华为在20年9月份开源了MindSpore Lite 1.0.0版本之后,其接口易用性、算子性能与完备度、第三方模型的广泛支持等方面,得到了众多手机应用开发者的广泛认可。MindSpore Lite为HMS Core AI领域提供了全场景AI推理框架,支撑华为手机的相机、图库、钱包、浏览器的二维码扫描、物体识别等AI相关模块,为各类华为穿戴、智慧屏等设备提供基础AI服务。同时,作为HMS Core开放给全球开发者接入的重要能力之一,华为机器学习服务已为全球1000+应用接入,日均调用量超过3亿。
目前,在21年新年伊始,华为发布了MindSpore Lite 1.1.0版本,在算子性能优化、模型小型化、加速库自动裁剪工具、端侧模型训练、语音类模型支持、Java接口开放、模型可视化等方面进行了全面升级,升级后的版本更轻、更快、更易用,新特性也会体现到HMS Core的新版本中。
1. 算子库优化与扩展
推理性能优化是本次版本的重头戏,除了持续的ARM CPU(FP16/FP32/INT8)性能优化,ARM GPU和X86_64的优化也是本次的亮点。GPU方面我们除了传统的算子优化,还加入了在线融合、AutoTuning等技术,使得ARM GPU推理性能大幅提升;同时为了更好的支持PC侧推理,在X86_64算子方面我们做了大量汇编层面的优化;经过大量模型的实测,MindSpore Lite 1.1.0版本在推理性能方面在业界各类框架中极具竞争力。
1.1 ARM CPU优化
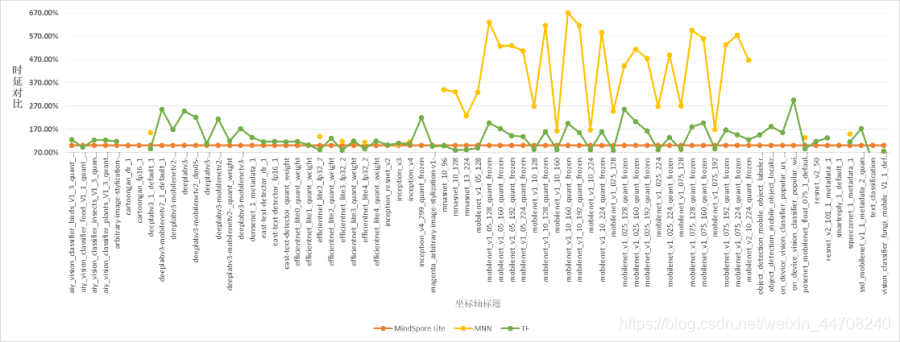
我们从引入减少计算量的更优算法,到尽可能减少硬件访存从而提高指令吞吐量,MindSpore Lite 的CPU算子性能大幅提升。我们使用TF Hub官网上100+端侧预置模型进行了推理时延对比测试,测试结果显示在Mate30/P30等高端机型上MindSpore Lite已全面超越官网数据,在P20等中低端机型上推理性能优于官网数据的占比也达到97%。
1.1.1 FP16推理性能
MindSpore Lite全面支持ARMv8.2的FP16推理,推理时延基本达到了FP32类型推理的二分之一,在推理时延大幅降低的同时精度满足业务要求;我们的FP16推理方案已经在华为HMS MLKit和华为手机预置的各类AI服务中普遍应用。
由于TF Lite不支持FP16推理,所以在FP16推理性能对比测试环节中我们只选择了MNN最新的1.1版本,从测试结果看MindSpore Lite在FP16推理时延更低,性能表现更好。
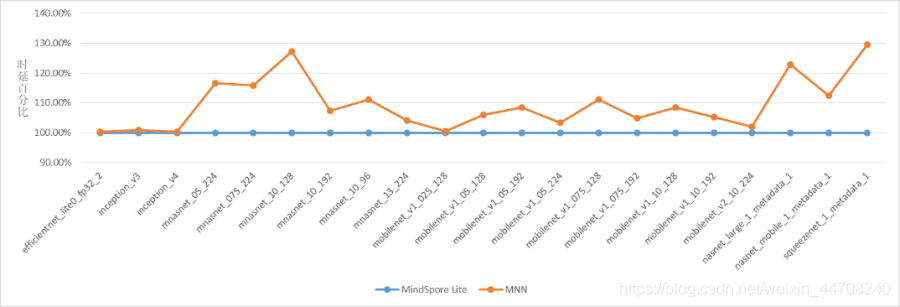
华为Mate30上网络整体时延对比情况
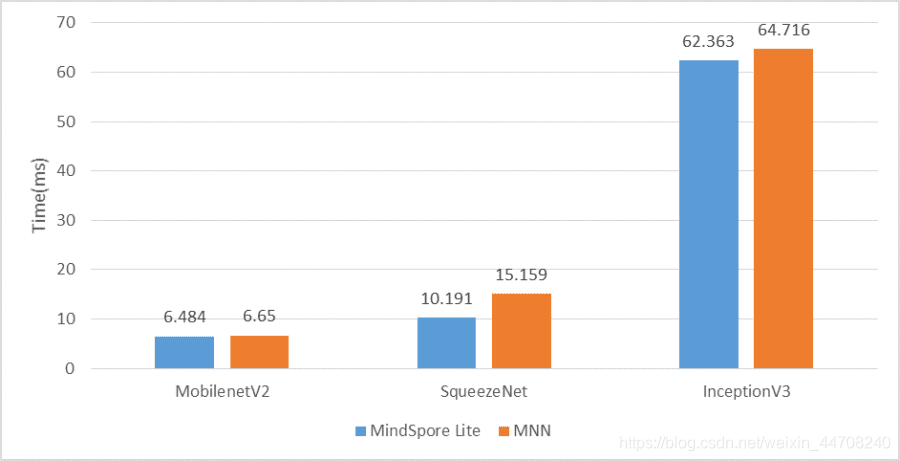
华为Mate30上FP16推理时延对比
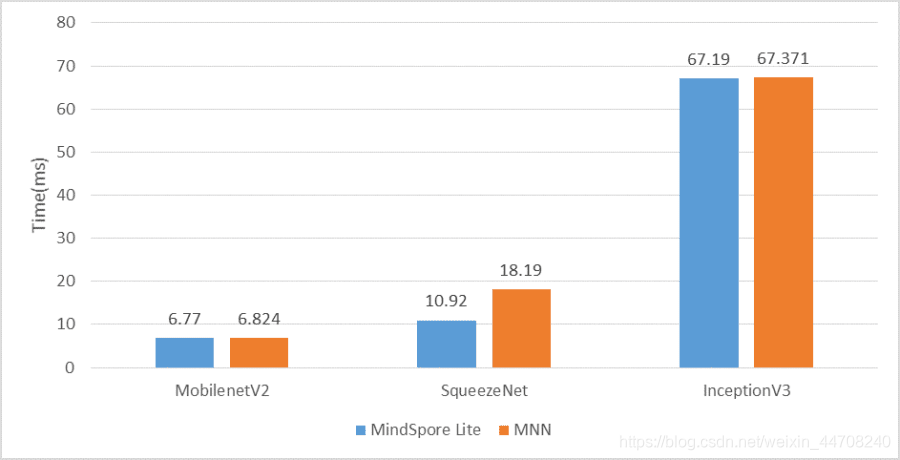
骁龙865+上FP16推理时延对比
1.1.2 Int8量化模型推理性能
对于量化算子,当前版本MindSpore Lite实现了在算法层面加入如Convolution Kernel为3x3的Winograd优化算法(目前主要针对非ARMv8.2机型),在支持ARMv8.2的高端机上使用SDOT指令对MatMul、Fully Connection、Convolution等算子进行优化,以及提高底层缓存命中率的一系列优化策略,使得MindSpore Lite量化推理性能得到大幅提升,相较于FP16推理有40%+的性能提升。
我们选择了TF Lite最新2.4版本和MNN最新的1.1版本进行推理性能对比测试,使用的模型为TF Hub官方预置的量化模型(测试过程中我们发现MNN存在大量量化模型无法转换问题,甚至TF Lite对自家模型也存在转换问题),从测试结果看MindSpore Lite对量化模型无论在支持度还是推理性能方面,时延都是最低,表现最好。
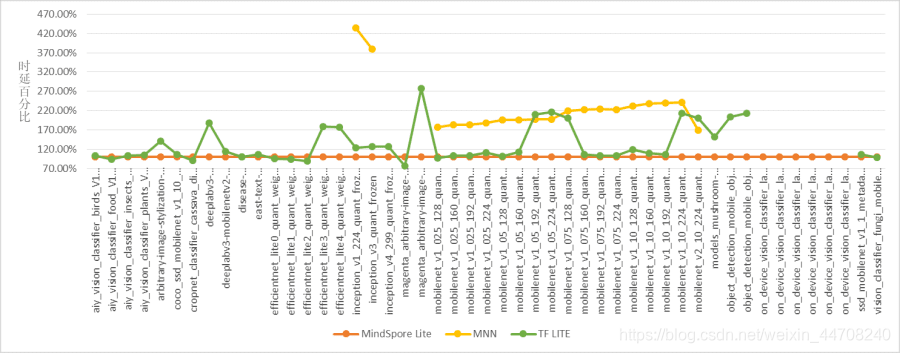
华为Mate30上量化网络整体时延对比情况
ARMv8.2机型测试
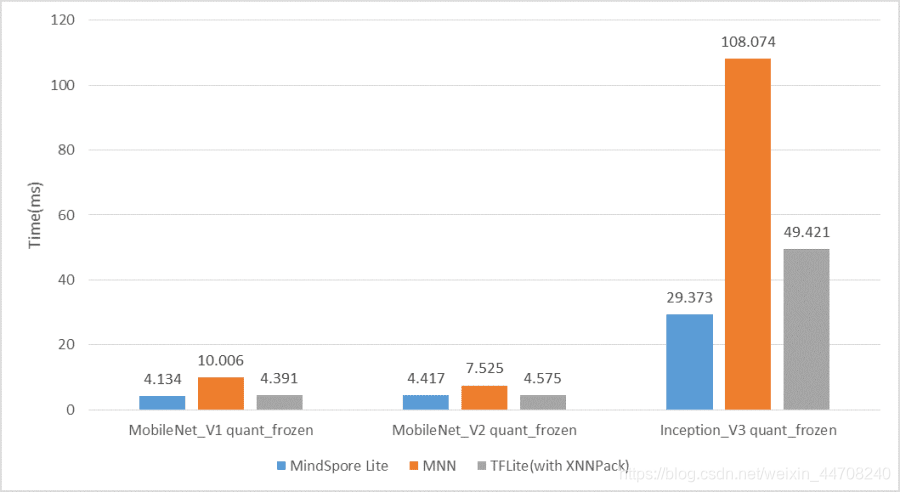
骁龙865+上量化模型时延对比
ARMv8机型测试
华为P20上量化模型时延对比
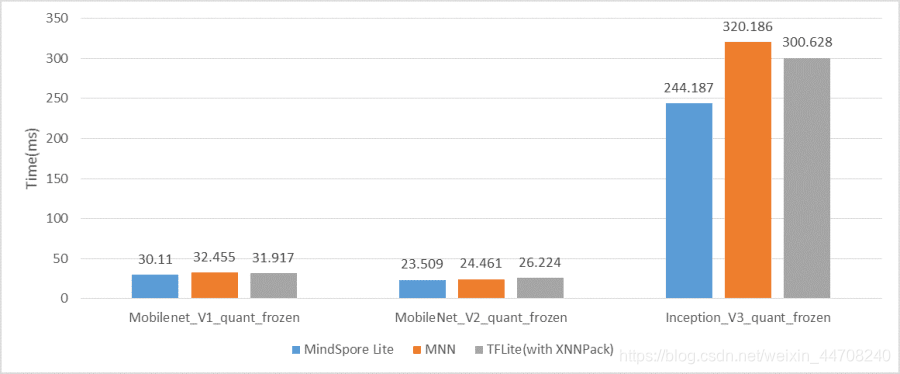
1.1.3 FP32推理性能
同时为了确保在低端CPU上使用MindSpore Lite推理时能够同样获得业界最优的推理性能,我们持续对FP32的推理性能进行了优化。我们在华为P20上以TFLite(2.4版本)、MNN(1.1版本)作为对比对象,进行了benchmark性能测试,从测试结果中可以看出MindSpore Lite FP32推理时延还是最低,表现最好,但和其他框架的差距不大。
华为P20上量化模型时延对比
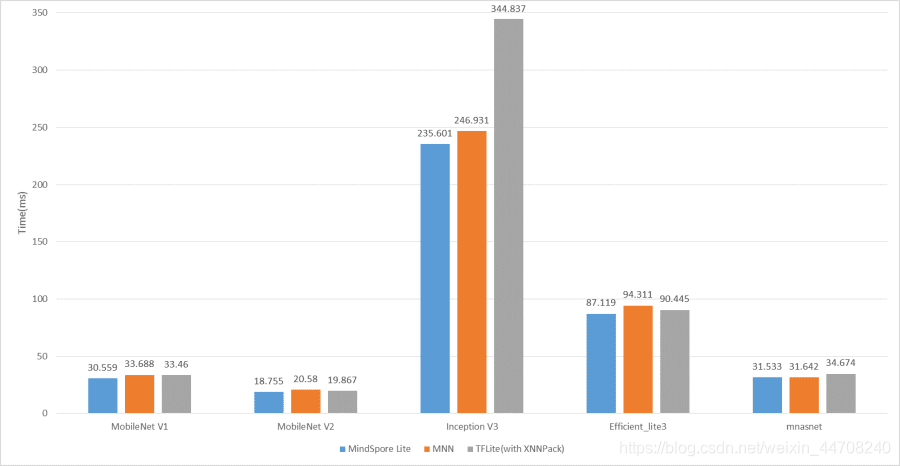
1.2 ARM GPU优化
MindSpore Lite 1.1版本我们对GPU推理性能进行了重点优化,除了在算子层面进行了常规优化外,还增加了在线融合、AutoTuning、OpenCL kernel二进制cache机制等多种优化方式,使得整体性能较MindSpore Lite 1.0有25%+的提升;
我们同样在华为Mate30上使用TF Hub官网100+预置模型与MNN(1.1版本)和TF(2.4版本)进行了GPU推理性能对比测试,可以从下图的测试结果看出MindSpore Lite GPU推理性能在大部分模型时延上都是最低,MNN则延迟都比较高。
华为Mate30上GPU FP32推理时延对比
1.3 X86_64 CPU优化
本次版本我们还对X86_64平台上的推理性能进行了大量优化工作,我们在Intel Core i7-8700的CPU上与Intel OpenVINO和MNN在几个经典CV类网络上进行了benchmark测试,从测试结果看MindSpore Lite时延同样最低;
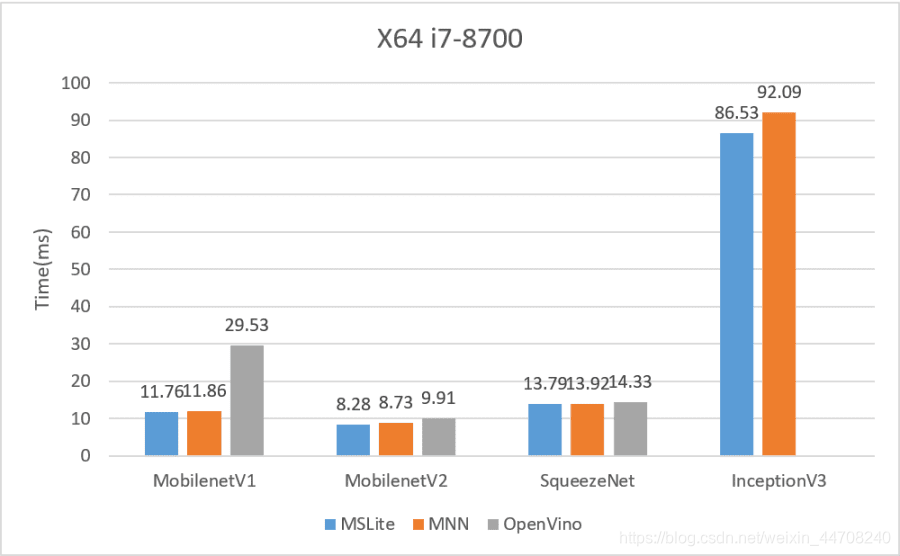
Intel Core i7-8700 X86_64 CPU推理性能对比
1.4更多的融合
当前MindSpore Lite版本已经基本覆盖了机器视觉领域通用的卷积相关融合pattern,同时针对基于Transformer结构的语音模型和LSTM结构的模型进行了深度融合优化,主要包括将小算子融合成Layernorm、LSTM等大算子,多个MatMul融合成BatchMatMul算子,Slice算子切分矩阵的前移融合等,使得语音类模型获得20%+的提升,后续我们将尝试融合pattern的自动schedule功能。
2. 算子完备度扩展
MindSpore Lite支持包括ARM CPU、ARM GPU、X86 CPU、Kirin NPU、MTK APU在内的多种硬件平台。
2.1 ARM CPU
MindSpore Lite是目前端侧推理框架中CPU算子支持最丰富的框架之一,当前我们的模型转换工具支持TF Lite(100个)、TF(53个)、ONNX(96个)以及Caffe(26个)等第三方框架算子定义的解析,做到了高兼容性,上文性能测试中我们也提到过MNN对很多模型无法转换,TF Lite对自家官网预置模型的支持度也不够完善;MindSpore Lite则实现了121个FP32,55个FP16以及71个INT8 CPU算子;而此次的1.1版本我们对控制流算子也进行一次大的调整与完善,以便更好的支持语音类模型。
2.2 ARM GPU
新增OpenCL算子10+,当前支持GPU算子总数为58,基本实现常见CV类网络覆盖;新增在线融合、Auto Tuning等特性支持,同时支持权重量化,实现8bit权重量化网络在GPU整网运行。
2.3 Kirin NPU
1.1版本我们完善了对华为麒麟NPU硬件平台的支持,增加了对Kirin 9000芯片的支持,同时新增了50+ NPU算子支持,从而实现支持大部分CV类场景在NPU上的加速执行;我们在华为最新的Mate 40手机上进行了几个典型网络的benchmark验证,NPU上推理时延较CPU推理有明显提升;
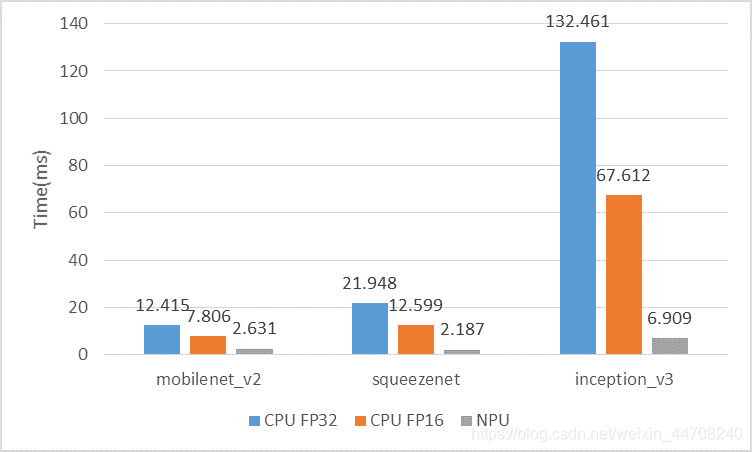
Mate 40上NPU和CPU FP32/16推理时延对比
3. 支持端侧训练
由于使用公共数据集训练的模型与真实用户场景存一定的偏差,比如人脸识别、语音识别等场景,我们往往需要利用本地数据对预训练模型进行微调,从而提高本地模型推理的精度,改善用户体验。
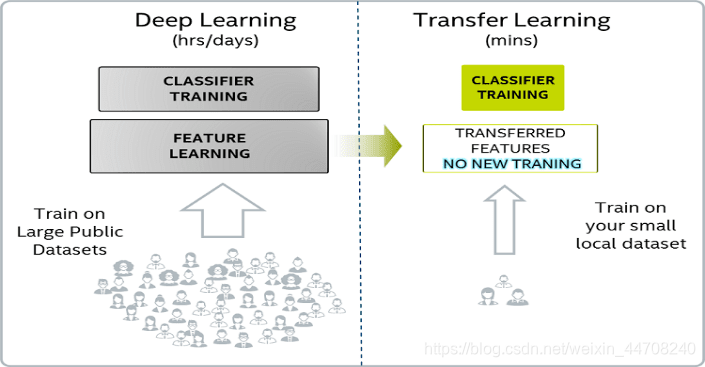
MindSpore Lite 1.1版本我们将端侧训练框架进行了开源,首个版本给我们带来了以下特性:
1) 支持30+反向算子,提供SGD、ADAM等常见优化器及CrossEntropy/SparsCrossEntropy/MSE等损失函数;既可从零训练模型,也可指定特定网络层微调,达到迁移学习目的;
2) 已支持LeNet/AlexNet/ResNet/MobileNetV1/V2/V3和EffectiveNet等网络训练,提供完整的模型加载,转换和训练脚本,方便用户使用和调测;
3) MindSpore云侧训练和端侧训练实现无缝对接,云侧模型可直接加载到端侧进行训练;
4) 支持checkpoint机制,训练过程异常中断后可快速恢复继续训练;
我们的端侧训练框架已经在华为部分设备的AI应用比如家庭相册等场景进行了商用,并取得了很好的用户体验。
4. 训练后量化
随着AI应用在端侧设备部署越来越普遍,而受制于端侧资源的局限性,对于模型小型化和推理性能提升的挑战日益倍增。MindSpore Lite提供了简单实用的训练后量化功能,最大程度压缩模型大小,减小内存占用,提升推理速度,降低功耗。
训练后量化相较于量化重训具有两个明显优势,一是无需大量训练数据集,二是无需重新训练,离线快速转换。MindSpore Lite训练后量化工具提供权重量化和全量化两种方法,支持1~16bit量化,支持分类,检测,NLP等多种模型。
为保障训练后量化模型精度损失小,我们采用pipeline组合量化方法,一阶段采用常规线性量化手段对权重和激活值进行量化,二阶段对量化误差进行分析,利用统计学方法对量化模型进行校正,补偿因量化带来的精度损失。
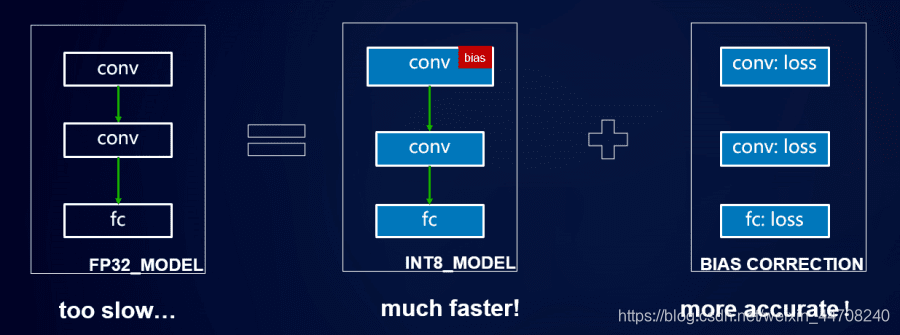
Pipeline 组合量化
以TF官网MobileNet_v2模型为例,MindSpore Lite训练后量化A8W8(激活值8bit量化、权重8bit量化)精度与FP32模型相比,经损失校正后,精度损失由0.82%降到0.4%,同样适用7bit量化下,精度损失仍不超过1%。
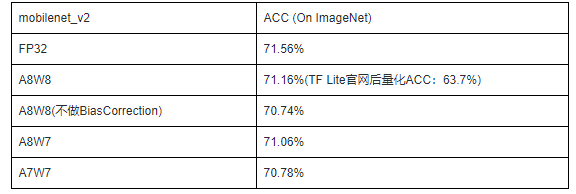
训练后全量化mobilenet_v2模型精度对比
我们在HMS Face场景下模型进行了INT8权重量化(模型size范围364KB~2.9MB),实际端到端识别精度完全满足服务要求。权重量化精度损失矫正方案的相对精度误差对比如下,可以看到损失矫正方案下量化精度损失有明显降低。
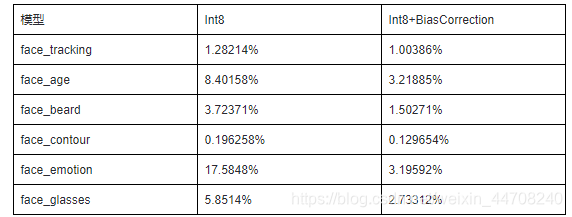
Face场景模型权重量化精度损失矫正方案相对精度损失对比
经内部大量测试和实际商用交付反馈,pipeline组合量化方法效果显著,甚至小至300KB的模型,经INT8量化压缩后精度仍满足商用要求。
5. 易用性增强
5.1 加速库自动裁剪工具
为了满足部分对发布包大小有极致小型化诉求的场景,我们提供了一个一键式裁剪工具,该工具可以根据用户指定的模型列表,自动裁剪出足以运行列表中指定模型的最小化MindSpore Lite版本。
5.2 离线工具参数精简
我们对离线转换工具参数进行了精简,最大程度地提高转换工具的易用性,让开发者在转换三方模型时,无需感知三方模型的量化类型、输入输出节点名称和对应的数据类型等。
5.3 支持Java接口
1.1版本正式开放了Java接口,以方便安卓开发者更简单的使用MindSpore Lite进行应用开发。
5.4 模型可视化
为了方便开发者调试,我们在Netron开源社区提交了支持MindSpore Lite模型可视化的代码,现在开发者可以使用Netron工具可视化MindSpore Lite模型。相信能给开发者调试模型,尤其是一些结构复杂的模型,带来极大的方便。
6. 开放更多的端侧预置模型
为了方便开发者在端侧快速部署自己的AI业务,MindSpore开放了更多的适合端侧使用的模型,其中不乏一些MindSpore首发的原创模型,这些模型可以方便的在MindSpore Hub上获取。
6.1 使用SCOP算法在Oxford-III Pet数据集对ResNet50网络剪枝的模型
SCOP:Scientific Control for Reliable Neural Network Pruning,是华为诺亚方舟实验室和北京大学联合提出了一种科学控制机制最小化剪枝节点对网络输出的影响。采用这种剪枝方法,能够实现ImageNet数据集上仅损失ResNet101网络0.01%的top-1准确率,模型参数量和计算量分别减少57.8%和60.2%,显著优于SOTA方法。模型链接:https://www.mindspore.cn/resources/hub/details?noah-cvlab/gpu/1.0/resnet-0.65x_v1.0_oxford_pets
6.2 基于SLB轻量化技术的模型VGG-Small
该模型使用华为诺亚方舟实验室入选NeurIPS 2020模型轻量化技术中的SLB量化技术(Searching for Low-Bit Weights in Quantized Neural NetWorks),在CIFAR10上基于2-bit weight和2-bit activation量化得到的端侧模型。模型链接:https://www.mindspore.cn/resources/hub/details?noah-cvlab/gpu/1.0/VGG-Small-low-bit_cifar10
如果想了解更多关于以上MindSpore首发模型中使用的轻量化技术,请参考:https://mp.weixin.qq.com/s/H1zg3ezZDdXQ-IQ7ki0Mtw
测试数据来自于华为内部实验室测试数据,有疑问可以在MindSpore论坛上进行反馈:https://bbs.huaweicloud.com/forum/forum-1076-1.html
MindSpore开源代码仓链接:https://gitee.com/mindspore/mindspore
原文链接:https://developer.huawei.com/consumer/cn/forum/topic/0202453926225910779?fid=18
原作者:胡椒