这个教程参考的是百度PaddlePaddle的RL系列教程:https://aistudio.baidu.com/aistudio/projectdetail/1445501
背景介绍
第一章节属于基础内容,第二课的数学知识总结的很好

1. 开始
1.1 概念认识
1.1.1 强化学习 vs 其他
强化学习与监督学习的区别
- 强化学习、监督学习、非监督学习是机器学习里的三个不同的领域,都跟深度学习有交集。
- 监督学习寻找输入到输出之间的映射,比如分类和回归问题。
- 非监督学习主要寻找数据之间的隐藏关系,比如聚类问题。
- 强化学习则需要在与环境的交互中学习和寻找最佳决策方案。
- 监督学习处理认知问题,强化学习处理
决策问题。 - 监督学习的样本一般是独立同分布的,而强化学习的序列决策数据,当前的决策会受到上一个决策的影响
1.1.2 强化学习的如何解决问题
- 强化学习通过不断的试错探索,吸取经验和教训,持续不断的优化策略,从环境中拿到更好的反馈。
- 强化学习有两种学习方案:
基于价值(value-based)、基于策略(policy-based)
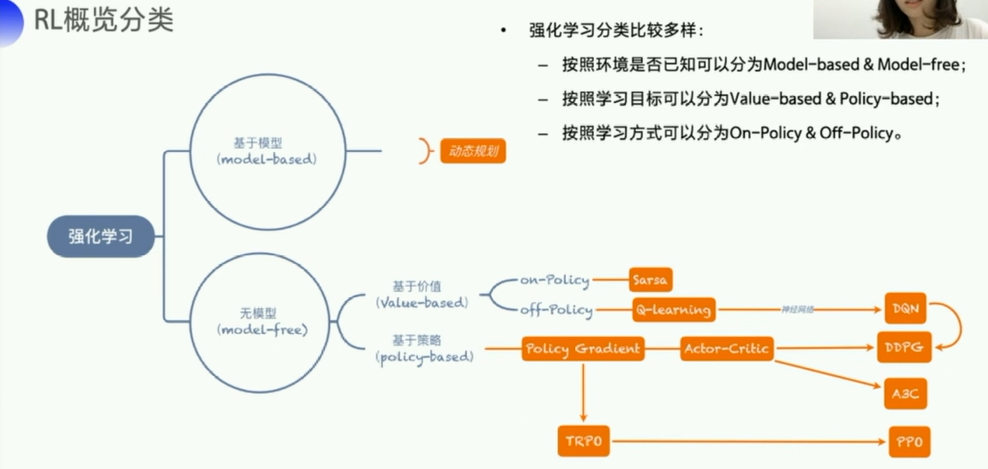
1.1.3 强化学习的算法和环境
- 经典算法:
Q-learning、Sarsa、DQN、Policy Gradient、A3C、DDPG、PPO - 环境分类:离散控制场景(输出动作可数)、连续控制场景(输出动作值不可数)
- 强化学习经典
环境库GYM将环境交互接口规范化为:重置环境reset()、交互step()、渲染render()- gym是环境 environment
- 强化学习
框架库PARL将强化学习框架抽象为Model、Algorithm、Agent三层,使得强化学习算法的实现和调试更方便和灵活。- parl是智能体/agent/算法部分
1.2 代码实践
1.2.1 环境配置
-
GYM是强化学习中经典的环境库,下节课我们会用到里面的
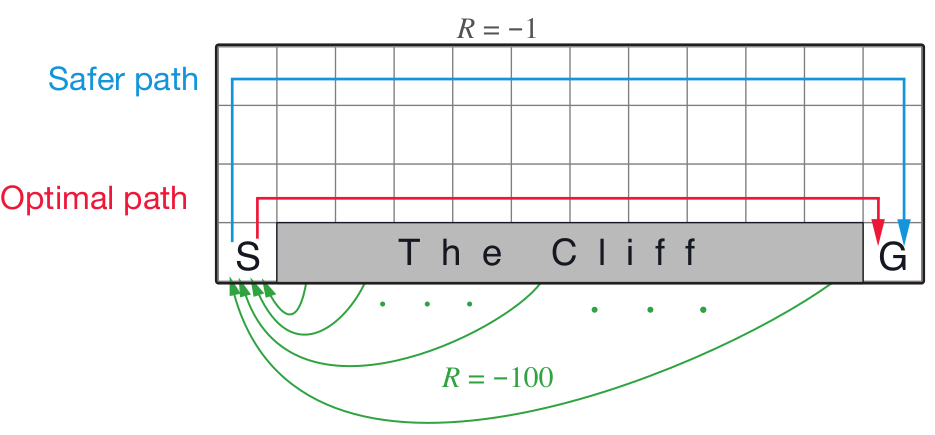
CliffWalkingWapper和FrozenLake环境,为了使得环境可视化更有趣一些,直播课视频中演示的Demo对环境的渲染做了封装,感兴趣的同学可以在PARL代码库中的examples/tutorials/lesson1中下载gridworld.py使用。- CliffWalkingWapper 在悬崖边走路的游戏
- 参考:
- 代码github地址:代码中有说明https://github.com/openai/gym/blob/master/gym/envs/toy_text/cliffwalking.py
- FrozenLake 在gym官网中可以看到这个游戏的动画视频:https://gym.openai.com/envs/#toy_text

- 代码github地址:代码中有说明https://github.com/openai/gym/blob/master/gym/envs/toy_text/frozen_lake.py
-
PARL教程中的jupyter使用的Python版本是3.7,就建立一个一样的好了。
- 新建conda环境
# 新建环境 conda create -n rl37 python=3.7 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ # 安装gym包 pip install gym # 如果速度慢,可以考虑换一个chanel pip install gym -i https://mirrors.aliyun.com/pypi/simple/ # 配置jupyter notebook内核 pip install ipykernel python -m ipykernel install --user --name rl37 --display-name "rl37" -
PARL开源库地址:https://github.com/PaddlePaddle/PARL
参考内容
这部分网上已经有很多其他博主也已经学习过了,可以参考:
1.3 强化学习初印象
1.3.1 资料推荐
课程ppt小红小蓝捉迷藏的链接:
- https://openai.com/blog/emergent-tool-use/
- 相应的视频应该是来自b站,(直接搜索emergent-tool-use 也会有很多类似的视频)
红球绿球链接:
书籍
- 《Reinforcement Learning:An Introduction(强化学习导论)》(强化学习教父Richard Sutton 的经典教材): http://incompleteideas.net/book/bookdraft2018jan1.pdf
论文
- DQN. “Playing atari with deep reinforcement learning.”
https://arxiv.org/pdf/1312.5602.pdf - A3C. “Asynchronous methods for deep reinforcement learning.”
http://www.jmlr.org/proceedings/papers/v48/mniha16.pdf - DDPG. “Continuous control with deep reinforcement learning.”
https://arxiv.org/pdf/1509.02971 - PPO. “Proximal policy optimization algorithms.”
https://arxiv.org/pdf/1707.06347
前沿研究方向
- Model-base RL,Hierarchical RL,Multi Agent RL,Meta Learning
视频推荐
b站(视频下方评论区有很多自发总结的笔记,博客等,可以借鉴)
-
周博磊:https://space.bilibili.com/511221970/channel/detail?cid=105354

-
李宏毅:
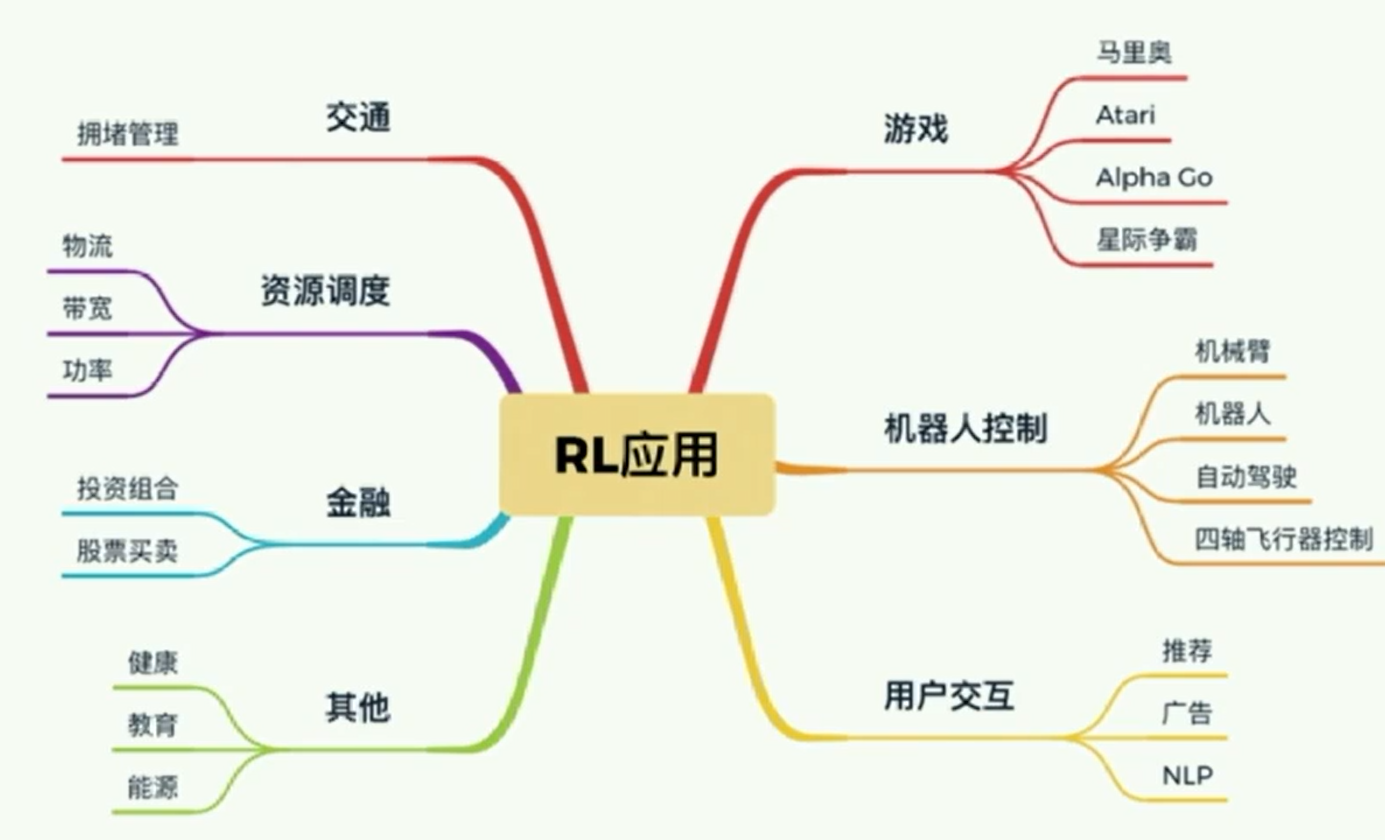
应用方向
- 游戏(马里奥、Atari、Alpha Go、星际争霸等)
- 机器人控制(机械臂、机器人、自动驾驶、四轴飞行器等)
- 用户交互(推荐、广告、NLP等)
- 交通(拥堵管理等)
- 资源调度(物流、带宽、功率等)
- 金融(投资组合、股票买卖等)
- 其他
1.4 强化学习核心知识
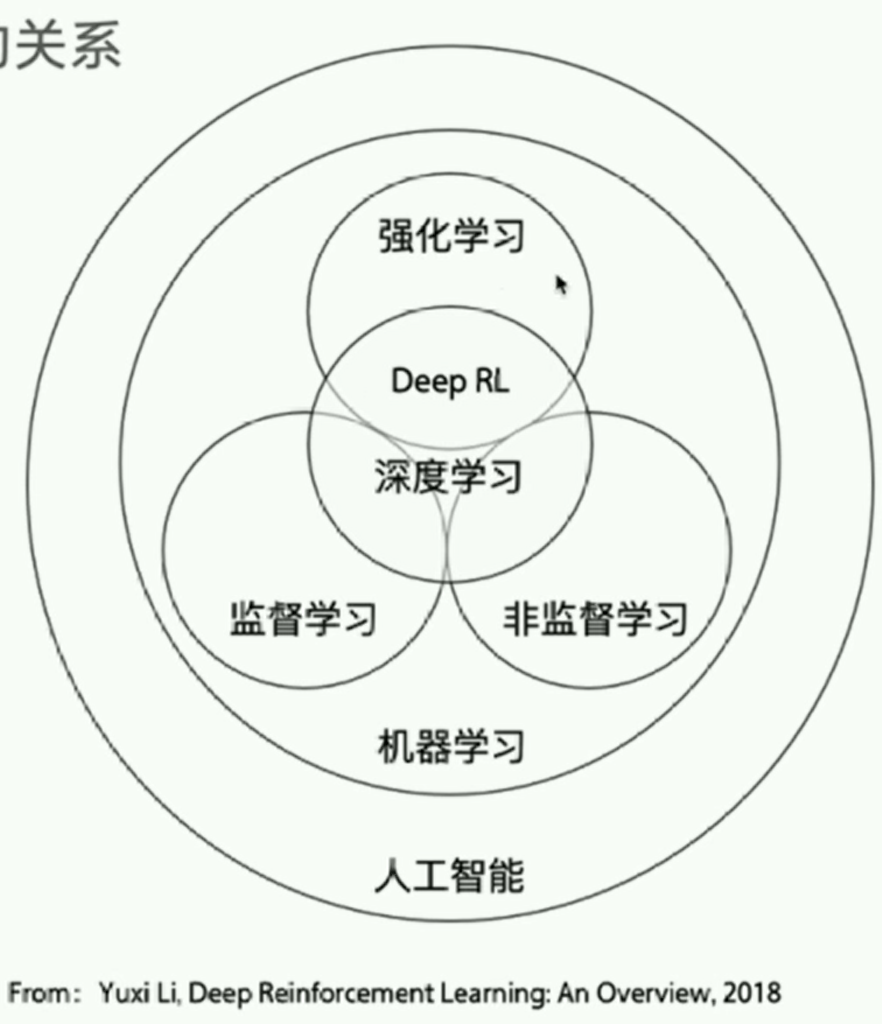
deep reinforcement learning an overview,论文地址:https://arxiv.org/pdf/1701.07274.pdf

算法框架库
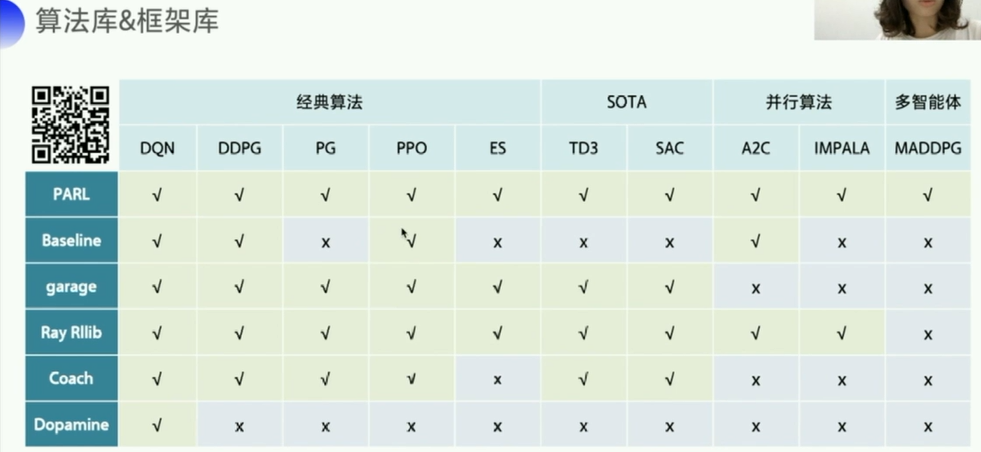
环境库

- 离散:输出的动作是可数的(动作空间是个数字)
- 连续:输出的动作是不可数的(比如机器人关节移动的角度)
- 控制机器人移动,旋转角度是连续,开关是离散
- DQN是一个面向离散控制的算法,即输出的动作是离散的。
- 对应到Atari 游戏中,只需要几个离散的键盘或手柄按键进行控制。
- 然而在实际中,控制问题则是连续的,高维的,比如一个具有6个关节的机械臂,每个关节的角度输出是连续值,假设范围是0°~360°,归一化后为(-1,1)。若把每个关节角取值范围离散化,比如精度到0.01,则一个关节有200个取值,那么6个关节共有2006
- 参考:https://www.cnblogs.com/alan-blog-TsingHua/p/9727175.html

1.5 gym,PARL(PaddlePaddle Reinforcement Learning)
1.5.1 环境安装
安装参考github说明:https://github.com/PaddlePaddle/PARL/tree/develop/examples/tutorials
windows上只支持python3.7的环境
安装依赖
- paddlepaddle>=1.8.5
- 可参见官网,安装语句类似于pytorch,没有cuda11.0的支持
- 参考:https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/1.8/install/pip/windows-pip.html
- 暂时安装没有cpu的版本,1.8.5好了
python -m pip install paddlepaddle==1.8.5 -i https://mirror.baidu.com/pypi/simple

报了一个问题,OpenCV不兼容,parl安装的时候也报了。。。后续如果出问题就重新安装一下好了
- parl==1.3.1
- 安装参考github链接:https://github.com/PaddlePaddle/PARL
- windows上只支持python3.7
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple parl --upgrade- 但是这样安装之后,其实那些例子还是没法使用,要git clone一部分,参考github文档QuickStart:https://github.com/PaddlePaddle/PARL/tree/develop/examples/QuickStart
pip install gym git clone --depth 1 https://github.com/PaddlePaddle/PARL.git cd PARL pip install .- 关于depth 1参数说明,参考:
- 速度很慢,除了修改hosts文件,可以考虑使用其他加速方式,慢慢等也可以,几十KB的走,也就1小时左右吧就下好了
- gym
- 直接查看了gym的版本是0.18.0
1.5.2 gym简单使用
跟着老师的步骤敲就可以,使用ipython编辑环境会报错,就使用原生的python编辑就好,暂时没有遇到OpenCV版本导致的错误,哈哈哈。
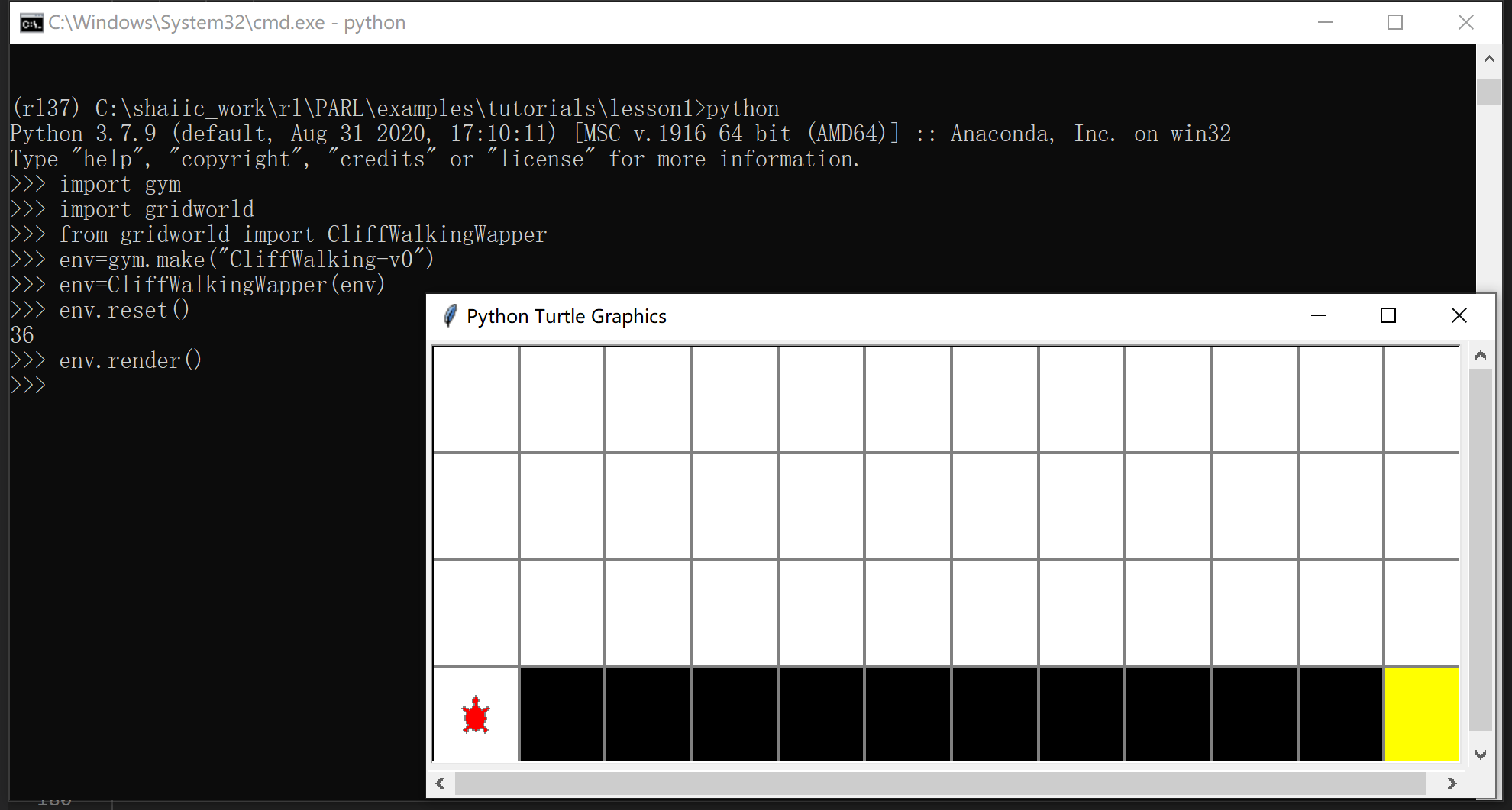
程序介绍
将gridworld.py程序和gym中的cliffwalkingwapper.py一起看,
- https://github.com/PaddlePaddle/PARL/blob/develop/examples/tutorials/lesson1/gridworld.py
- https://github.com/openai/gym/blob/master/gym/envs/toy_text/cliffwalking.py
大致说明一下这个程序里用到的一些东西
env.reset()复位,让这个小乌龟回到初始位置,初始位置是36号格子

env.step()让小乌龟进行一个动作,
- UP = 0
- RIGHT = 1
- DOWN = 2
- LEFT = 3
env.render()每次环境状态(小乌龟走了一步之后,图会改变)发生改变,要重新渲染这个图才能看到新的环境状态。
下面是先0,上一步,再1,右一步之后小乌龟的位置(环境的状态)
每次step返回的四个值分别表示:
- 24 当前乌龟的位置,
- -1是reward,
- False,游戏是否结束,是否到达黄色终点位置
- 概率 1.0 暂时这个程序用不到转移函数概率

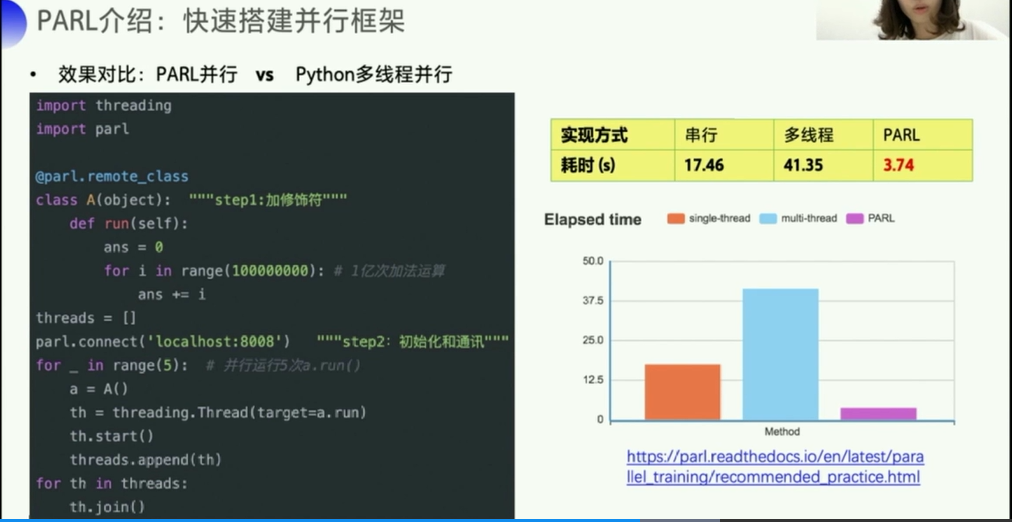
1.5.3 PARL

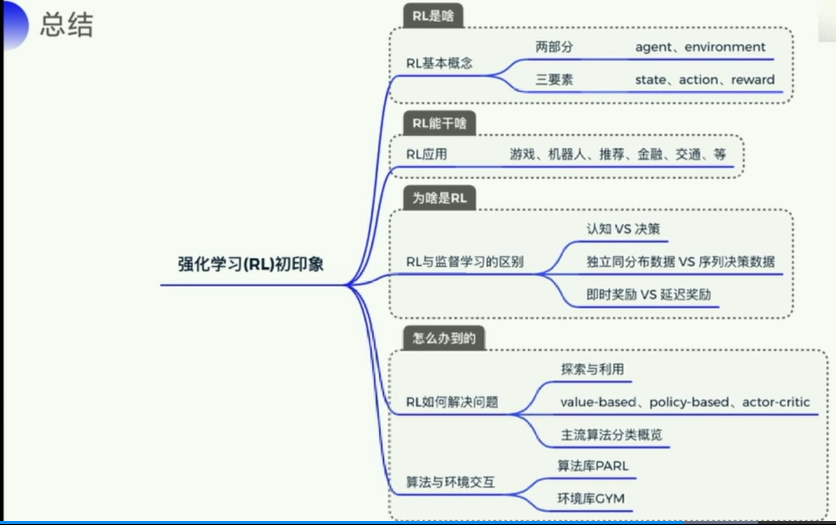
1.6 总结
1.7 课后作业
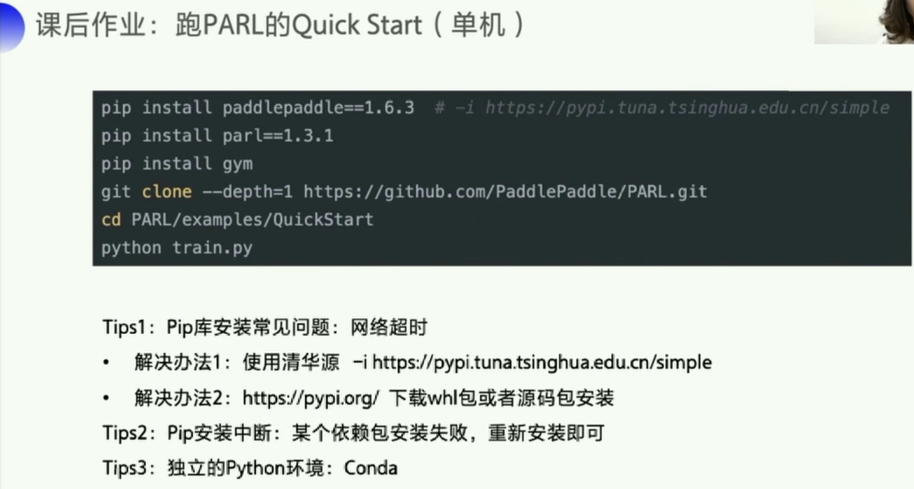
pip install paddlepaddle==1.6.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install parl==1.3.1
pip install gym
git clone --depth=1 https://github.com/PaddlePaddle/PARL.git
cd PARL/examples/QuickStart
python train.py
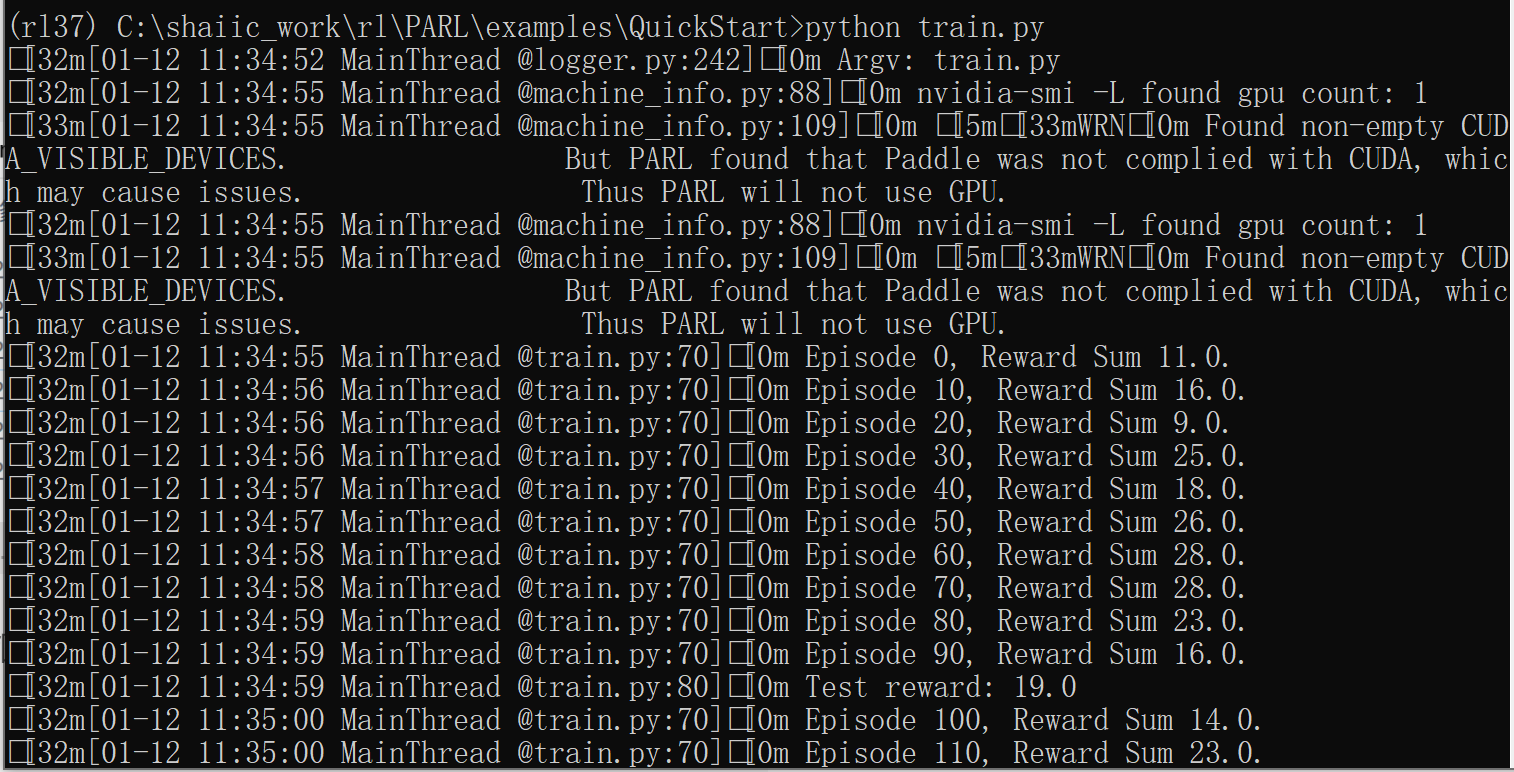
可以看到目录里有一个这个程序运行后的效果gif图。此外,程序输出信息类似:
最后目录中会产生一个新的model_dir文件夹,但是里卖的内容打不开

2. 其他资料
2.1 为什么叫强化
参考关于强化理论的解释:强化理论/Reinforcement theory
强化理论(Reinforcement theory)是美国的心理学家和行为科学家斯金纳(B. F. Skinner)等人提出的一种理论,也称为行为修正理论或行为矫正理论。
斯金纳认为人是没有尊严和自由的,人们作出某种行为,不做出某种行为,只取决于一个影响因素,那就是行为的后果。他提出了一种“操作条件反射”理论,认为人或动物为了达到某种目的,会采取一定的行为作用于环境。当这种行为的后果对他有利时,这种行为就会在以后重复出现;不利时,这种行为就减弱或消失。人们可以用这种正强化或负强化的办法来影响行为的后果,从而修正其行为。
最早提出强化概念的是俄国著名的生理学家巴甫洛夫,
在巴甫洛夫经典条件反射中,强化指伴随于条件刺激物之后的无条件刺激的呈现,是一个行为前的、自然的、被动的、特定的过程。
而在斯金纳的操作条件反射中,强化是一种人为操纵,是指伴随于行为之后以有助于该行为重复出现而进行的奖罚过程。
巴甫洛夫等的实验对象的行为是刺激引起的反应, 称为“应答性反应( respondents) ”;
而斯金纳的实验对象的行为是有机体自主发出( emitted) 的, 称为“操作性反应( operant) ”。
经典条件作用只能用来解释基于应答性行为的学习, 斯金纳把这类学习称为“S( 刺激) 类条件作用”;另一种学习模式,即操作性或工具性条件作用的模式, 则可用来解释基于操作性行为的学习, 他称为“R( 强化) 类条件作用”,并称为“S-R” 心理
此外,参考OSCHINA文章:涨知识,什么是强化学习(Reinforcement Learning)
强化学习(Reinforcement Learning)灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。
这个方法具有普适性,因此在其他许多领域都有研究,例如博弈论、控制论、运筹学、信息论、模拟优化方法、多主体系统学习、群体智能、统计学以及遗传算法。
强化学习采用的是边获得样例边学习的方式,在获得样例之后更新自己的模型,利用当前的模型来指导下一步的行动,下一步的行动获得reward之后再更新模型,不断迭代重复直到模型收敛。
在这个过程中,非常重要的一点在于“在已有当前模型的情况下,如果选择下一步的行动才对完善当前的模型最有利”,这就涉及到了RL中的两个非常重要的概念:
探索(exploration)和开发(exploitation),
exploration是指选择之前未执行过的actions,从而探索更多的可能性;
exploitation是指选择已执行过的actions,从而对已知的actions的模型进行完善。
强化学习最重要的3个特点是:
- 基本是以一种闭环的形式;
- 不会直接指示选择哪种行动(actions);
- 一系列的actions和奖励信号(reward signals)都会影响之后较长的时间。
2.2 一些问题和回答
- 强化学习需不需要数据,数据哪里来?
- 需要数据,RL,L代表learning,学习就是从数据中学,所以是需要数据的。
- 数据从与环境的交互中来,或者也可以有一些历史数据
- 强化学习与监督学习、非监督学习的关系?
- 强化学习属于半监督学习,与这两个是并列关系
- GYM是什么? PARL又是什么?
- gym是一个环境库,gym是体育馆健身房的意思(发生动作的环境/场所)
- 参考:Open AI gym简介
- 论文介绍:https://arxiv.org/pdf/1606.01540.pdf
- Classic control and toy text:提供了一些RL相关论文中的一些小问题,开始学习Gym从这开始!
- Algorithmic: 提供了学习算法的环境,比如翻转序列这样的问题,虽然能很容易用直接编程实现,但是单纯用例子来训练RL模型有难度的。这些问题有一个很好的特性: 能够通过改变序列长度改变难度。
- Atari: 这里提供了一些小游戏,比如我们小时候玩过的小蜜蜂,弹珠等等。这些问题对RL研究有着很大影响!
- Board games: 提供了Go这样一个简单的下棋游戏,由于这个问题是多人游戏,Gym提供有opponent与你训练的agent进行对抗。
- 2D and 3D robots:机器人控制环境。 这些问题用 MuJoCo 作为物理引擎。
当然还有很多好玩的问题,比如CNN的自动调参、Minecraft等。
- PARL是一个算法库,
- gym是一个环境库,gym是体育馆健身房的意思(发生动作的环境/场所)