爬虫入门练习项目
本人是大三学生,分享一些学习心得,如果有错误,请大佬指导
这里我们爬取的某网排行榜,xpath比较简单,且爬取的条目比较少,适合新生练习
- 项目分析
首先我们要选取目标网站,网站图片放不出来
网址 “http://xinhuanet.com/politicspro/”
打开网址,可以看到排行榜在网页左侧,有三条数据需要爬取,分别是排名,新闻题目,链接
题目以及链接
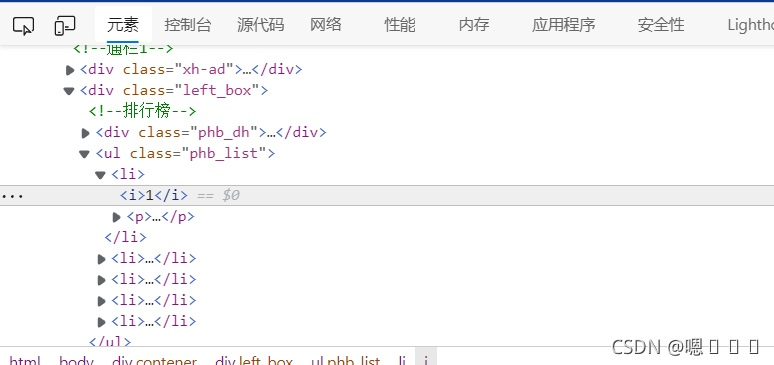

接着我们就可以将xpath写出来了
#准备爬取的内容所在地址
//ul[@class="phb_list"]/li
#排名
i/text()
#题目
p/a/text()
#链接
p/a/@href
- 完整代码
# -*- coding: utf-8 -*-
"""
Created on Tue Nov 2 08:23:49 2021
@author: 继续革命
"""
import requests
from lxml import etree
import csv
xinhuaUrl='http://www.xinhuanet.com/politicspro/'
#获取网页源码
def getSource(url):
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40'
}
response=requests.get(url,headers=headers)
#防止出现乱码
response.encoding='utf-8'
return response.text
#排行榜
#标题,链接
def getEveryItem(source):
#生成一个Html对象
selector=etree.HTML(source)
#通过selector对象来找到新闻信息
newItemList=selector.xpath('//ul[@class="phb_list"]/li')
#定义空列表
newList=[]
#遍历
for eachNew in newItemList:
newDict={}
ranking=eachNew.xpath('i/text()')#排名
title=eachNew.xpath('p/a/text()')#题目
link=eachNew.xpath('p/a/@href')#链接
newDict['ranking']=ranking
newDict['title']=title
newDict['url']=link
print(newDict)
newList.append(newDict)
return newList
def writeData(newList):
#写入数据
with open('xinhua.csv','w',encoding='utf-8',newline='')as f:
write=csv.DictWriter(f, fieldnames=['ranking','title','url'])
write.writeheader()
for each in newList:
write.writerow(each)
if __name__ == "__main__":
source = getSource(xinhuaUrl)
newList=[]
newList += getEveryItem(source)
writeData(newList)
运行,得到结果
码字不易,求支持