数据库
创建数据库Create database db_library;
查看数据库show databases;
选择数据库ues db_library;
删除数据库drop database db_library;
注:除了use不用写database之外,其他都要写database
数据表
使用数据库 use db1_library;
在数据库中创建数据表 create table t_reader(
read_id char(6),
read_name varchar(50),
read_sex char(2));
查看数据表的结构describe t_reader; (desc reader;)
复制表格:create table t_book2 like t_book1
查看当前数据库的全部数据表show tables;
删除数据表:drop table t_book;
注:查看数据表desc,不用写table
数据表中字段的操作
改表的名字:
alter table t_book1 rename t_book;
在一个表中增加一个字段:
alter table t_book add book_copy int;
删除表中的一个字段:
alter table t_book drop borrow_data;
改t_name表中一个字段reader_borrowtota的类型:
alter table t_name modify reader_borrowtotal int;
(modify是稍作修改的意思,就改个类型就好了,改类型直接改就好了)
改t_press表中字段的名称website改为press_website varchar(50):
alter table t_press change website press_website varchar(50);
(换字段名,原来在前,后来的在后面)
数据表约束
将数据表t_reader1中的字段reader_sex改为非空:
alter table t_reader1 modify reader_sex char(2) not null;
将数据表t_reader1中的字段reader_sex的默认值改为0:
alter table t_reader1 modify reader_sex char(2) default 0;
将数据表table t_reader2中的reader_id字段设置为非空而且自增,这个字段就是主键了
create table t_reader2(
reader_id int unique auto_increment,
reader_name varchar(50),
reader_sex char(2));
将t_reader2的字段reader_name设置为外键,参考t_reader1的reader_id,reader_name2是外键名
alter table t_reader2 add constraint reader_name2 foreign key(reader_name)references t_reader1(reader_id);

插入数据
插入一条语句到reader表格:
insert into reader (id,name) values(‘1’,‘张三’);
插入多条语句到teacher表
mysql> insert into teacher values
-> (‘7’,‘李八’,‘24’),
-> (‘8’,‘张九’,‘25’),
-> (‘9’,‘李十’,‘26’);
注:没有最大的括号,最后一个括号是分号来的
创新一个表tbook1与tbook结构一致,而且向表t book1插入t book所有的记录
create table t_bookl like t_book;
insert into t_bookl select * from t_book;
修改数据
更新t_book表,将book_name="云计算应用技术”的人名字改为"张明”
update t_book set book_author="张明”where book_name="云计算应用技术”;
更新t_book表,让press_id="101"的book_copy值加10
update t_book set book_copy=book_copy+10 where press_id=“101”;
删数据
从t_book表中删除id=”106”的行(记录)
delete from t_book where press_id=“106”;
查询数据
查询表格的全部字段:select * from reader;
查询表格的指定字段(投影):select id,name from reader;
Distince去掉查询结果的重复行(选择):select distinct id from reader;
查找结果且让字段显示为中文“还书日期”:select id as 还书日期 from reader;
条件查询
查询在指定氛围用between and 不在某个范围用not between and
select name from reader where id between 1 and 1;
查询空值用is null ,不是空值用is not null(当不往表中赋值的时候,就是null,如果赋值null的话就不是真正的空)
select * from reader where name is null;
从第几行开始,显示多少行
select * from reader where name is null limit 1,2;(从符合条件的表格的第二行开始,显示两行)
查询在某个集合内用in,不在用not in
select name from reader where id in (1,2);
模糊查询用like
select * from reader where name like “%王%”;
求全部人的年例的平均值(查表中的那一列的数值的平均值)
select avg(age) form book1;
group by条件(男的分为一行,女的分为一行),having要搭配group by使用,having是分组的限制条件(年龄是21岁的显示出来),分男女组后又限制年龄大于二十一的才显示
order by升序降序,默认升序,1表示第一个字段升序或者降序,desc降序,asc升序
分别求出男生和女生的平均年例,并且大于3的才显示出来,最后还是降序的
mysql> select avg(id) as 平均年龄,sex 平均年龄对应id,sex对应group by的sex
-> from reader
-> group by sex 年龄作为分组,null是没有写的
-> having avg(id)>3 对分组的进一步限制,平均值大于三的才显示出来
-> order by 1 desc; 第一个字段就是平均年龄,进行降序显示
注:用avg和group by一般用来求一个人的全部科目成绩

自连接
表与自身进行笛卡儿积,可以用来查询一个表中最少两次:借阅了同一本书两次的id有哪个
mysql> select *
-> from book1 a,book1 b 一个表分为两个,而且起名字为a和b
-> where a.id=b.id; 符合条件的显示
或者用inner join on 还有where来写语句
mysql> select *
-> from book1 a inner join book1 b //inner join自连接的意思
-> on a.id=b.id //on是用来配合inner jion的,符合条件的显示
-> where a.id<‘10’; //where又是一个筛选条件
In子查询
SELECT * FROM t_borrow_record //从这个表格里面查询这个信息
NHERE reader_id IN //条件是:id要符合这个条件,女读者
(SELECT reader_id FROM t_reader WHERE reader_sex=女’); 从另一个表中查询出id
exists查询
mysql> select * from book1
-> where exists(select * from book2 where book1.id=book2.id);
现在要从book1中查询数据,筛选条件是看exists,如果book1.id=book2.id成立,对应exists就成立,就可以显示出来,book1中的id值等于book2的字段就可以显示。
创建索引
普通索引INDEX
唯一索引UNIQUE INDEX
全文索引FULLTEXT INDEX
1#实例1:为已经创建好的表t_reader2的字段名reader_id创建普通升序索引,index_rid是索引名称
CREATE INDEX index_rid ON t_reader2(reader_id ASC);
#实例4:为表t_borrow_record2建立多列索引,字段列borrow_id进行升序排列,borrow_id列相同的情况下按reader_id的升序排列,index_bid1是索引名
CREATE INDEX index_bid1 oN t_borrow_record2(borrow_id DESC,reader_id ASc);
#实例2:创建表t_book2,与t book结构一致(不能复制表结构),在创建表的过程中为ISBN创建一个唯一降序索引
CREATE TABLE t_book2
(ISBN CHAR(17),
book_name VARCHAR(50),
book_author VARCHAR(50),
UNIQUE INDEX index_isbn(ISBN DESC)
);
使用SQ1语句查看表中的所有索引
SHOW INDEX FROM t_reader2;
#实例3:为表t_press2的字段列press_name创建全文索引,index_namel是索引名
ALTER TABLE t_press2 ADD FULLTEXT INDEX index_namel(press_name);
视图
创建视图
创建90后读者信息的视图view_after90参照创建视图语法
CREATE VIEW view_after90
AS
SELECT * FROM t_reader WHERE reader_birthday between"1990-1-1"and"1999-12-31";(select后面是视图的规则)
删除视图view_after90
参照删除视圈语法
DROP VIEW IF EXISTS iew_after90;
修改视图view after90,改为包含80后读者信息参照修改视图语法
ALTER VIEW view_after90
AS
SELECT * FROM t_reader WHERE reader_birthday between"1980-1-1"and"1989-12-31";
查看视图是否创建成功:
desc view_after90;
视图名不需要用引号包裹,查询结果显示视图名、字符信息等
SHOW CREATE VIEW view_name;
用户变量
用户变量:先定义才能使用,包括会话用户变量定义和局部变量
系统变量:可以直接使用
设置i为12
set @i=12;
多值设置
set @t1=0,@t2=0,@t3=0;
或者直接分配
select @t1:=(@t2:=1)+@t3:=4,@t1,@t2,@t3;
结果为
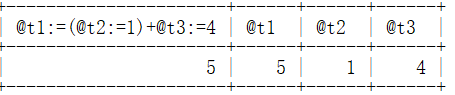
程序结构
顺序,分支,循环
存储过程
存储过程:相当于调用函数,相当于自定义库包,调用这个存储过程就可以实现特定的功能
创建一个存储过程,查询所有读者的基本信息。
DELIMITER //
CREATE PROCEDURE p1()
COMMENT‘查询所有读者的信息’ //这个是备注来的
BEGIN
SELECT*
FROM t_reader
END//
DELIMITER;
查看存储过程状态信息
SHOW PROCEDURE STATUS LIKE ‘procedure_name’
end//
引号里写上查看存储过程的名字
查看存储过程定义信息
SHOW CREATE PROCEDURE procedure_name;
end//
修改存储过程
ALTER PROCEDURE procedure name [characteristic………]
end//
: 注意:这个语法用于修改存储过程的某些特征,比如读写权限。如要修改存储过程的内容,可以先删除该存储过程,再重新创建。
删除存储过程的格式
DROP PROCEDURE procedure_ name;
end//
存储过程的参数
输入参数:IN表示调用者向过程传入值(传入值可以是常量或变量)
输出参数:OUT表示过程向调用者传出值(可以返回多个值,传出值只能是变量)
输入输出参数:INOUT表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量)
输入参数
mysql> delimiter //
mysql> create procedure p_in(in pid char(6)) //存储过程名p_in,参数名pid
-> begin
-> select * from book1
-> where id=pid;
-> end//
调用存储过程:call p_in(‘10’);
输出参数
创建一个带输出参数的存储过程,查询图书的最高价格,最低价格和平均价格。
mysql> create procedure p_out1 //存储过程
-> (out para_min float,out para_max float,out para_avg float) 三个输出参数
-> begin //下面是查询部分
-> select min(id),max(id),avg(id)
-> into para_min,para_max,para_avg from book1; //将最低的价格放到para_min中,将最高的价格放到para_min中,将平均价格放到para_min中
-> end//
调用:
mysql> call p_out1(@para_min,@para_max,@para_avg);
-> end//
查询结果:
mysql> select @para_min,@para_max,@para_avg;
-> end//
输入输出参数
创建一个带输入输出参数的存储过程,对某本书的价格增加10元。
mysql> create procedure P_inout(inout price float)
-> begin
-> set price=price+10;
-> end//
mysql> set @currentprice=5.5; //先设输入值
-> call p_inout(@currentprice); //然后调用
-> select(@currentprice); //查询结果
-> end//
循环条件实例
1.创建一个存储过程,计算100以内的所有整数之和。
mysql> create procedure p3(out total int) 存储过程名称P3,out表示输出参数total变量
-> begin
-> declare num int default 0; //1.定义一个局部变量num初始化为零
-> set total=0; //2.把存储过程的输出参数total的初始值设为0
-> while num<=100 do //3.用while循环来进行控制,循环条件是num<100
-> set num=num+1; //1)让num自增+1
-> set total=total+num; 2)让total累加num进行求和
-> end while;
-> end//
mysql> call p3(@sum); //调用存储过程
-> select @sum; //查询
-> end//
IF分支条件
输入一个数值,判断是属于什么类型的
mysql> create procedure p4 (in score int)
-> begin
-> if score >= 90 and score <= 100 then select ‘A’;
-> elseif score >= 80 and score <= 90 then select ‘B’;
-> elseif score >= 60 and score <= 80 then select ‘C’;
-> else select ‘D’;
-> end if;
-> end //
查询90是属于什么类型的:call p4(@90);
CASE分支条件
创建一个存储过程,判断书的价格。
mysql> create procedure pro_price
-> (in b_name varchar(50),out price float,out result varchar(10))
-> begin
-> select id into price
-> from book1
-> where name=b_name;//1.根据b name查询这本图书的价格,并把价格赋值给price这个变量
//2.判断price的取值范围
-> case
-> when price>=5 then set result=‘昂贵’;//用set对result过值为“昂贵”
-> end case;
-> end//
@price,@b这两个变量来接收两个输出参数的值
mysql> call pro_price(‘田七’,@price,@b);
-> select @price,@b;
-> end//
函数
创建一个函数,功能是根据的ID查找该ID对应的名字。
mysql> create function fun_name2(bookid int) // fun_name2是函数名,bookid是输入参数
-> returns char(10) //本函数的返回值的类型为char
-> begin
-> return (select name from book1 where id=bookid); // |return(select查询语句) //在book1表中,根据ib等于参数bookid的值时查找该id对应的名字
-> end//
//通过select语句来调用下,调用存储过程,查看一下该函数的运行结果
mysql> select fun_name2(‘9’);
-> end//
触发器
删除或更新表格时会触发一些代码
触发器的特点及作用特点
具有原子性,即所有的SQL语句作为一个整体,要么全部执行,要么全部不执行。
触发器的工作原理
在insert类型的触发器当中,用NEW来临时存储插入的新数据。
在delete类型的触发器中,用OLD来临时存储被删除的原数据。
在update触发器中:用OLD表来保存修改之前的原数据,用NEW表保存修改之后的新数据。
创建插入触发器实例1
每向book1中插入一条记录后,则向t_log表中插入该表的表名book1和插入的时间。
mysql> create table t_log( //1首先用create table令来创建日志表t_log
-> log1 int auto_increment primary key, //(1)自增的int类型的log1
-> t_name varchar(20), //(2)tname字符串20个长度,用来记录表的名字
-> log_time datetime); //(3)datetime类型的logtime,用来记录日志时间
-> end//
创建该触发器
mysql> create trigger trigger_log
-> after insert on book1 for each row
-> insert into t_log(t_name,log_time) values(‘t_book’,now());
-> end//
(1)after指的是插入后触发该触发器
(2)作用的表为book1,
(3)对于book1表中任意插入一条记录时将触发该触发器。功能:每次插入时,都向日志表中插入日志数据,t_name列的取值为固定的字符串“t_book"。log_time为插入的日志的时间,这个时间就是系统当前时间
测试教据,检验触发器的效果
-向表_book1中插入数据
insert into book1(id,name) values(16,‘数据库’);
查看日志表的数据
mysql> select * from t_log;
查询日志
开启“查询日志":
SET GLOBAL general_log=ON;
关闭“查询日志”:
SET GLOBAL general log =OFF;