文章目录
一、正态数据
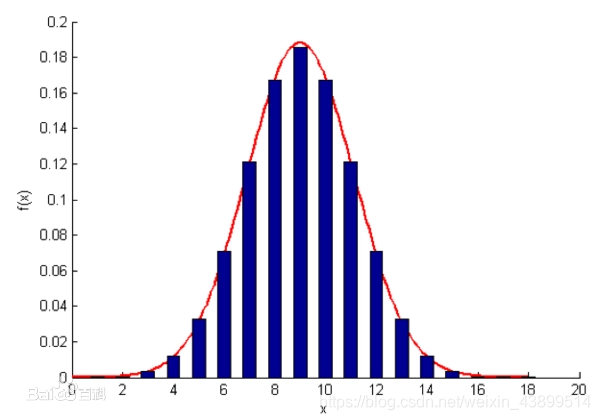
正态数据的分布是一个钟型分布,数据点的分布是中间高两边低的,例如一个学校里学生的身高。特别高和特别低的都少,高度居中的人较多。如下图(其中x轴为数据的取值,y轴为对应取值的频率)
二、数据需要正态化的原因
很多统计学的理论,如线性回归、假设检验和参数估计等,很多地方需要数据的分布为正态。而现实中的数据不一定服从正态或者是标准正态,因此需要对数据进行正态化,才可以使用已有的一些模型。有时候,模型的表现不好,可能跟数据的预处理有很大的关系。
三、两个指标判断是否是正态
数据一般有两个指标,样本均值和方差,一个是衡量数据分布的中心位置,另一个是衡量数据分布的离散程度。而正态分布也有l两个指标,偏度和峰度,其中偏度和数据分布的对称性有关,峰度与数据分的高矮胖瘦有关。
-
偏度
数据的偏度是衡量数据的分布是否是左右对称的。其中标准正态分布的偏度为零,非标准的数据分布分别称为“左偏”(偏度小于零,有极端小值)和“右偏”(偏度大于零,有极端大值)。 -
峰度
数据的峰度是衡量数据分布是否是高瘦的,还是胖乎乎的。其中标准正态分布的峰度为3,非标准的数据分布分别称为“尖峰”(峰度大于3,数据点较集中于中心位置)和“厚尾”(分度小于3,数据点较分散)。
四、如何对数据正态化
数据不是标准正态分布,正是因为数据的偏度和峰度与标准正态分布的不同。因此,解决数据正态化的关键,即判定数据的偏度和峰度问题,用对应的方法进行正态化。
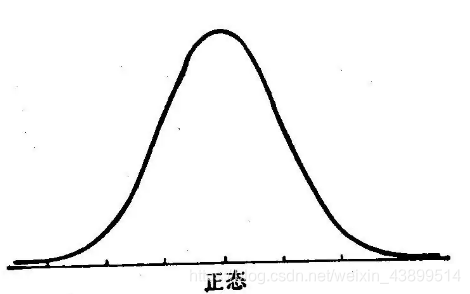
1. 偏态数据正态化(偏度)
偏态数据的正态化处理方式一般有指数变换、对数变换、Box-cox变换等,需要根据数据的不同情况进行选择。
左偏态
左偏数据:又称为负偏态,数据的分布存在极端小值,数值较大的数据点比较集中。因此需要一种方法,缩小数值较小的点之间的距离,将数值较大的数据点的距离增大。(或者是相对地缩小和放大)
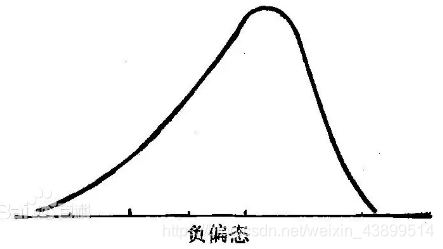
因此,这个时候可以指数变换,或者是其他的凹函数,因为指数变换在数据点的值较大的时候,变化率更大(导数),能把数值较大的数据点的距离增大。指数变换公式: x n e w = e x o l d x_{new} = e^{x_{old}} xnew=exold,图像如下

例如:若数据点取值为1,2,9,10,虽然数据的原始距离相等,即 2 − 1 = 10 − 9 2-1 = 10-9 2−1=10−9,但是变换后距离,数据取值较大的距离增加的更大,即 e 2 − e 1 < e 10 − e 9 = 13923 e^2-e^1 < e^{10}-e^{9}=13923 e2−e1<e10−e9=13923.
右偏态
右偏数据又称为正偏态,情况和左偏的恰好相反,有较大的数据点,处理方法也是恰好相反。
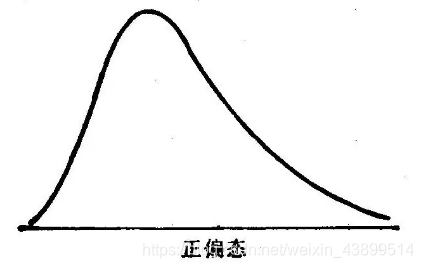
因此可以考虑对数变换,或者是其他的凸函数,因为对数变换在数据点的值较大的时候,变化率更小(导数),能把数值较大的数据点的距离相对减小。对数变换的公式为: x n e w = l n ( x o l d ) x_{new}=ln(x_{old}) xnew=ln(xold),图像如下
例如,若数据点取值为1,2,9,10,虽然数据的原始距离相等,即 2 − 1 = 10 − 9 2-1 = 10-9 2−1=10−9,但是变换后距离,数据取值较大的距离增加的更小,即 0.693 = l n 2 − l n 1 > l n 10 − l n 9 = 0.105 0.693=ln2-ln1 > ln{10}-ln{9}=0.105 0.693=ln2−ln1>ln10−ln9=0.105.
偏态不分左右偏
使用Box-cox变换,它既可以处理左偏的情况,又可以处理右偏的情况。很多软件中可以调包,这里仅提供这个思路。百度百科
y ( λ ) = { y λ − 1 λ , λ ≠ 0 ln y , λ = 0 y(\lambda)=\left\{\begin{array}{ll} \frac{y^{\lambda}-1}{\lambda}, & \lambda \neq 0 \\ \ln y, & \lambda=0 \end{array}\right. y(λ)={
λyλ−1,lny,λ=0λ=0
2. 正态数据标准化(峰度)(无论什么数据标准化后就服从正态了吗?)
经常会听到数据标准化这个概念,说是经过标准化后,数据就服从正态分布了,其实这种说法是不严谨的。因为数据非
首先需要强调的是,数据标准化只能将一个正态分布变成标准正态分布,并不能将偏态数据变成正态分布,所以,数据标准化处理的是正态分布数据峰度不等于3(标准正态分布)和正态数据的均值不为0的情况。

数据标准化的意义主要是,在回归问题中,可以使得各变量更具有可比性,同时分析结果更容易满足回归分析的残差假定。
总结
- 数据不是标准正态分布的主要原因,来源于数据的偏度和峰度。
- 处理偏度的通常方式有指数变换、对数变换和box-cox变换。
- 处理峰度的通常方式是数据的标准化。
- 另外数据的标准化,不能将偏态数据变成正态分布。