Spring Mvc 和 Spring WebFlux
Spring MVC 构建于 Servlet API 之上,使用的是同步阻塞式 I/O 模型,每一个请求对应一个线程去处理。
Spring WebFlux 是一个异步非阻塞式的 Web 框架,它能够充分利用多核 CPU 的硬件资源去处理大量的并发请求。
WebFlux 的优势&提升性能
WebFlux 内部使用的是响应式编程(Reactive Programming),以 Reactor 库为基础, 基于异步和事件驱动,可以让我们在不扩充硬件资源的前提下,提升系统的吞吐量和伸缩性。
WebFlux 并不能使接口的响应时间缩短,它仅仅能够提升吞吐量和伸缩性。
WebFlux 应用场景
Spring WebFlux 是一个异步非阻塞式的 Web 框架,所以,它特别适合应用在 IO 密集型的服务中,比如微服务网关这样的应用中。
备注:
IO 密集型包括:磁盘IO密集型, 网络IO密集型,微服务网关就属于网络 IO 密集型,使用异步非阻塞式编程模型,能够显著地提升网关对下游服务转发的吞吐量。
异同点

相同点:
- 都可以使用 Spring MVC 注解,如
@Controller, 方便我们在两个 Web 框架中自由转换; - 均可以使用 Tomcat, Jetty, Undertow Servlet 容器(Servlet 3.1+);
注意点:
- Spring MVC 因为是使用的同步阻塞式,更方便开发人员编写功能代码,Debug 测试等,一般来说,如果 Spring MVC 能够满足的场景,就尽量不要用 WebFlux;
- WebFlux 默认情况下使用 Netty 作为服务器;
- WebFlux 不支持 MySql;
响应式编程
Reactive Streams
响应式流和迭代器较相似,不过迭代器是基于“拉”(pull)的,而响应式流是基于“推”(push)的。 迭代器的使用其实是命令式编程,因为由开发者决定什么时候调用next()获取下一个元素。
在响应式流中,与上面等价的是发布者-订阅者。但当有新的可用元素时,是由发布者推给订阅者的。这个“推”就是响应式的关键所在。另外,对被推过来元素的操作也是以声明的方式进行的,程序员只需表达做什么就行了,不需要管怎么做。
发布者使用onNext方法向订阅者推送新元素,使用onError方法告知一个错误,使用onComplete方法告知已经结束。可见,错误处理和完成(结束)也是以一个良好的方式被处理。错误和结束都可以终止序列。这种方式非常灵活。这种模式支持0个(没有)元素/1个元素/n(多)个元素(包括无限序列,如果滴答的钟表)这些情况。
顶级接口
package org.reactivestreams;
Publisher
public interface Publisher<T> {
//注册订阅者
public void subscribe(Subscriber<? super T> s);
}
Consumer
public interface Subscriber<T> {
/**
* 该方法在订阅Publisher之后执行,在订阅之前不会有数据流的消费
*/
public void onSubscribe(Subscription s);
/**
* 消费下一个消息,在执行request方法之后通知Publisher,可被调用多次,有request(x),参数x决定执行几次
*
* @param t the element signaled
*/
public void onNext(T t);
/**
* 订阅失败事件
* @param t the throwable signaled
*/
public void onError(Throwable t);
/**
* 订阅成功事件
*/
public void onComplete();
}
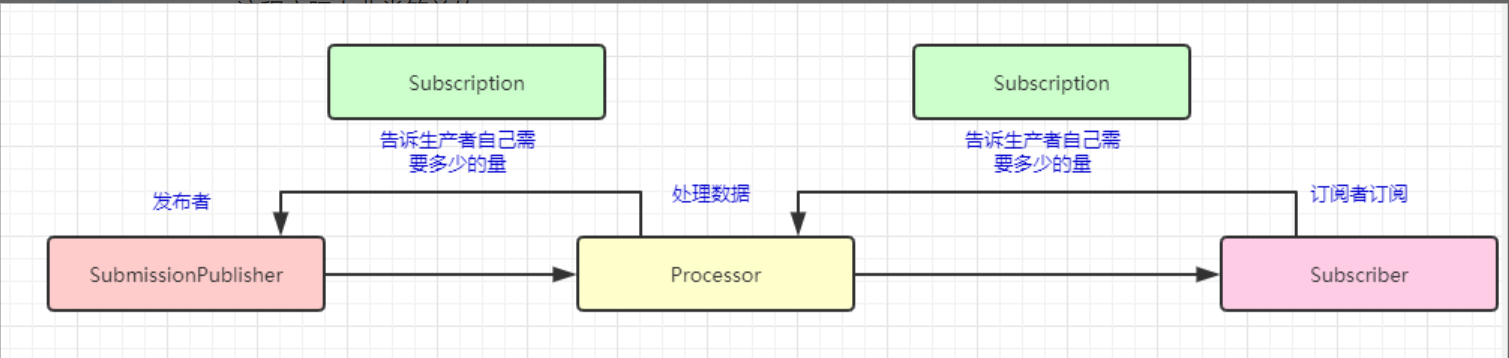
Subscription
生产消费对象参数 。用于发布者与订阅者之间的通信(实现背压:订阅者能够告诉生产者需要多少数据)
public interface Subscription {
/**
* 消费请求 。request(n)来决定这次subscribe获取元素的最大数目
*/
public void request(long n);
/**
* 取消请求。并且清除resources。cancel执行后,不一定会立即取消,可能由于前面的信号。
*/
public void cancel();
}
Processor
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> {
}
Reactor
Reactor实现
Reactor引入可组合响应式的类型,实现了发布者接口,但也提供了丰富的操作符,就是Flux和Mono。
-
Flux,流动,表示0到N个元素。
-
Mono,单个,表示0或1个元素。
它们之间的不同主要在语义上,表示异步处理的粗略基数。
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-core</artifactId>
<version>3.3.5.RELEASE</version>
</dependency>
Flux
一个Flux<T>是一个标准的Publisher<T>,表示一个异步序列,可以发射0到N个元素,可以通过一个完成信号或错误信号**终止**。这3种类型的信号转化为对一个下游订阅者的***onNext***,***onComplete***,***onError***3个方法的调用。这3个方法也可以理解为事件/回调,且它们都是可选的。
如没有onNext但有onComplete,表示一个空的有限序列。既没有onNext也没有onComplete,表示一个空的无限序列(没有什么实际用途,可用于测试)。无限序列也没有必要是空的,如Flux.interval(Duration)产生一个Flux ,它是无限的,从钟表里发射出的规则的“嘀嗒”。
Mono
一个Mono是一个特殊的Publisher,最多发射一个元素,可以使用***onComplete***信号或**onError信号来终止。
它提供的操作符只是Flux提供的一个子集,同样,一些操作符(如把Mono和Publisher结合起来)可以把它切换到一个Flux。如Mono#concatWith(Publisher)返回一个Flux,然而Mono#then(Mono)返回的是另一个Mono。Mono可以用于表示没有返回值的异步处理(与Runnable相似),用Mono表示。
Flux常用函数
调试reactor
在我们传统阻塞代码里面,调试(Debug)的时候是一件非常简单的事情,通过打断点,得到相关的stack 的信息,就可以很清楚的知道错误信息。 但是在reactor 环境下去调试代码并不是一件简单的事情,最常见的就是 一个 Flux流,怎么去得到每个元素信息,怎么去知道在管道里面下一个元素是什么,每个元素是否像期望的那样做了操作。
官方推荐的工具是 StepVerifier 。
https://projectreactor.io/docs/core/release/reference/index.html#testing
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-test</artifactId>
<scope>test</scope>
<version>3.3.5.RELEASE</version>
</dependency>
示例:
@Test
public void reactorTest(){
StepVerifier.create(Flux.just(1,2)) //1
.expectNext(1,2) //2
.expectComplete() //3
.verify(); //4
}
- 创建测试的异步流
- 测试期望的值
- 测试是否完成
- 验证
StepVerifier方法
-
map:同stream。
-
flatmap :同stream。
-
filter:同stream。
-
zip
“压缩”就是将多个流一对一的合并起来,还有一个原因,因为在每个flux流或者mono流里面,各个流的速度是不一样,zip还有个作用就是将两个流进行同步对齐。
Reactor中的多线程
Schedulers
在reactor中处理线程调度的不叫thread pool,而是Schedulers(调度器),通过调度器就可以创建出供我们直接使用的多线程环境。
Schedulers.immediate()
在当前线程中使用
Schedulers.single()
创建一个可重用的单线程环境,该方法的所有调用者都会重复使用同一个线程。
Schedulers.elastic()
创建一个弹性线程池,会重用空闲线程,当线程池空闲时间过长就会自动废弃掉。通常使用的场景是给一个阻塞的任务分配自己的线程,从而不会影响到其他任务的执行。
Schedulers.parallel()
创建一个固定大小的线程池,线程池大小和cpu个数相等。
错误处理
onErrorReturn
onErrorReturn在发生错误的时候,会提供一个缺省值,类似于安全取值的问题,但是这个在响应式流里面会更加实用。 这样就可以在处理一些未知元素的时候,又不想让未知因素中止程序的继续运行,就可以采取这种方式。
Flux.just(1,2,0)
.map(v->2/v)
.onErrorReturn(0)
.map(v->v*2)
.subscribe(System.out::println,System.err::println);
onErrorResume
在发生错误的时候,提供一个新的流或者值返回
Flux.just(1,2,0)
//调用redis服务获取数据
.flatMap(id->redisService.getUserByid(id))
//当发生异常的时候,从DB用户服务获取数据
.onErrorResume(v->userService.getUserByCache(id));
onErrorMap
上面的都是我们去提供缺省的方法或值处理错误,但是有的时候,我们需要抛出错误,但是需要将错误包装一下,可读性好一点,也就是抛出自定义异常。
Flux.just(1,2,0)
.flatMap(id->getUserByid(id))
.onErrorMap(v->new CustomizeExcetion("服务器开小差了",v));
doOnError 记录错误日志
在发生错误的时候我们需要记录日志,在reactor里面专门独立出api记录错误日志。 doOnError 对于流里面的元素只读,也就是他不会对流里面的任务元素操作,记录日志后,会将错误信号继续抛到后面,让后面去处理。
Flux.just(1,2,0)
.flatMap(id->getUserByid(id))
.doOnError(e-> Log.error("this occur something error"))
.onErrorMap(v->new CustomizeExcetion("服务器开小差了",v));
finally 确保做一些事情
有的时候我们想要像传统的同步代码那样使用finally去做一些事情,比如关闭http连接,清理资源,那么在reactor中怎么去做finally
Flux.just(1,2,0)
.flatMap(id->getUserByid(id))
.doOnError(e-> Log.error("this occur something error"))
.onErrorMap(v->new CustomizeExcetion("服务器开小差了",v))
.doFinally(System.out.println("我会确保做一些事情"))
;
retry 重试机制
当遇到一些不可控因素导致的程序失败,但是代码逻辑确实是正确的,这个时候需要重试机制。 但是需要注意的是**重试不是从错误的地方开始重试**,相当于对publisher 的重订阅,也就是从零开始重新执行一遍,所以无法达到类似于断点续传的功能,所以使用场景还是有限制。
背压(流量控制)
通过 Reactor提供的BaseSubscriber来进行自定义我们自己流量控制的subscriber
Flux.just(1,2)
.doOnRequest(s->System.out.println("no. "+s))
.subscribe(new BaseSubscriber<Integer>() {
@Override
protected void hookOnSubscribe(Subscription subscription) {
System.out.println("订阅开始了,我要请求几个元素");
request(1);
}
@Override
protected void hookOnNext(Integer value) {
System.out.println("收到一个元素,下一次请求几个元素");
request(1);
}
});