如题,实现文本字数统计,文本在D盘,名称是testfileA.txt
文本内容如下:
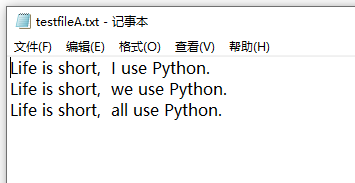
话不多说,上程序:
from pyspark import SparkContext
sc = SparkContext("local", "wordcount")
text_file = sc.textFile("D:/Python_Path/testfileA.txt")
## \表示换行连接。(word, 1)中只能为1,是2的话表示出现个数的2倍,3的话表示三倍。
wordcount = text_file.flatMap(lambda line : line.split(" "))\
.map(lambda word: (word, 1))\
.reduceByKey(lambda a, b : a+b)
wordcount.foreach(print) #依次打印统计次数
运行结果如下:
