1- 首先编写一个参数传递的Flink的WordCount代码
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author liu a fu
* @version 1.0
* @date 2021/3/3 0003
* @DESC 使用Flink 计算引擎实现流式数据处理:从Socket接收数据,实时进行词频统计WordCount 参数传递
*
*/
public class WordCount {
public static void main(String[] args) throws Exception {
//使用工具类,解析程序运行传递参数
ParameterTool parameterTool = ParameterTool.fromArgs(args);
if (2 != parameterTool.getNumberOfParameters()){
System.out.println("Usage: WordCount --host <host> --port <port> .............");
System.exit(-1);
}
final String host = parameterTool.get("host");
final int port = parameterTool.getInt("port");
//1-流处理环境准备 StreamExecutionEnvironment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2-读取流试数据 source
DataStreamSource<String> inputDataStream = env.socketTextStream("node1.itcast.cn", 9999);
//3-数据的转换 transformation
/*
step1. 将每行数据按照分割符分割为单词
spark spark flink -> spark, spark, flink
step2. 将每个单词转换为二元组,表示每个单词出现一次
spark, spark, flink -> (spark, 1), (spark, 1), (flink, 1)
step3. 按照单词分组,将同组中次数进行累加sum
(spark, 1), (spark, 1), (flink, 1) -> (spark, 1 + 1 = 2) , (flink, 1 = 1)
*/
//TODO: 3-1 将每行数据按照指定的分割符号切割
SingleOutputStreamOperator<String> wordDataStream = inputDataStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> out) throws Exception {
for (String word: line.trim().split("\\s+")){
out.collect(word);
}
}
});
//TODO: 3-2 将每行数据准换为 二元元组
SingleOutputStreamOperator<Tuple2<String, Integer>> tupleDataStream = wordDataStream.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String words) throws Exception {
return Tuple2.of(words, 1);
}
});
//TODO: 3-3 将每个单词按照 同组中的 sum进行累加
SingleOutputStreamOperator<Tuple2<String, Integer>> resultDataStream = tupleDataStream
.keyBy(0).sum(1);
//4- 数据终端 sink
resultDataStream.print();
//5- 触发执行器 execute
env.execute(WordCount.class.getSimpleName());
}
}
将上述程序打好jar包,打好Jar包删除log4j文件
2. 第一种方式命令方式提交
- 此方式提交Flink应用可以运行至Standalone集群和YARN集群(Session会话模式和Job分离模式),此处以运行YARN的Job分离模式为例演示提交Flink应用程序。
1: 上传打好的Jar包
cd /export/server/flink/
rz
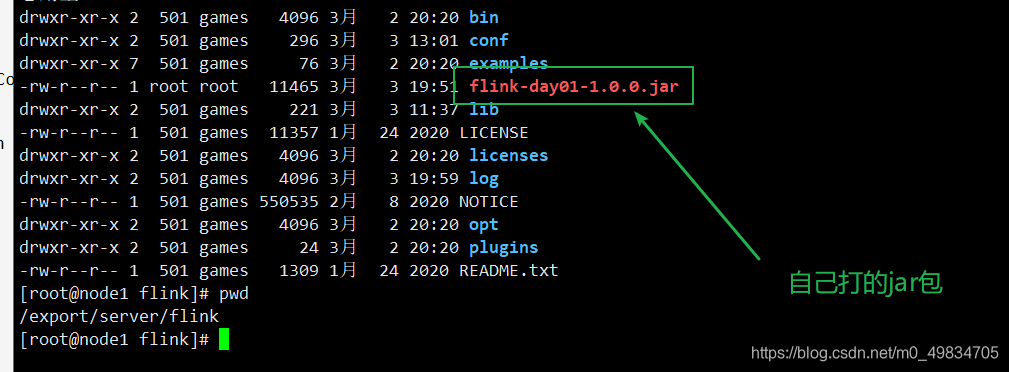
2: 提交运行:
bin/flink run --class cn.itcast.stream.WordCount \
-m yarn-cluster -yjm 1024 -ytm 1024 \
flink-day01-1.0.0.jar --host node1.itcast.cn --port 9999
--class 后面跟全类名
flink-day01-1.0.0.jar jar包的名字

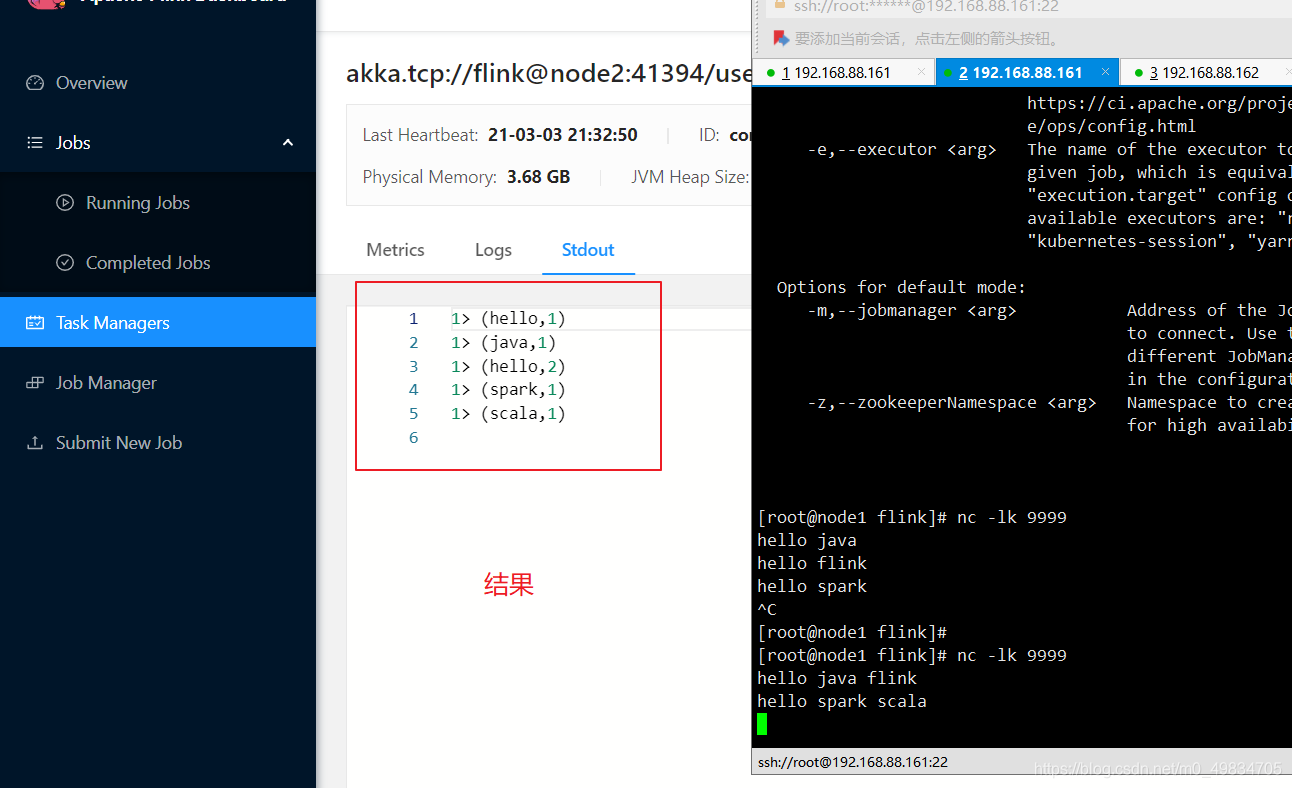
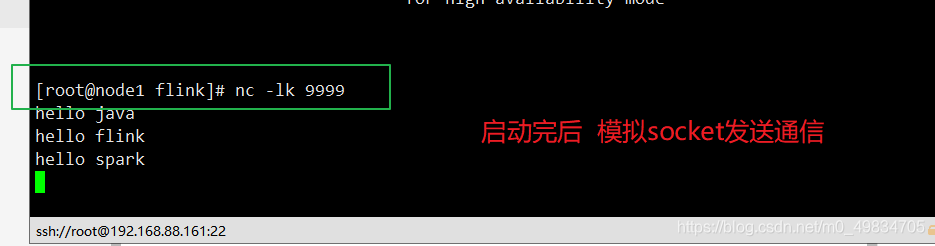
模拟socket发送通信:
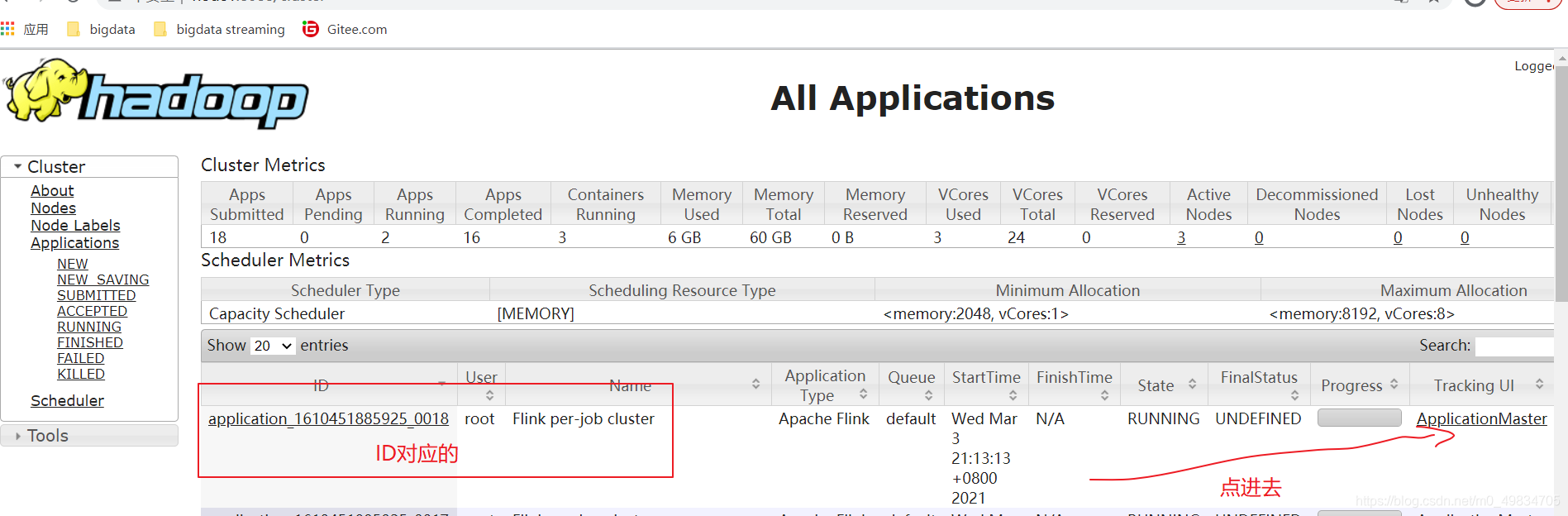
结果:
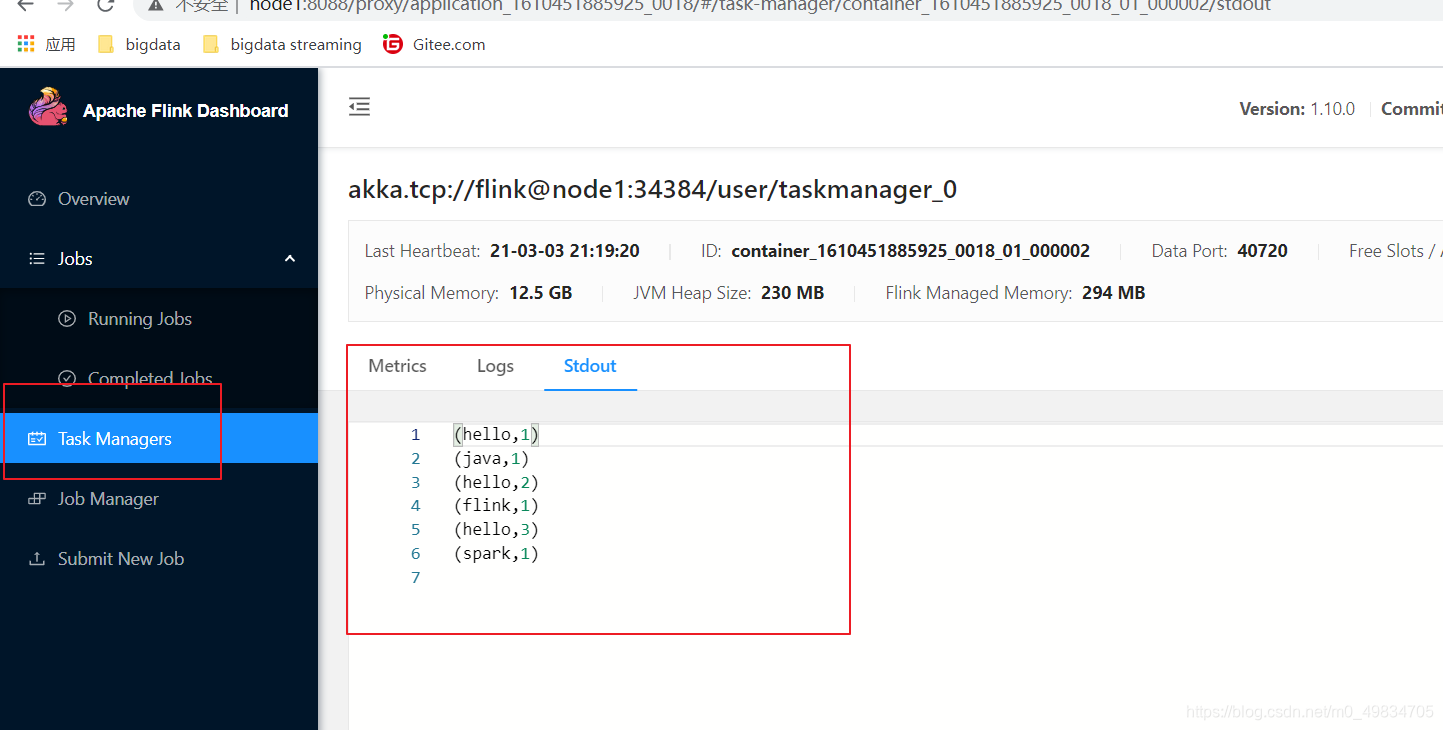
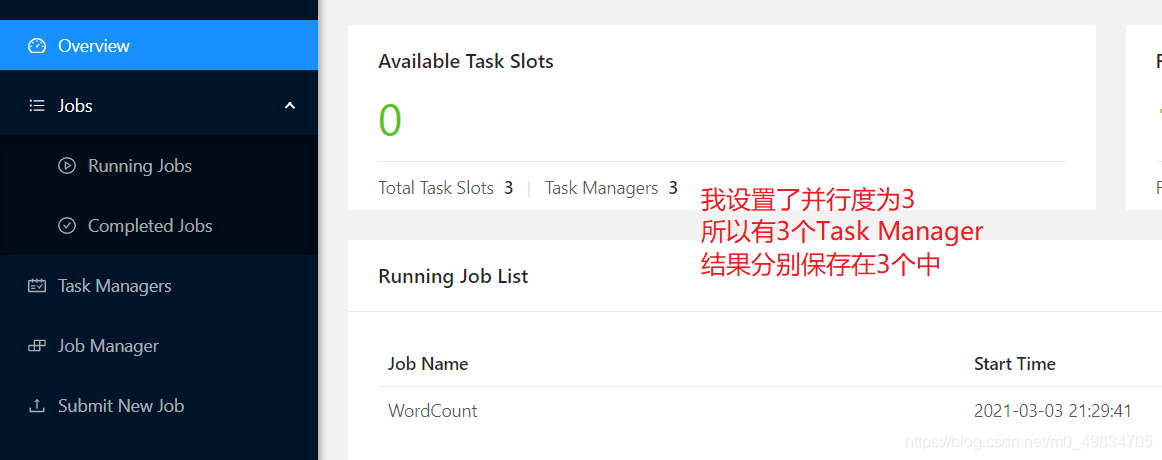
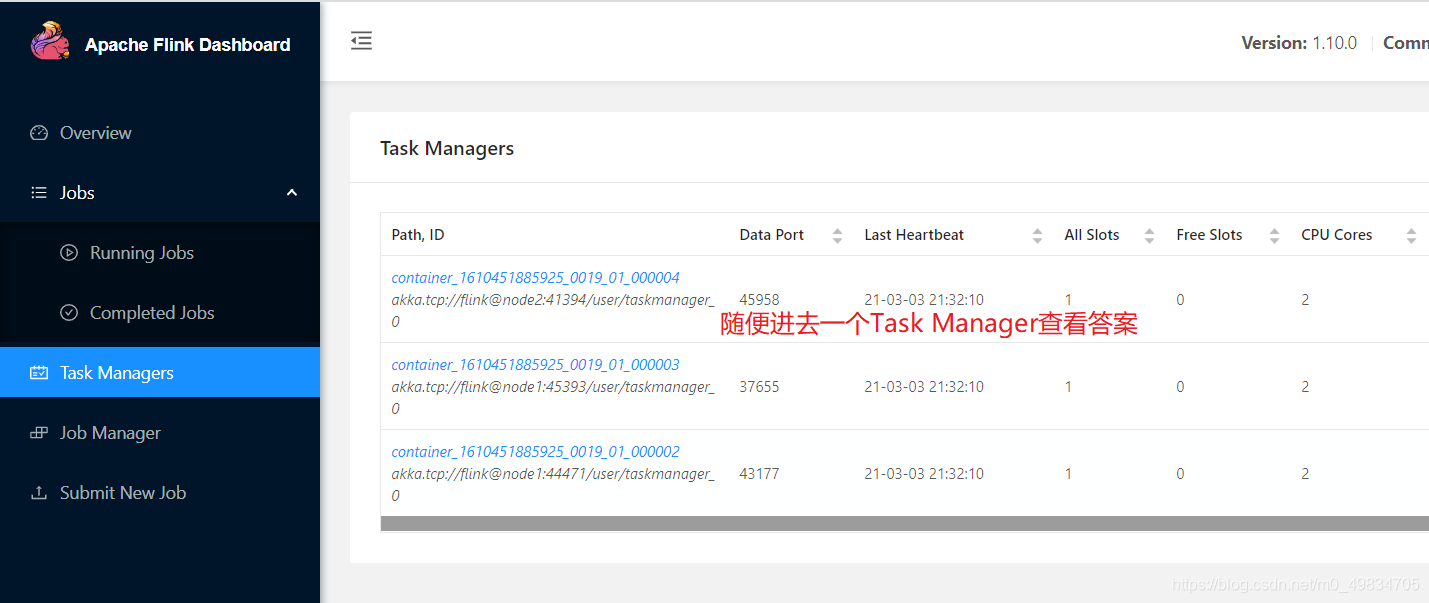
3. 第二种方式UI界面提交
此种方式提交应用,仅仅在Flink Standalone集群和YARN Session会话模式下,此处以YARNSession为例演示。
1: 开启hadoop集群: start-all.sh
2: 启动YARN Session
cd /export/server/flink/
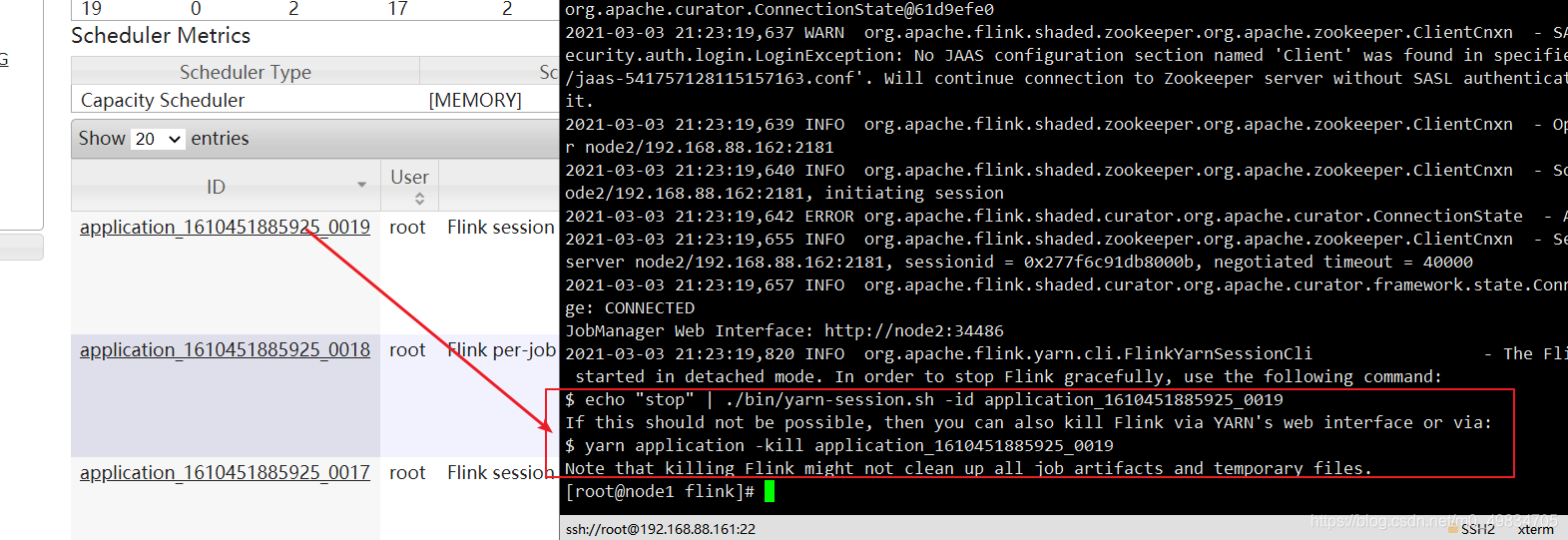
bin/yarn-session.sh -tm 1024 -jm 1024 -s 1 -d
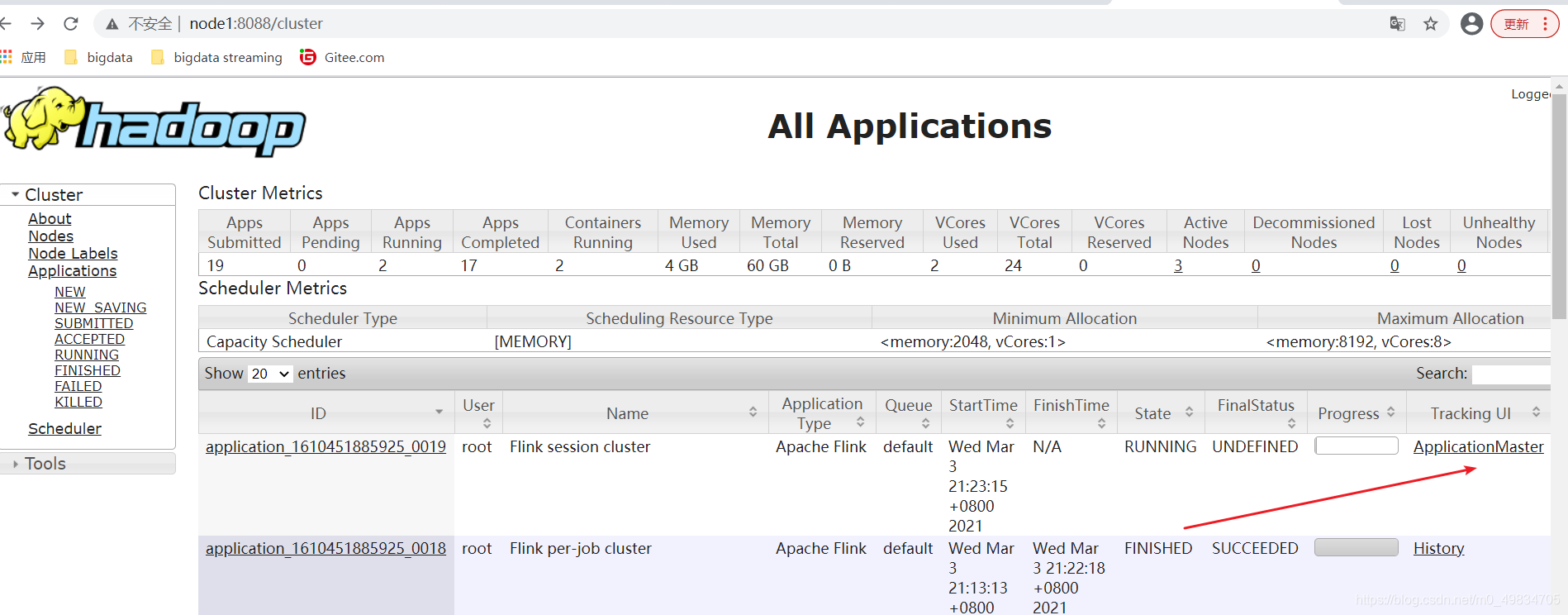
3: 通过Yarn的webUI访问Spark任务的WEBUI
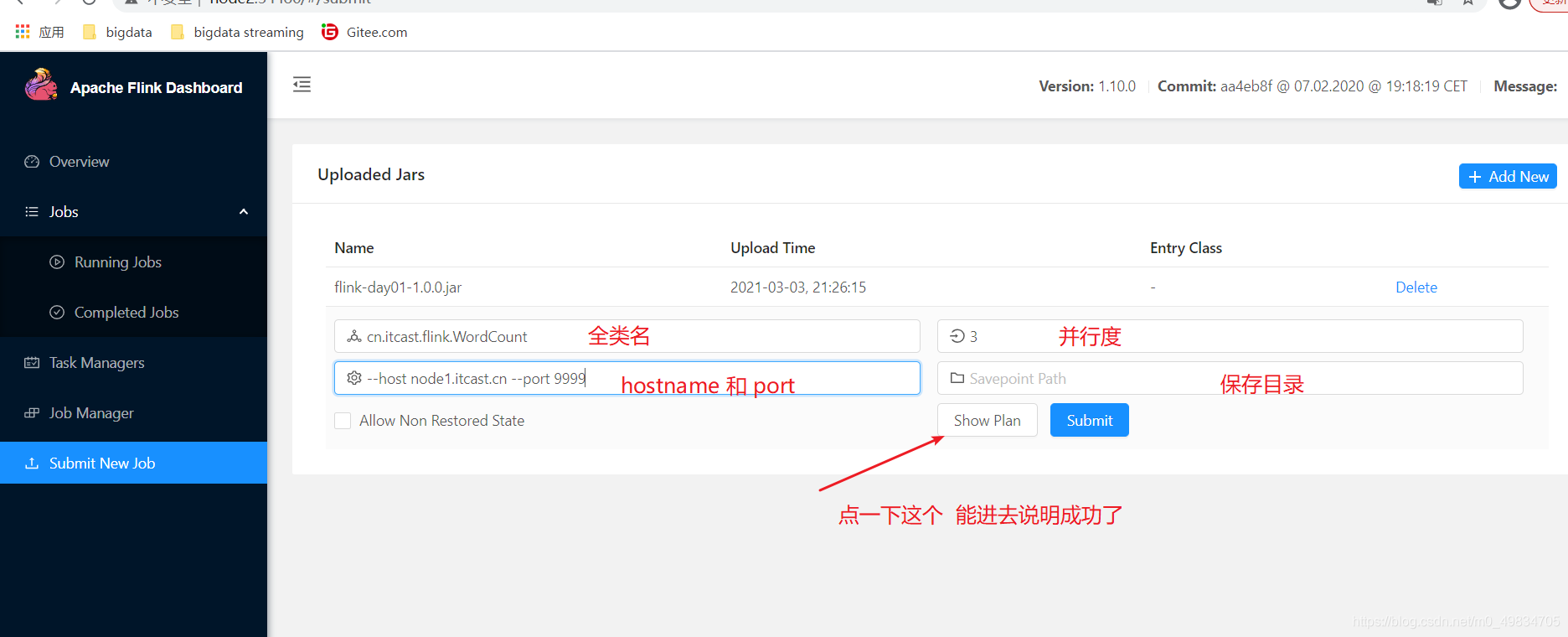
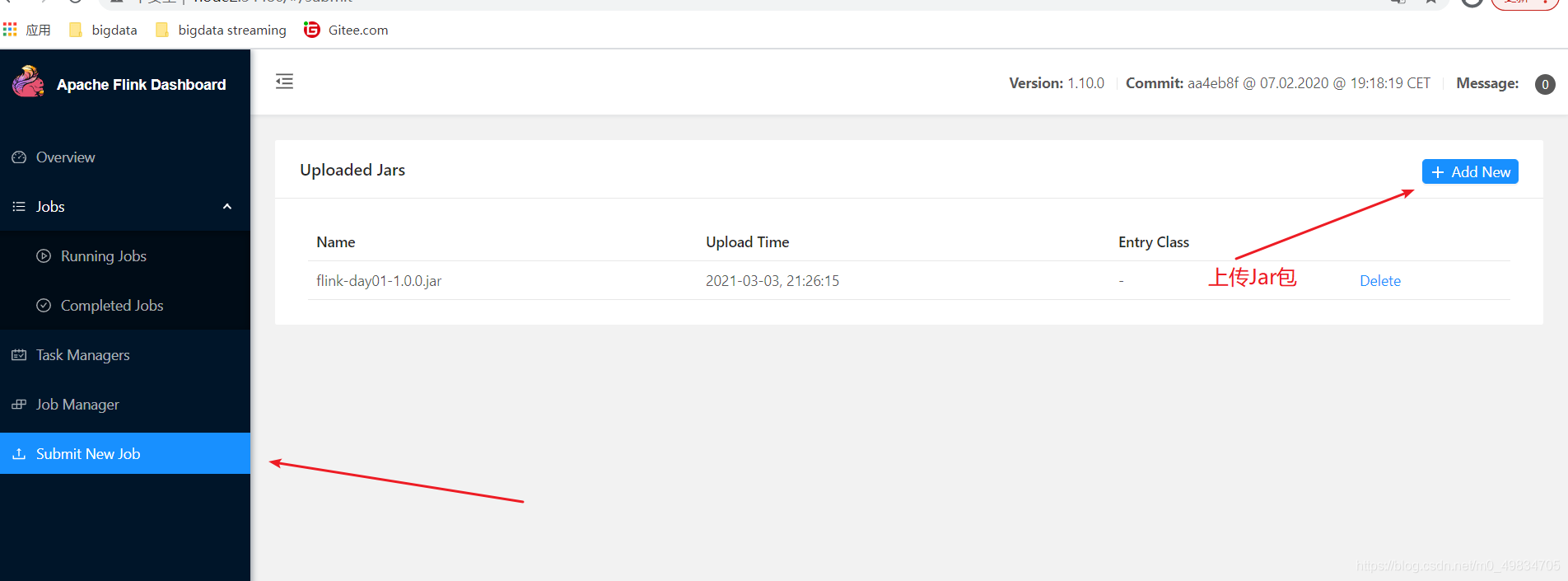
4: 上传Jar包:
5: 填写参数: