之前在只看了一遍吴恩达神经网络下写了一篇Darknet_yolov2的综述,最近接着往下学时发现很多基础的概念不是很懂,所以这篇解决一下寸疑问题
1.卷积滑动窗口
滑动窗口大家都了解的,从图片的左上角开始到右下角,直到这个窗口滑过图像的每一个角落。卷积滑动窗口就是在此基础上,用卷积层代替全连接层,输出114类似的张量,算法的效率相比滑动窗口提高了很多 ,但是不能准确输出boundingbox,无法精确的框出object的位置。
2.yologridcell检测
yolo和上述不同的是,输入一整张图片,将图片分为33(比如)的单元格,对每一个单元格应用图像定位算法,将objetc分配到其中点所在的gridcell上,输出boundingbox[bx,by,bh,bw]

3.交并比(IOU)
边界框的准确度可以用IOU进行表示,IOU等于计算两个边界框交集和并集之比;
一般约定,在检测中,IOU>0.5,则认为检测正确,一般阈值设为0.5。
4.非极大值抑制(NMS)
这个算法不单单是针对Yolo算法的,而是所有的检测算法中都会用到。NMS算法主要解决的是一个目标被多次检测的问题,首先从所有的检测框中找到置信度最大的那个框,然后依次计算其与剩余框的IOU,如果其值大于一定阈值(重合度过高),那么就将该框剔除;然后对剩余的检测框重复上述过程,直到处理完所有的检测框。
但是对于Yolo算法,其却采用了另外一个不同的处理思路(至少从C源码看是这样的),其区别就是先使用NMS,然后再确定各个box的类别。对于98个boxes,首先将小于置信度阈值的值归0,然后分类别地对置信度值采用NMS,这里NMS处理结果不是剔除,而是将其置信度值归为0。最后才是确定各个box的类别,当其置信度值不为0时才做出检测结果输出。这个策略不是很直接,但是貌似Yolo源码就是这样做的。Yolo论文里面说NMS算法对Yolo的性能是影响很大的,所以可能这种策略对Yolo更好。
参考转载于,写的很详细https://zhuanlan.zhihu.com/p/32525231
贴下源码:`static void sort(int n, const float x, int* indices)
{
// 排序函数,排序后进行交换的是indices中的数据
// n:排序总数// x:带排序数// indices:初始为0~n-1数目
static void sort(int n, const float* x, int* indices)
{
// 排序函数,排序后进行交换的是indices中的数据
// n:排序总数// x:带排序数// indices:初始为0~n-1数目
int i, j;
for (i = 0; i < n; i++)
for (j = i + 1; j < n; j++)
{
if (x[indices[j]] > x[indices[i]])
{
//float x_tmp = x[i];
int index_tmp = indices[i];
//x[i] = x[j];
indices[i] = indices[j];
//x[j] = x_tmp;
indices[j] = index_tmp;
}
}
}
int nonMaximumSuppression(int numBoxes, const CvPoint *points,
const CvPoint *oppositePoints, const float *score,
float overlapThreshold,
int *numBoxesOut, CvPoint **pointsOut,
CvPoint **oppositePointsOut, float **scoreOut)
{
// numBoxes:窗口数目// points:窗口左上角坐标点// oppositePoints:窗口右下角坐标点
// score:窗口得分// overlapThreshold:重叠阈值控制// numBoxesOut:输出窗口数目
// pointsOut:输出窗口左上角坐标点// oppositePoints:输出窗口右下角坐标点
// scoreOut:输出窗口得分
int i, j, index;
float* box_area = (float*)malloc(numBoxes * sizeof(float)); // 定义窗口面积变量并分配空间
int* indices = (int*)malloc(numBoxes * sizeof(int)); // 定义窗口索引并分配空间
int* is_suppressed = (int*)malloc(numBoxes * sizeof(int)); // 定义是否抑制表标志并分配空间
// 初始化indices、is_supperssed、box_area信息
for (i = 0; i < numBoxes; i++)
{
indices[i] = i;
is_suppressed[i] = 0;
box_area[i] = (float)( (oppositePoints[i].x - points[i].x + 1) *
(oppositePoints[i].y - points[i].y + 1));
}
// 对输入窗口按照分数比值进行排序,排序后的编号放在indices中
sort(numBoxes, score, indices);
for (i = 0; i < numBoxes; i++) // 循环所有窗口
{
if (!is_suppressed[indices[i]]) // 判断窗口是否被抑制
{
for (j = i + 1; j < numBoxes; j++) // 循环当前窗口之后的窗口
{
if (!is_suppressed[indices[j]]) // 判断窗口是否被抑制
{
int x1max = max(points[indices[i]].x, points[indices[j]].x); // 求两个窗口左上角x坐标最大值
int x2min = min(oppositePoints[indices[i]].x, oppositePoints[indices[j]].x); // 求两个窗口右下角x坐标最小值
int y1max = max(points[indices[i]].y, points[indices[j]].y); // 求两个窗口左上角y坐标最大值
int y2min = min(oppositePoints[indices[i]].y, oppositePoints[indices[j]].y); // 求两个窗口右下角y坐标最小值
int overlapWidth = x2min - x1max + 1; // 计算两矩形重叠的宽度
int overlapHeight = y2min - y1max + 1; // 计算两矩形重叠的高度
if (overlapWidth > 0 && overlapHeight > 0)
{
float overlapPart = (overlapWidth * overlapHeight) / box_area[indices[j]]; // 计算重叠的比率
if (overlapPart > overlapThreshold) // 判断重叠比率是否超过重叠阈值
{
is_suppressed[indices[j]] = 1; // 将窗口j标记为抑制
}
}
}
}
}
}
*numBoxesOut = 0; // 初始化输出窗口数目0
for (i = 0; i < numBoxes; i++)
{
if (!is_suppressed[i]) (*numBoxesOut)++; // 统计输出窗口数目
}
*pointsOut = (CvPoint *)malloc((*numBoxesOut) * sizeof(CvPoint)); // 分配输出窗口左上角坐标空间
*oppositePointsOut = (CvPoint *)malloc((*numBoxesOut) * sizeof(CvPoint)); // 分配输出窗口右下角坐标空间
*scoreOut = (float *)malloc((*numBoxesOut) * sizeof(float)); // 分配输出窗口得分空间
index = 0;
for (i = 0; i < numBoxes; i++) // 遍历所有输入窗口
{
if (!is_suppressed[indices[i]]) // 将未发生抑制的窗口信息保存到输出信息中
{
(*pointsOut)[index].x = points[indices[i]].x;
(*pointsOut)[index].y = points[indices[i]].y;
(*oppositePointsOut)[index].x = oppositePoints[indices[i]].x;
(*oppositePointsOut)[index].y = oppositePoints[indices[i]].y;
(*scoreOut)[index] = score[indices[i]];
index++;
}
}
free(indices); // 释放indices空间
free(box_area); // 释放box_area空间
free(is_suppressed); // 释放is_suppressed空间
return LATENT_SVM_OK;
}
5.置信度
所谓置信度其实包含两个方面,一是这个边界框含有目标的可能性大小Pr(obj),二是这个边界框的准确度。 当该边界框是背景时(即不包含目标),此时 Pr(obj)=0 。而当该边界框包含目标时,Pr(obj)=1 。边界框的准确度可以用预测框与实际框(ground truth)的IOU(intersection over union,交并比)来表征,记为IOU 。因此置信度可以定义为 Pr(obg)IOU。很多人可能将Yolo的置信度看成边界框是否含有目标的概率,但是其实它是两个因子的乘积,预测框的准确度也反映在里面。边界框的大小与位置可以用4个值来表征:[x,y,w,h],其中 [x,y] 是边界框的中心坐标,而 w 和 h 是边界框的宽与高。这样理论上4个元素的大小应该在 [0-1] 范围。这样,每个边界框的预测值实际上包含5个元素:[x,y,w,h,c] ,其中前4个表征边界框的大小与位置,而最后一个值是置信度。
做图像检测时,图片上框出来的除了boundingbox还有就是置信度的大小。
6.还有分类问题,对于每一个单元格其还要给出预测出类别概率值,其表征的是由该单元格负责预测的边界框其目标属于各个类别的概率。但是这些概率值其实是在各个边界框置信度下的条件概率。值得注意的是,不管一个单元格预测多少个边界框,其只预测一组类别概率值,这是Yolo算法的一个缺点,在后来的改进版本中,Yolo9000是把类别概率预测值与边界框是绑定在一起的。同时,我们可以计算出各个边界框类别置信度(class-specific confidence scores)
总结一下,每个单元格需要预测 [B5+C] 个值。如果将输入图片划分为 [SS] 网格,那么最终预测值为 [SS*(B*5+C)] 大小的张量
以yolov1为例,检测20类,B=2,S=7,前20个元素是类别概率值,然后2个元素是边界框置信度,两者相乘可以得到类别置信度,最后8个元素是边界框的 大小
7.构建障碍物识别检测算法(两者区别)
创建标签训练集:
CNN的做法是挑选并裁剪训练集图片,尽量使object位于中心;
Yolo做法是将一整张图片放入,从中框选出图片中的object。对于裁剪,我我认为框选图片打标签,yolo对于训练权重无论是准确率还是挑选图片,都更简易一些
8.准确率,召回率,AP,Map
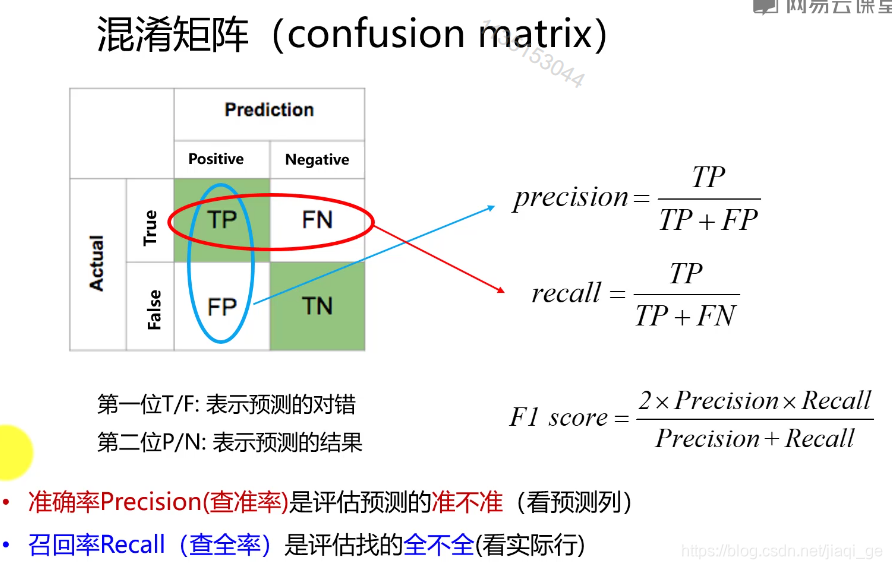 混淆矩阵中,True/False,表示预测的对错;Positive/Negative表示预测的结果
混淆矩阵中,True/False,表示预测的对错;Positive/Negative表示预测的结果
准确率:precision
recall:查全率,从图片中找到的样本/总样本
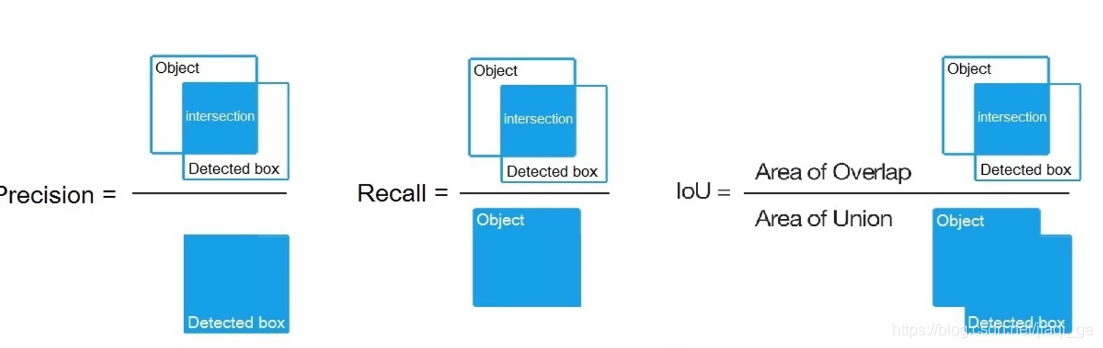
 查全率/召回率和IOU可以一起用这样的方式理解
查全率/召回率和IOU可以一起用这样的方式理解
 AP:平均精度,衡量的是学习出来的模型在每个类别上的好坏
AP:平均精度,衡量的是学习出来的模型在每个类别上的好坏
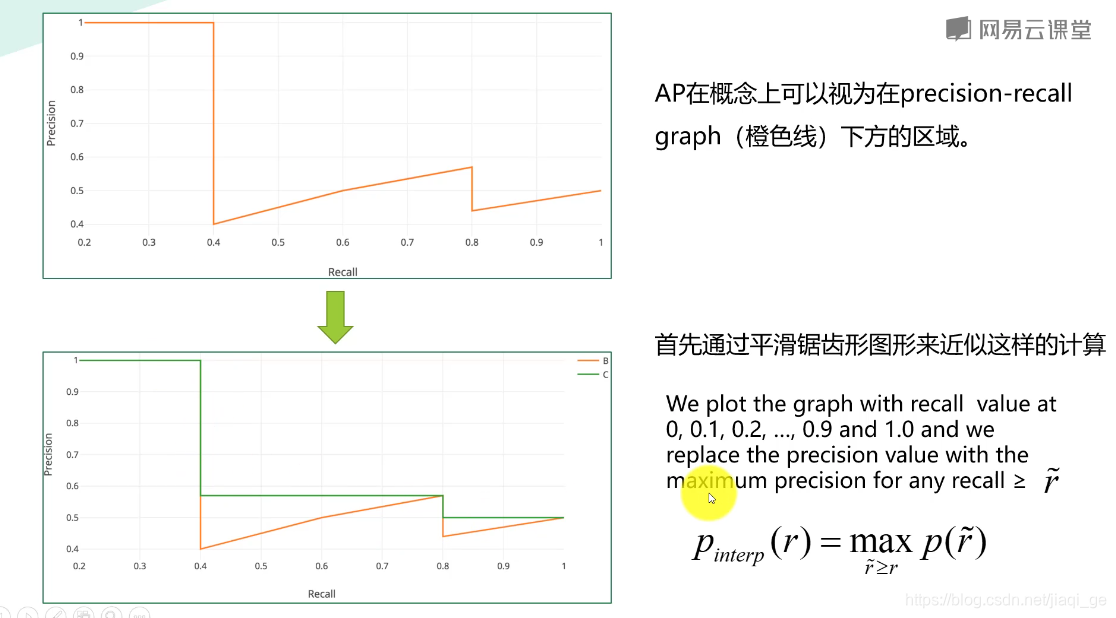
Map:算出recall从0到 1时的准确率,计算准确率的平均值,对所有类别求平均,以P,R作为指标都不够全面,所以以PR曲线下的面积当作尺度。