1.软件版本
ISE14.7
2.本算法理论知识
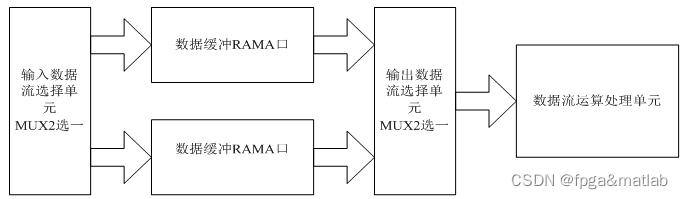
乒乓处理操作的原理如下所示:
乒乓操作的处理流程为:输入数据流通过“输入数据选择单元”将数据流等时分配到两个数据缓冲区,数据缓冲模块可以为任何存储模块,比较常用的存储单元为双口 RAM(DPRAM) 、单口 RAM(SPRAM) 、FIFO等。
在第一个缓冲周期,将输入的数据流缓存到“数据缓冲模块 1”;在第 2 个缓冲周期,通过“输入数据选择单元”的切换,将输入的数据流缓存到“数据缓冲模块 2”,同时将“数据缓冲模块 1”缓存的第 1 个周期数据通过“输入数据选择单元”的选择,送到“数据流运算处理模块”进行运算处理;在第 3 个缓冲周期通过“输入数据选择单元”的再次切换,将输入的数据流缓存到“数据缓冲模块 1”,同时将“数据缓冲模块 2”缓存的第 2 个周期的数据通过“输入数据选择单元”切换,送到“数据流运算处理模块”进行运算处理。如此循环。
乒乓操作的最大特点是通过“输入数据选择单元”和“输出数据选择单元”按节拍、相互配合的切换,将经过缓冲的数据流没有停顿地送到“数据流运算处理模块”进行运算与处理。把乒乓操作模块当做一个整体,站在这个模块的两端看数据,输入数据流和输出数据流都是连续不断的,没有任何停顿,因此非常适合对数据流进行流水线式处理。所以乒乓操作常常应用于流水线式算法,完成数据的无缝缓冲与处理。
假设A 端口处输入数据流速率为100Mbps,在第1个缓冲周期10ms内,通过“输入数据选择单元”,从B1到达 DPRAM1。B1的数据速率也是100Mbps,DPRAM1要在10ms内写入1Mb数据。同理,在第2个10ms,数据流被切换到DPRAM2,端口B2的数据速率也是100Mbps,DPRAM2在第2个10ms被写入1Mb数据。在第3个10ms,数据流又切换到 DPRAM1,DPRAM1被写入1Mb数据。
通过乒乓操作实现低速模块处理高速数据的实质是:通过 DPRAM 这种缓存单元实现了数据流的串并转换,并行用 “ 数据预处理模块 1” 和 “ 数据预处理模块 2” 处理分流的数据,是面积与速度互换原则的体现。
这里,考虑到版本问题,我使用了全verilog进行设计,也就是说,我使用了verilog设计了其中使用的寄存器。实现存储器的功能。
另外,由于数据处理单元是最后的数据处理模块,这个根据实际情况而定,因此,这里我们只设计数据处理模块之前的所有的模块。

整个系统主要包括,输入选择模块,两个RAM模块,输出选择模块,以及最后的控制器模块。

下面简单的对各个模块进行介绍:
tops:即整体的乒乓操作模块;
controller:控制器,即通过产生一个使能信号,控制两个RAM的读写时序。其主要的功能为:
通过产生一个周期性变化的使能信号,使得两个RAM达到如下的功能:
在第一个缓冲周期,将输入的数据流缓存到“数据缓冲模块 1”;在第 2 个缓冲周期,通过“输入数据选择单元”的切换,将输入的数据流缓存到“数据缓冲模块 2”,同时将“数据缓冲模块 1”缓存的第 1 个周期数据通过“输入数据选择单元”的选择,送到“数据流运算处理模块”进行运算处理;在第 3 个缓冲周期通过“输入数据选择单元”的再次切换,将输入的数据流缓存到“数据缓冲模块 1”,同时将“数据缓冲模块 2”缓存的第 2 个周期的数据通过“输入数据选择单元”切换,送到“数据流运算处理模块”进行运算处理。如此循环。
MUXER:输入选择模块
即根据控制器的输出使能信号,产生控制RAM读写的使能。使得实现写入,读取操作交替工作的过程
RAMer:读写存储器。可以将输入的数据进行保存
通过两个RAM同时工作,实现这么一个过程,即当一个RAM在写的时候,另外一个RAM进行读取并开始操作。
MUXER2:输出选择模块
即实现RAM输出模块的交替输出功能。
3.部分源码
`timescale 1ns / 1ps
//
// Company:
// Engineer:
//
// Create Date: 15:13:18 03/13/2014
// Design Name:
// Module Name: tops
// Project Name:
// Target Devices:
// Tool versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//
module tops(
i_clk,
i_rst,
i_din,
o_dout,
//test
o_controller,
o_wr1,
o_wr2,
o_d1,
o_d2,
o_addr,
o_addw
);
input i_clk;
input i_rst;
input[15:0] i_din;
output[15:0]o_dout;
//test
output o_controller;
output o_wr1;
output o_wr2;
output[15:0]o_d1;
output[15:0]o_d2;
output[7:0] o_addr;
output[7:0] o_addw;
controller controller_u(
.i_clk (i_clk),
.i_rst (i_rst),
.o_enable (o_controller)
);
//MUX
muxer muxer_u(
.i_clk (i_clk),
.i_rst (i_rst),
.i_en (o_controller),
.o_wr1 (o_wr1),
.o_wr2 (o_wr2)
);
//RAM1
RAMer RAMer_u1(
.i_clk (i_clk),
.i_rst (i_rst),
.i_wr (o_wr1),
.i_din (i_din),
.o_dout(o_d1),
.o_addr(o_addr),
.o_addw(o_addw)
);
//RAM2
RAMer RAMer_u2(
.i_clk (i_clk),
.i_rst (i_rst),
.i_wr (o_wr2),
.i_din (i_din),
.o_dout(o_d2),
.o_addr(),
.o_addw()
);
//MUX
muxer2 muxer2_u(
.i_clk (i_clk),
.i_rst (i_rst),
.i_en (o_controller),
.i_d1 (o_d1),
.i_d2 (o_d2),
.o_d (o_dout)
);
//DATA PROCESS
//this module can be done by your own module
endmodule
4.仿真分析

A02-45