文章目录
前言
今天无聊的刷着CSDN,偶然发现了个爬虫练习网站GlideSky,这让我虎躯一震,瞬间就来精神了,最为爬虫爱好者,对于这种网站当然是十分有兴趣的,于是我点进去看了看。
首先要注册个账号,这不是什么问题,注册好后去看了看网站定位,如下

emm…确实不错,大家也可以去注册个账号练习练习
话不多说,直接第一关
1、第一关
网站页面如下,就是一堆数字

2、第一关答案及注释分析
import requests
from bs4 import BeautifulSoup
#头文件
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36",
#注意带上Cookie,不然会被拦截,参考图1,大家参考自己填上
"Cookie": ""
}
#最后的总数
sum = 0
#请求地址
url = "http://glidedsky.com/level/web/crawler-basic-1"
response = requests.get(url=url,headers=headers)
#使用 BeautifulSoup 解析
data = BeautifulSoup(response.text,"lxml")
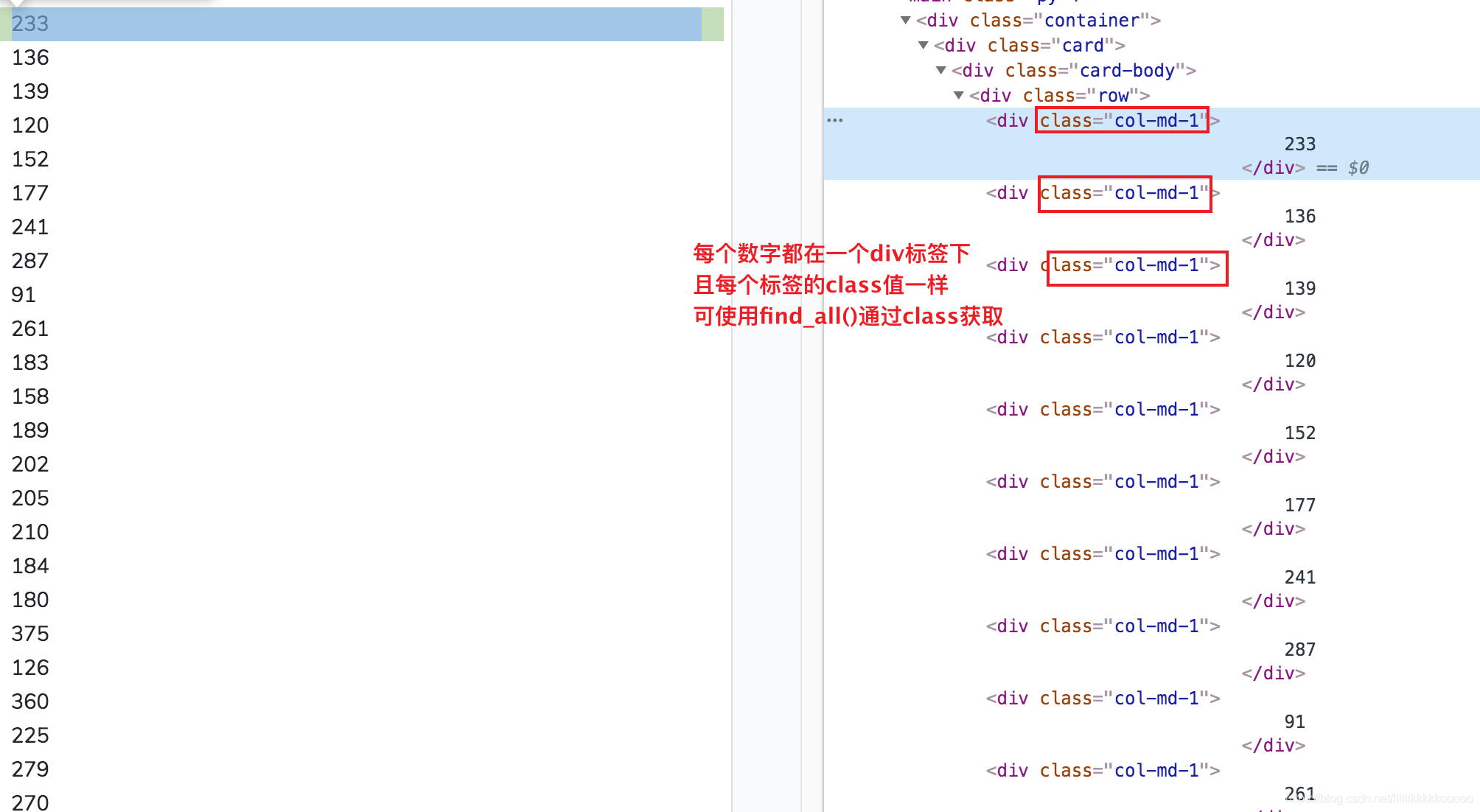
#参考图2,获取全部数字,遍历
div_list = data.find_all(class_="col-md-1")
for div in div_list:
d = BeautifulSoup(str(div),"lxml")
sum += int(d.text.strip())
print(sum)

提交答案

闯关成功!!!
3、网页辅助分析
图1
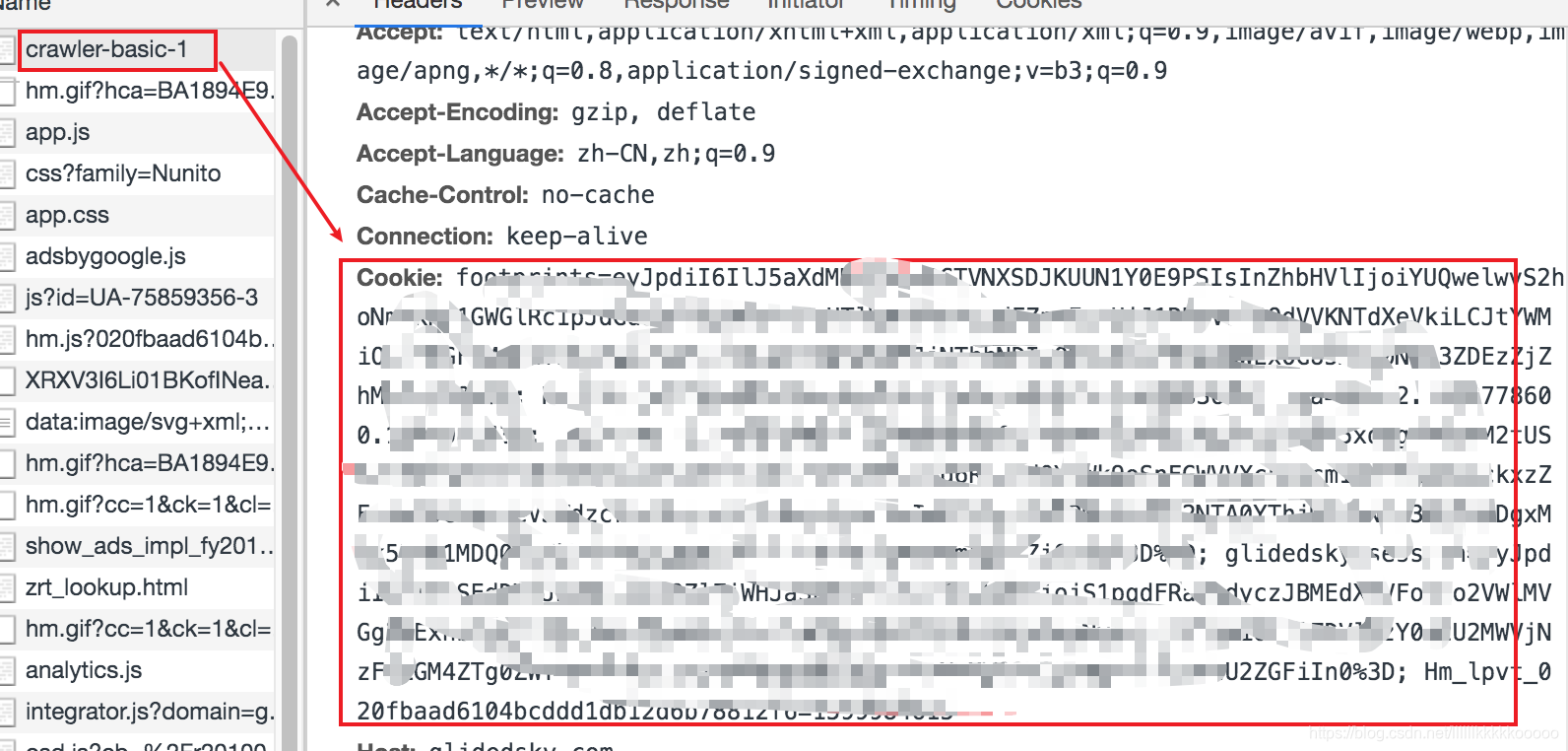
图2
博主会持续更新,有兴趣的小伙伴可以点赞、关注和收藏下哦,你们的支持就是我创作最大的动力!
博主开源Python爬虫教程目录索引(宝藏教程,你值得拥有!)