -aux --sort -pcpu | less
根据CPU使用升序排序ps -aux --sort -pmem | less
根据内存使用升序排序ps -L pid
查看指定进程的线程ps -axjf
树形结构显示进程ps -eo pid,user,args
查看登录服务器的进程watch -n 1 'ps -aux --sort -pmem,-pcpu'
实时监控进程状态
4、strace
strace常用来跟踪进程执行时的系统调用和所接收的信号。在Linux中,进程不能直接访问硬件设备,当进程需要访问硬件设备(比如读取磁盘文件,接收网络数据等等)时,必须由用户态模式切换至内核态模式,通过系统调用访问硬件设备。strace可以跟踪到一个进程产生的系统调用,包括参数、返回值、执行消耗的时间。strace -c[df] [-In] [-bexecve] [-eexpr]... [-Ooverhead] [-Ssortby] -ppid... / [-D] [-Evar[=val]]... [-uusername] command [args]
-c:统计每一系统调用的所执行的时间、次数和出错的次数等。
-d:输出strace关于标准错误的调试信息
-f:跟踪由fork调用所产生的子进程
-ff:如果提供-o filename,则所有进程的跟踪结果输出到相应的filename.pid中,pid是各进程的进程号。
-F:尝试跟踪vfork调用,-f时vfork不被跟踪。
-h:输出简要的帮助信息。
-i:输出系统调用的入口指针。
-q:禁止输出关于脱离的消息。
-r:打印出相对时间关于,,每一个系统调用.
-t:在输出中每一行前加上时间信息。
-tt:在输出中的每一行前加上时间信息,微秒级。
-ttt:微秒级输出,以秒显示时间。
-T:显示每一调用所耗的时间,以秒为单位。
-v:输出所有的系统调用。
-V:输出strace的版本信息。
-x:以十六进制形式输出非标准字符串
-xx:所有字符串以十六进制形式输出.
-a column:设置返回值的输出位置,默认为40。
-e expr:指定一个表达式,用来控制如何跟踪。格式如下:
[qualifier=][!]value1[,value2]...
qualifier可选值为trace、abbrev、verbose、raw、signal、read、write,value是用来限定的符号或数字,默认qualifier是 trace,感叹号是否定符号,例如:
-eopen等价于-e trace=open,表示只跟踪open调用,而-etrace!=open表示跟踪除open外的其它调用。
-e trace=open,close,rean,write表示只跟踪四个系统调用,默认set=all。
-e trace=file 只跟踪有关文件操作的系统调用。
-e trace=process只跟踪有关进程控制的系统调用。
-e trace=network跟踪与网络有关的所有系统调用。
-e strace=signal跟踪所有与系统信号有关的系统调用。
-e trace=ipc跟踪所有与进程通讯有关的系统调用。
-e abbrev=set设定strace输出的系统调用的结果集。
-e raw=set将指定的系统调用的参数以十六进制显示。
-e signal=set指定跟踪的系统信号,默认为all,如 signal=!SIGIO表示不跟踪SIGIO信号。
-e read=set输出从指定文件中读出数据。
-o filename:将strace的输出写入文件filename。
-p pid:跟踪指定的进程pid。
-s strsize:指定输出的字符串的最大长度,默认为32,文件名一直全部输出.
-u username:以username 的UID和GID执行被跟踪的命令strace -p pid
追踪已经存在的进程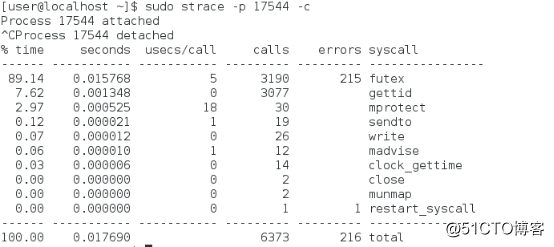
strace command args
追踪应用启动过程
5、df
df(disk free)命令用于显示Linux系统上的文件系统磁盘使用情况统计。df [选项]... [FILE]...
-a, --all:包含所有文件系统
--block-size={SIZE}:使用SIZE大小的Blocks
-h, --human-readable:可读格式
-H, --si:1000为单位显示
-i, --inodes:列出 inode 资讯,不列出已使用 block
-k, --kilobytes:--block-size=1024
-l, --local:限制列出的文件结构
-m, --megabytes:--block-size=1048576
--no-sync:显示信息前不sync,默认设置
-P, --portability:使用POSIX输出格式
--sync:先sync再显示信息
-t, --type=TYPE:限制列出文件系统的TYPE
-T, --print-type:显示文件系统的形式
-x, --exclude-type=TYPE:限制列出文件系统不要显示TYPE
--help:打印帮助信息
--version:打印版本
6、du
du(disk usage)命令用于显示目录或文件所占用的磁盘空间。du [-abcDhHklmsSx][-X文件][--block-size][--exclude=目录或文件][--max-depth=目录层数][--help][--version][目录或文件] [-L 链接符号]
-a或-all:显示目录和文件的大小。
-b或-bytes:显示目录或文件大小时,以byte为单位。
-c或--total:显示目录或文件的大小以及大小总和。
-D或--dereference-args:显示指定符号链接的源文件大小。
-h或--human-readable:以K,M,G为单位,提高信息的可读性。
-H或--si:K,M,G是以1000为换算单位。
-k或--kilobytes:以1024 bytes为单位。
-l或--count-links:重复计算硬件连接的文件。
-L<符号连接>或--dereference<符号连接>:显示选项中所指定符号连接的源文件大小。
-m或--megabytes:以1MB为单位。
-s或--summarize:仅显示总计。
-S或--separate-dirs:显示目录的大小时,不含其子目录的大小。
-x或--one-file-xystem:以开始处理时的文件系统为准,若遇上其它文件系统目录则略过。
-X<文件>或--exclude-from=<文件>:在<文件>指定目录或文件。
--exclude=<目录或文件>:略过指定的目录或文件。
--max-depth=<目录层数>:超过指定层数的目录后,予以忽略。
--help:显示帮助。
--version:显示版本信息。
三、dstat
1、dstat简介
dstat是一个全能系统信息统计工具,提供vmstat、iostat、netstat、nfsstat、ifstat等命令工具类似功能。dstat拥有彩色界面并支持即时刷新。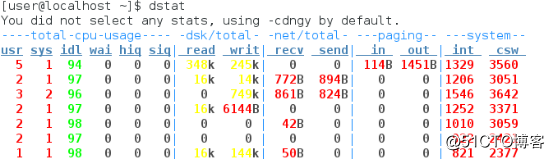
dstat提供的下列状态的性能监控:
(1)CPU状态:CPU使用率,显示用户、内核、空闲、等待、硬中断、软中断。
(2)磁盘统计:磁盘读写,显示磁盘的读、写总数。
(3)网络统计:网络设备发送和接收的数据,显示的网络收、发数据总数。
(4)分页统计:系统的分页活动。显示in(换入)和out(换出)。
(5)系统统计:显示中断(int)和上下文切换(csw)。
dstat安装:yum install dstat
2、dstat命令格式
dstat [-afv] [options..] [delay [count]]
-c, --cpu:显示CPU使用情况
-C 0,3,total:统计指定CPU或汇总信息
-d, --disk:显示磁盘使用情况
-D total,hda:统计指定磁盘或汇总信息
-g, --page:显示分页情况
-i, --int:显示中断统计
-I 5,eth2:显示平均负载情况,包括1分钟、5分钟、15分钟平均值
-l, --load:开启平均负载统计
-m, --mem:显示内存使用情况
-n, --net:显示网络信息
-N eth1,total:指定网络接口
-p, --proc:统计进程信息,包括runnable、uninterruptible、new
-r, --io:统计I/O请求,包括读写请求
-s, --swap:显示swap使用情况
-S swap1,total:可以指定多个swap
-t, --time:显示统计时时间,对分析历史数据非常有用
-y, --sys:统计系统信息,包括中断、上下文切换
--ipc:显示IPC使用情况,消息队列、信号量、共享内存
--lock:统计lock信息
--raw:统计raw信息
--tcp:统计tcp信息
--udp:统计udp信息
--unix:统计unix信息
-M stat1,stat2:统计external信息
-a, --all:等同于-cdngy
-f, --full:等同于-C -D -I -N -S
-v, --vmstat:等同于-pmgdsc -D
--integer:强制输出整型值,默认
--nocolor:禁用颜色功能
--noheaders:禁止重复输出header,默认打印依次屏幕输出一次header
--noupdate:当delay大于1时,禁止在时间间隔内更新
--output file:输出状态信息到CVS文件
--aio:开启同步IO统计
3、dstat插件简介
dstat通过插件方式提供灵活可扩展的功能,dstat --list可以查看dstat支持的所有参数,internal是dstat自带的监控参数,/usr/share/dstat是dstat支持的插件,这些插件可以扩展dstat的功能,如可以监控电源(battery)、mysql等。
但插件并不是都可以直接使用,部分插件还依赖其它python包支持,如想监控mysql,必须要装python连接mysql的一些包。
4、dstat插件命令
--battery:电池电池百分比(需要ACPI)
--battery-remain:电池剩余小时、分钟(需要ACPI)
--cpufreq:CPU频率百分比(需要ACPI)
--dbus:dbus连接的数量(需要python-dbus)
--disk-util:显示某一时间磁盘的忙碌状况
--fan:风扇转速(需要ACPI)
--freespace:每个文件系统的磁盘使用情况
--gpfs:gpfs读/写 I / O(需要mmpmon)
--gpfs-ops:GPFS文件系统操作(需要mmpmon)
--helloworld:dstat插件Hello world示例
--innodb-buffer:显示innodb缓冲区统计
--innodb-io:显示innodb I / O统计数据
--innodb-ops:显示innodb操作计数器
--lustre:显示lustreI / O吞吐量
--memcache-hits:显示memcache 的命中和未命中的数量
--mysql5-cmds:显示MySQL5命令统计
--mysql5-conn:显示MySQL5连接统计
--mysql5-io:MySQL5 I / O统计数据
--mysql5-keys:显示MySQL5关键字统计
--mysql-io:显示MySQL I / O统计数据
--mysql-keys:显示MySQL关键字统计
--net-packets:显示接收和发送的数据包的数量
--nfs3:显示NFS v3客户端操作
--nfs3-ops:显示扩展NFS v3客户端操作
--nfsd3:显示NFS v3服务器操作
--nfsd3-ops:显示扩展NFS v3服务器操作
--ntp:显示NTP服务器的ntp时间
--postfix:显示后缀队列大小(需要后缀)
--power:显示电源使用量
--proc-count:显示进程的总数
--rpc:显示rpc客户端调用统计
--rpcd:显示RPC服务器调用统计
--sendmail:显示sendmail队列大小(需要sendmail)
--snooze:显示每秒运算次数
--test:显示插件输出
--thermal:热系统的温度传感器
--top-bio:显示消耗块IO最大的进程
--top-cpu:显示消耗CPU最大的进程
--top-cputime:显示使用CPU时间最大的进程(单位ms)
--top-cputime-avg:显示使用CPU时间平均最大的进程(单位ms)
--top-io:显示消耗I/O最大进程
--top-latency:显示总延迟最大的进程(单位ms)
--top-latency-avg:显示平均延时最大的进程(单位ms)
--top-mem:显示使用内存最大的进程
--top-oom:显示第一个被OOM结束的进程
--utmp:显示utmp连接的数量(需要python-utmp)
--vmk-hba:显示VMware ESX内核vmhba统计数
--vmk-int:显示VMware ESX内核中断数据
--vmk-nic:显示VMware ESX内核端口统计
--vz-io:显示每个OpenVZ请求CPU使用率
--vz-ubc:显示OpenVZ用户统计
--wifi:无线连接质量和信号噪声比
--disk-util:显示某一时间磁盘的忙碌状况
--freespace:显示当前磁盘空间使用率
--proc-count:显示正在运行的程序数量
--top-bio:示块IO最大的进程
--top-cpu:显示CPU占用最大的进程
--top-io:显示正常IO最大的进程
--top-mem:显示占用最多内存的进程
5、dstat常用命令
(1)CPU使用情况查看
查看CPU使用情况,执行命令dstat -c。显示各个信息为CPU用户占用,系统占用,空闲,等待,中断,软件中断等信息。dstat -c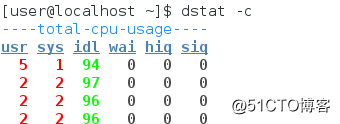
(2)磁盘使用情况查看 dstat -d
(3)网络状态查看dstat -n
(4)内存使用信息查看dstat -m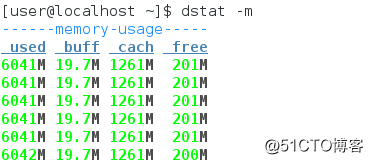
(5)系统平均负载查看dstat -l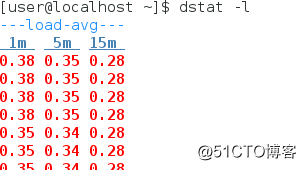
(6)IO使用情况查看dstat -r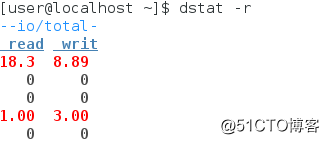
(7)TCP、UDP查看dstat --tcp --udp -t -c 3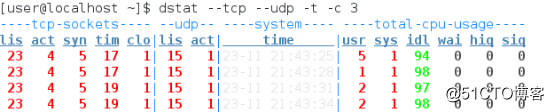
四、iotop
1、iotop简介
iotop是一个用来监视磁盘IO使用状况的top类工具,可监测进程使用的磁盘IO的信息(requires 2.6.20 or later)。
iotop 监控Linux内核输出的IO使用信息,并且显示一个系统中进程或线程的当前IO使用情况。yum -y install iotop
2、iotop命令
iotop [OPTIONS]
--version:显示版本号
-h, --help:显示帮助信息
-o, --only:仅显示正在产生IO操作的进程或者线程,可以随时按o切换。
-b, --batch:运行在非交互式的模式
-n NUM, --iter=NUM:在非交互式模式下,设置显示次数,
-d SEC, --delay=SEC:设置显示的间隔秒数,支持非整数值
-p PID, --pid=PID:只显示指定PID的信息
-u USER, --user=USER:显示指定用户的进程信息
-P, --processes:只显示进程,一般为显示所有的线程
-a, --accumulated:显示从iotop启动后每个线程完成了的IO总数
-k, --kilobytes:以KB显示
-t, --time:在每一行前添加一个当前的时间
3、iotop快捷键
r:反向排序,
o:切换至选项--only,
p:切换至--processes选项,
a:切换至--accumulated选项
q:退出
i:改变线程的优先级
4、iotop常用命令
iotop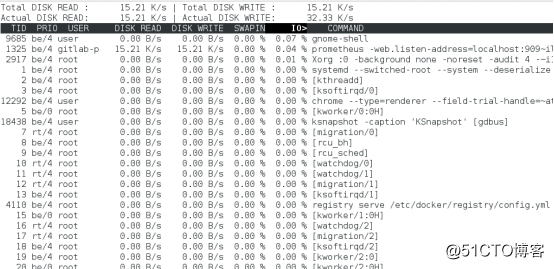
第一行表示进程的磁盘读写大小总数。
第二行表示磁盘真实的读写大小总数。由于缓存、缓冲区、IO合并等因素的影响,可能并不相等于进程的磁盘读写大小总数。
进程部分,从各个角度来分别表示进程的IO情况,包括线程ID、IO 优先级、每秒读磁盘的大小、每秒写磁盘的大小、换入和等待IO的时钟百分比等。iotop -b -o -n 2 -d 5 -t
使用非交互模式将iotop命令输出信息写入日志。
五、blktrace
1、blktrace简介
blktrace是一个针对Linux内核中块设备IO层的跟踪工具,用来收集磁盘IO信息中当IO进行到块设备层(block)时的详细信息(如IO请求提交、入队、合并、完成等信息),是由Linux内核块设备层的维护者开发的,目前已经集成到内核2.6.17及其后内核版本中。blktrace可以获取IO请求队列的各种详细的情况,包括进行读写的进程名称、进程号、执行时间、读写的物理块号、块大小等。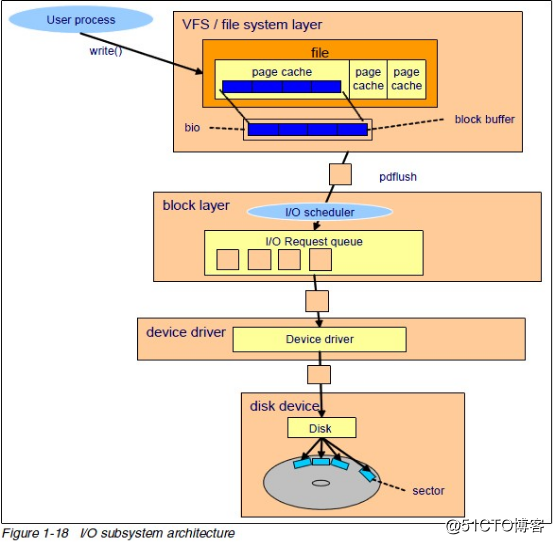
2、blktrace安装
在线安装:yum install blktrace
3、blktrace工作原理
(1)blktrace测试时会分配物理机上逻辑CPU数量个线程,并且每一个线程绑定一个逻辑CPU来收集数据。
(2)blktrace在debugfs挂载的路径(默认/sys/kernel/debug)下每个线程产生一个文件,然后调用ioctl函数,通过系统调用交由内核处理,由内核经由debugfs文件系统往文件描述符写入数据。
(3)blktrace需要结合blkparse使用,由blkparse来解析blktrace产生的特定格式的二进制数据。
(4)blkparse仅打开blktrace产生的文件,从文件里面取数据进行解析展示。
4、blktrace命令
blktrace -d dev [ -r debugfs_path ] [ -o output ] [ -w time ] [ -a action ] [ -A action_mask ] [ -v ]
-A hex-mask:设置过滤信息mask成十六进制mask
-a mask:添加mask到当前的过滤器
-b size:指定缓存大小for提取的结果,默认为512KB
-d dev:添加一个设备追踪
-I file:增加文件的设备到追踪
-k:杀掉正在运行的追踪进程
-n num-sub:指定缓冲池大小,默认为4个子缓冲区
-o file:指定输出文件的名字
-r rel-path:指定的debugfs挂载点
-V:打印版本号
-w seconds:设置运行的时间sudo blktrace -d /dev/sda -o test1
5、blkparse
blkparse是分析和展示blktrace采集数据的工具。blktrace -d /dev/sda -o - | blkparse -i -
将blktrace结果输出到屏幕,然后blkparse将屏幕中的blktrace结果作为分析的输入,最后将分析的结果输出到屏幕。blktrace -d /dev/sda |blkparse -i -
将blktrace结果输出到本地目录,文件名为sda.blktrace.x,blkparse -i trace
将trace文件作为blkparse输入,blkparse结果输出到屏幕。blkparse -i trace -o outout
将trace文件作为blkparse输入,将分析结果输出到output文件。
六、perf
1、perf简介
perf是 Linux Kernel 2.6.31以后内置的性能分析工具,以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。perf top能够实时显示占用CPU时钟最多的函数或者指令,可以用来查找热点函数。
2、perf命令
perf [--version] [--help] [OPTIONS] COMMAND [ARGS]
annotate:解析perf.data文件,显示被注释的代码。
archive:根据perf.data数据文件记录的build-id,将所有被采样的elf文件打包,可以在其它机器上分析数据文件中记录的采样数据。
bench:perf中内置的benchmark,包括针对调度器和内存管理子系统的benchmark。
buildid-cache:管理perf的buildid缓存,每个elf文件都有一个唯一buildid,buildid被perf用来关联性能数据与elf文件。
buildid-list:列出数据文件中记录的所有buildid。
config:在配置文件获取和设置变量
data: Data file related processing
diff: 对比两个perf.data数据文件的差异,给出每个符号(函数)在热点分析上的具体差异。
evlist:列出数据文件perf.data中所有性能事件。
inject:读取perf record工具记录的事件流,并将其定向到标准输出。在被分析代码中的任何一点,都可以向事件流中注入其它事件。
kmem: 针对内核内存(slab)子系统进行追踪测量的工具
kvm:追踪测试运行在KVM虚拟机上的Guest OS。
list:列出当前系统支持的所有性能事件,包括硬件性能事件、软件性能事件以及检查点。
lock:分析内核中的锁信息,包括锁的争用情况,等待延迟等。
mem:分析内存访问情况
record:收集采样信息,并将其记录在perf.data数据文件中。
report:读取perf record创建的数据文件,并给出热点分析结果。
sched:针对调度器子系统的分析工具。
script:执行perl或python写的功能扩展脚本、生成脚本框架、读取数据文件中的数据信息等。
stat:系统全局性能统计工具
test:perf对当前软硬件平台进行健全性测试,测试当前软硬件平台是否能支持perf所有功能。
timechart:针对测试期间系统行为进行可视化的工具
top:系统性能实时分析工具
probe:定义动态检查点。
trace:追踪系统调用工具
3、perf record
perf record [<options>] [<command>]
-e event:指定性能事件(多个用,分隔列表)
-p pid:指定待分析进程pid(多个用,分隔列表)
-t tid:指定待分析线程tid(多个用,分隔列表)
-u uid:指定收集用户数据,uid为名称或数字
-a:从所有CPU收集系统数据
-g:开启函数调用关系图记录
-C cpu-list:只统计指定CPU列表的数据,如:0,1,3或1-2
-r RT priority:perf程序以SCHED_FIFO实时优先级RT priority运行,值越大进程优先级越高(即nice值越小)
-c count: 事件每发生count次采一次样
-F n:每秒采样n次
-o output.data:指定输出文件output.data,默认输出到perf.data
4、perf top
perf top [<options>]
-e event:指定采样分析的性能事件。
-p pid:指定目标进程
-k pat:指定带符号表的内核映像所在路径
-K:不显示属于内核或模块的符号。
-U:不显示属于用户态程序的符号。
-d n:刷新周期,默认为2s,默认每2s从mmap的内存区域读取一次性能数据。
-g:得到函数的调用关系图。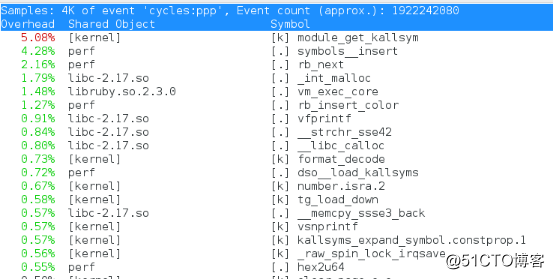
第一行分别是采样数(Samples)、事件类型(event)和事件总数量(Event count)。perf总共采集4000个CPU时钟事件,而总事件数则为1922242080。如果采样数过少,后序数据无实际参考价值。
第一列Overhead是symbol的性能事件在所有采样中的比例,用百分比来表示。
第二列Shared是函数或指令所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等。
第三列Object是动态共享对象的类型。[.]表示用户空间的可执行程序、或者动态链接库,而[k]表示内核空间。
第四列Symbol是符号名,即函数名。当函数名未知时,用十六进制的地址来表示。
perf top可以实时展示系统的性能信息,但并不保存数据,因此不能用于离线或者后续分析。perf record提供了保存数据的功能,保存后的数据需要使用perf report解析展示。
perf top 和 perf record加上-g参数,开启调用关系采样,可以根据调用链来分析性能问题。
perf工具看不到函数名,只能看到一些 16 进制格式的函数地址。其实,只要你观察一下 perf 界面最下面的那一行,就会发现一个警告信息:
perf找不到待分析进程依赖库时,不会打印出函数名称,只会显示16进制格式的函数地址。
如果应用程序在编译发布时,使用strip删除ELF二进制文件的符号表,perf也只能显示函数地址。
5、perf report
perf report [options]
-i filename:指定输入文件,默认为perf.data