缓存引发的问题
缓存穿透
缓存穿透:指访问不存在的key,依然被大量用户访问
指大量请求访问缓存中不存在的值,从而大量请求打进DB中,导致DB故障。
缓存击穿
缓存击穿:一个缓存key失效后,依然被大量用户访问
指热点数据缓存过期的一瞬间,大量请求打进DB中,导致DB故障。
缓存雪崩
缓存雪崩:多个缓存key失效,依然被大量用户访问
指大面积的缓存集体失效,导致用户要向数据库发送请求,而引发的故障。
解决方案
- 接口层增加校验,如用户鉴权校验(参数校验)
- 从缓存区不到的数据,数据库也取不到的数据可以设置为null
- 超时时间设置得比较随机,这样可以一定程度上避免雪崩的出现
布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不会存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力缓存预热提交把热点key存入缓存中
布隆过滤器
存入缓存的值经过多次哈希函数算出哈希code然后存放到一个数组中,该数组只存放0和1,因此我们可以通过位运算可以快速知道某个缓存是否在redis中。
运用布隆过滤器可以过滤掉redis中不存在的缓存key,但是无法确定某个值是否一定存在里面。
结论:布隆过滤器中不存在的值,现实中一定不存在布隆过滤器中存在的值,现实中未必存在
布隆过滤器的应用场景不止于此,比如:
- 原本有10亿个号码,现在又来了10万个号码,要快速准确判断这10万个号码是否在10亿个号码库中
- 垃圾邮箱的过滤
- 爬虫URL过滤
等等类似这种大数据量集合,快速准确的判断某个数据是否在集合中,并且不占内存,这就是布隆过滤器的应用场景
缓存预热
提前把热点数据塞入redis
因为我们不知道,所以我们要采用 加锁的那一套保护方案
开发逻辑上也要规避差集,会造成击穿,穿透,雪崩
具体操作:
- 日常例行统计数据访问记录,统计访问频度较高的热点数据
- 利用LRU数据删除策略,构建数据留存队列
Redis实现分布式锁
客户端的请求首先会去redis请求锁,此时只能有一个线程能拿到锁,其他线程做一个cas的自旋。这个拿到锁的线程才可以去mysql把数据带回redis然后释放锁。其他的client兄弟就能在redis中找到数据。当
双写不一致
当我们向数据库进行更新操作的时候,同时也要希望更新缓存中的顺序。这是两个动作,不具有原子性,那么到底是谁先谁后呢?因此我们有了以下四个方案
- 先更新数据库 ,在写缓存 (不可取)
- 先写缓存, 再更新数据库(不可取)
- 先删除缓存,再更新数据库(不可取)
- 先更新数据库,再删除缓存(可取,但是有瑕疵)
先更新数据库 ,在写缓存
线程A要去数据库执行一个删除库存的操作,但还未更新缓存。但此时线程B来查缓存,发现还有缓存,进行下单,其实数据库已经没缓存了,因此方案不行
先写缓存,再更新数据库
一开始缓存中没有数据,线程A去数据库写数据,但还没写成。此时线程B到缓存中查数据,缓存中的是新数据,但是数据库还没更新,数据库的是老数据,那么线程B会拿数据库的老数据进行操作。
先删除缓存,再更新数据库
线程A删除缓存,然后去更新数据库。此时线程B来了,B发现缓存中没东西,然后跑去数据库拿,并且B比A更快拿到数据,但是这个数据还是老数据,因为A还没未数据进行一个写入。
先更新数据库,再删除缓存
线程B去查数据库的数据,此时线程A执行更新数据库,并且删除了缓存。那么线程B会按之前查到的老数据的数据并且存入缓存中,这个存放在缓存中的数据是老的数据,
解决办法:
延迟双删除: 线程A在第一次删除完了之后,进行一个sleep,然后再删除一次。就能避免上面的问题。但是这也会引入另外一个问题,这个sleep的值该设为多少不好把握。在此背景下,Canal横空出世!
Canal
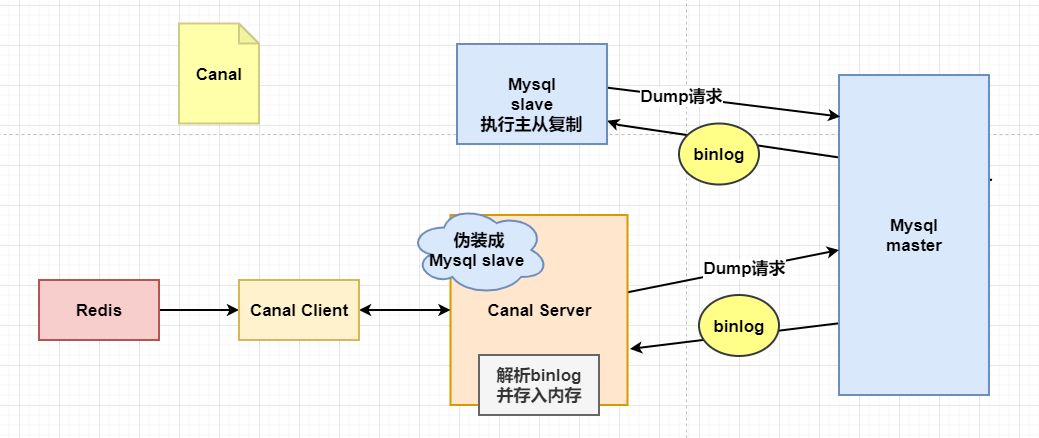
主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
Canal 伪装成mysql的一个从机slave,然后向Mysql master,发送dump请求,去获得binlog。等到master返回binlog之后,会把binlog中的数据,解析到内存,不进行持久化,提供给客户进行查询。