近期在使用tensorflow2.0的keras模块,训练的模型权重保存格式是.h5(Hierarchical Data Format,HDF5),然后遇到了个bug,一直无法载入权重,总提示shape不匹配,然后就想看下这个h5文件的内容。在网上了搜了各种使用h5py的方法都无法正确读取keras生成的h5文件内容,纠结这个问题浪费了我1整天的时间。下面说下我的解决办法。
首先说下环境:
Python3.6(Anaconda管理)
Tensorflow=2.0.0rc1
h5py=2.8.0rc1
首先推荐大家下载一个HDF5文件管理系统,HDFView,网盘链接:https://pan.baidu.com/s/12KcnRMWPhaaiixcja-1FRw 提取码:nc6k
下载安装后我们通过HDFView打开我们生成的.h5文件,以我的resnet101模型权重为例。

打开后我才发现,这个目录的结构和我想象的有点不太一样,比如说在上图中,我的模型中权重kernel:0的全称应该是'/block1/unit_1/conv2/kernel:0',但存储在h5文件中的路径全称确是'/block1/block1/unit_1/conv2/kernel:0'。
下面我们通过python的h5py包来打开这个h5文件,这里先给出一个最笨的办法(但很实用):
import h5py
f = h5py.File('./save_weights/resNet.h5', 'r')
data = f['/block1/block1/unit_1/conv2/kernel:0']
print(data.value)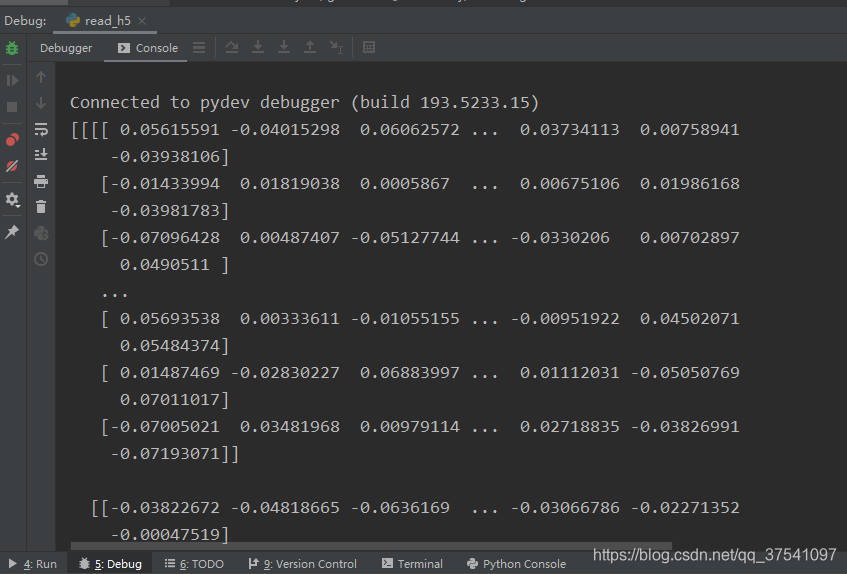
就这简单的几行代码,我们就将h5文件中的其中一个权重给读取出来了。你会发现,我们打开的'/block1/block1/unit_1/conv2/kernel:0'路径不就是我们刚刚通过HDFView软件查看的其中一个权重的路径吗,是的,这就是我说的笨方法,通过HDFView查看的目录结构获取权重。
下面给出第二种方法,通过h5py包自己去遍历所有文件:
import h5py
f = h5py.File('./save_weights/resNet_1.h5', 'r')
for root_name, g in f.items():
print(root_name)
for _, weights_dirs in g.attrs.items():
for i in weights_dirs:
name = root_name + "/" + str(i, encoding="utf-8")
data = f[name]
print(data.value)
首先声明下,这个代码是自己试出来的,因为网上并没有找到一个可行的方法,也懒得看官方文档。但该方法确实可以使用,亲测有效。
在代码中,首先打开h5文件,接着遍历根目录,接着获取每个根目录下的所有权重路径,将根目录路径与子权重路径进行拼接,接着打开该路径读取权重信息。