https://blog.csdn.net/u010463032/article/details/78953436
引言
Spark 从1.6.x 开始对 JVM 的内存使用作出了一种全新的改变,Spark 1.6.x 以前是基于静态固定的JVM内存使用架构和运行机制,如果你不知道 Spark 到底对 JVM 是怎么使用,你怎么可以很有信心地或者是完全确定地掌握和控制数据的缓存空间呢,所以掌握Spark对JVM的内存使用内幕是至关重要的。很多人对 Spark 的印象是:它是基于内存的,而且可以缓存一大堆数据,显现 Spark 是基于内存的观点是错的,Spark 只是优先充分地利用内存而已。如果你不知道 Spark 可以缓存多少数据,你就误乱地缓存数据的话,肯定会有问题。
在数据规模已经确定的情况下,你有多少 Executor 和每个 Executor 可分配多少内存 (在这个物理硬件已经确定的情况下),你必须清楚知道你的內存最多能够缓存多少数据;在 Shuffle 的过程中又使用了多少比例的缓存,这样对于算法的编写以及业务实现是至关重要的!!!
文章的后部份会介绍 Spark 2.x 版本 JVM 的内存使用比例,它被称之为 Spark Unified Memory,这是统一或者联合的意思,但是 Spark 没有用 Shared 这个字,因为 A 和 B 进行 Unified 和 A 和 B 进行 Shared 其实是两个不同的概念, Spark 在运行的时候会有不同类型的 OOM,你必须搞清楚这个 OOM 背后是由什么导致的。
比如说我们使用算子 mapPartition 的时候,一般会创建一些临时对象或者是中间数据,你这个时候使用的临时对象和中间数据,是存储在一个叫 UserSpace 里面的用户操作空间,那你有没有想过这个空间的大小会导致应用程序出现 OOM 的情况,
在 Spark 2.x 中 Broadcast 的数据是存储在什么地方;仅仅为每个节点拷贝一份,更大的用途是优化性能,减少网络传输以及内存损耗。每个节点上只会有一个副本, 而不会为每个 task 都拷贝一份副本
ShuffleMapTask 的数据又存储在什么地方,可能你会认为 ShuffleMapTask 的数据是缓存在 Cache 中。
这篇文章会介绍 JVM 在 Spark 1.6.X 以前和 2.X 版本对 Java 堆的使用,还会逐一解密上述几个疑问,也会简单介绍 Spark 1.6.x 以前版本在 Spark On Yarn 上内存的使用案例
JVM 内存使用架构剖析
JVM 有很多不同的区,最开始的时候,它会通过类装载器把类加载进来,在运行期数据区中有 "本地方法栈","程序计数器","Java 栈"、"Java 堆"和"方法区"以及本地方法接口和它的本地库。从 Spark 的角度来谈代码的运行和数据的处理,主要是谈 Java 堆 (Heap) 空间的运用。下图是JVM 内存架构图
- 本地方法栈:这个是在迭归的时候肯定是至关重要的;
- 程序计数器:这是一个全区计数器,对于线程切换是至关重要的;
- Java 栈 (Stack):Stack 区属于线程私有,高效的程序一般都是并发的,每个线程都会包含一个 Stack 区域,Stack 区域中含有基本的数据类型以及对象的引用,其它线程均不能直接访问该区域;Java 栈分为三大部份:基本数据类型区域、操作指令区域、上下文等;
- Java 堆 (Heap):存储的全部都是 Object 对象实例,对象实例中一般都包含了其数据成员以及与该对象对应类的信息,它会指向类的引用一个,不同线程肯定要操作这个对象;一个 JVM 实例在运行的时候只有一个 Heap 区域,而且该区域被所有的线程共享;补充说明:垃圾回收是回收堆 (heap) 中内容,堆上才有我们的对象。
- 方法区:又名静态成员区域,包含整个程序的 class、static 成员等,类本身的字节码是静态的;它会被所有的线程共享和是全区级别的;
Spark 1.6.x 和 2.x 的 JVM 剖析
Spark JVM 到底可以缓存多少数据
下图显示的是Spark 1.6.x 以前版本对 Java 堆 (heap) 的使用情况,左则是 Storage 对内存的使用,右则是 Shuffle 对内存的使用,这叫 Static Memory Management,数据处理以及类的实体对象都存放在 JVM 堆 (heap) 中。
Spark 1.6.x 版本对 JVM 堆的使用
JVM Heap 默认情况下是 512MB,这是取决于 spark.executor.memory 的参数,在回答 Spark JVM 到底可以缓存多少数据这个问题之前,首先了解一下 JVM Heap 在 Spark 中是如何分配内存比例的。无论你定义了 spark.executor.memory 的内存空间有多大,Spark 必然会定义一个安全空间,在默认情况下只会使用 Java 堆上的 90% 作为安全空间,在单个 Executor 的角度来讲,就是 Heap Size x 90%。
埸景一:假设说在一个Executor,它可用的 Java Heap 大小是 10G,实际上 Spark 只能使用 90%,这个安全空间的比例是由spark.storage.safetyFaction 来控制的。(如果你内存的 Heap 非常大的话,可以尝试调高为 95%),在安全空间中也会划分三个不同的空间:一个是 Storage 空间、一个是 Unroll 空间和一个是 Shuffle 空间。
- 安全空间 (safe):计算公式是 spark.executor.memory * spark.storage.safetyFraction。也就是 Heap Size x 90%,在埸景一的例子中是 10 x 0.9 = 9G;
- 缓存空间 (Storage):计算公式是 spark.executor.memory x spark.storage.safetyFraction x spark.storage.memoryFraction。也就是 Heap Size x 90% x 60%;Heap Size x 54%,在埸景一的例子中是 10 x 0.9 x 0.6 = 5.4G;一个应用程序可以缓存多少数据是由 safetyFraction 和 memoryFraction 这两个参数共同决定的。
[下图是 StaticMemoryManager.scala 中的 getMaxStorageMemory 方法] - Unroll 空间:Shuffle 空间:计算公式是 spark.executor.memory x spark.shuffle.memoryFraction x spark.shuffle.safteyFraction。在 Shuffle 空间中也会有一个默认 80% 的安全空间比例,所以应该是 Heap Size x 20% x 80%;Heap Size x 16%,在埸景一的例子中是 10 x 0.2 x 0.8 = 1.6G;从内存的角度讲,你需要从远程抓取数据,抓取数据是一个 Shuffle 的过程,比如说你需要对数据进行排序,显现在这个过程中需要内存空间。
- 计算公式是 spark.executor.memory x spark.storage.safetyFraction x spark.storage.memoryFraction x spark.storage.unrollFraction
也就是 Heap Size x 90% x 60% x 20%;Heap Size x 10.8%,在埸景一的例子中是 10 x 0.9 x 0.6 x 0.2 = 1.8G,你可能把序例化后的数据放在内存中,当你使用数据时,你需要把序例化的数据进行反序例化。
[下图是 StaticMemoryManager.scala 中的 maxUnrollMemory 变量] - 对 cache 缓存数据的影响是由于 Unroll 是一个优先级较高的操作,进行 Unroll 操作的时候会占用 cache 的空间,而且又可以挤掉缓存在内存中的数据 (如果该数据的缓存级别是 MEMORY_ONLY 的话,否则该数据会丢失)。
- 计算公式是 spark.executor.memory x spark.storage.safetyFraction x spark.storage.memoryFraction x spark.storage.unrollFraction
[下图是 StaticMemoryManager.scala 中的 getMaxExecutionMemory 方法]
Spark Unified Memory 原理和运行机制
下图是一种叫联合内存 (Spark Unified Memeory),数据缓存与数据执行之间的内存可以相互移动,这是一种更弹性的方式,下图显示的是 Spark 2.x 版本对 Java 堆 (heap) 的使用情况,数据处理以及类的实体对象存放在 JVM 堆 (heap) 中。
[下图是 Spark 2.x 版本对 JVM 堆 Storage 和 Execution 的使用分布]
Spark 2.x 版本对 JVM 堆的使用
Spark 2.1.0 新型 JVM Heap 分成三个部份:Reserved Memory、User Memory 和 Spark Memory。
- Reserved Memory:默认都是300MB,这个数字一般都是固定不变的,在系统运行的时候 Java Heap 的大小至少为 Heap Reserved Memory x 1.5. e.g. 300MB x 1.5 = 450MB 的 JVM配置。一般本地开发例如说在 Windows 系统上,建义系统至少 2G 的大小。
[下图是 UnifiedMemoryManager.scala 中 UnifiedMemoryManager 伴生对象里的 RESERVED_SYSTEM_MEMORY_BYTES 参数]
SparkMemory空间默认是占可用 HeapSize 的 60%,与上图显示的75%有点不同,当然这个参数是可配置的!!
[下图是 UnifiedMemoryManager.scala 中 UnifiedMemoryManager 伴生对象里的 getMaxMemory 方法] - User Memory:写 Spark 程序中产生的临时数据或者是自己维护的一些数据结构也需要给予它一部份的存储空间,你可以这么认为,这是程序运行时用户可以主导的空间,叫用户操作空间。它占用的空间是 (Java Heap - Reserved Memory) x 25%(默认是25%,可以有参数供调优),这样设计可以让用户操作时所需要的空间与系统框架运行时所需要的空间分离开。
假设 Executor 有 4G 的大小,那么在默认情况下 User Memory 大小是:(4G - 300MB) x 25% = 949MB,也就是说一个 Stage 内部展开后 Task 的算子在运行时最大的大小不能够超过 949MB。例如工程师使用 mapPartition 等,一个 Task 内部所有算子使用的数据空间的大小如果大于 949MB 的话,那么就会出现 OOM。
思考题:有 100个 Executors 每个 4G 大小,现在要处理 100G 的数据,假设这 100G 分配给 100个 Executors,每个 Executor 分配 1G 的数据,这 1G 的数据远远少于 4G Executor 内存的大小,为什么还会出现 OOM 的情况呢?那是因为在你的代码中(e.g.你写的应用程序算子)超过用户空间的限制 (e.g. 949MB),而不是 RDD 本身的数据超过了限制。
- Spark Memeory:系统框架运行时需要使用的空间,这是从两部份构成的,分别是 Storage Memeory 和 Execution Memory。现在 Storage 和 Execution (Shuffle) 采用了 Unified 的方式共同使用了 (Heap Size - 300MB) x 75%,默认情况下 Storage 和 Execution 各占该空间的 50%。你可以从图中可以看出,Storgae 和 Execution 的存储空间可以往上和往下移动。
定义:所谓 Unified 的意思是 Storgae 和 Execution 在适当时候可以借用彼此的 Memory,需要注意的是,当 Execution 空间不足而且 Storage 空间也不足的情况下,Storage 空间如果曾经使用了超过 Unified 默认的 50% 空间的话则超过部份会被强制 drop 掉一部份数据来解决 Execution 空间不足的问题 (注意:drop 后数据会不会丢失主要是看你在程序设置的 storage_level 来决定你是 Drop 到那里,可能 Drop 到磁盘上),这是因为执行(Execution) 比缓存 (Storage) 是更重要的事情。
[下图是 UnifiedMemoryManager.scala 中 UnifiedMemoryManager 伴生对象里的 apply 方法]
但是也有它的基本条件限制,Execution 向 Storage 借空间有两种情况:具体代码实现可以参考源码补充 : Spark 2.1.X 中 Unified 和 Static MemoryManager
[下图是 Execution 向 Storage 借空间的第一种情况]
第一种情况:Storage 曾经向 Execution 借了空间,它缓存的数据可能是非常的多,然后 Execution 又不需要那么大的空间 (默认情况下各占 50%),假设现在 Storage 占了 80%,Execution 占了 20%,然后 Execution 说自己空间不足,Execution 会向内存管理器发信号把 Storgae 曾经占用的超过 50%数据的那部份强制挤掉,在这个例子中挤掉了 30%;
[下图是 Execution 向 Storage 借空间的第二种情况]
第二种情况:Execution 可以向 Storage Memory 借空间,在 Storage Memory 不足 50% 的情况下,Storgae Memory 会很乐意地把剩馀空间借给 Execution。相反当 Execution 有剩馀空间的时候,Storgae 也可以找 Execution 借空间。- Storage Memeory:相当于旧版本的 Storage 空间,在旧版本中 Storage 占了 54% 的 Heap 空间,这个空间会负责存储 Persist、Unroll 以及 Broadcast 的数据。假设 Executor 有 4G 的大小,那么 Storage 空间是:(4G - 300MB) x 75% x 50% = 1423.5MB 的空间,也就是说如果你的内存够大的话,你可以扩播足够大的变量,扩播对于性能提升是一件很重要的事情,因为它所有的线程都是共享的。从算子运行的角度来讲,Spark 会倾向于数据直接从 Storgae Memeory 中抓取过来,这也就所谓的内存计算。
- Execution Memeory:相当于旧版本的 Shuffle 空间,这个空间会负责存储 ShuffleMapTask 的数据。比如说从上一个 Stage 抓取数据和一些聚合的操作、等等。在旧版本中 Shuffle 占了 16% 的 Heap 空间。Execution 如果空间不足的情况下,除了选择向 Storage Memory 借空间以外,也可以把一部份数据 Spill 到磁盘上,但很多时候基于性能调优方面的考虑都不想把数据 Spill 到磁盘上。思考题:你觉得是 Storgae 空间或者是 Execution 空间比较重要呢?
Spark1.6.x 以前 on Yarn 计算内存使用案例
这是一张 Spark 运行在 Yarn 上的架构图,它有 Driver 和 Executor 部份,在 Driver 部份有一个内存控制参数,Spark 1.6.x 以前是spark.driver.memory,在实际生产环境下建义配置成 2G。如果 Driver 比较繁忙或者是经常把某些数据收集到 Driver 上的话,建义把这个参数调大一点。
图的左边是 Executor 部份,它是被 Yarn 管理的,每台机制上都有一个 Node Manager;Node Manager 是被 Resources Manager 管理的,Resources Manager 的工作主要是管理全区级别的计算资源,计算资源核心就是内存和 CPU,每台机器上都有一个 Node Manager 来管理当前内存和 CPU 等资源。Yarn 一般跟 Hadoop 藕合,它底层会有 HDFS Node Manager,主要是负责管理当前机器进程上的数据并且与HDFS Name Node 进行通信。
[下图是 Spark on Yarn 的架构图]
在每个节点上至少有两个进程,一个是 HDFS Data Node,负责管理磁盘上的数据,另外一个是 Yarn Node Manager,负责管理执行进程,在这两个 Node 的下面有两个 Executors,每个 Executor 里面运行的都是 Tasks。从 Yarn 的角度来讲,会配置每个 Executor 所占用的空间,以防止资源竞争,Yarn 里有一个叫 Node Memory Pool 的概念,可以配置 64G 或者是 128G,Node Memory Pool 是当前节点上总共能够使用的内存大小。
图中这两个 Executors 在两个不同的进程中 (JVM#1 和 JVM#2),里面的 Task 是并行运行的,Task 是运行在线程中,但你可以配置 Task 使用线程的数量,e.g. 2条线程或者是4条线程,但默认情况下都是1条线程去处理一个Task,你也可以用 spark.executor.cores 去配置可用的 Core 以及 spark.executor.memory 去配置可用的 RAM 的大小。
在 Yarn 上启动 Spark Application 的时候可以通过以下参数来调优:
- -num-executor 或者 spark.executor.instances 来指定运行时所需要的 Executor 的个数;
- -executor-memory 或者 spark.executor.memory 来指定每个 Executor 在运行时所需要的内存空间;
- -executor-cores 或者是 spark.executor.cores 来指定每个 Executor 在运行时所需要的 Cores 的个数;
- -driver-memory 或者是 spark.driver.memory 来指定 Driver 内存的大小;
- spark.task.cpus 来指定每个 Task 运行时所需要的 Cores 的个数;
场景一:例如 Yarn 集群上有 32 个 Node 来运行的 Node Manager,每个 Node 的内存是 64G,每个 Node 的 Cores 是 32 Cores,假如说每个 Node 我们要分配两个 Executors,那么可以把每个 Executor 分配 28G,Cores 分配为 12 个 Cores,每个 Spark Task 在运行的时候只需要一个 Core 就行啦,那么我们 32 个 Nodes 同时可以运行: 32 个 Node x 2 个 Executors x (12 个 Cores / 1) = 768 个 Task Slots,也就是说这个集群可以并行运行 768 个 Task,如果 Job 超过了 Task 可以并行运行的数量 (e.g. 768) 则需要排队。那么这个集群模可以缓存多少数据呢?从理论上:32 个 Node x 2 个 Executors x 28g x 90% 安全空间 x 60%缓存空间 = 967.68G,这个缓存数量对于普通的 Spark Job 而言是完全够用的,而实际上在运行中可能只能缓存 900G 的数据,900G 的数据从磁盘储存的角度数据有多大呢?还是 900G 吗?不是的,数据一般都会膨胀好几倍,这是和压缩、序列化和反序列化框架有关,所以在磁盘上可能也就 300G 的样子的数据。
总结
了解 Spark Shuffle 中的 JVM 内存使用空间对一个Spark应用程序的内存调优是至关重要的。跟据不同的内存控制原理分别对存储和执行空间进行参数调优:spark.executor.memory, spark.storage.safetyFraction, spark.storage.memoryFraction, spark.storage.unrollFraction, spark.shuffle.memoryFraction, spark.shuffle.safteyFraction。
Spark 1.6 以前的版本是使用固定的内存分配策略,把 JVM Heap 中的 90% 分配为安全空间,然后从这90%的安全空间中的 60% 作为存储空间,例如进行 Persist、Unroll 以及 Broadcast 的数据。然后再把这60%的20%作为支持一些序列化和反序列化的数据工作。其次当程序运行时,JVM Heap 会把其中的 80% 作为运行过程中的安全空间,这80%的其中20%是用来负责 Shuffle 数据传输的空间。
Spark 2.0 中推出了联合内存的概念,最主要的改变是存储和运行的空间可以动态移动。需要注意的是执行比存储有更大的优先值,当空间不够时,可以向对方借空间,但前提是对方有足够的空间或者是 Execution 可以强制把 Storage 一部份空间挤掉。Excution 向 Storage 借空间有两种方式:第一种方式是 Storage 曾经向 Execution 借了空间,它缓存的数据可能是非常的多,当 Execution 需要空间时可以强制拿回来;第二种方式是 Storage Memory 不足 50% 的情况下,Storgae Memory 会很乐意地把剩馀空间借给 Execution。
如果是你的计算比较复杂的情况,使用新型的内存管理 (Unified Memory Management) 会取得更好的效率,但是如果说计算的业务逻辑需要更大的缓存空间,此时使用老版本的固定内存管理 (StaticMemoryManagement) 效果会更好。
https://www.cnblogs.com/chenghaohao/p/8098955.html
Spark内存溢出OOM异常:OutOfMemoryError:GC overhead limit exceeded,Java heap space的解决方案
因为之前spark程序运算量不是特别大,关于提交时申请的集群资源就一直没有变动,后来数据不断增大,导致程序出现以下异常:
java.lang.OutOfMemoryError: Java heap space
java.lang.OutOfMemoryError:GC overhead limit exceeded
spark属性方面调整:
一般这两个异常是由于executor或者driver内存设置的不够导致的,driver设置过小的情况不过相对较小,一般是由于executoer内存不足导致的。 不过不论是哪种情况,我们都可以通过提交命令或者是spark的配置文件指定driver-memory和executor-memory的内存大小来解决问题。
spark-submit --master yarn-cluster --class MAIN_CLASS --executor-memory 10G --executor-cores 10 --driver-memory 2g --name APP_NAME
代码方面调整建议:
其实当数据量越大时,越能体现出代码质量的重要性,所以出现oom的问题也应该从代码方向看一下是否还有调整优化的空间,特别是针对RDD操作的代码。比如,RDD是否还需要重用进行多次操作,如果是我们就可以使用cache()和persist()选择不同的缓存策略,不但提高下次操作时的执行效率,并且还能节省创建RDD占用的内存。
另外Transformation 操作是延迟计算的,也就是说从一个RDD 转换生成另一个 RDD 的转换操作不是马上执行,需要等到有 Action 操作的时候才会真正触发运算。
另外还有算子的选择,例如:mapPartitionsToPair虽然能提高spark的执行效率,但如果数据量过大内存不足在进行算子操作时,也会有可能跑出java heap space异常
另外还有算子内操作尽量能用基本数据类型就不用引用类型,能用数组就不用集合,另外还比如字符串拼接,用StringBuffer代替+连接等等。这些方式不但可以节省空间还能增加算子的执行效率。
一、Spark报错信息
问题一..描述 org.apache.spark.shuffle.FetchFailedException
这种问题一般发生在有大量shuffle操作的时候,task不断的failed,然后又重执行,一直循环下去,非常的耗时。
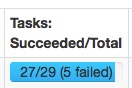
2.报错提示
(1) missing output location
org.apache.spark.shuffle.MetadataFetchFailedException: Missing an output location for shuffle 0 (2) shuffle fetch faild
org.apache.spark.shuffle.FetchFailedException: Failed to connect to spark047215/192.168.47.215:50268 当前的配置为每个executor使用1cpu,5GRAM,启动了20个executor
3.解决方案
一般遇到这种问题提高executor内存即可,同时增加每个executor的cpu,这样不会减少task并行度。
- spark.executor.memory 15G
- spark.executor.cores 3
- spark.cores.max 21
启动的execuote数量为:7个
execuoteNum = spark.cores.max/spark.executor.cores
每个executor的配置:
3core,15G RAM
消耗的内存资源为:105G RAM
15G*7=105G
可以发现使用的资源并没有提升,但是同样的任务原来的配置跑几个小时还在卡着,改了配置后几分钟就结束了。
问题二 . 描述 Executor&Task Lost
因为网络或者gc的原因,worker或executor没有接收到executor或task的心跳反馈
2.报错提示
(1) executor lost
WARN TaskSetManager: Lost task 1.0 in stage 0.0 (TID 1, aa.local): ExecutorLostFailure (executor lost)
(2) task lost
WARN TaskSetManager: Lost task 69.2 in stage 7.0 (TID 1145, 192.168.47.217): java.io.IOException: Connection from /192.168.47.217:55483 closed
(3) 各种timeout
ERROR TransportChannelHandler: Connection to /192.168.47.212:35409 has been quiet for 120000 ms while there are outstanding requests. Assuming connection is dead; please adjust spark.network.timeout if this is wrong
3.解决方案
提高 spark.network.timeout 的值,根据情况改成300(5min)或更高。
默认为 120(120s),配置所有网络传输的延时,如果没有主动设置以下参数,默认覆盖其属性
- spark.core.connection.ack.wait.timeout
- spark.akka.timeout
- spark.storage.blockManagerSlaveTimeoutMs
- spark.shuffle.io.connectionTimeout
- spark.rpc.askTimeout or spark.rpc.lookupTimeout
问题三.倾斜 问题描述
大多数任务都完成了,还有那么一两个任务怎么都跑不完或者跑的很慢。
分为数据倾斜和task倾斜两种。
2.错误提示
(1) 数据倾斜
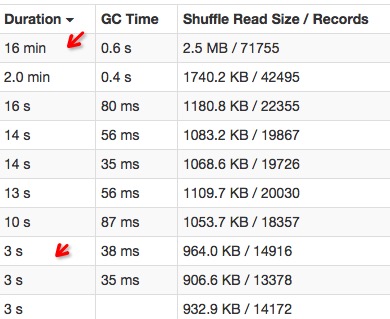
(2) 任务倾斜
差距不大的几个task,有的运行速度特别慢。
3.解决方案
(1) 数据倾斜
数据倾斜大多数情况是由于大量null值或者""引起,在计算前过滤掉这些数据既可。
例如:
sqlContext.sql("...where col is not null and col != ''")
(2) 任务倾斜
task倾斜原因比较多,网络io,cpu,mem都有可能造成这个节点上的任务执行缓慢,可以去看该节点的性能监控来分析原因。以前遇到过同事在spark的一台worker上跑R的任务导致该节点spark task运行缓慢。
或者可以开启spark的推测机制,开启推测机制后如果某一台机器的几个task特别慢,推测机制会将任务分配到其他机器执行,最后Spark会选取最快的作为最终结果。
- spark.speculation true
- spark.speculation.interval 100 - 检测周期,单位毫秒;
- spark.speculation.quantile 0.75 - 完成task的百分比时启动推测
- spark.speculation.multiplier 1.5 - 比其他的慢多少倍时启动推测。
问题四.OOM(内存溢出OutOfMemoryError) 问题描述
内存不够,数据太多就会抛出OOM的Exeception
2.解决方案
主要有driver OOM和executor OOM两种
(1) driver OOM
一般是使用了collect操作将所有executor的数据聚合到driver导致。尽量不要使用collect操作即可。
(2) executor OOM
1.可以按下面的内存优化的方法增加code使用内存空间
2.增加executor内存总量,也就是说增加spark.executor.memory的值
3.增加任务并行度(大任务就被分成小任务了),参考下面优化并行度的方法
优化
1.内存
当然如果你的任务shuffle量特别大,同时rdd缓存比较少可以更改下面的参数进一步提高任务运行速度。
spark.storage.memoryFraction - 分配给rdd缓存的比例,默认为0.6(60%),如果缓存的数据较少可以降低该值。
spark.shuffle.memoryFraction - 分配给shuffle数据的内存比例,默认为0.2(20%)
剩下的20%内存空间则是分配给代码生成对象等。
如果任务运行缓慢,jvm进行频繁gc或者内存空间不足,或者可以降低上述的两个值。
"spark.rdd.compress","true" - 默认为false,压缩序列化的RDD分区,消耗一些cpu减少空间的使用
如果数据只使用一次,不要采用cache操作,因为并不会提高运行速度,还会造成内存浪费。
2.并行度
spark.default.parallelism
发生shuffle时的并行度,在standalone模式下的数量默认为core的个数,也可手动调整,数量设置太大会造成很多小任务,增加启动任务的开销,太小,运行大数据量的任务时速度缓慢。
spark.sql.shuffle.partitions
sql聚合操作(发生shuffle)时的并行度,默认为200,如果任务运行缓慢增加这个值。
相同的两个任务:
spark.sql.shuffle.partitions=300:
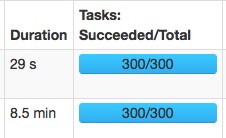
spark.sql.shuffle.partitions=500:
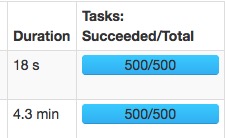
速度变快主要是大量的减少了gc的时间。
修改map阶段并行度主要是在代码中使用rdd.repartition(partitionNum)来操作。
1、Caused by: java.lang.OutOfMemoryError: GC overhead limit exceeded
这种情况发生的原因是, 程序基本上耗尽了所有的可用内存, GC也清理不了。
JVM抛出 java.lang.OutOfMemoryError: GC overhead limit exceeded 错误就是发出了这样的信号: 执行垃圾收集的时间比例太大, 有效的运算量太小. 默认情况下, 如果GC花费的时间超过 98%, 并且GC回收的内存少于 2%, JVM就会抛出这个错误。
JDK6新增错误类型。当GC为释放很小空间占用大量时间时抛出。
在JVM中增加该选项 -XX:-UseGCOverheadLimit 关闭限制GC的运行时间(默认启用 )
在spark-defaults.conf中增加以下参数
spark.executor.extraJavaOptions -XX:-UseGCOverheadLimit
spark.driver.extraJavaOptions -XX:-UseGCOverheadLimit
3、Timeout 报错Executor heartbeat timed out after 140927 ms ; ExecutorLostFailure
ERROR scheduler.JobScheduler: Error running job streaming job 1559791512000 ms.0
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times,
most recent failure: Lost task 0.3 in stage 0.0 (TID 8, , executor 5): ExecutorLostFailure (executor 5 exited caused by one of the running tasks) Reason: Executor heartbeat timed out after 140927 ms
17/10/18 17:33:46 WARN TaskSetManager: Lost task 1393.0 in stage 382.0 (TID 223626, test-ssps-s-04): ExecutorLostFailure (executor 0 exited caused by one of the running tasks)
Reason:Executor heartbeat timed out after 173568 ms
17/10/18 17:34:02 WARN NettyRpcEndpointRef: Error sending message [message = KillExecutors(app-20171017115441-0012,List(8))] in 2 attempts
org.apache.spark.rpc.RpcTimeoutException: Futures timed out after [120 seconds]. This timeout is controlled by spark.rpc.askTimeout at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:48)网络或者gc引起,worker或executor没有接收到executor或task的心跳反馈。
提高 spark.network.timeout 的值,根据情况改成300(5min)或更高。
默认为 120(120s),配置所有网络传输的延时
spark.network.timeout 300000
解决
提交spark submit任务的时候,加大超时时间设置
--conf spark.network.timeout 10000000
--conf spark.executor.heartbeatInterval=10000000
--conf spark.driver.maxResultSize=4g
2、Error sending result RpcResponse{requestId
4、IllegalStateException: Cannot call methods on a stopped SparkContext.
错误原因
自己关闭资源的位置写在任务循环代码之内了
sqlContext.sparkSession.close()
sc.stop()
详细检查写结束的位置,写在最后,解决问题。低级失误val sqlContext = new HiveContext(sc)
val sql = sqlContext.sql("select * from ysylbs9 ").collect1、报错:Container marked as failed:;ExecutorLostFailure ;;Container killed on request
cluster.YarnScheduler: Lost executor 2 on zdbdsps025.iccc.com: Container marked as failed: container_e55_1478671093534_0624_01_000003 on host: zdbdsps025.iccc.com. Exit status: 143. Diagnostics: Container killed on request. Exit code is 143
Container exited with a non-zero exit code 143
Killed by external signal
是因为yarn管理的某个节点掉了,所以spark将任务移至其他节点执行:
16/11/15 14:24:28 WARN scheduler.TaskSetManager: Lost task 224.0 in stage 0.0 (TID 224, zdbdsps025.iccc.com): ExecutorLostFailure (executor 2 exited caused by one of the running tasks) Reason: Container marked as failed: container_e55_1478671093534_0624_01_000003 on host: zdbdsps025.iccc.com. Exit status: 143. Diagnostics: Container killed on request. Exit code is 143
Container exited with a non-zero exit code 143
Killed by external signal
16/11/15 14:24:28 INFO cluster.YarnClientSchedulerBackend: Asked to remove non-existent executor 2
中间又报:heartbeats ;Lost executor 6 ;Executor heartbeat timed out after 133569 ms
16/11/15 14:30:43 WARN spark.HeartbeatReceiver: Removing executor 6 with no recent heartbeats: 133569 ms exceeds timeout 120000 ms
16/11/15 14:30:43 ERROR cluster.YarnScheduler: Lost executor 6 on zdbdsps027.iccc.com: Executor heartbeat timed out after 133569 ms
每个task 都超时了
16/11/15 14:30:43 WARN scheduler.TaskSetManager: Lost task 329.0 in stage 0.0 (TID 382, zdbdsps027.iccc.com): ExecutorLostFailure (executor 6 exited caused by one of the running tasks) Reason: Executor heartbeat timed out after 133569 ms
DAGScheduler发现Executor 6 也挂了,于是将executor移除
16/11/15 14:30:43 INFO scheduler.DAGScheduler: Executor lost: 6 (epoch 1)
16/11/15 14:30:43 INFO storage.BlockManagerMasterEndpoint: Trying to remove executor 6 from BlockManagerMaster.
16/11/15 14:30:43 INFO storage.BlockManagerMasterEndpoint: Removing block manager BlockManagerId(6, zdbdsps027.iccc.com, 38641)
16/11/15 14:30:43 INFO storage.BlockManagerMaster: Removed 6 successfully in removeExecutor
16/11/15 14:30:43 INFO cluster.YarnClientSchedulerBackend: Requesting to kill executor(s) 6
然后移至其他节点,随后又发现RPC出现问题;Error sending result RpcResponse{requestId
16/11/15 14:32:58 ERROR server.TransportRequestHandler: Error sending result RpcResponse{requestId=4735002570883429008, body=NioManagedBuffer{buf=java.nio.HeapByteBuffer[pos=0 lim=47 cap=47]}} to zdbdsps027.iccc.com/172.19.189.53:51057; closing connection
java.io.IOException: 断开的管道
at sun.nio.ch.FileDispatcherImpl.write0(Native Method)
at sun.nio.ch.SocketDispatcher.write(SocketDispatcher.java:47)
at sun.nio.ch.IOUtil.writeFromNativeBuffer(IOUtil.java:93)
Spark是移动计算而不是移动数据的,所以由于其他节点挂了,所以任务在数据不在的节点,再进行拉取,由于极端情况下,环境恶劣,通过namenode知道数据所在节点位置,spark依旧会去有问题的节点fetch数据,所以还会报错 再次kill掉,由于hadoop是备份三份数据的,spark通过会去其他节点拉取数据。随之一直发现只在一个节点完成task. 最终问题查找,yarn的节点挂了,
下面是部分代码调试:
case class LBS_STATIC_TABLE(LS_certifier_no: String,LS_location: String,LS_phone_no: String,time: String)
该case class 作为最终注册转换为hive表
val logger: Logger = LoggerFactory.getLogger(LbsCalculator.getClass)
//从hbase获取数据转换为RDD
def hbaseInit() = {
val tableName = "EVENT_LOG_LBS_HIS"
val conf = HBaseConfiguration.create()
// conf.addResource("hbase-site.xml ")
val HTable = new HTable(conf, tableName)
HTable
}
def tableInitByTime(sc : SparkContext,tablename:String,columns :String,fromdate: Date,todate:Date):RDD[(ImmutableBytesWritable,Result)] = {
val configuration = HBaseConfiguration.create()
//这里上生产注释掉,调试时可打开,因为提交yarn会自动加载yarn管理的hbase配置文件
configuration.addResource("hbase-site.xml")
configuration.set(TableInputFormat.INPUT_TABLE, tablename)
val scan = new Scan
//这里按timestrap进行过滤,比用scan过滤器要高效,因为用hbase的过滤器其实也是先scan全表再进行过滤的,效率很低。
scan.setTimeRange(fromdate.getTime,todate.getTime)
val column = columns.split(",")
for(columnName <- column){
scan.addColumn("f1".getBytes, columnName.getBytes)
}
val hbaseRDD = sc.newAPIHadoopRDD(configuration, classOf[TableInputFormat],
classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],
classOf[org.apache.hadoop.hbase.client.Result])
System.out.println(hbaseRDD.count())
hbaseRDD
}
//这里写了一种过滤器方法,后续将所有hbase过滤器方法写成公共类
val filter: Filter = new RowFilter(CompareFilter.CompareOp.GREATER_OR_EQUAL, new SubstringComparator("20160830"))
scan.setFilter(filter)
//这里要注意,拿到的数据在1个partition中,在拿到后需要进行repartition,因为如果一个task能够承载比如1G的数据,那么将只有1个patition,所以要重新repatition加大后续计算的并行度。
//这里repatition的个数需要根据具体多少数据量,进行调整,后续测试完毕写成公共方法。通过Rdd map 转换为(身份证号,经纬度坐标,手机号码,时间)这里就将获取的数据repatition了
val transRDD = hbRDD.repartition(200).map{ p => {
val id =Bytes.toString(p._2.getValue("f1".getBytes, "LS_certifier_no".getBytes))
val loc = Bytes.toString(p._2.getValue("f1".getBytes, "LS_location".getBytes))
val phone = Bytes.toString(p._2.getValue("f1".getBytes, "LS_phone_no".getBytes))
val rowkey = Bytes.toString(p._2.getValue("f1".getBytes, "rowkey".getBytes))
val hour = rowkey.split("-")(2).substring(8,10)
(id,loc,phone,hour)
}
}
//这里进行了字段过滤,因为很多时候数据具有不完整性,会导致后续计算错误
val calculateRDD = transRDD.repartition(200).filter(_._1 != null).filter(_._2 != null).filter(_._3 != null).filter(_._4 !=null)需要注意的是reduceByKey并不会在监控页面单独为其创建监控stage,所以你会发现与之前的map(filer)的stage中,同时监控中会发现已经进行了repartition
.reduceByKey(_ + _)
//进行hiveContext对象的创建,为后续进行表操作做准备。
val hiveSqlContext = HiveTableHelper.hiveTableInit(sc)
def hiveTableInit(sc:SparkContext): HiveContext ={
val sqlContext = new HiveContext(sc)
sqlContext
}
//传入之前数据分析过的结果,生成表
val hiveRDD = hRDD.map(p => LBS_STATIC_TABLE(p._1,p._2,p._3,p._4,p._5)
//创建DataFrame并以parquet格式保存为表。这里需要注意的是,尽量少的直接用hiveSqlContext.sql()直接输入sql的形式,因为这样还会走spark自己的解析器。需要调用RDD的DataFrame API会加快数据处理速度。后续整理所有算子。
val hiveRDDSchema = hiveSqlContext.createDataFrame(hiveRDD)
val aaa = hiveRDDSchema.show(10)
hiveSqlContext.sql("drop table if exists " + hivetablename)
hiveRDDSchema.registerTempTable("LBS_STATIC_TABLE")
hiveRDDSchema.write.format("parquet").saveAsTable(hivetablename)
以下是整理的Spark中的一些配置参数,官方文档请参考Spark Configuration。
Spark提供三个位置用来配置系统:
-
Spark属性:控制大部分的应用程序参数,可以用SparkConf对象或者Java系统属性设置
-
环境变量:可以通过每个节点的
conf/spark-env.sh脚本设置。例如IP地址、端口等信息 -
日志配置:可以通过log4j.properties配置
Spark属性参数
Spark属性控制大部分的应用程序设置,并且为每个应用程序分别配置它。这些属性可以直接在SparkConf上配置,然后传递给SparkContext。SparkConf允许你配置一些通用的属性(如master URL、应用程序名称等等)以及通过set()方法设置的任意键值对。例如,我们可以用如下方式创建一个拥有两个线程的应用程序。
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName("CountingSheep")
.set("spark.executor.memory", "1g")
val sc = new SparkContext(conf)动态加载Spark属性
在一些情况下,你可能想在SparkConf中避免硬编码确定的配置。例如,你想用不同的master或者不同的内存数运行相同的应用程序。Spark允许你简单地创建一个空conf。
val sc = new SparkContext(new SparkConf())然后你在运行时设置变量:
./bin/spark-submit --name "My app" --master local[4] --conf spark.shuffle.spill=false
--conf "spark.executor.extraJavaOptions=-XX:+PrintGCDetails -XX:+PrintGCTimeStamps" myApp.jarSpark shell和spark-submit工具支持两种方式动态加载配置。第一种方式是命令行选项,例如--master,如上面shell显示的那样。spark-submit可以接受任何Spark属性,用--conf参数表示。但是那些参与Spark应用程序启动的属性要用特定的参数表示。运行./bin/spark-submit --help将会显示选项的整个列表。
bin/spark-submit也会从conf/spark-defaults.conf中读取配置选项,这个配置文件中,每一行都包含一对以空格或者等号分开的键和值。例如:
spark.master spark://5.6.7.8:7077
spark.executor.memory 512m
spark.eventLog.enabled true
spark.serializer org.apache.spark.serializer.KryoSerializer任何标签指定的值或者在配置文件中的值将会传递给应用程序,并且通过SparkConf合并这些值。在SparkConf上设置的属性具有最高的优先级,其次是传递给spark-submit或者spark-shell的属性值,最后是spark-defaults.conf文件中的属性值。
优先级顺序:
SparkConf > CLI > spark-defaults.conf查看Spark属性
在http://<driver>:4040上的应用程序Web UI在Environment标签中列出了所有的Spark属性。这对你确保设置的属性的正确性是很有用的。
注意:只有通过spark-defaults.conf, SparkConf以及命令行直接指定的值才会显示。对于其它的配置属性,你可以认为程序用到了默认的值。
可用的属性
控制内部设置的大部分属性都有合理的默认值,一些最通用的选项设置如下:
应用程序属性
| 属性名称 | 默认值 | 含义 |
|---|---|---|
| spark.app.name |
(none) |
你的应用程序的名字。这将在UI和日志数据中出现 |
| spark.driver.cores |
1 |
driver程序运行需要的cpu内核数 |
| spark.driver.maxResultSize |
1g |
每个Spark action(如collect)所有分区的序列化结果的总大小限制。设置的值应该不小于1m,0代表没有限制。如果总大小超过这个限制,程序将会终止。大的限制值可能导致driver出现内存溢出错误(依赖于 |
| spark.driver.memory |
512m |
driver进程使用的内存数 |
| spark.executor.memory |
512m |
每个executor进程使用的内存数。和JVM内存串拥有相同的格式(如512m,2g) |
| spark.extraListeners |
(none) |
注册监听器,需要实现SparkListener |
| spark.local.dir |
/tmp |
Spark中暂存空间的使用目录。在Spark1.0以及更高的版本中,这个属性被SPARK_LOCAL_DIRS(Standalone, Mesos)和LOCAL_DIRS(YARN)环境变量覆盖。 |
| spark.logConf |
false |
当SparkContext启动时,将有效的SparkConf记录为INFO。 |
| spark.master |
(none) |
集群管理器连接的地方 |
运行环境
| 属性名称 | 默认值 | 含义 |
|---|---|---|
| spark.driver.extraClassPath |
(none) |
附加到driver的classpath的额外的classpath实体。 |
| spark.driver.extraJavaOptions |
(none) |
传递给driver的JVM选项字符串。例如GC设置或者其它日志设置。注意, |
| spark.driver.extraLibraryPath |
(none) |
指定启动driver的JVM时用到的库路径 |
| spark.driver.userClassPathFirst |
false |
(实验性)当在driver中加载类时,是否用户添加的jar比Spark自己的jar优先级高。这个属性可以降低Spark依赖和用户依赖的冲突。它现在还是一个实验性的特征。 |
| spark.executor.extraClassPath |
(none) |
附加到executors的classpath的额外的classpath实体。这个设置存在的主要目的是Spark与旧版本的向后兼容问题。用户一般不用设置这个选项 |
| spark.executor.extraJavaOptions |
(none) |
传递给executors的JVM选项字符串。例如GC设置或者其它日志设置。注意, |
| spark.executor.extraLibraryPath |
(none) |
指定启动executor的JVM时用到的库路径 |
| spark.executor.logs.rolling.maxRetainedFiles |
(none) |
设置被系统保留的最近滚动日志文件的数量。更老的日志文件将被删除。默认没有开启。 |
| spark.executor.logs.rolling.size.maxBytes |
(none) |
executor日志的最大滚动大小。默认情况下没有开启。值设置为字节 |
| spark.executor.logs.rolling.strategy |
(none) |
设置executor日志的滚动(rolling)策略。默认情况下没有开启。可以配置为 |
| spark.executor.logs.rolling.time.interval |
daily |
executor日志滚动的时间间隔。默认情况下没有开启。合法的值是 |
| spark.files.userClassPathFirst |
false |
(实验性)当在Executors中加载类时,是否用户添加的jar比Spark自己的jar优先级高。这个属性可以降低Spark依赖和用户依赖的冲突。它现在还是一个实验性的特征。 |
| spark.python.worker.memory |
512m |
在聚合期间,每个python worker进程使用的内存数。在聚合期间,如果内存超过了这个限制,它将会将数据塞进磁盘中 |
| spark.python.profile |
false |
在Python worker中开启profiling。通过 |
| spark.python.profile.dump |
(none) |
driver退出前保存分析结果的dump文件的目录。每个RDD都会分别dump一个文件。可以通过 |
| spark.python.worker.reuse |
true |
是否重用python worker。如果是,它将使用固定数量的Python workers,而不需要为每个任务 |
| spark.executorEnv.[EnvironmentVariableName] |
(none) |
通过 |
| spark.mesos.executor.home |
driver side SPARK_HOME |
设置安装在Mesos的executor上的Spark的目录。默认情况下,executors将使用driver的Spark本地(home)目录,这个目录对它们不可见。注意,如果没有通过 |
| spark.mesos.executor.memoryOverhead |
executor memory * 0.07, 最小384m |
这个值是 |
Shuffle行为
| 属性名称 | 默认值 | 含义 |
|---|---|---|
| spark.reducer.maxMbInFlight |
48 |
从递归任务中同时获取的map输出数据的最大大小(mb)。因为每一个输出都需要我们创建一个缓存用来接收,这个设置代表每个任务固定的内存上限,所以除非你有更大的内存,将其设置小一点 |
| spark.shuffle.blockTransferService |
netty |
实现用来在executor直接传递shuffle和缓存块。有两种可用的实现: |
| spark.shuffle.compress |
true |
是否压缩map操作的输出文件。一般情况下,这是一个好的选择。 |
| spark.shuffle.consolidateFiles |
false |
如果设置为”true”,在shuffle期间,合并的中间文件将会被创建。创建更少的文件可以提供文件系统的shuffle的效 率。这些shuffle都伴随着大量递归任务。当用ext4和dfs文件系统时,推荐设置为”true”。在ext3中,因为文件系统的限制,这个选项可 能机器(大于8核)降低效率 |
| spark.shuffle.file.buffer.kb |
32 |
每个shuffle文件输出流内存内缓存的大小,单位是kb。这个缓存减少了创建只中间shuffle文件中磁盘搜索和系统访问的数量 |
| spark.shuffle.io.maxRetries |
3 |
拉取数据重试次数 10 |
| spark.shuffle.io.numConnectionsPerPeer |
1 |
Netty only |
| spark.shuffle.io.preferDirectBufs |
true |
Netty only |
| spark.shuffle.io.retryWait |
5 |
每次重试拉取数据的等待间隔 30 |
| spark.shuffle.manager |
sort |
它的实现用于shuffle数据。有两种可用的实现: |
| spark.shuffle.memoryFraction |
0.2 |
如果 |
| spark.shuffle.sort.bypassMergeThreshold |
200 |
(Advanced) In the sort-based shuffle manager, avoid merge-sorting data if there is no map-side aggregation and there are at most this many reduce partitions |
| spark.shuffle.spill |
true |
如果设置为”true”,通过将多出的数据写入磁盘来限制内存数。通过 |
| spark.shuffle.spill.compress |
true |
在shuffle时,是否将spilling的数据压缩。压缩算法通过 |
Spark UI
| 属性名称 | 默认值 | 含义 |
|---|---|---|
| spark.eventLog.compress |
false |
是否压缩事件日志。需要 |
| spark.eventLog.dir |
file:///tmp/spark-events |
Spark事件日志记录的基本目录。在这个基本目录下,Spark为每个应用程序创建一个子目录。各个应用程序记录日志到直到的目录。用户可能想设置这为统一的地点,像HDFS一样,所以历史文件可以通过历史服务器读取 |
| spark.eventLog.enabled |
false |
是否记录Spark的事件日志。这在应用程序完成后,重新构造web UI是有用的 |
| spark.ui.killEnabled |
true |
运行在web UI中杀死stage和相应的job |
| spark.ui.port |
4040 |
你的应用程序dashboard的端口。显示内存和工作量数据 |
| spark.ui.retainedJobs |
1000 |
在垃圾回收之前,Spark UI和状态API记住的job数 |
| spark.ui.retainedStages |
1000 |
在垃圾回收之前,Spark UI和状态API记住的stage数 |
压缩和序列化
| 属性名称 | 默认值 | 含义 |
|---|---|---|
| spark.broadcast.compress |
true |
在发送广播变量之前是否压缩它 |
| spark.closure.serializer |
org.apache.spark.serializer.JavaSerializer |
闭包用到的序列化类。目前只支持java序列化器 |
| spark.io.compression.codec |
snappy |
压缩诸如RDD分区、广播变量、shuffle输出等内部数据的编码解码器。默认情况下,Spark提供了三种选择:lz4、lzf和snappy,你也可以用完整的类名来制定。 |
| spark.io.compression.lz4.block.size |
32768 |
LZ4压缩中用到的块大小。降低这个块的大小也会降低shuffle内存使用率 |
| spark.io.compression.snappy.block.size |
32768 |
Snappy压缩中用到的块大小。降低这个块的大小也会降低shuffle内存使用率 |
| spark.kryo.classesToRegister |
(none) |
如果你用Kryo序列化,给定的用逗号分隔的自定义类名列表表示要注册的类 |
| spark.kryo.referenceTracking |
true |
当用Kryo序列化时,跟踪是否引用同一对象。如果你的对象图有环,这是必须的设置。如果他们包含相同对象的多个副本,这个设置对效率是有用的。如果你知道不在这两个场景,那么可以禁用它以提高效率 |
| spark.kryo.registrationRequired |
false |
是否需要注册为Kyro可用。如果设置为true,然后如果一个没有注册的类序列化,Kyro会抛出异常。如果设置为false,Kryo将会同时写每个对象和其非注册类名。写类名可能造成显著地性能瓶颈。 |
| spark.kryo.registrator |
(none) |
如果你用Kryo序列化,设置这个类去注册你的自定义类。如果你需要用自定义的方式注册你的类,那么这个属性是有用的。否则 |
| spark.kryoserializer.buffer.max.mb |
64 |
Kryo序列化缓存允许的最大值。这个值必须大于你尝试序列化的对象 |
| spark.kryoserializer.buffer.mb |
0.064 |
Kyro序列化缓存的大小。这样worker上的每个核都有一个缓存。如果有需要,缓存会涨到 |
| spark.rdd.compress |
true |
是否压缩序列化的RDD分区。在花费一些额外的CPU时间的同时节省大量的空间 |
| spark.serializer |
org.apache.spark.serializer.JavaSerializer |
序列化对象使用的类。默认的Java序列化类可以序列化任何可序列化的java对象但是它很慢。所有我们建议用org.apache.spark.serializer.KryoSerializer |
| spark.serializer.objectStreamReset |
100 |
当用 |
运行时行为
| 属性名称 | 默认值 | 含义 |
|---|---|---|
| spark.broadcast.blockSize |
4096 |
TorrentBroadcastFactory传输的块大小,太大值会降低并发,太小的值会出现性能瓶颈 |
| spark.broadcast.factory |
org.apache.spark.broadcast.TorrentBroadcastFactory |
broadcast实现类 |
| spark.cleaner.ttl |
(infinite) |
spark记录任何元数据(stages生成、task生成等)的持续时间。定期清理可以确保将超期的元数据丢弃,这在运行长时间任务是很有用的,如运行7*24的sparkstreaming任务。RDD持久化在内存中的超期数据也会被清理 |
| spark.default.parallelism |
本地模式:机器核数;Mesos:8;其他: |
如果用户不设置,系统使用集群中运行shuffle操作的默认任务数(groupByKey、 reduceByKey等) |
| spark.executor.heartbeatInterval |
10000 |
executor 向 the driver 汇报心跳的时间间隔,单位毫秒 |
| spark.files.fetchTimeout |
60 |
driver 程序获取通过 |
| spark.files.useFetchCache |
true |
获取文件时是否使用本地缓存 |
| spark.files.overwrite |
false |
调用 |
| spark.hadoop.cloneConf |
false |
每个task是否克隆一份hadoop的配置文件 |
| spark.hadoop.validateOutputSpecs |
true |
是否校验输出 |
| spark.storage.memoryFraction |
0.6 |
Spark内存缓存的堆大小占用总内存比例,该值不能大于老年代内存大小,默认值为0.6,但是,如果你手动设置老年代大小,你可以增加该值 |
| spark.storage.memoryMapThreshold |
2097152 |
内存块大小 |
| spark.storage.unrollFraction |
0.2 |
Fraction of spark.storage.memoryFraction to use for unrolling blocks in memory. |
| spark.tachyonStore.baseDir |
System.getProperty(“java.io.tmpdir”) |
Tachyon File System临时目录 |
| spark.tachyonStore.url |
tachyon://localhost:19998 |
Tachyon File System URL |
网络
| 属性名称 | 默认值 | 含义 |
|---|---|---|
| spark.driver.host |
(local hostname) |
driver监听的主机名或者IP地址。这用于和executors以及独立的master通信 |
| spark.driver.port |
(random) |
driver监听的接口。这用于和executors以及独立的master通信 |
| spark.fileserver.port |
(random) |
driver的文件服务器监听的端口 |
| spark.broadcast.port |
(random) |
driver的HTTP广播服务器监听的端口 |
| spark.replClassServer.port |
(random) |
driver的HTTP类服务器监听的端口 |
| spark.blockManager.port |
(random) |
块管理器监听的端口。这些同时存在于driver和executors |
| spark.executor.port |
(random) |
executor监听的端口。用于与driver通信 |
| spark.port.maxRetries |
16 |
当绑定到一个端口,在放弃前重试的最大次数 |
| spark.akka.frameSize |
10 |
在”control plane”通信中允许的最大消息大小。如果你的任务需要发送大的结果到driver中,调大这个值 |
| spark.akka.threads |
4 |
通信的actor线程数。当driver有很多CPU核时,调大它是有用的 |
| spark.akka.timeout |
100 |
Spark节点之间的通信超时。单位是秒 |
| spark.rpc.askTimeout | 10 | rpc超时时间 优化:1000 |
| spark.akka.heartbeat.pauses |
6000 |
This is set to a larger value to disable failure detector that comes inbuilt akka. It can be enabled again, if you plan to use this feature (Not recommended). Acceptable heart beat pause in seconds for akka. This can be used to control sensitivity to gc pauses. Tune this in combination of |
| spark.akka.failure-detector.threshold |
300.0 |
This is set to a larger value to disable failure detector that comes inbuilt akka. It can be enabled again, if you plan to use this feature (Not recommended). This maps to akka’s |
| spark.akka.heartbeat.interval |
1000 |
This is set to a larger value to disable failure detector that comes inbuilt akka. It can be enabled again, if you plan to use this feature (Not recommended). A larger interval value in seconds reduces network overhead and a smaller value ( ~ 1 s) might be more informative for akka’s failure detector. Tune this in combination of |
调度相关属性
| 属性名称 | 默认值 | 含义 |
|---|---|---|
| spark.task.cpus |
1 |
为每个任务分配的内核数 |
| spark.task.maxFailures |
4 |
Task的最大重试次数 |
| spark.scheduler.mode |
FIFO |
Spark的任务调度模式,还有一种Fair模式 |
| spark.cores.max |
当应用程序运行在Standalone集群或者粗粒度共享模式Mesos集群时,应用程序向集群请求的最大CPU内核总数(不是指每 台机器,而是整个集群)。如果不设置,对于Standalone集群将使用spark.deploy.defaultCores中数值,而Mesos将使 用集群中可用的内核 |
|
| spark.mesos.coarse |
False |
如果设置为true,在Mesos集群中运行时使用粗粒度共享模式 |
| spark.speculation |
False |
以下几个参数是关于Spark推测执行机制的相关参数。此参数设定是否使用推测执行机制,如果设置为true则spark使用推测执行机制,对于Stage中拖后腿的Task在其他节点中重新启动,并将最先完成的Task的计算结果最为最终结果 |
| spark.speculation.interval |
100 |
Spark多长时间进行检查task运行状态用以推测,以毫秒为单位 |
| spark.speculation.quantile |
推测启动前,Stage必须要完成总Task的百分比 |
|
| spark.speculation.multiplier |
1.5 |
比已完成Task的运行速度中位数慢多少倍才启用推测 |
| spark.locality.wait |
3000 |
以下几个参数是关于Spark数据本地性的。本参数是以毫秒为单位启动本地数据task的等待时间,如果超出就启动下一本地优先级别 的task。该设置同样可以应用到各优先级别的本地性之间(本地进程 -> 本地节点 -> 本地机架 -> 任意节点 ),当然,也可以通过spark.locality.wait.node等参数设置不同优先级别的本地性 |
| spark.locality.wait.process |
3 | 本地进程级别的本地等待时间 |
| spark.locality.wait.node |
spark.locality.wait |
本地节点级别的本地等待时间 |
| spark.locality.wait.rack |
3 |
本地机架级别的本地等待时间 优化:5 |
| spark.scheduler.revive.interval |
1000 |
复活重新获取资源的Task的最长时间间隔(毫秒),发生在Task因为本地资源不足而将资源分配给其他Task运行后进入等待时间,如果这个等待时间内重新获取足够的资源就继续计算 |
Dynamic Allocation
| 属性名称 | 默认值 | 含义 |
|---|---|---|
| spark.dynamicAllocation.enabled |
false |
是否开启动态资源搜集 |
| spark.dynamicAllocation.executorIdleTimeout |
600 |
|
| spark.dynamicAllocation.initialExecutors |
spark.dynamicAllocation.minExecutors |
|
| spark.dynamicAllocation.maxExecutors |
Integer.MAX_VALUE |
|
| spark.dynamicAllocation.minExecutors |
0 |
|
| spark.dynamicAllocation.schedulerBacklogTimeout |
5 |
|
| spark.dynamicAllocation.sustainedSchedulerBacklogTimeout |
schedulerBacklogTimeout |
安全
| 属性名称 | 默认值 | 含义 |
|---|---|---|
| spark.authenticate |
false |
是否Spark验证其内部连接。如果不是运行在YARN上,请看 |
| spark.authenticate.secret |
None |
设置Spark两个组件之间的密匙验证。如果不是运行在YARN上,但是需要验证,这个选项必须设置 |
| spark.core.connection.auth.wait.timeout |
30 |
连接时等待验证的实际。单位为秒 |
| spark.core.connection.ack.wait.timeout |
60 |
连接等待回答的时间。单位为秒。为了避免不希望的超时,你可以设置更大的值 |
| spark.ui.filters |
None |
应用到Spark web UI的用于过滤类名的逗号分隔的列表。过滤器必须是标准的javax servlet Filter。通过设置java系统属性也可以指定每个过滤器的参数。 |
| spark.acls.enable |
false |
是否开启Spark acls。如果开启了,它检查用户是否有权限去查看或修改job。UI利用使用过滤器验证和设置用户 |
| spark.ui.view.acls |
empty |
逗号分隔的用户列表,列表中的用户有查看Spark web UI的权限。默认情况下,只有启动Spark job的用户有查看权限 |
| spark.modify.acls |
empty |
逗号分隔的用户列表,列表中的用户有修改Spark job的权限。默认情况下,只有启动Spark job的用户有修改权限 |
| spark.admin.acls |
empty |
逗号分隔的用户或者管理员列表,列表中的用户或管理员有查看和修改所有Spark job的权限。如果你运行在一个共享集群,有一组管理员或开发者帮助debug,这个选项有用 |
加密
| 属性名称 | 默认值 | 含义 |
|---|---|---|
| spark.ssl.enabled |
false |
是否开启ssl |
| spark.ssl.enabledAlgorithms |
Empty |
JVM支持的加密算法列表,逗号分隔 |
| spark.ssl.keyPassword |
None |
|
| spark.ssl.keyStore |
None |
|
| spark.ssl.keyStorePassword |
None |
|
| spark.ssl.protocol |
None |
|
| spark.ssl.trustStore |
None |
|
| spark.ssl.trustStorePassword |
None |
Spark Streaming
| 属性名称 | 默认值 | 含义 |
|---|---|---|
| spark.streaming.blockInterval |
200 |
在这个时间间隔(ms)内,通过Spark Streaming receivers接收的数据在保存到Spark之前,chunk为数据块。推荐的最小值为50ms |
| spark.streaming.receiver.maxRate |
infinite |
每秒钟每个receiver将接收的数据的最大记录数。有效的情况下,每个流将消耗至少这个数目的记录。设置这个配置为0或者-1将会不作限制 |
| spark.streaming.receiver.writeAheadLogs.enable |
false |
Enable write ahead logs for receivers. All the input data received through receivers will be saved to write ahead logs that will allow it to be recovered after driver failures |
| spark.streaming.unpersist |
true |
强制通过Spark Streaming生成并持久化的RDD自动从Spark内存中非持久化。通过Spark Streaming接收的原始输入数据也将清除。设置这个属性为false允许流应用程序访问原始数据和持久化RDD,因为它们没有被自动清除。但是它会 造成更高的内存花费 |
集群管理
Spark On YARN
| 属性名称 | 默认值 | 含义 |
|---|---|---|
| spark.yarn.am.memory |
512m |
client 模式时,am的内存大小;cluster模式时,使用 |
| spark.driver.cores |
1 |
claster模式时,driver使用的cpu核数,这时候driver运行在am中,其实也就是am和核数;client模式时,使用 |
| spark.yarn.am.cores |
1 |
client 模式时,am的cpu核数 |
| spark.yarn.am.waitTime |
100000 |
启动时等待时间 |
| spark.yarn.submit.file.replication |
3 |
应用程序上传到HDFS的文件的副本数 |
| spark.yarn.preserve.staging.files |
False |
若为true,在job结束后,将stage相关的文件保留而不是删除 |
| spark.yarn.scheduler.heartbeat.interval-ms |
5000 |
Spark AppMaster发送心跳信息给YARN RM的时间间隔 |
| spark.yarn.max.executor.failures |
2倍于executor数,最小值3 |
导致应用程序宣告失败的最大executor失败次数 |
| spark.yarn.applicationMaster.waitTries |
10 |
RM等待Spark AppMaster启动重试次数,也就是SparkContext初始化次数。超过这个数值,启动失败 |
| spark.yarn.historyServer.address |
Spark history server的地址(不要加 |
|
| spark.yarn.dist.archives |
(none) |
|
| spark.yarn.dist.files |
(none) |
|
| spark.executor.instances |
2 |
executor实例个数 |
| spark.yarn.executor.memoryOverhead |
executorMemory * 0.07, with minimum of 384 |
executor的堆内存大小设置 |
| spark.yarn.driver.memoryOverhead |
driverMemory * 0.07, with minimum of 384 |
driver的堆内存大小设置 |
| spark.yarn.am.memoryOverhead |
AM memory * 0.07, with minimum of 384 |
am的堆内存大小设置,在client模式时设置 |
| spark.yarn.queue |
default |
使用yarn的队列 |
| spark.yarn.jar |
(none) |
|
| spark.yarn.access.namenodes |
(none) |
|
| spark.yarn.appMasterEnv.[EnvironmentVariableName] |
(none) |
设置am的环境变量 |
| spark.yarn.containerLauncherMaxThreads |
25 |
am启动executor的最大线程数 |
| spark.yarn.am.extraJavaOptions |
(none) |
|
| spark.yarn.maxAppAttempts |
yarn.resourcemanager.am.max-attempts in YARN |
am重试次数 |
Spark on Mesos
使用较少,参考Running Spark on Mesos。
Spark Standalone Mode
Spark History Server
当你运行Spark Standalone Mode或者Spark on Mesos模式时,你可以通过Spark History Server来查看job运行情况。
Spark History Server的环境变量:
| 属性名称 | 含义 |
|---|---|
| SPARK_DAEMON_MEMORY |
Memory to allocate to the history server (default: 512m). |
| SPARK_DAEMON_JAVA_OPTS |
JVM options for the history server (default: none). |
| SPARK_PUBLIC_DNS |
|
| SPARK_HISTORY_OPTS |
配置 spark.history.* 属性 |
Spark History Server的属性:
| 属性名称 | 默认 | 含义 |
|---|---|---|
| spark.history.provider |
org.apache.spark.deploy.history.FsHistoryProvide |
应用历史后端实现的类名。 目前只有一个实现, 由Spark提供, 它查看存储在文件系统里面的应用日志 |
| spark.history.fs.logDirectory |
file:/tmp/spark-events |
|
| spark.history.updateInterval |
10 |
以秒为单位,多长时间Spark history server显示的信息进行更新。每次更新都会检查持久层事件日志的任何变化。 |
| spark.history.retainedApplications |
50 |
在Spark history server上显示的最大应用程序数量,如果超过这个值,旧的应用程序信息将被删除。 |
| spark.history.ui.port |
18080 |
官方版本中,Spark history server的默认访问端口 |
| spark.history.kerberos.enabled |
false |
是否使用kerberos方式登录访问history server,对于持久层位于安全集群的HDFS上是有用的。如果设置为true,就要配置下面的两个属性。 |
| spark.history.kerberos.principal |
空 |
用于Spark history server的kerberos主体名称 |
| spark.history.kerberos.keytab |
空 |
用于Spark history server的kerberos keytab文件位置 |
| spark.history.ui.acls.enable |
false |
授权用户查看应用程序信息的时候是否检查acl。如果启用,只有应用程序所有者和 |
环境变量
通过环境变量配置确定的Spark设置。环境变量从Spark安装目录下的conf/spark-env.sh脚本读取(或者windows的conf/spark-env.cmd)。在独立的或者Mesos模式下,这个文件可以给机器确定的信息,如主机名。当运行本地应用程序或者提交脚本时,它也起作用。
注意,当Spark安装时,conf/spark-env.sh默认是不存在的。你可以复制conf/spark-env.sh.template创建它。
可以在spark-env.sh中设置如下变量:
| 环境变量 | 含义 |
|---|---|
| JAVA_HOME |
Java安装的路径 |
| PYSPARK_PYTHON |
PySpark用到的Python二进制执行文件路径 |
| SPARK_LOCAL_IP |
机器绑定的IP地址 |
| SPARK_PUBLIC_DNS |
你Spark应用程序通知给其他机器的主机名 |
除了以上这些,Spark standalone cluster scripts也可以设置一些选项。例如每台机器使用的核数以及最大内存。
因为spark-env.sh是shell脚本,其中的一些可以以编程方式设置。例如,你可以通过特定的网络接口计算SPARK_LOCAL_IP。
配置日志
Spark用log4j logging。你可以通过在conf目录下添加log4j.properties文件来配置。一种方法是复制log4j.properties.template文件。