1. Machine Learning概述
1.1 什么是ML
Machine Learning ≈ Looking for Function
两大类任务(回归与分类)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jU2aje4e-1635772845343)(C:\Users\admin\AppData\Roaming\Typora\typora-user-images\image-20211101124751493.png)]](https://img-blog.csdnimg.cn/e4be51ffe4a14dabb5d58f4cde1066f2.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4twZhOtZ-1635772974787)(C:\Users\admin\AppData\Roaming\Typora\typora-user-images\image-20211101124832223.png)]](https://img-blog.csdnimg.cn/02f7c6c018934eb59f818944cb89a77f.png)
1.2 Framework of ML


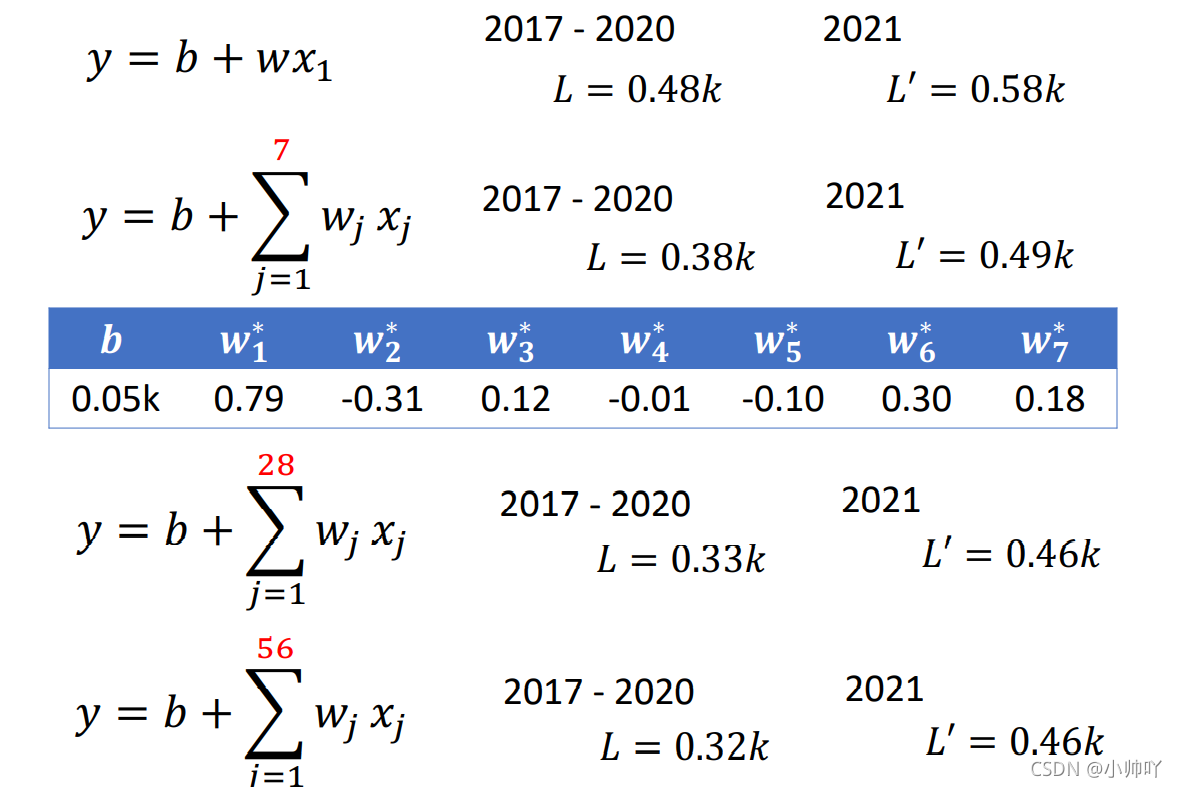
2. 基本步骤(基础版:线性模型)

2.1 function with unknown

2.2 Define Loss from Training Data



2.3 optimization




2.4 summary

接下来看一下根据我们学习出来的w与b进行预测的结果与真实结果的对比

是否在图中发现什么规律?
3. 基础步骤(进阶版:非线性模型)
3.1 引入
线性模型有严重的model bias的问题

我们希望用一个常数加上一系列蓝色的set造出来红色曲线

这个蓝色的set是什么呢?

由此便由一个常数和一组sigmoid函数构造出一个非线性的红色曲线

我们对比一个线性与非线性模型

具体看一下这个非线性曲线的真实构造



3.2 function with unknown

3.3 Define Loss from Training Data

3.4 optimization


我们进行实际操作时模型的参数是如何更新的呢?

举例说明一下:

为什么要设置batch size呢?
梯度下降的每一轮迭代下,要计算所有数据的损失函数值,然后计算每个参数的偏导数,来求出目前的梯度方向。
但是在计算损失函数的过程中,需要把每个数据点都计算出来,有的时候,数据可能有几百万甚至更多,这个时候可能迭代速度就会明显下降下来了。所有这个时候有了一种 mini-batch gradient descent 小批量梯度下降,把数据分成一个一个的batch,然后每计算一个batch,就更新一次梯度,也就是说现在梯度下降中,每次迭代不是计算全部数据的损失函数,而是一个batch的损失函数。这样可以加快训练的速度,还有模型收敛的速度。因为以前要把所有数据都过一遍模型才能得到更新,现在模型的更新更频繁了。
4. 常见问题

4.1 Model bias
4.1.1 什么是Model bias

针对模型偏差:让我们的模型更加复杂比如说增加层数,增加参数个数
4.1.2 如何解决model bias的问题

4.2 optimization
4.2.1 什么是optimization不够好的问题

4.2.2 如何解决optimization不够好的问题
常见Adam算法,Adam 是一种可以替代传统随机梯度下降(SGD)过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重。
4.3 overfitting
4.3.1 什么是overfitting的问题

4.3.2 如何解决overfitting的问题
针对overfitting的办法:1. 增加训练数据 2. 做data augmentation
- Less parameters 4. less features 5. regularization 6. dropout
4.4 寻找一个平衡

Model Bias的问题是因为模型太简单,而overfitting的问题是因为模型太复杂,我们需要找一个平衡点平衡两者
5. 实例演示
蚂蚁蜜蜂识别
https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html
6. 相关资料
https://tangshusen.me/Dive-into-DL-PyTorch/#/ 动手学深度学习
https://pytorch.org/tutorials/ pytorch官方教程
https://www.kaggle.com/ 比赛学习网站
https://pytorch.org/tutorials/beginner/deep_learning_60min_blitz.html 使用 pytorch进行深度学习:60 分钟闪电战
https://www.bilibili.com/video/BV1Wv411h7kN?p=2 B站李宏毅机器学习课程
李宏毅机器学习PPT百度网盘链接:https://pan.baidu.com/s/1VQ_vHoD9Z4yqfUtGy5uccA
提取码:hi0p
https://drive.google.com/ 谷歌colab平台