前言
正是由于非线性激活函数的返回叠加,才使得神经网络有足够的非线性拟合,选择不同的激活函数将影响整个深度神经网络的效果。
提示:以下是本篇文章正文内容,下面案例可供参考
一、sigmoid函数

sigmoid函数曾经是传统神经网络中使用频率最高的函数,其特点和优势很明显:可以将任意输入映射到[0,1]的值域范围,是偏于求导的平滑函数,
但是有三个缺点造成了现在几乎没有神经网络用其做激活函数:
1,容易过饱和,换句话说,sigmoid函数只有在坐标原点附近有明显的梯度变化,其两端变化非常缓慢,这会导致在反向传播过程中更新参数是梯度弥散的现象,并该现象随着网络层数的加深而变得更加严重。
2,函数输出并不是中心对称的,即sigmoid函数的输出值恒大于0,这会导致模型训练的收敛速度变慢。
3,所使用的幂运算相对耗时。
二、tanh函数

tanh函数很像是sigmoid函数的放大版。在实际使用中要略微优于sigmoid函数,因为它解决的中心对称问题。
三,ReLU函数

ReLU函数目前是神经网络中最流行,使用最广泛的函数。
其本质上是一个取最大值函数,非全区间可导。
ReLU在正区间内解决了梯度消失问题,只需要判断输入是否大于0,所以计算速度非常快(解决了问题1,3)
但它的输出同样也不是中心对称的。与此之外还产生了一个新问题:神经元失活(dead relu problem)即某些神经元可以永远不会参与计算,原因有二:
参数初始化不合适,没能达到激活值,而且这些神经元在反向传播过程中也不会被激活。
学习速率太高,从而导致训练过程中参数更新过大。在不解决这些问题的情况下,网络中大概会有10-20%的神经元失活。
解决方案:可采用Xavier初始化;Adagrad自动调节学习速率
四, Leaky ReLU
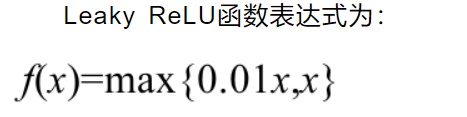

理论和实践矛盾,这就很奇怪~这也是为什么relu更流行的原因
五,ELU指数线性单元函数&SELU函数

并不常用
六,softmax函数

相比于ELU和SELU更为常用一样,但依然不如relu