随着容器技术的迅速发展,Kubernetes 已然成为大家追捧的容器集群管理系统。Prometheus 作为生态圈 Cloud Native Computing Foundation(简称:CNCF)中的重要一员,其活跃度仅次于 Kubernetes, 现已广泛用于 Kubernetes 集群的监控系统中。本文将简要介绍 Prometheus 的组成和相关概念,以便开发人员和云平台运维人员可以快速的掌握 Prometheus。
Prometheus 简介
Prometheus 是一套开源的系统监控报警框架。它启发于 Google 的 borgmon 监控系统,由工作在 SoundCloud 的 google 前员工在 2012 年创建,作为社区开源项目进行开发,并于 2015 年正式发布。2016 年,Prometheus 正式加入 Cloud Native Computing Foundation,成为受欢迎度仅次于 Kubernetes 的项目。
作为新一代的监控框架,Prometheus 具有以下特点:
强大的多维度数据模型:
时间序列数据通过 metric 名和键值对来区分。
所有的 metrics 都可以设置任意的多维标签。
数据模型更随意,不需要刻意设置为以点分隔的字符串。
可以对数据模型进行聚合,切割和切片操作。
支持双精度浮点类型,标签可以设为全 unicode。
灵活而强大的查询语句(PromQL):在同一个查询语句,可以对多个 metrics 进行乘法、加法、连接、取分数位等操作。
易于管理: Prometheus server 是一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储。
高效:平均每个采样点仅占 3.5 bytes,且一个 Prometheus server 可以处理数百万的 metrics。
使用 pull 模式采集时间序列数据,这样不仅有利于本机测试而且可以避免有问题的服务器推送坏的 metrics。
可以采用 push gateway 的方式把时间序列数据推送至 Prometheus server 端。
可以通过服务发现或者静态配置去获取监控的 targets。
有多种可视化图形界面。
易于伸缩。
需要指出的是,由于数据采集可能会有丢失,所以 Prometheus 不适用对采集数据要 100% 准确的情形。但如果用于记录时间序列数据,Prometheus 具有很大的查询优势,此外,Prometheus 适用于微服务的体系架构。
Prometheus 组成及架构
Prometheus 生态圈中包含了多个组件,其中许多组件是可选的:
Prometheus Server: 用于收集和存储时间序列数据。
Client Library: 客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
Push Gateway: 主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus server 端推送它们的 metrics。这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。
Exporters: 用于暴露已有的第三方服务的 metrics 给 Prometheus。
Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook 等。
一些其他的工具。
如下为Prometheus架构图: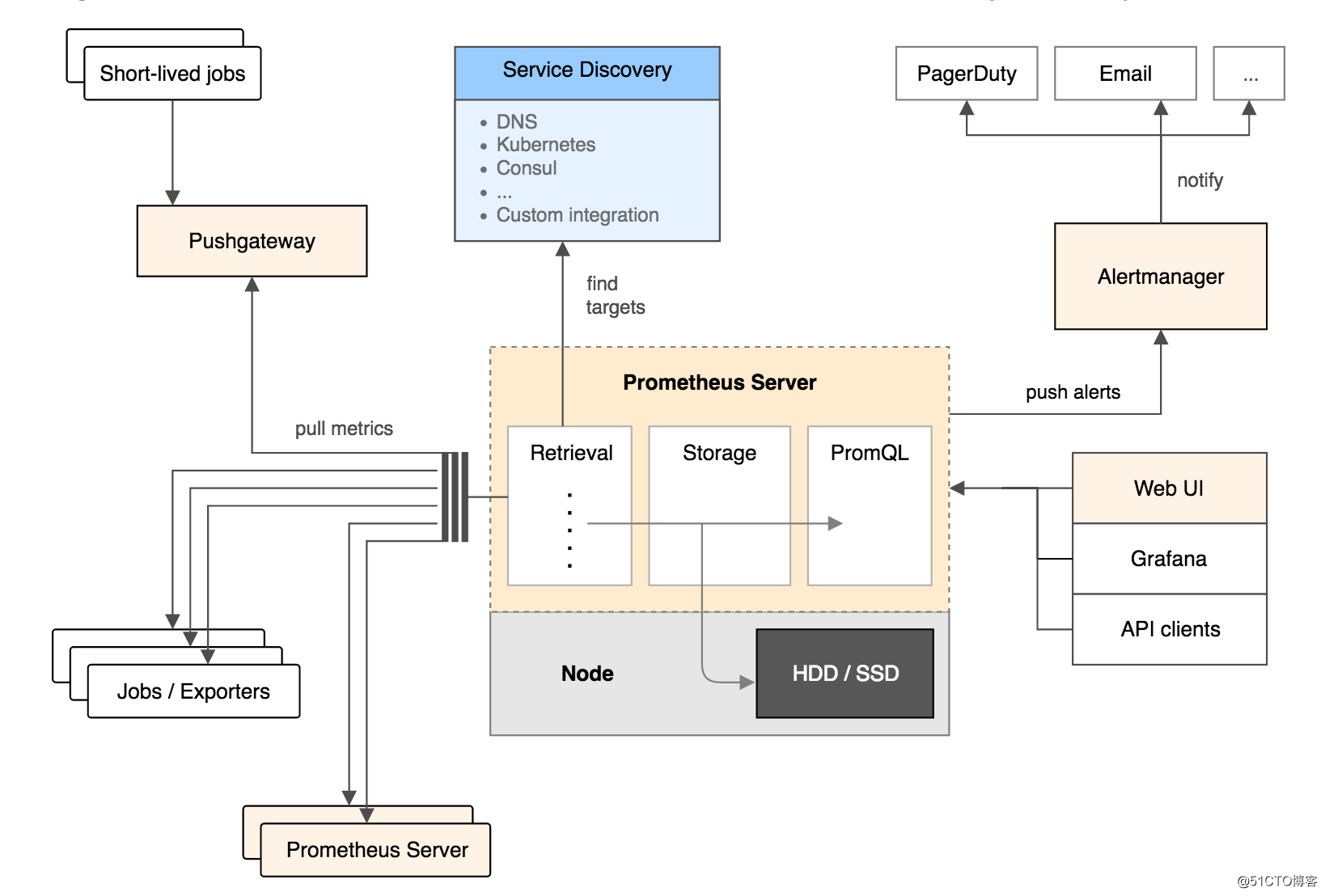
从上图可以看出,Prometheus 的主要模块包括:Prometheus server, exporters, Pushgateway, PromQL, Alertmanager 以及图形界面。
其大概的工作流程是:
- Prometheus server 定期从配置好的 jobs 或者 exporters 中拉 metrics,或者接收来自 Pushgateway 发过来的 metrics,或者从其他的 Prometheus server 中拉 metrics。
- Prometheus server 在本地存储收集到的 metrics,并运行已定义好的 alert.rules,记录新的时间序列或者向 Alertmanager 推送警报。
- Alertmanager 根据配置文件,对接收到的警报进行处理,发出告警。
- 在图形界面中,可视化采集数据。
Prometheus 相关概念
下面将对 Prometheus 中的数据模型,metric 类型以及 instance 和 job 等概念进行介绍,以便读者在 Prometheus 的配置和使用中可以有一个更好的理解。
数据模型
Prometheus 中存储的数据为时间序列,是由 metric 的名字和一系列的标签(键值对)唯一标识的,不同的标签则代表不同的时间序列。
metric 名字:该名字应该具有语义,一般用于表示 metric 的功能,例如:httprequeststotal, 表示 http 请求的总数。其中,metric 名字由 ASCII 字符,数字,下划线,以及冒号组成,且必须满足正则表达式 [a-zA-Z:][a-zA-Z0-9:]。
标签:使同一个时间序列有了不同维度的识别。例如 httprequeststotal{method=”Get”} 表示所有 http 请求中的 Get 请求。当 method=”post” 时,则为新的一个 metric。标签中的键由 ASCII 字符,数字,以及下划线组成,且必须满足正则表达式 [a-zA-Z:][a-zA-Z0-9:]。
样本:实际的时间序列,每个序列包括一个 float64 的值和一个毫秒级的时间戳。
格式:{=,…},例如:http_requests_total{method=”POST”,endpoint=”/api/tracks”}。
四种 Metric 类型
Prometheus 客户端库主要提供四种主要的 metric 类型:
- Counter
一种累加的 metric,典型的应用如:请求的个数,结束的任务数, 出现的错误数等等。
例如,查询 http_requests_total{method=”get”, job=”Prometheus”, handler=”query”} 返回 8,10 秒后,再次查询,则返回 14。
- Gauge
一种常规的 metric,典型的应用如:温度,运行的 goroutines 的个数。
可以任意加减。
例如:go_goroutines{instance=”172.17.0.2″, job=”Prometheus”} 返回值 147,10 秒后返回 124。
- Histogram
可以理解为柱状图,典型的应用如:请求持续时间,响应大小。
可以对观察结果采样,分组及统计。
例如,查询 http_request_duration_microseconds_sum{job=”Prometheus”, handler=”query”} 时,返回结果如下: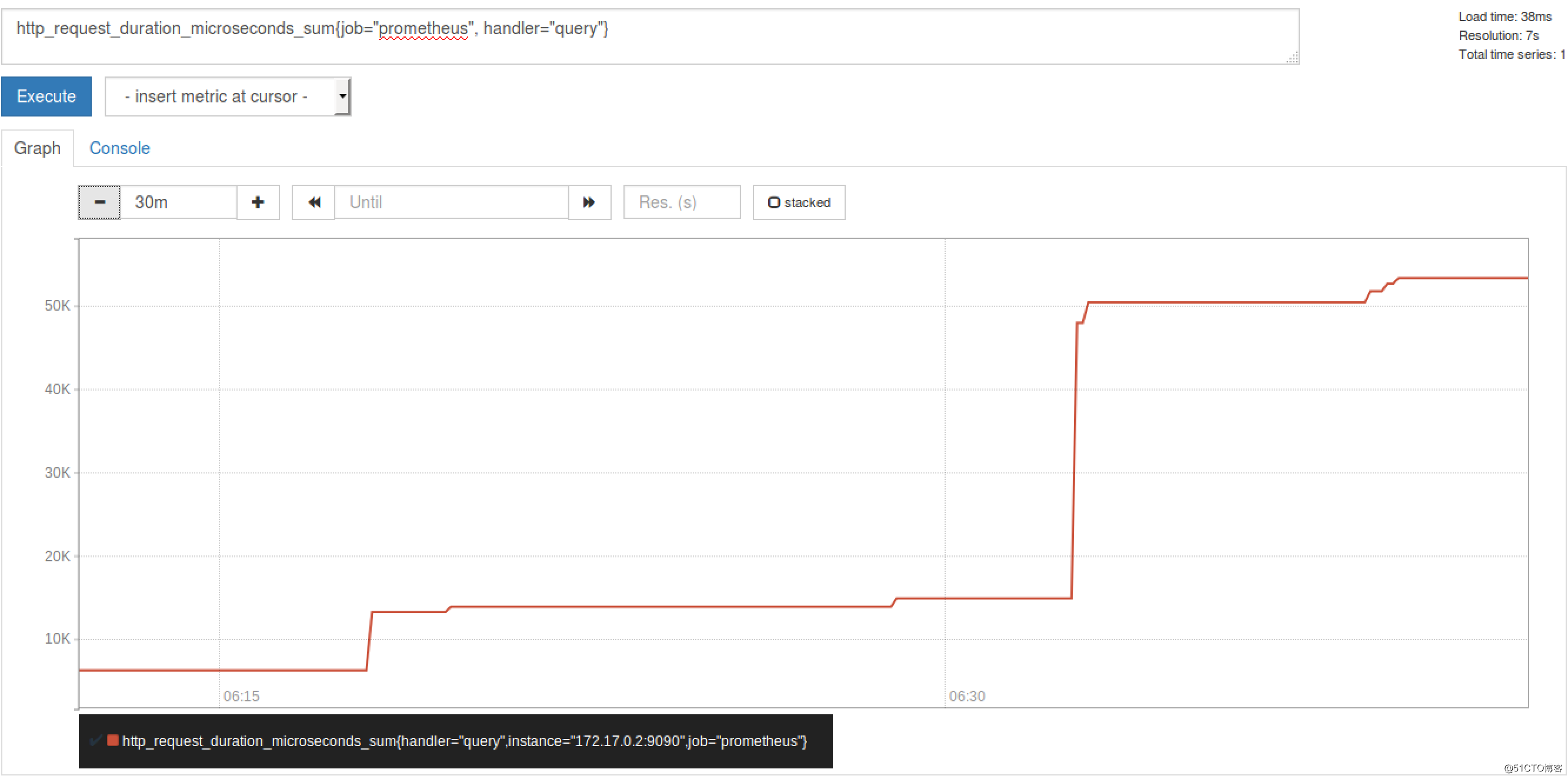
图 2. Histogram metric 返回结果图
Histogram metric 返回结果图
- Summary
类似于 Histogram, 典型的应用如:请求持续时间,响应大小。
提供观测值的 count 和 sum 功能。
提供百分位的功能,即可以按百分比划分跟踪结果。
instance 和 jobs
instance: 一个单独 scrape 的目标, 一般对应于一个进程。
jobs: 一组同种类型的 instances(主要用于保证可扩展性和可靠性),例如:
清单 1. job 和 instance 的关系
job: api-server
instance 1: 1.2.3.4:5670
instance 2: 1.2.3.4:5671
instance 3: 5.6.7.8:5670
instance 4: 5.6.7.8:5671显示更多
当 scrape 目标时,Prometheus 会自动给这个 scrape 的时间序列附加一些标签以便更好的分别,例如: instance,job。
下面以实际的 metric 为例,对上述概念进行说明。
图 3. Metrics 示例
Metrics 示例
如上图所示,这三个 metric 的名字都一样,他们仅凭 handler 不同而被标识为不同的 metrics。这类 metrics 只会向上累加,是属于 Counter 类型的 metric,且 metrics 中都含有 instance 和 job 这两个标签。