NVIDIA云原生技术:耐心看完受益匪浅
第一篇-》NVIDIA云原生技术
NVIDIA云原生技术使开发人员能够使用Docker和Kubernetes构建和运行GPU加速的容器。
【1】NVIDIA容器工具包
概观
NVIDIA容器工具包允许用户构建和运行GPU加速的容器。该工具包包括一个容器运行时图书馆和实用程序来自动配置容器以利用NVIDIAGPUs。
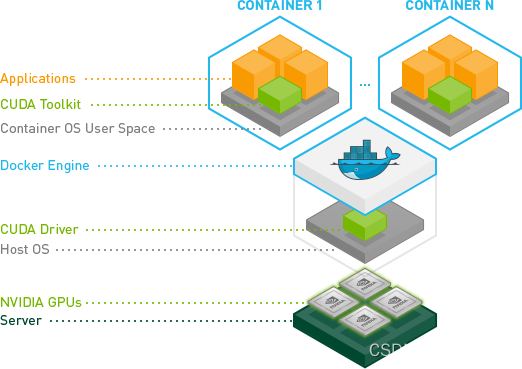
NVIDIA容器工具包支持生态系统中的不同容器引擎-[码头工人], [LXC], [波德曼]等等。跟随[用户指南]用这些引擎运行GPU容器。
体系结构
这[架构概述]描述了
NVIDIA容器工具包的技术架构和软件的封装。
安装指南
这[安装指南]展示了如何在不同的
Linux发行版和平台上安装NVIDIA容器工具包。
故障排除指南
[解决纷争]列出
NVIDIA Container Toolkit的一些已知问题以及一般故障排除步骤。
【2】GPU操作员
概观
Kubernetes通过提供对特殊硬件资源的访问,如NVIDIA GPUs、NIC、Infiniband适配器和其他设备[设备插件框架]。然而,配置和管理具有这些硬件资源的节点需要配置多个软件组件,例如驱动程序、容器运行时或其他库,这很困难并且容易出错。NVIDIA GPU操作员使用[运营商框架]在Kubernetes中自动管理配置GPU所需的所有NVIDIA软件组件。这些组件包括NVIDIA驱动程序(支持CUDA)、用于GPU的Kubernetes设备插件[NVIDIA容器工具包],自动节点标记使用无谷蛋白膳食,德中会展经济协会基于监控和其他。
【3】带GPU的Kubernetes
【3.1】安装Kubernetes
介绍
Kubernetes是一个用于自动化部署、扩展和管理容器化应用程序的开源平台。Kubernetes包括对GPU的支持和对Kubernetes的增强,因此用户可以轻松配置和使用GPU资源来加速AI和HPC工作负载。
有很多方法可以安装NVIDIA支持组件的上游Kubernetes,如
驱动程序、插件和运行时。
开始操作:
选项1:使用[深度操作]
选项2:使用[Kubeadm安装]Kubernetes
选项2-a:使用[英伟达GPU]运营商自动化/管理NVIDIA软件组件的部署
选项2-b:将NVIDIA软件组件设置为[先决条件]运行应用程序之前
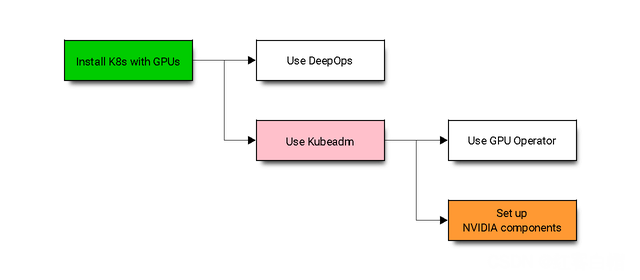
选项1:使用DeepOps安装Kubernetes
使用
DeepOps来自动化部署,尤其是对于包含许多工作节点的集群。DeepOps是一个ansible脚本的模块化集合,它可以在您的节点上自动部署Kubernetes、Slurm或两者的混合。它还会安装必要的GPU驱动程序、用于Docker的NVIDIA容器工具包(nvidia-docker2),以及GPU加速工作的各种其他依赖项。它封装了NVIDIA GPUs的最佳实践,可以根据需要定制或作为单独的组件运行。
1.使用以下步骤通过DeepOps安装Kubernetes:
选择要部署的预配节点。这是运行
DeepOps Ansible脚本的地方,通常是一台连接到目标集群的开发笔记本电脑。在此供应节点上,使用以下命令克隆DeepOps存储库:
git clone https://github.com/NVIDIA/deepops.git
2.或者,使用以下命令签出最近发布的标签:
cd deepops \
&& git checkout tags/20.10
如果您没有明确使用release标签,那么将使用最新的开发代码,而不是官方版本。
3.按照中的说明进行操作[DeepOps Kubernetes部署指南]安装Kubernetes。
选项2:使用Kubeadm安装Kubernetes
对于脚本较少的方法,特别是对于较小的集群或者希望了解构成Kubernetes集群的组件的地方,可以使用
Kubeadm。
Kubernetes集群由主节点和工作节点组成。主节点运行Kubernetes的控制平面组件,这允许您的集群正常运行。这些组件包括API服务器(的前端kubectlCLI),主节点(存储集群状态)等。
使用
纯CPU(无GPU)主节点,它们运行控制平面组件:调度程序、API服务器和控制器管理器。控制面板组件可能会对您的CPU密集型任务产生一些影响,反之,CPU或HDD/SSD密集型组件也会对您的控制面板组件产生影响。随着
kubeadm,本文将介绍安装单节点Kubernetes集群的步骤(在这里,我们取消了控制平面的限制,以便它可以运行GPU pods),但是集群可以通过添加节点轻松扩展。
步骤0:开始之前
在继续安装组件之前,检查所有Kubernetes[先决条件]已经满足了。这些先决条件包括:
【1】 检查
网络适配器和所需的端口
【2】禁用节点上的交换,以便kubelet可以正常工作
【3】安装受支持的容器运行时,如Docker、containerd或CRI-O
根据您的Linux发行版,请参考以下步骤:
乌班图LTS¶
本节提供了在
Ubuntu 18.04和20.04 LTS发行版上设置K8s的步骤。
步骤1:安装容器引擎
NVIDIA支持使用Docker和其他CRI兼容运行时运行GPU容器,例如集装箱d或者叫CRI-O。
码头工人 集装箱d |
|
| 按照中的步骤操作[向导安装Docker] |
步骤2:安装Kubernetes组件
首先,安装一些依赖项:
sudo apt-get update \
&& sudo apt-get install -y apt-transport-https curl
添加包存储库密钥:
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
存储库:
cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
更新软件包列表并安装库伯莱:
sudo apt-get update \
&& sudo apt-get install -y -q kubelet kubectl kubeadm
!注意
如果你在使用containerd作为CRI运行时,然后按照以下步骤操作:
【1】 为配置cgroup驱动程序kubelet:
sudo mkdir -p /etc/systemd/system/kubelet.service.d/
sudo cat << EOF | sudo tee /etc/systemd/system/kubelet.service.d/0-containerd.conf
[Service]
Environment="KUBELET_EXTRA_ARGS=--container-runtime=remote --runtime-request-timeout=15m --container-runtime-endpoint=unix:///run/containerd/containerd.sock --cgroup-driver='systemd'"
EOF
【2】重新启动kubelet:
sudo systemctl daemon-reload \
&& sudo systemctl restart kubelet
禁用交换
sudo swapoff -a
和
init使用kubeadm:
sudo kubeadm init --pod-network-cidr=192.168.0.0/16
使用Kubeadm完成配置设置:
mkdir -p $HOME/.kube \
&& sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config \
&& sudo chown $(id -u):$(id -g) $HOME/.kube/config
步骤3:配置网络
现在,使用Calico设置网络:
$ kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
解除对控制平面的限制,以便它可以用于在我们简单的单节点集群中调度GPU pods:
$ kubectl taint nodes --all node-role.kubernetes.io/master-
您的集群现在应该可以调度容器化的应用程序了。
CentOS
按照本节中的步骤在CentOS 7/8上设置K8s。
!注意
如果您在云IaaS平台(如EC2)上使用CentOS 7/8,那么您可能需要进行一些额外的设置,如下所示:
【1】为您的EC2地区选择官方CentOS图像:https://wiki.centos.org/Cloud/AWS
【2】安装一些必备组件:
CentOS 8 |
CentOS 7 |
sudo dnf install -y tar bzip2 make automake gcc gcc-c++ \
pciutils elfutils-libelf-devel libglvnd-devel \
iptables firewalld bind-utils \
vim wget
【3】更新正在运行的内核,以确保您运行的是最新的更新
CentOS 8 |
CentOS 7 |
sudo dnf update -y
【4】重启你的虚拟机
sudo reboot
步骤0:配置系统
禁用新功能
为了成功安装NVIDIA驱动程序,必须首先禁用新驱动程序。
确定
nouveau驱动程序已加载:
$ lsmod | grep -i nouveau
在以下位置创建文件
/etc/modprobe.d/blacklist-nouveau.conf包含以下内容:
blacklist nouveau
options nouveau modeset=0
重新生成内核initramfs:
sudo dracut --force
继续下一步之前,请重新启动系统。
对于本节的剩余部分,我们将遵循使用的一般步骤[kubeadm]。此外,为了方便起见,让我们进入一个互动
sudo会话,因为其余大多数命令都需要root权限:
sudo -i
禁用SELinux
setenforce 0 \
&& sed -i --follow-symlinks 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/sysconfig/selinux
桥接流量和iptables
如中所述kubedadm文档,请确保br_netfilter模块已加载:
$ modprobe br_netfilter
确保
net.bridge.bridge-nf-call-iptables已正确配置:
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
并重新启动
sysctl配置:
sysctl --system
防火墙和所需端口
网络插件要求在控制平面和工作节点上打开某些端口。看到这个了吗[桌子]有关这些端口号用途的更多信息。
确保
firewalld正在运行:
$ systemctl status firewalld
如果需要,开始
firewalld:
$ systemctl --now enable firewalld
现在打开端口:
firewall-cmd --permanent --add-port=6443/tcp \
&& firewall-cmd --permanent --add-port=2379-2380/tcp \
&& firewall-cmd --permanent --add-port=10250/tcp \
&& firewall-cmd --permanent --add-port=10251/tcp \
&& firewall-cmd --permanent --add-port=10252/tcp \
&& firewall-cmd --permanent --add-port=10255/tcp
还需要添加
docker0接口到公共区域,并允许docker0入口和出口:
`CentOS 8 | CentOS 7`
$ nmcli connection modify docker0 connection.zone public \
&& firewall-cmd --zone=public --add-masquerade --permanent \
&& firewall-cmd --zone=public --add-port=443/tcp
重新加载
firewalld配置和dockerd为使设置生效:
$ firewall-cmd --reload \
&& systemctl restart docker
或者,在我们安装Kubernetes控制平面之前,使用一个简单的
ping命令:
$ docker run busybox ping google.com
禁用交换
为了提高性能,请在系统上禁用交换:
$ swapoff -a
步骤1:安装Docker
按照中的步骤操作[向导]在CentOS 7/8上安装Docker。
步骤2:安装Kubernetes组件
将网络存储库列表添加到软件包管理器配置中:
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
安装组件:
`CentOS 8 | CentOS 7`
$ dnf install -y kubelet kubectl kubeadm
确保
kubelet在系统重新启动时启动:
$ systemctl --now enable kubelet
现在使用kubeadm要初始化控制平面:
kubeadm init --pod-network-cidr=192.168.0.0/16
此时,您可以随意退出互动
sudo我们开始的那个环节。
配置目录
要开始使用群集,请以普通用户身份运行以下命令:
mkdir -p $HOME/.kube \
&& sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config \
&& sudo chown $(id -u):$(id -g) $HOME/.kube/config
如果您正在使用一个简单的集群(或者只是测试),您可以解开控制平面节点,以便它也可以运行容器:
$ kubectl taint nodes --all node-role.kubernetes.io/master-
此时,您的集群将如下所示:
$ kubectl get pods -A
`NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-f9fd979d6-46hmf 0/1 Pending 0 23s
kube-system coredns-f9fd979d6-v7v4d 0/1 Pending 0 23s
kube-system etcd-ip-172-31-54-109.ec2.internal 0/1 Running 0 38s
kube-system kube-apiserver-ip-172-31-54-109.ec2.internal 1/1 Running 0 38s
kube-system kube-controller-manager-ip-172-31-54-109.ec2.internal 0/1 Running 0 37s
kube-system kube-proxy-xd5zg 1/1 Running 0 23s
kube-system kube-scheduler-ip-172-31-54-109.ec2.internal 0/1 Running 0 37s`
步骤3:配置网络
出于本文的目的,我们将使用Calico作为网络插件来配置Kubernetes集群中的网络。由于一个[问题]使用CentOS上的Calico和iptables,让我们在部署插件之前修改配置。
下载calico配置:
curl -fOSsL https://docs.projectcalico.org/manifests/calico.yaml
并将以下配置选项添加到环境部分:
- name: FELIX_IPTABLESBACKEND
value: "NFT"
保存修改后的文件,然后部署插件:
$ kubectl apply -f ./calico.yaml
几分钟后,您可以看到网络已经配置完毕:
`NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-5c6f6b67db-wmts9 1/1 Running 0 99s
kube-system calico-node-fktnf 1/1 Running 0 100s
kube-system coredns-f9fd979d6-46hmf 1/1 Running 0 3m22s
kube-system coredns-f9fd979d6-v7v4d 1/1 Running 0 3m22s
kube-system etcd-ip-172-31-54-109.ec2.internal 1/1 Running 0 3m37s
kube-system kube-apiserver-ip-172-31-54-109.ec2.internal 1/1 Running 0 3m37s
kube-system kube-controller-manager-ip-172-31-54-109.ec2.internal 1/1 Running 0 3m36s
kube-system kube-proxy-xd5zg 1/1 Running 0 3m22s
kube-system kube-scheduler-ip-172-31-54-109.ec2.internal 1/1 Running 0 3m36s`
要验证网络是否已成功设置,让我们使用
multitool容器:
$ kubectl run multitool --image=praqma/network-multitool --restart Never
然后运行一个简单的
ping命令来确保可以正确检测到DNS服务器:
kubectl exec multitool -- sh -c 'ping google.com'
PING google.com (172.217.9.206) 56(84) bytes of data.
64 bytes from iad30s14-in-f14.1e100.net (172.217.9.206): icmp_seq=1 ttl=53 time=0.569 ms
64 bytes from iad30s14-in-f14.1e100.net (172.217.9.206): icmp_seq=2 ttl=53 time=0.548 ms
步骤4:安装NVIDIA软件
至此,您应该有一个工作的Kubernetes控制平面和连接到集群的worker节点。我们可以继续在工作节点上配置NVIDIA软件。如本文开头所述,有两种选择:
安装NVIDIA依赖项
Kubernetes集群中的GPU worker节点需要启用以下组件:
【1】NVIDIA驱动程序
【2】NVIDIA容器工具包
【3】NVIDIA Kubernetes设备插件(以及可选的GPU功能发现插件)
【4】(可选)DCGM出口商收集GPU遥测数据,并集成到Prometheus等监控堆栈中
让我们走完这些步骤。
安装NVIDIA驱动程序
本节概述了使用安装驱动程序的步骤
aptLTS Ubuntu上的软件包管理器。
注意
有关设置NVIDIA驱动程序的完整说明,请访问快速入门指南[https://docs . NVIDIA . com/datacenter/Tesla/Tesla-installation-notes/index . html]。该指南涵盖了成功安装驱动程序所需的大量预安装要求和受支持Linux发行版的步骤。
为当前运行的内核安装内核头文件和开发包:
sudo apt-get install linux-headers-$(uname -r)
设置CUDA网络存储库,并确保CUDA网络存储库上的包优先于规范存储库:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID | sed -e 's/\.//g') \
&& wget https://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64/cuda-$distribution.pin \
&& sudo mv cuda-$distribution.pin /etc/apt/preferences.d/cuda-repository-pin-600
安装CUDA存储库GPG密钥:
sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64/7fa2af80.pub \
&& echo "deb http://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64 /" | sudo tee /etc/apt/sources.list.d/cuda.list
更新
apt存储库缓存并使用cuda-drivers或者cuda-drivers-<branch-number>元包。使用--no-install-recommends不依赖于X包的精简驱动安装选项。这对于云实例上的无头安装特别有用:
sudo apt-get update \
&& sudo apt-get -y install cuda-drivers
安装NVIDIA容器工具包(nvidia-docker2)
首先,设置
stableNVIDIA运行时和GPG密钥的存储库:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - \
&& curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
根据容器引擎的不同,您可能需要使用不同的包。
码头工人|集装箱d
安装nvidia-docker2更新程序包列表后的程序包(及其依赖项):
sudo apt-get update \
&& sudo apt-get install -y nvidia-docker2
因为
Kubernetes不支持--gpusDocker的选项nvidia运行时应该设置为GPU节点上Docker的默认容器运行时。这可以通过添加default-runtime行插入Docker守护进程配置文件,该文件通常位于系统的/etc/docker/daemon.json:
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
设置默认运行时后,重新启动Docker守护程序以完成安装:
sudo systemctl restart docker
此时,可以通过运行一个基本的
CUDA容器来测试工作设置:
sudo docker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smi
您应该观察到如下所示的输出:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.51.06 Driver Version: 450.51.06 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
| N/A 34C P8 9W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
安装NVIDIA设备插件
要在Kubernetes中使用GPU [NVIDIA设备插件]是必需的。NVIDIA设备插件是一个daemonset,它自动枚举集群每个节点上的GPU数量,并允许pods在GPU上运行。
部署设备插件的首选方法是使用
helm。首先,安装头盔:
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 \
&& chmod 700 get_helm.sh \
&& ./get_helm.sh
添加
nvidia-device-plugin helm存储库:
helm repo add nvdp https://nvidia.github.io/k8s-device-plugin \
&& helm repo update
部署设备插件:
helm install --generate-name nvdp/nvidia-device-plugin
有关部署daemonset时用户可配置的更多选项,请[参考文件]
此时,所有的吊舱都应展开:
$ kubectl get pods -A
`NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-5fbfc9dfb6-2ttkk 1/1 Running 3 9d
kube-system calico-node-5vfcb 1/1 Running 3 9d
kube-system coredns-66bff467f8-jzblc 1/1 Running 4 9d
kube-system coredns-66bff467f8-l85sz 1/1 Running 3 9d
kube-system etcd-ip-172-31-81-185 1/1 Running 4 9d
kube-system kube-apiserver-ip-172-31-81-185 1/1 Running 3 9d
kube-system kube-controller-manager-ip-172-31-81-185 1/1 Running 3 9d
kube-system kube-proxy-86vlr 1/1 Running 3 9d
kube-system kube-scheduler-ip-172-31-81-185 1/1 Running 4 9d
kube-system nvidia-device-plugin-1595448322-42vgf 1/1 Running 2 9d`
要测试CUDA作业是否可以部署,运行一个示例CUDA
vectorAdd应用:下面显示了
pod规格以供参考,它要求1个GPU:
apiVersion: v1
kind: Pod
metadata:
name: gpu-operator-test
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
image: "nvidia/samples:vectoradd-cuda10.2"
resources:
limits:
nvidia.com/gpu: 1
将此
podspec另存为gpu-pod.yaml。现在,部署应用程序:
$ kubectl apply -f gpu-pod.yaml
检查日志以确保应用程序成功完成:
$ kubectl get pods gpu-operator-test
NAME READY STATUS RESTARTS AGE
gpu-operator-test 0/1 Completed 0 9d
并检查日志
gpu-operator-testpod:
$ kubectl logs gpu-operator-test
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
