目录
1.基本知识:
1.Redis有16个数据库,默认使用的是第0个数据库。

2.Redis是单线程的
-
原因:因为Redis是很快的,而且是基于内存的。所以CPU,多核不是Redis的性能瓶颈,Redis的性能瓶颈收到机器的内存和网络带宽限制。所以既然不受CPU,多核限制,那么干嘛不用单线程呢?
-
为什么单线程那么快:
误区1:高性能的服务器一定是多线程的。(不一定)
误区2:多线程一定比单线程效率高。(不一定:因为多线程往往涉及到CPU上下文的切换,这也是很耗时的操作。)
那么Redis将所有数据都存放在内存中,用单个CPU的一块内存的数据,那么就不会差生CPU的上下文切换的消耗,所以对于内存系统来说,没有上下文切换效率就是最高。所以使用单线程去操作效率就是最高的。
多次读写都是在一个CPU上,在内存的情况下,单线程就是最佳的方案。
3.memcached和redis的区别
- memcached支持的数据类型比较单一;redsi支持多种数据类型
- memcached只能在内存操作,不支持持久化;redis技能在内存中运行也能支持持久化
- memcached是多线程+锁;Redis是单线程+多路IO复用
1.4.单线程+多路IO复用:能实现多线程的效果
效率更高,能让CPU发挥出更高的效能。
多路复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如调用select和poll函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞知道超时。得到就绪状态后进行真正的操作可以在同一个线程里执行,也可以启动线程执行。

2.一些命令
1.可以用select 进行切换数据库。

2.dbsize:数据库大小

3.查看当前数据库所有的key:keys *

4.清空当前库和清空全部
flushall
flushdb

3.五大基本类型
官网参考命令Redis命令
3.1.Redis-key的基本命令
1.存储一个key-value:set name txl

2.获取key对应的值:get name

3.判断key是否存在:exists name

4.移动一个key-value到指定数据库:move name 1移动name到数据库1

5.设置过期时间:expire age 10设置age10s过期

6.ttl:查看剩余时间

7.type:查看数据类型type name

8.删除key
del key:删除指定的key数据unlink key:根据value选择非阻塞删除。当时仅将key从keyspae元数据中删除,真正的刹车农户会在后续异步操作中执行。
3.2.String类型
1.设置key,获取key
set key1 ttxxllget key1
2.追加字符串
append key1 "666":如果当前key不存在,相当于set一个key
3.查看key长度
strlen key1:
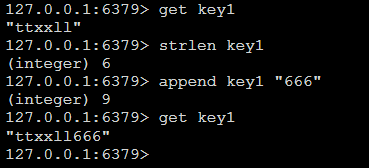
4.自增,自减:
incr keydecr key
127.0.0.1:6379> set views 0 #views初始值0
OK
127.0.0.1:6379> get views
"0"
127.0.0.1:6379> incr views #views自增1
(integer) 1
127.0.0.1:6379> get views
"1"
127.0.0.1:6379> type views
string
127.0.0.1:6379> incr views #views自增1
(integer) 2
127.0.0.1:6379> incr views #views自增1
(integer) 3
127.0.0.1:6379> decr views #views自减1
(integer) 2
127.0.0.1:6379> decr views #views自减1
(integer) 1
5.根据步长变化:
incrby key10decrby views 5127.0.0.1:6379> get views "1" 127.0.0.1:6379> incrby views 10 (integer) 11 127.0.0.1:6379> get views "11" 127.0.0.1:6379> decrby views 5 (integer) 6 127.0.0.1:6379> get views "6"
6.截取字符串的某个范围部分
getrange key start end:getrange key 0 -1:获取整个字符串等价于get key127.0.0.1:6379> set key "hellottxxll" OK 127.0.0.1:6379> get key "hellottxxll" 127.0.0.1:6379> getrange key 0 4 "hello"
7.替换指定位置的字符串
-
setrange key offset value
8.setex和setnx
-
setex key seconds value:新建一个key并同时设置过期时间 -
setnx key value:如果key不存在,创建key;如果存在,不创建。
9.批量设置key和批量获得key
mset k1 v1 k2 v2 k3 v3mget k1 k2 k3127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 OK 127.0.0.1:6379> keys * 1) "k2" 2) "k3" 3) "k1" 127.0.0.1:6379> mget k1 k2 k3 1) "v1" 2) "v2" 3) "v3" 127.0.0.1:6379>
10.msetnx k1 v1 k2 v2...:如果都不存在,才会创建。是一个原子性的操作。

10.对象
- 1.用json创建一个
user:1对象:set user:1 {name:zhangsan, age:3}

-
2.另一种对象设计:
user:{id}:{field}127.0.0.1:6379> mset user:2:name txl user:2:age 10 OK 127.0.0.1:6379> mget user:2:name user:2:age 1) "txl" 2) "10" 127.0.0.1:6379>

11先获取再设置,不存在值返回null,并创建新值。
- .
getset:

12.String类型的使用场景
String类型的value除了是字符串,还可以是数字。
可以用于计数器,来统计一些指标。
3.2.1.String的数据结构
String的数据结构为简单动态字符串。是恶意修改的字符串,内部结构实现上类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。

如上图所示,内部是为当前字符串实际分配的实际空间capacity,它一般要高于实际字符串长度len。当字符串长度小于1M时,扩容都是加倍现有的空间;如果长度超过了1M,扩容一次只会增加1M。
需要注意的是字符串最大长度为512M。
3.3.List类型
在Redis里面,我们可以把List玩成栈、队列、阻塞队列…
所有的List命令都是l开头。
1.从左边push值:
lpush key element [element ...]:lpush name-list txl ttt xxx lll
2.获取值:
lrange key start end:- 获取list中的全部值:
lrange name-list 0 -1
3.注意:lput顺序和取出的顺序是相反的

4.从右边push:push顺序和取出顺序相同
rpush mylist a b c d e f g

5.移除最左边(几个)元素,移除最右边(几个)元素
-
lpop key [count]:移除最左边(几个)元素,参数count默认是1。
-
rpop key [count]:移除最右边(几个)元素,参数count默认是1。
6.获取指定索引位置的元素
lindex key indexlindex mylist -1:-1代表直接获取最后一个元素

7.返回列表的长度
llen key

8.移除指定个数的值
lrem myist count valuelrem mylist 2 a:从左到右移除两个值alrem mylist -1 a:移除最后一个a
9.将list截断:List会改变
ltrim mylist 1 4:按照下标将mylist截断,只保留index=1到index=4的部分。

10.移除当前列表的最右端一个元素,并移动到其他list的最左端
rpoplpush mylist other-list

11.替换list中指定下标的值:相当于更新操作,如果该列表不存在或者索引不存在会报错
lset key index elementlset other-list 0 z

12.在一个集合的指定元素的前或后位置插入一个元素
linsert other-list after z a

linsert other-list before z a

3.3.1.List底层数据结构
1.单键多值:List是简单的字符串列表,按照插入顺序排序,可以从头部或者尾部添加。
2.它的底层实际上是个双向链表,对两端的操作性能很高,通过索引下标操作中间的节点性能会较差。

3.List的数据结构:快速链表quickList
- 首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。
- 当数据量较多时,会将若干个压缩列表ziplist组成一个quicklist。
- 之所以不是把每个元素作为一个节点,而是将若干个元素作为一个ziplist,再将ziplist作为一个链表节点,是为了节省额外指针prev和next的空间占用。
- Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入和删除性能,又不会出现太多的冗余空间。
3.4.Set类型
Set中的值不能重复,相关命令都是s开头。
1.添加元素
sadd myset 1 2 3 4
2.查看set中的所有值
smembers myset

3.判断某个元素是否在set中
sismember myset 2:判断myset中是否有元素2

4.获取set的元素个数
scard myset

5.移除具体的若干个元素
srem myset 1 2:移除myset中的元素1和元素2

6.从set中随机取出若干个元素
srandmember myset 2:从myset中随机取出2个元素

7.随机删除若干个元素
spop myset:随机删除1个元素spop myset 2:随机删除2个元素

8.移除指定的元素到另一个set中
smove myset other 2:将myset中的元素2移动到other中

9.计算数学集合
sdiff myset youset:取myset与youset的myset的差 --> 推荐好友sdiff youset myset:取youset与myset的youset的差集 --> 推荐好友sunion myset youset:取并集sinter myset youset:取交集 --> 共同关注

3.4.1.Set底层数据结构
- Set是Redis提供的一个类似列表的结构,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择。并且set提供了判断某个成员是否在一个set集合的重要接口,这个也是list所不能提供的。
- Redis的set是string类型的无需集合。它底层其实是一个value为null的hash表,所以添加删除,查找的复杂度都是O(1)。
- Set的底层数据结构式dict字典,字典是用哈希表实现的。类似Java中的HashSet,底层也是HashMap,只不过Java中的HashSet的所有Value都指向同一个对象;Redis中的Set的所有Value都指向一个内部值。
3.5.Hash类型
key-map类型,map本身也是key-value。是一个键值对集合。
相关命令时h开头。
1.创建hash并set值
hset key field value field value ...hset myhash name txl age 1 gender m:设置一个名为myhash的hash,其中有字段name,age,gender。
2.取值
hget key fieldhget myhash namehget myhash age

3.获取多个字段的值
-
hmget myhash name age gender id field1 field2
4.获取所有的字段和值
hgetall myhash

5.删除指定的字段
hdel myhash field1 field2

6.获取指定hash的键值对个数
hlen myhash
7.判断字段是否存在
hexists myhash field1

8.只获得所有的key
hkeys myhash

9.只获得所有的values
-
hvals myhash

10.一些其他操作 -
hincrby myhash age 1:为myhash中的age字段增加1 -
hincrby myhash age -1:为myhash中的age字段增加-1 -
hsetnx myhash name tttt:如果不存在name字段,才能成功赋值。
3.5.1.Hash的数据结构
Hash类型对应的数据结构式两种:ziplist压缩列表,Hashtable哈希表。当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable。
3.6.ZSet类型
相比Set,在进行add是,要为每个元素设置一个score属性。
1.添加元素
zadd key socre membrzadd my-zset 1 first 2 second
2.查看zset元素
zrange my-zset 0 1:升序查看
127.0.0.1:6379> zrange my-zset 0 1
1) "first"
2) "second"
127.0.0.1:6379> zrange my-zset 0 -1
1) "first"
2) "second"
zrevrange salary 0 -1 withscores:降序查看

3.指定范围排序:升序
zadd salary 5000 zhangsan 2000 lisi 3000 wanger:新建一个zset:salary,插入3个值zrange salary 0 -1:查看salary中所有元素,默认是按照score升序排列

zrangebyscore salary -inf +inf:将salry中元素按照socre排序,score的范围在(-∞, +∞)

zrangebyscore salary 0 3000:将salry中元素按照socre排序,score的范围在(0, 3000)

zrangebyscore salary -inf +inf withscores:排序的同时,打印结果带上score

4.移除zset中的元素zrem salary lisi:移除zset:salary中的lisi元素

5.查看zset中的元素个数
zcard salary
6.计算指定score范围的元素格式

zcount salary 0 3000:计算score位于0-3000的元素个数

3.6.1.ZSet的数据结构
SortedSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据结构Map<String, Double>,可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部的元素会按照权重score进行排序,可以得到每个元素的名次,还可以通过score的范围来获取元素的列表。
zset底层使用了两个数据结构
- hash,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。
- 跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。
跳跃表:
-
1、简介
有序集合在生活中比较常见,例如根据成绩对学生排名,根据得分对玩家排名等。对于有序集合的底层实现,可以用数组、平衡树、链表等。数组不便元素的插入、删除;平衡树或红黑树虽然效率高但结构复杂;链表查询需要遍历所有效率低。Redis采用的是跳跃表。跳跃表效率堪比红黑树,实现远比红黑树简单。 -
2.图示

实例演示:对比有序链表和跳跃表,从链表中查询出51 -
1有序链表

要查找值为51的元素,需要从第一个元素开始依次查找、比较才能找到。共需要6次比较。
-
2跳跃表

从第2层开始,1节点比51节点小,向后比较。
21节点比51节点小,继续向后比较,后面就是NULL了,所以从21节点向下到第1层。
在第1层,41节点比51节点小,继续向后,61节点比51节点大,所以从41向下。
在第0层,51节点为要查找的节点,节点被找到,共查找4次。
从此可以看出跳跃表比有序链表效率要高。