Redis 数据类型 - list
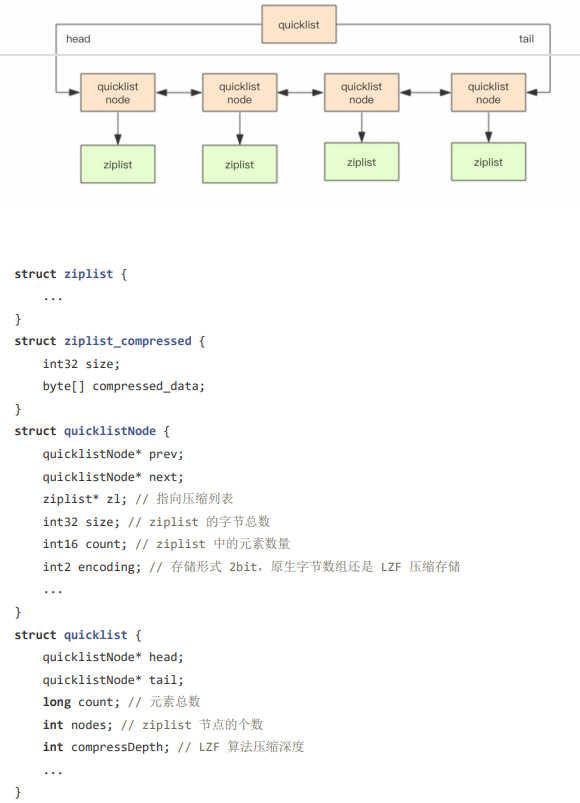
list 中文翻译为:列表,目前 6.2 的版本中,数据结构为 quicklist, 但是逻辑结构其实是 linkedlist + ziplist 的混合体,它将linkedlist 按段切分,每一段使用 ziplist 来紧凑存储,多个 ziplist 之间使用双向指针串接起来。其中每个节点的数据结构如下,根据单个节点结构 quicklistNode 可以看出,通过 prev, next 指针组成双向链表,其中 head,tail 节点值为 null。
2.1 ziplist
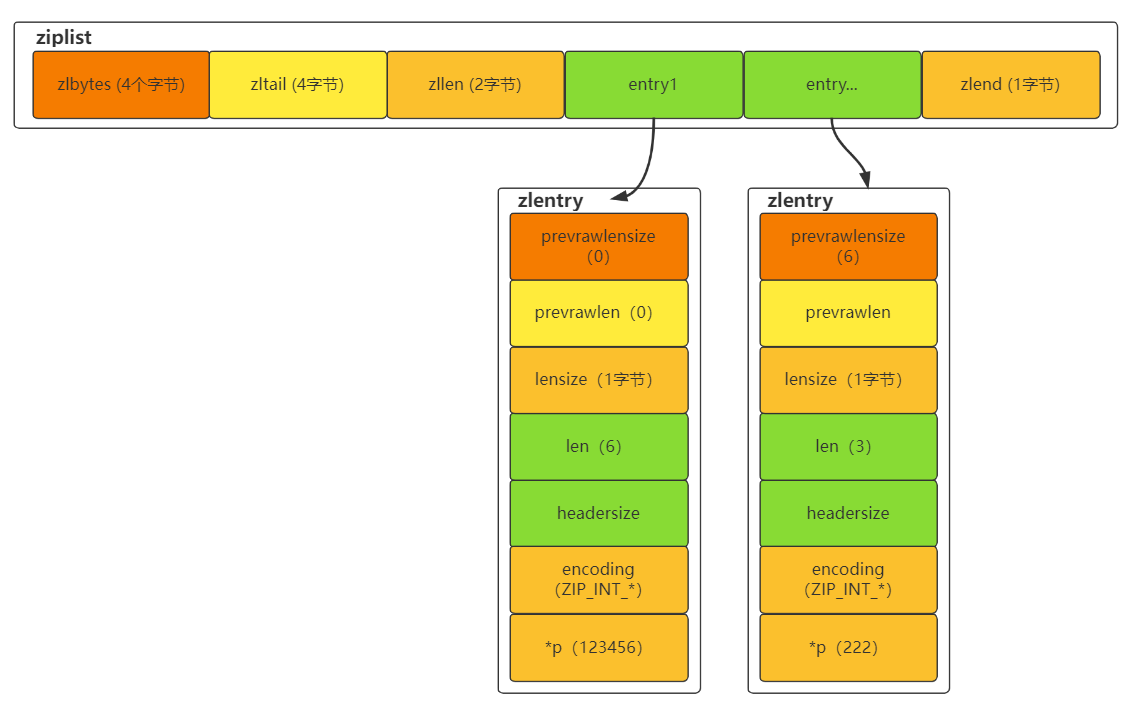
ziplist 压缩列表,顾名思义,可以它具有很高的内存效率,节省空间,只存储整数值和字符串,通过利用时间换空间的概念,达到节省空间,结构如下,分别时 ziplist 和 zlentry。

- zlbytes:32bit无符号整数,表示ziplist占用的字节总数(包括本身占用的4个字节);
- zltail:32bit无符号整数,记录最后一个entry的偏移量,方便快速定位到最后一个entry;
- zllen:16bit无符号整数,记录entry的个数;
- entry:存储的若干个元素,可以为字节数组或者整数;
- zlend:ziplist最后一个字节,是一个结束的标记位,值固定为255。
// 创建空的压缩链表函数,没有定义实际的ziplist 结构
unsigned char *ziplistNew(void) {
// ZIPLIST_HEADER_SIZE:zlbytes + zltail + zllen = 10个字节
// ZIPLIST_END_SIZE:zlend,1个字节
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
// 申请内存(11个字节)
unsigned char *zl = zmalloc(bytes);
// zlbytes赋值
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
// zltail赋值
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
// zllen赋值
ZIPLIST_LENGTH(zl) = 0;
// zlend赋值
zl[bytes-1] = ZIP_END;
return zl;
}
zlentry 为 ziplist 中的 entry节点,ziplist中的每个 entry 均包含两个信息:prevrawlen 和 encoding。prevrawlen 字段:存储前一个entry的长度,以便能够从后到前遍历列表。encoding表示entry类型,整数或字符串,对于字符串,还表示字符串有效负载的长度。 因此,完整的entry存储形式如下:
// ziplist 的 entry 节点
typedef struct zlentry {
// 用于编码前一个 entry 大小的字节数
unsigned int prevrawlensize;
// 前一个 entry 的大小
unsigned int prevrawlen;
// 用于编码当前 entry 大小的字节数
unsigned int lensize;
// 当前 entry 的实际大小
unsigned int len;
// prevrawlensize + lensize.
unsigned int headersize;
// 判断存储的数据是字符串(字节数组)还是整型
unsigned char encoding;
// 节点value值
unsigned char *p;
} zlentry;
zlentry 存储了上一个 entry 的大小,那么就可以根据ziplist 的特点,从后也可以进行遍历,但是当 ziplist 添加或者删除元素时,最坏情况下会执行N次空间重分配,因为每个 entry 都具有前一个 entry 的信息,而每次空间分配的最坏复杂度为O(N),所以连锁更新的最坏复杂度为 O(N*N)
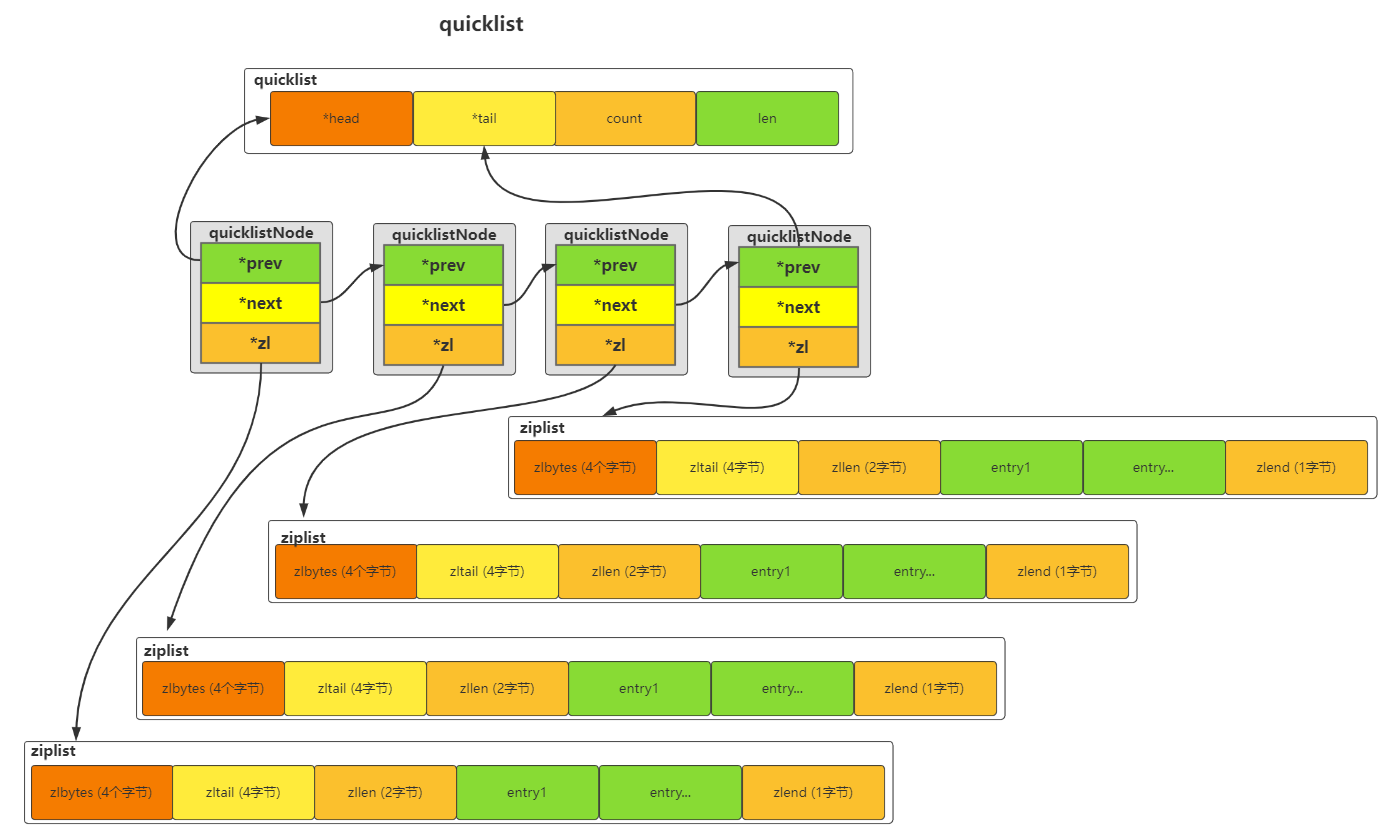
2.2 quicklist
quicklist 是一个双向链表,并且是一个 ziplist 的双向链表,也就是说 quicklist 的每个节点都是一个 ziplist。结合了 linkedlist 和 ziplist 的优点,
// quicklist 压缩结构
typedef struct quicklistLZF {
unsigned int sz; /* LZF size in bytes*/
char compressed[];
} quicklistLZF;
// quicklist 节点结构
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;//数据指针。如果当前节点的数据没有压缩,那么它指向一个ziplist结构;否则,它指向一个quicklistLZF 结构。
unsigned int sz; // zipList 大小
unsigned int count : 16; // ziplist 的元素数量
unsigned int encoding : 2; //原生字节数组==1 还是 LZF 压缩的==2
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
// quicklist 结构
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; // 所有元素总数
unsigned long len; // quicklistNode 节点总数
int fill : QL_FILL_BITS; // 为单个节点填充因子
unsigned int compress : QL_COMP_BITS; // LZF 算法压缩深度;0=off
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
适用场景列表键、发布订阅、慢查询、监视器等。
为了进一步节约空间,redis 还会对 ziplist 进行压缩存储,使用 LZF 算法压缩,可以选择压缩深度。
2.3 为什么使用 quicklist?
- redis 原来使用linkedlist 和 ziplist 作为 list 对象的底层数据结构,根据 key 的键大小或者 list 中的元素总数进行切换。当键不是很大时,或者 list 中元素不多时,使用 ziplist,通过时间换空间的思路去减少内存空间占用,因为此时 list 中的元素也不多,时间消耗几乎很少。
- 当 list 中元素增多时,无论是增加或者是减少元素,那么都会对ziplist 造成O(N*N)的复杂度,造成时间消耗增多,降低了性能 。
- linkedlist 双向链表方便从头、尾节点进行操作,但是内存消耗大。每个节点要多额外保存两个指针:prev、next。当数据量大时,ziplist 需要连续的空间,但是 linkedlist 则不需要。这也就是以前版本当元素过多时,会转换尾 linkedlist。
- 为了综合上述的优缺点,quicklist 使得空间效率和时间效率的折中,即存在双端队列,又分散了 ziplist。