1.
服务之间的发现,服务之间的通信‘’
三种:
集群内部之间的服务的访问
通过Service,Service有ClusterIp,service可以指向多个pod,但是程序中布满了service的ip显然不雅,所以k8s提供了DNS
可以通过service的名字去访问service的ip。

第二种情况,多个实例之间需要交互的时候,需要知道服务列表具体有哪些pod,这种类型的Service就返回给podA一个列表。

集群内的服务和集群外的服务之间的通信,
集群内部的容器访问外部的mysql的时候,第一种是直接写死的ip去访问。

第二种方式是我可以像访问集群内部的服务一样去访问这个Mysql,先定义一个空的Service, 然后我们手动的定义一个EndPoint,他们的名字一样,然后他们会绑定在一起,EndPoint配置的就是一个具体的外部服务的地址。

集群外的服务到集群内的服务的通信(常见)
通过NodePort, NodePort是一种Service的类型,跟上面的Service相比除了有一个ClusterIp,之外他还会在每一个节点上都暴露一个端口出来,集群中的任何一个节点都会有一个端口,(用的少)

另外一种方式HostPort, 只是一个简单的端口映射。
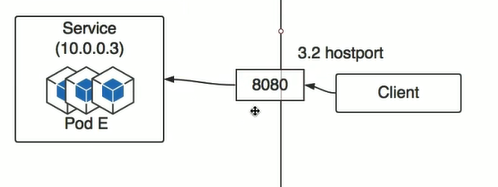
第三种情框 浏览器访问集群内部的一个pod,

ingress: 配置文件,在哪个域名下,哪个路径下,要解析到哪个Service,具体的实现由IngressController实现,

社区的Ingress实现
Ingress-nginx:使集群服务具备通过ip访问的能力

支持多个:

NameSpace:

k8s会创建一个叫default的默认的命名空间。

拿到命名空间下的所有资源:


Resources:

每个节点都要想主节点上报自己的资源情况。


Request是需要预留出来的资源,哪怕服务跑起来自用一点点资源,但是还是要预留出来,其他服务不能占用这个被预留的资源。如果内存改的非常的大,那么pod就会一直处于pending状态,他就一直起不来,没有满足他的需求的条件。cpu改的非常的大,pod处于pending的状态.,也是因为没有满足要求的条件。
pending状态的时候可以通过describe来查看原因

当CPU不满足的时候就可以看到没有足够的CPU资源的错误信息
如果内存的使用超过了limit的限制值,那么这个pod会被直接kill掉,如果cpu则不会,因为CPU是压缩资源。
内存资源出现竞争会杀pod,而cpu资源出现竞争不会杀pod。
那么如何查看这个服务用了多少的内存和CPU呢?
找到在这个节点上运行的容器:


服务的可靠性的最高,这两个的值相等的时候,如果这两个值都没有设置就是最不可靠。

label:
label的本质就是key value ,label可以贴到多个资源


意思就是这个Deploy只负责,具有app(key)为web-demo(value)这样标签的pod
