前言:此文章从客户端提交job任务开始,到对需要处理的数据进行切片,产生对应的maptask任务,Yarn来管理任务的调度来执行maptask和reducetask(包括shuffle)进行了详细的代码分析。
一、hadoop的Job 提交流程源码
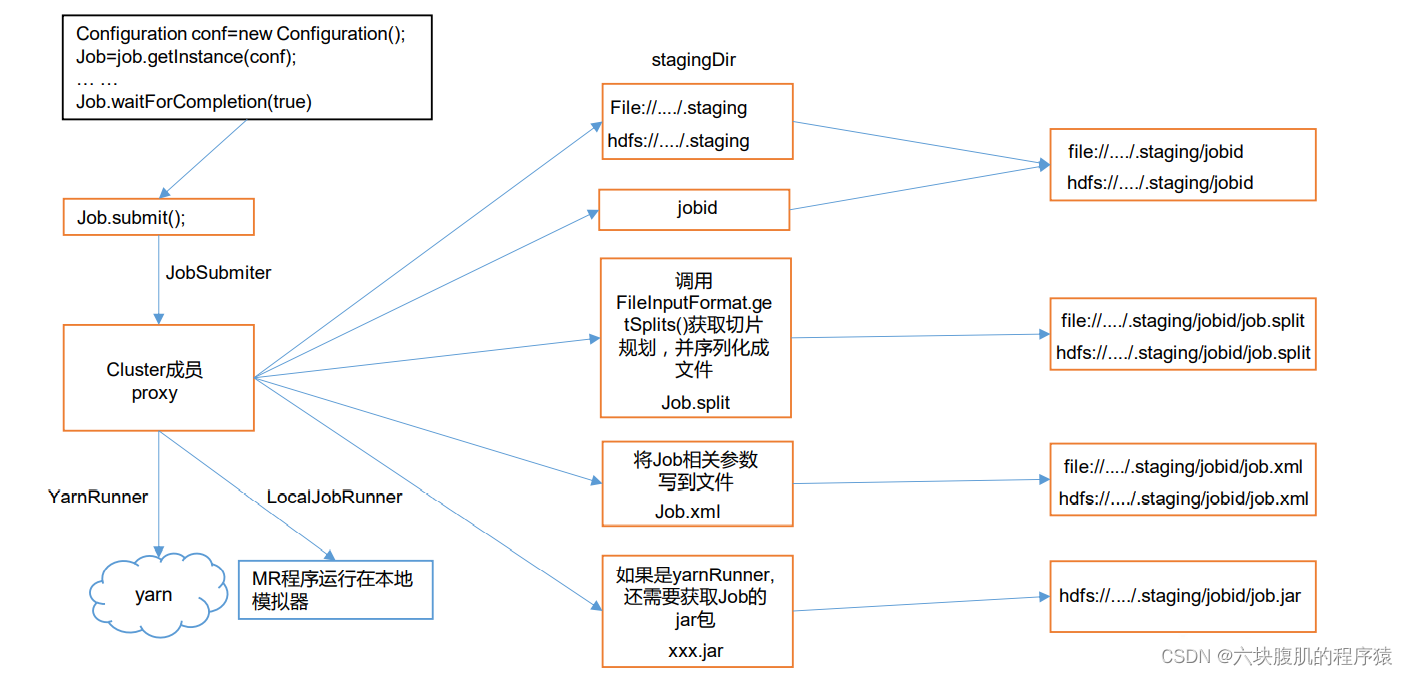
流程图:
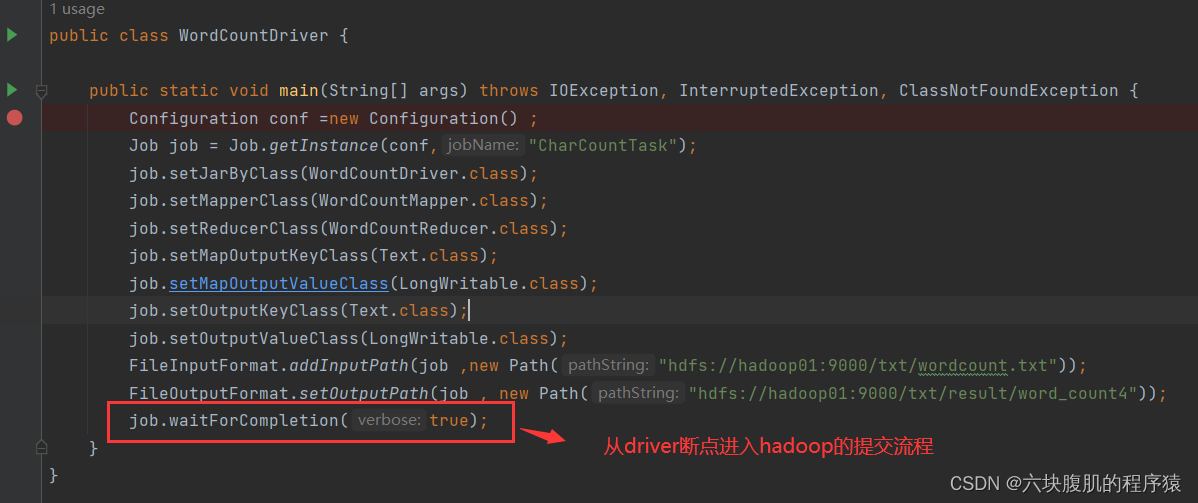
1.从我们编写的mapreduce的代码中进入job提交源码
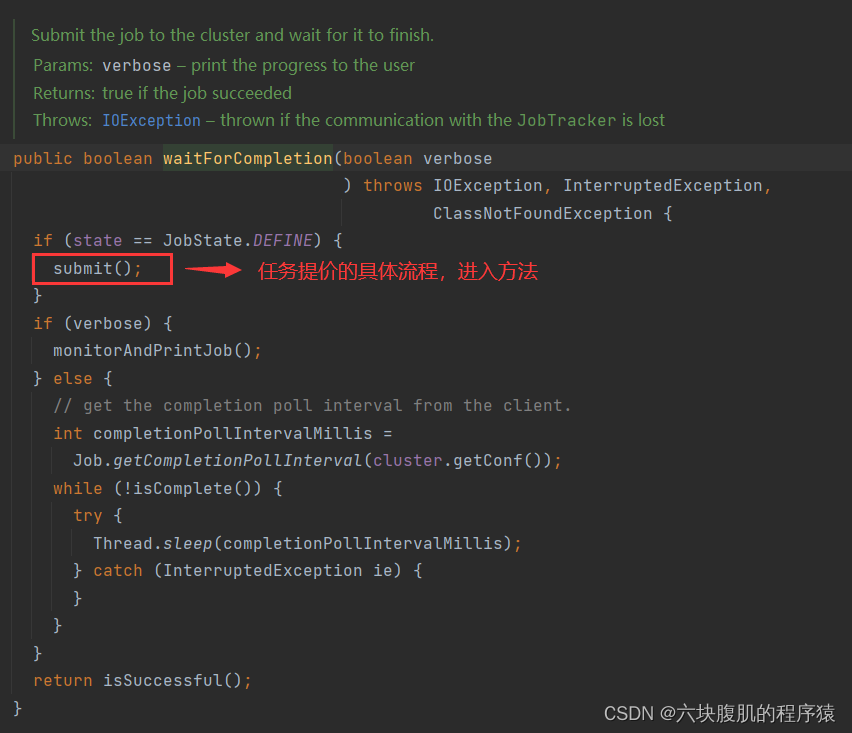
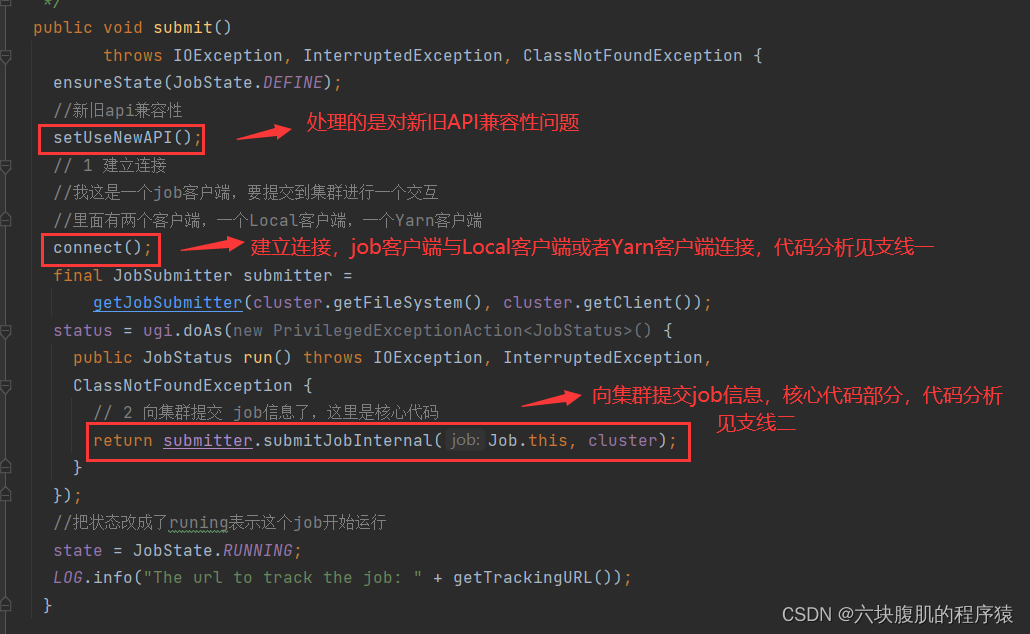
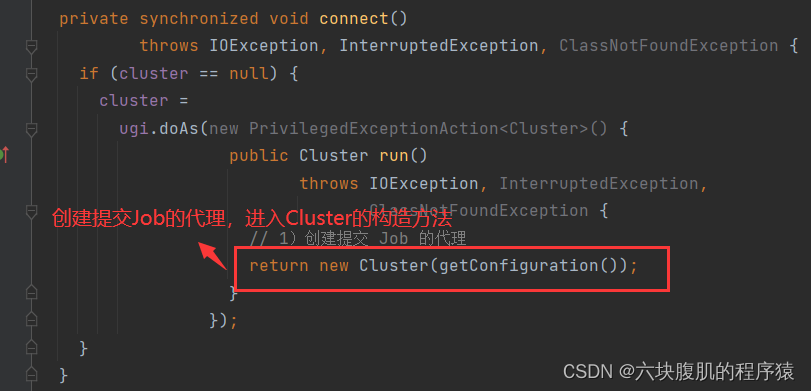
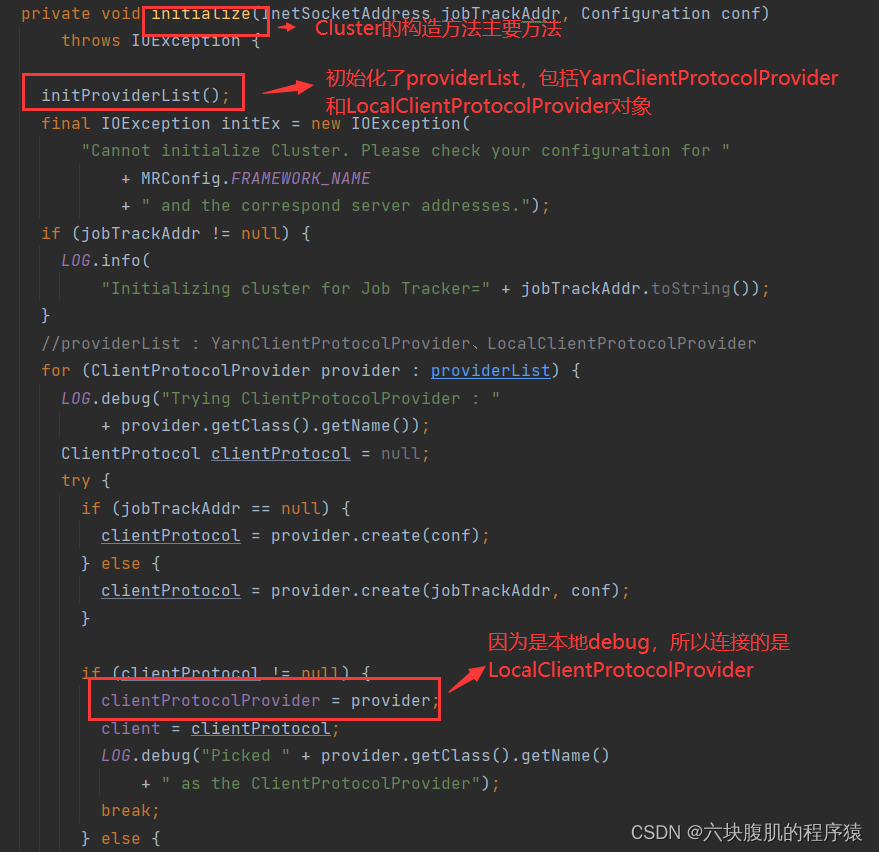
支线一:进入connect();
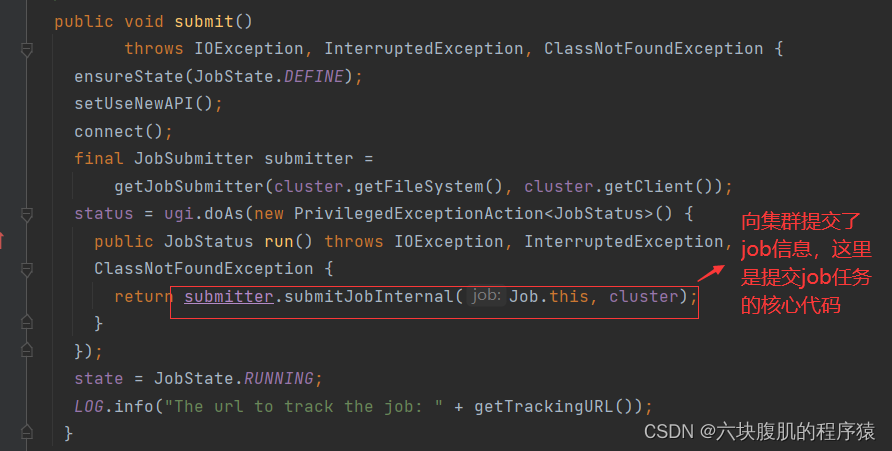
2.支线二:进入submitter.submitJobInternal(Job.this, cluster),向集群提交了job信息,这里是提交job任务的核心代码
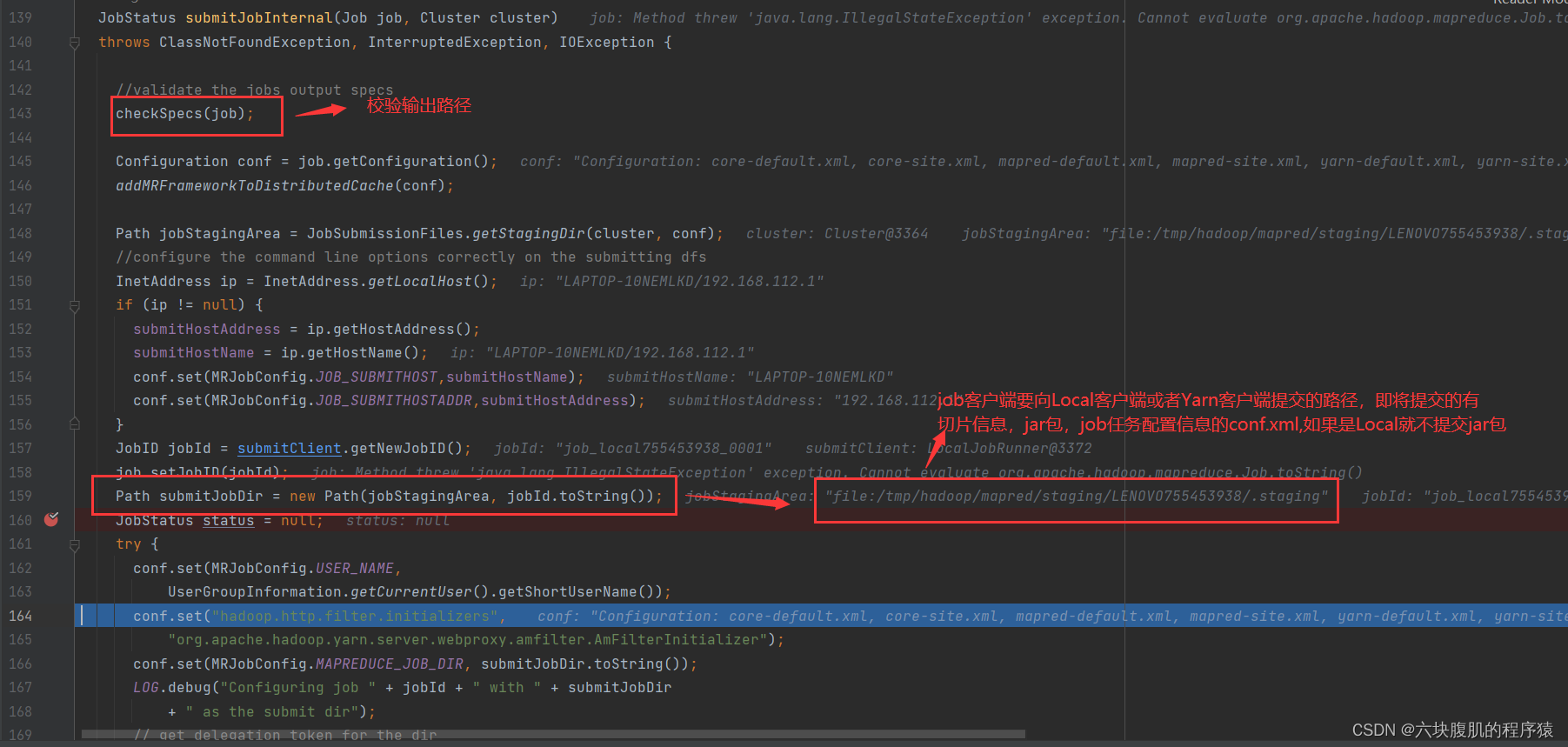
该方法(submitter.submitJobInternal(Job.this, cluster))往下翻:
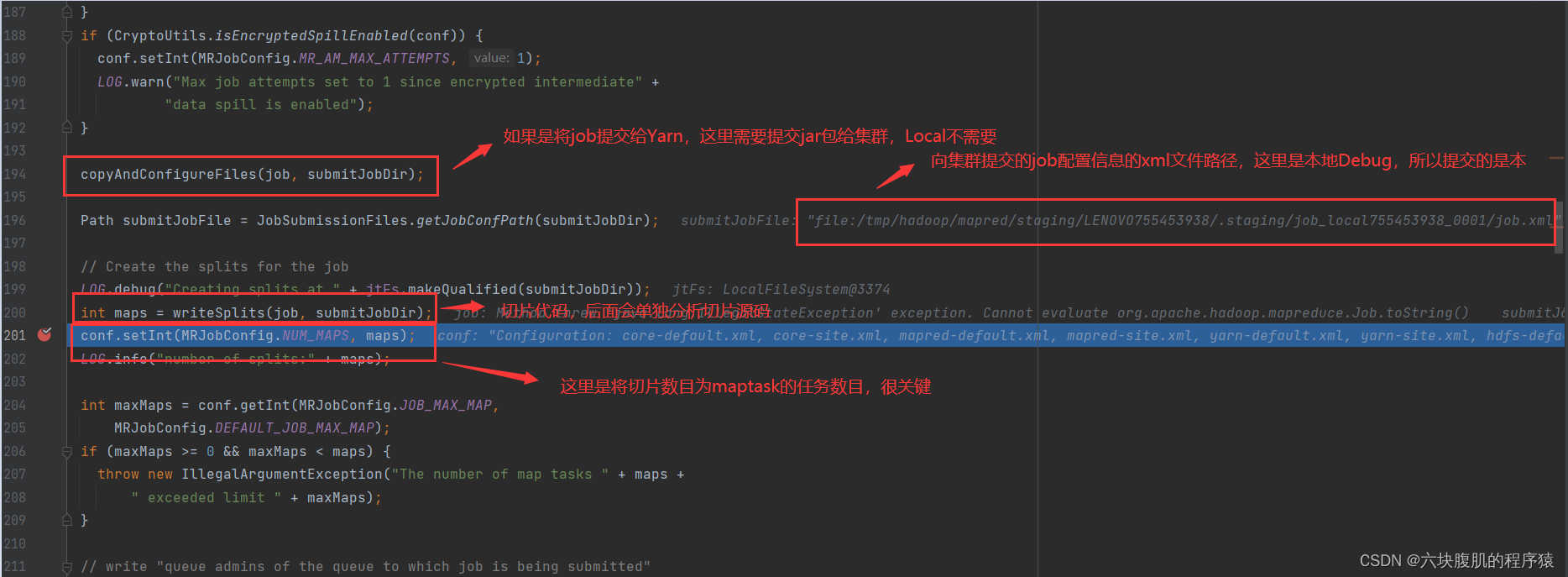
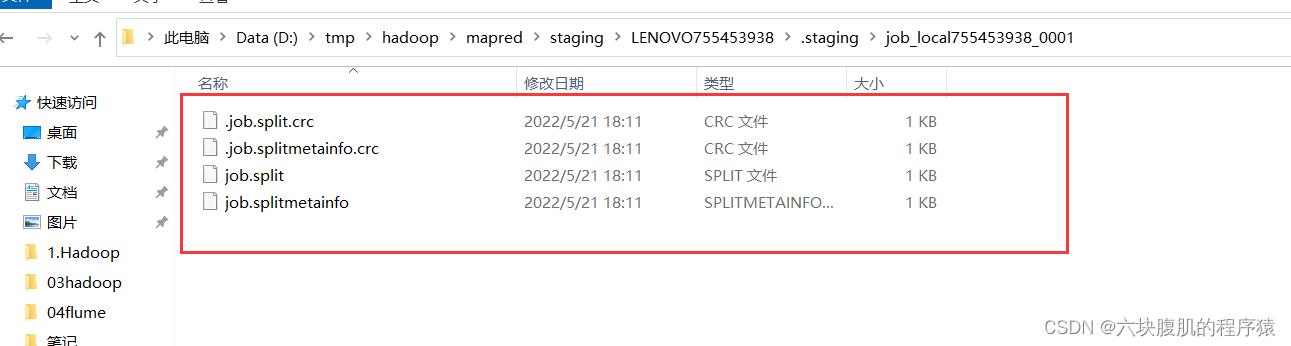
存入了切片信息的本地路径
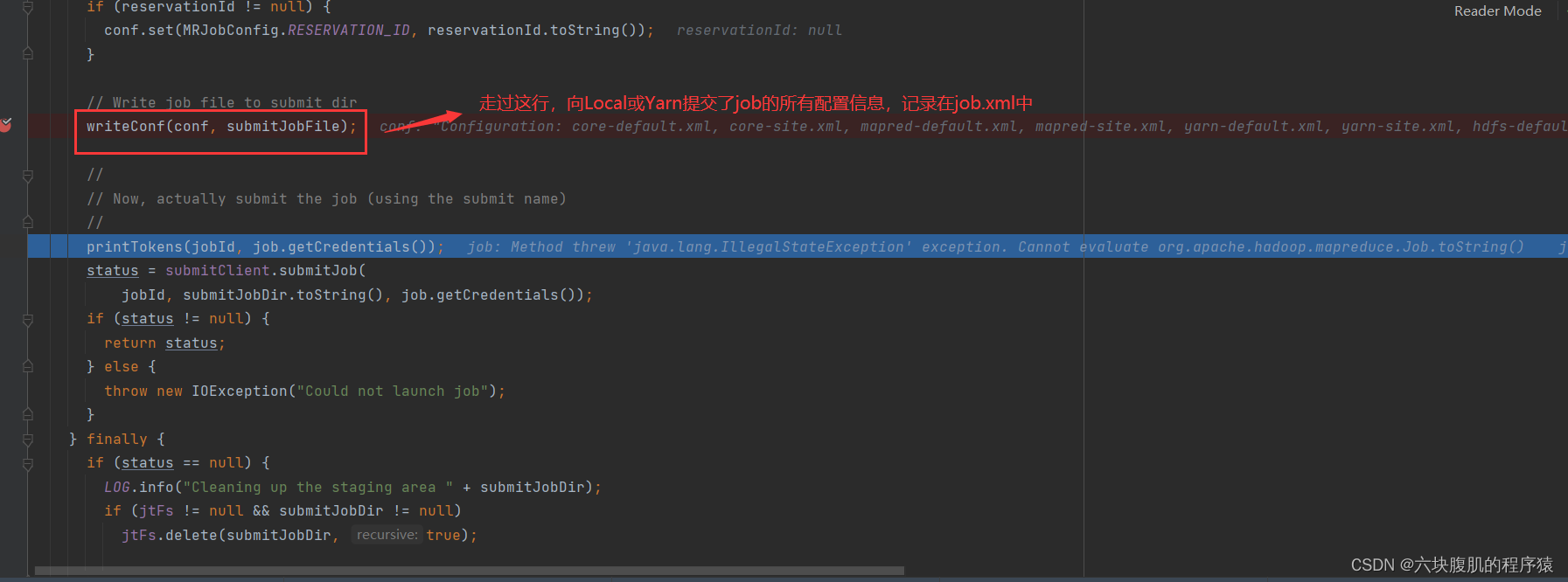
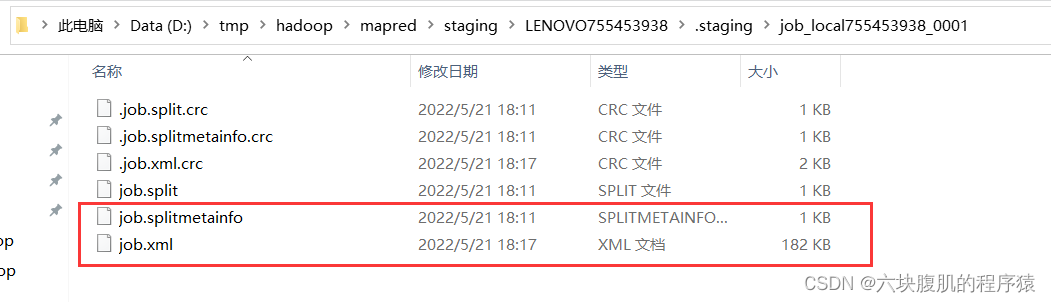
submitter.submitJobInternal(Job.this, cluster)方法继续往下走
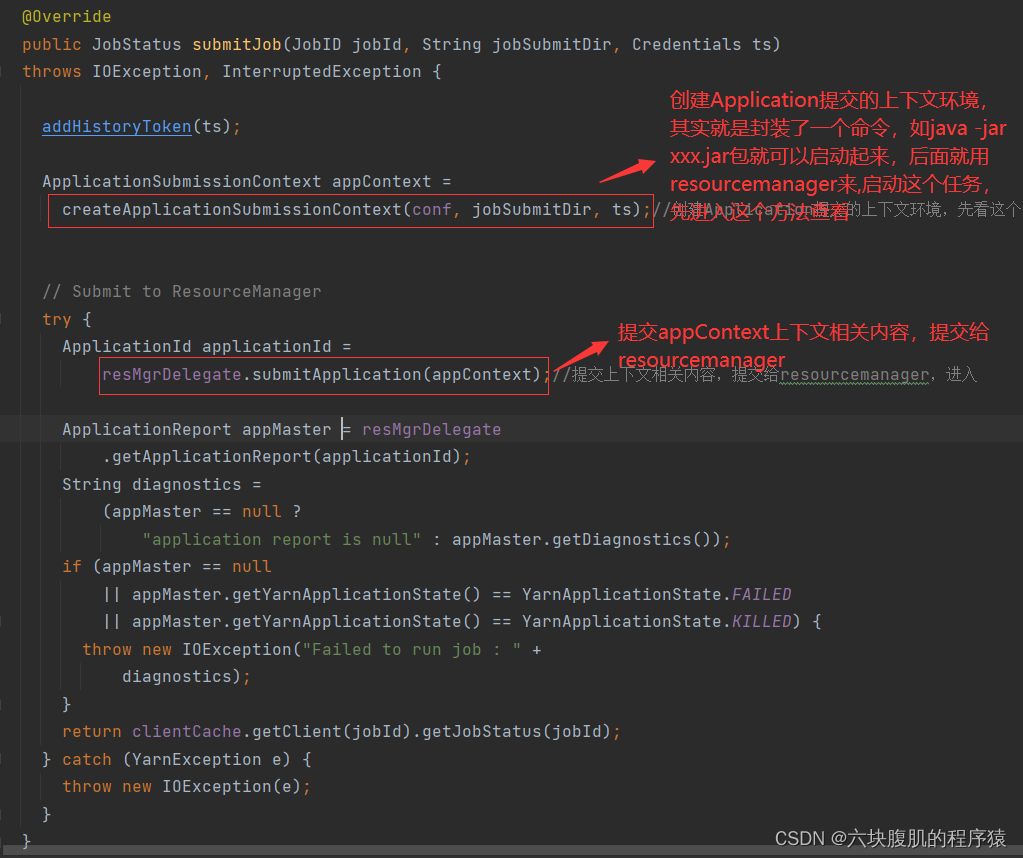
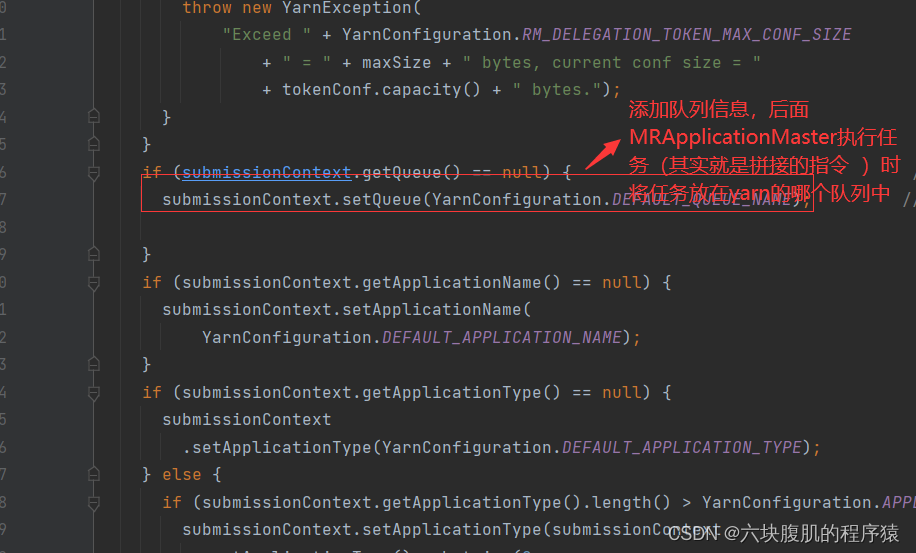
该方法继续往下看:将job的任务创建的Application的appContext上下文信息发送到Yarn的ResourseManager
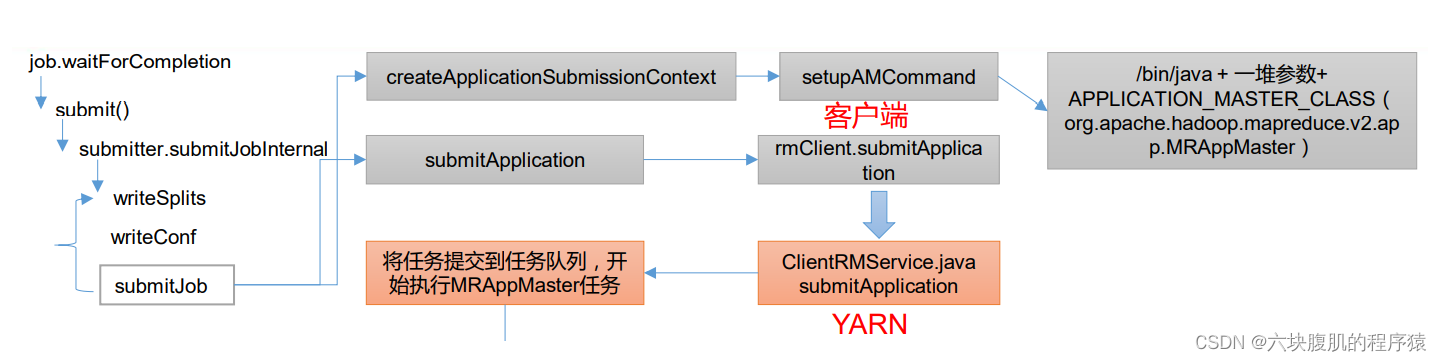
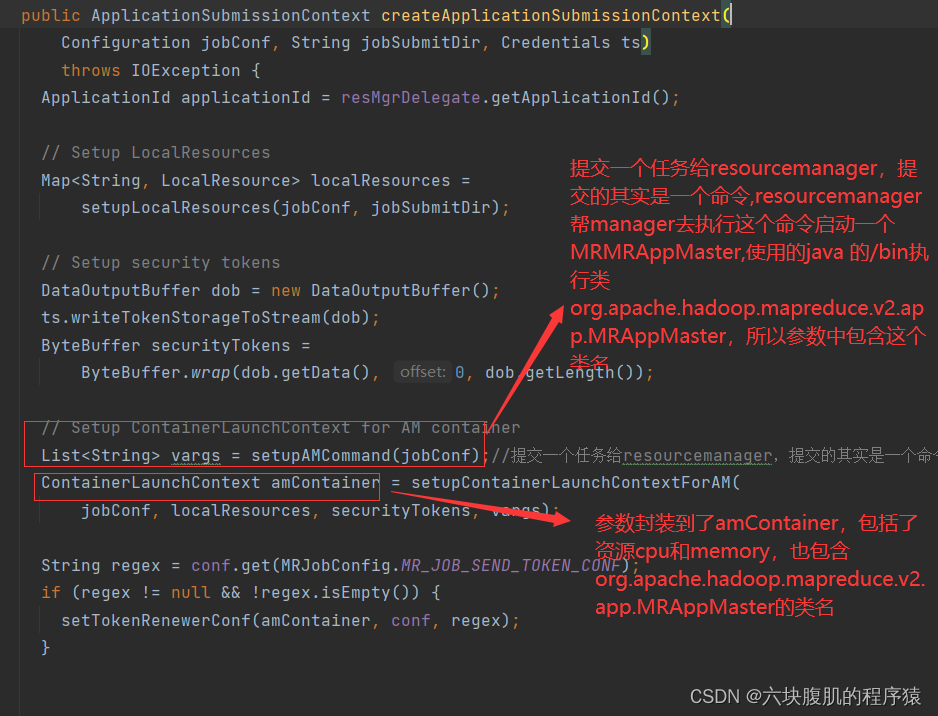
进入setupAMCommand,查看封装的各种参数
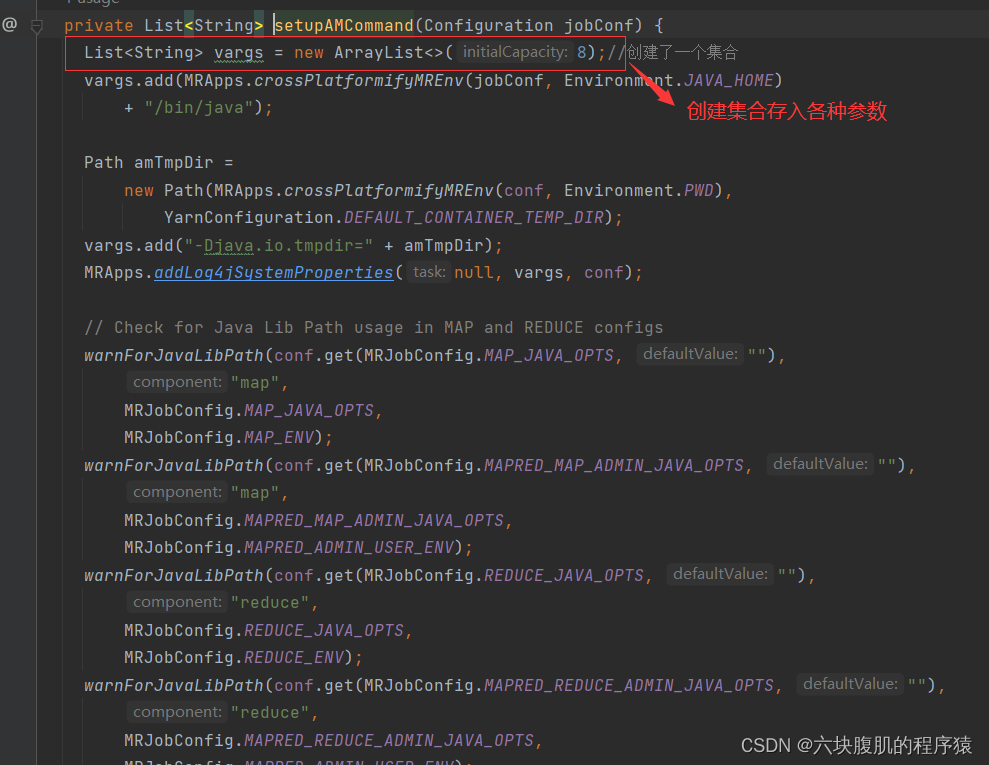
该方法继续往下翻
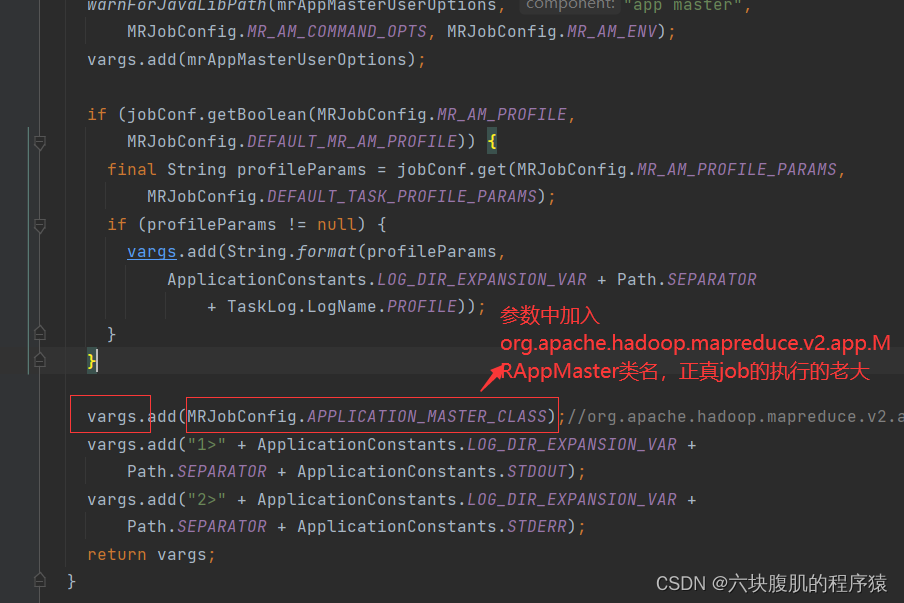
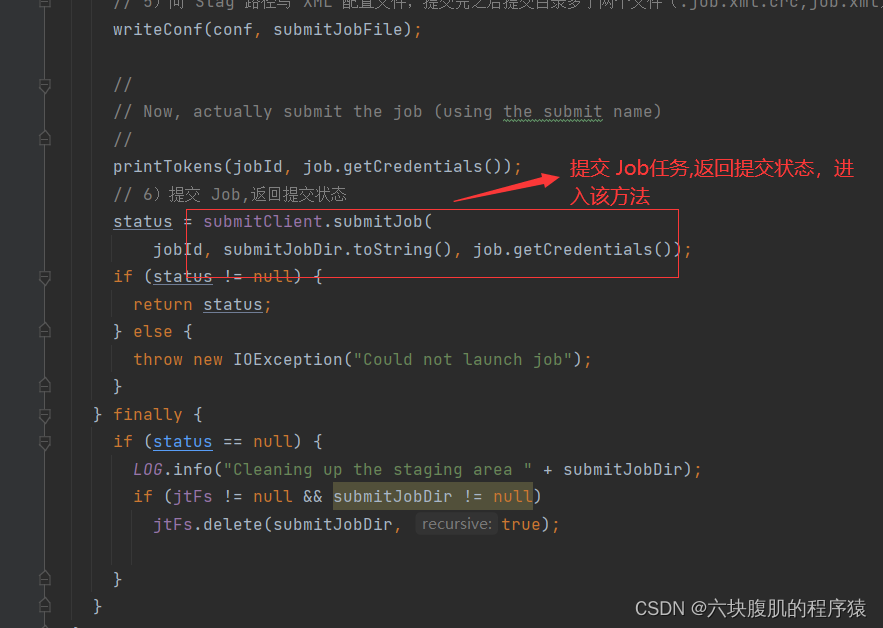
回到YARNRunner的submitJob方法
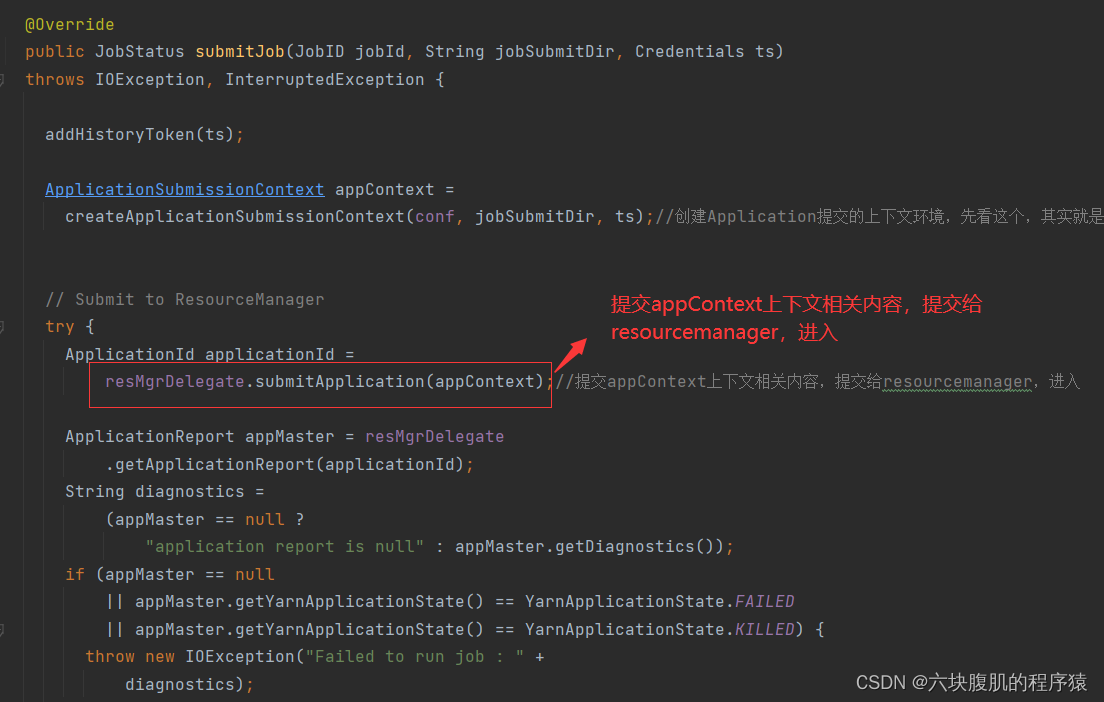
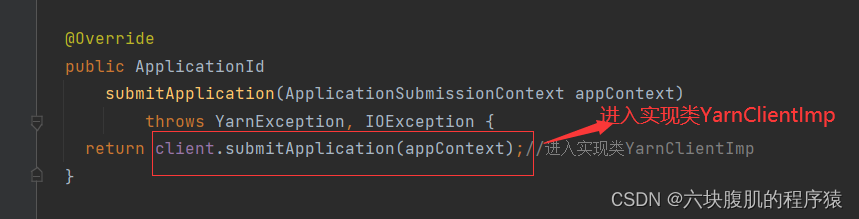
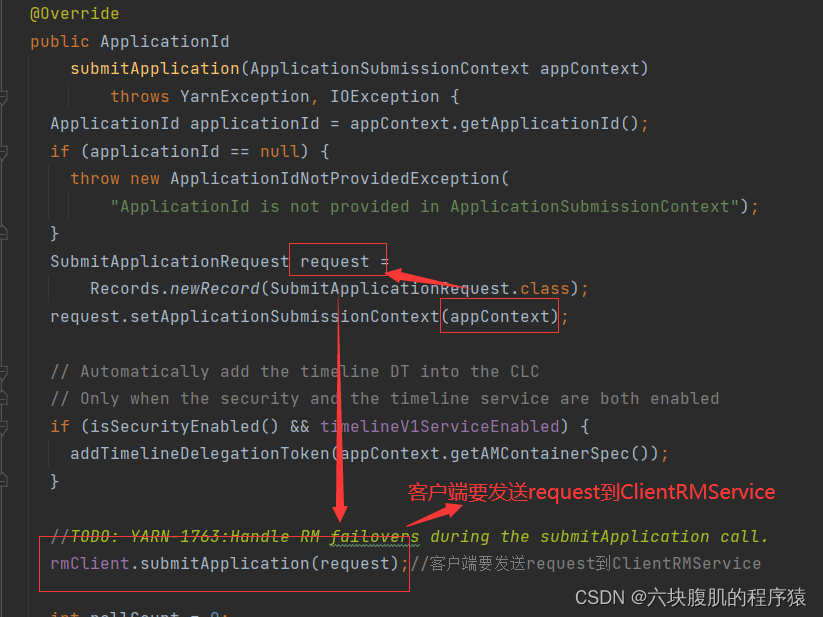
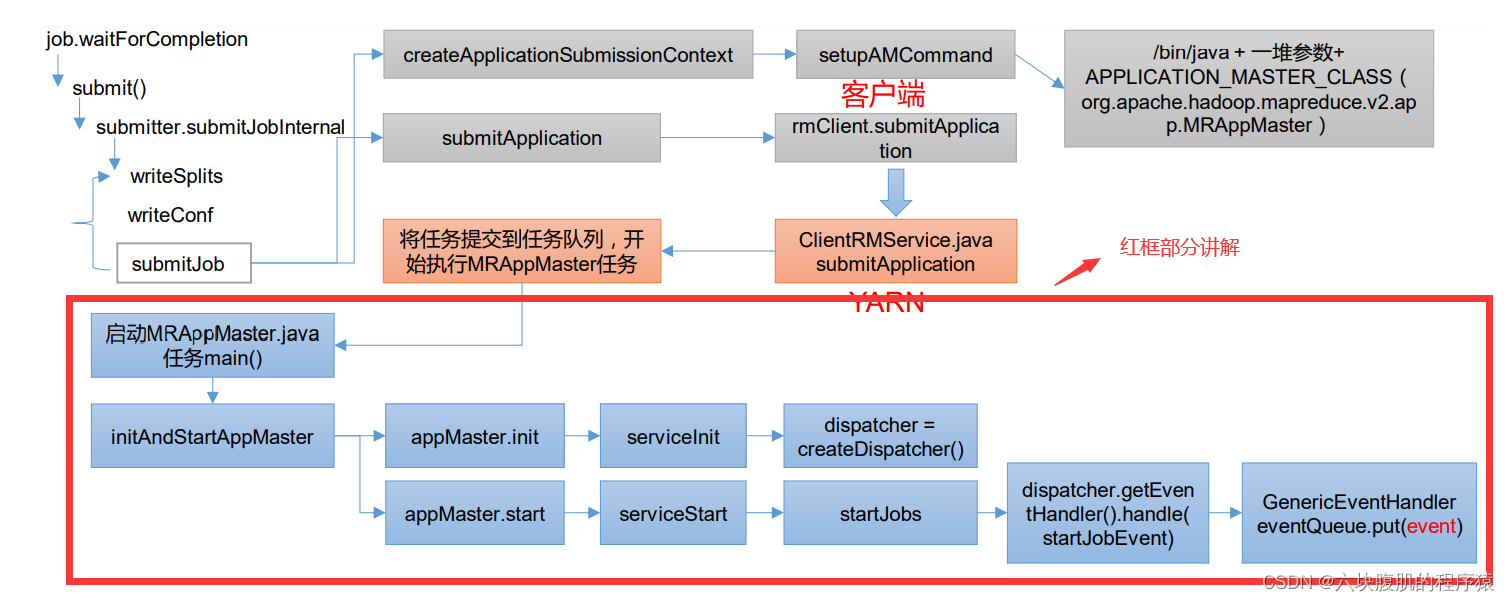
代码已经从客户端提交到了ClientRMService,ClientRMService就是resourceManager端,接下来可以查看Yarn 源码解析
二、hadoop的Job 提交流程切片源码
补充上面Job提交流程中有切片部分,单独拎出来分析
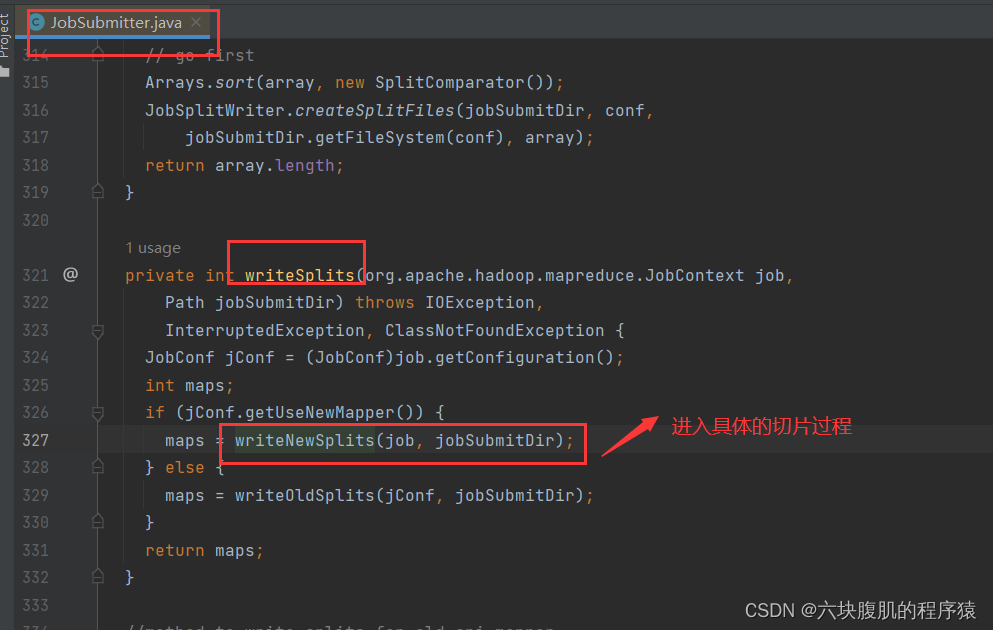

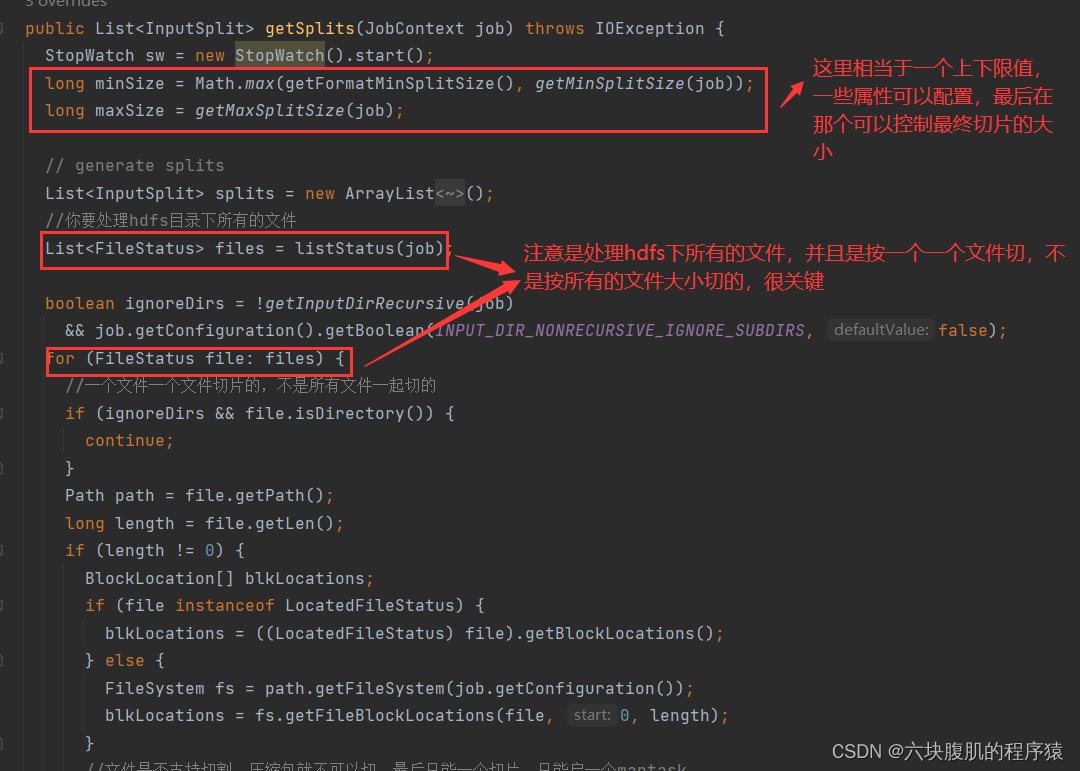
该方法继续往下走
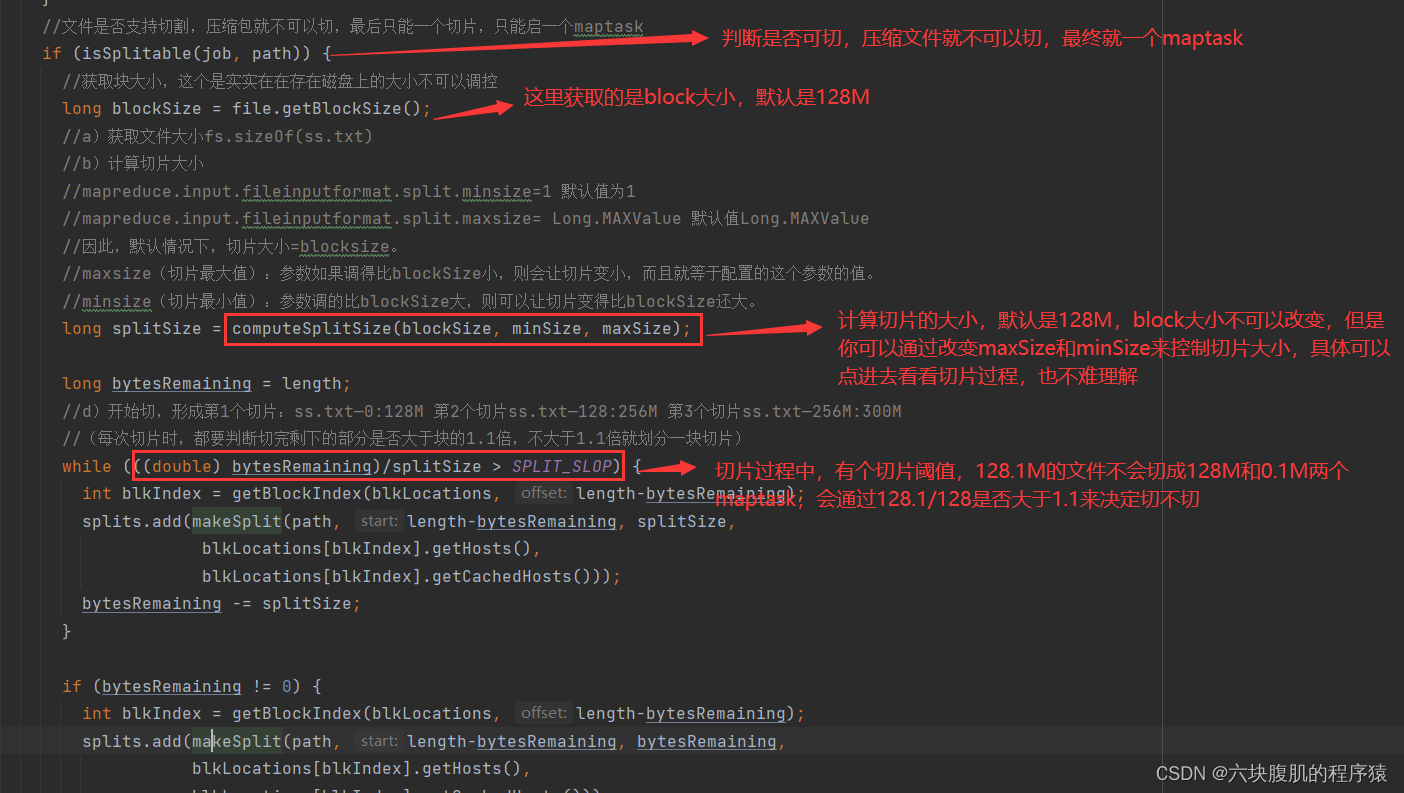
总结重点:切片大小默认是这样computeSplitSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M,公司里也一般是这个,不过可以修改,切块大小不是精准128M切,而是每次切片时,都要判断切完剩下的部分是否大于块的1.1倍,不大于1.1倍就划分一块切片。
三、Yarn 源码解析
1.YARN工作机制
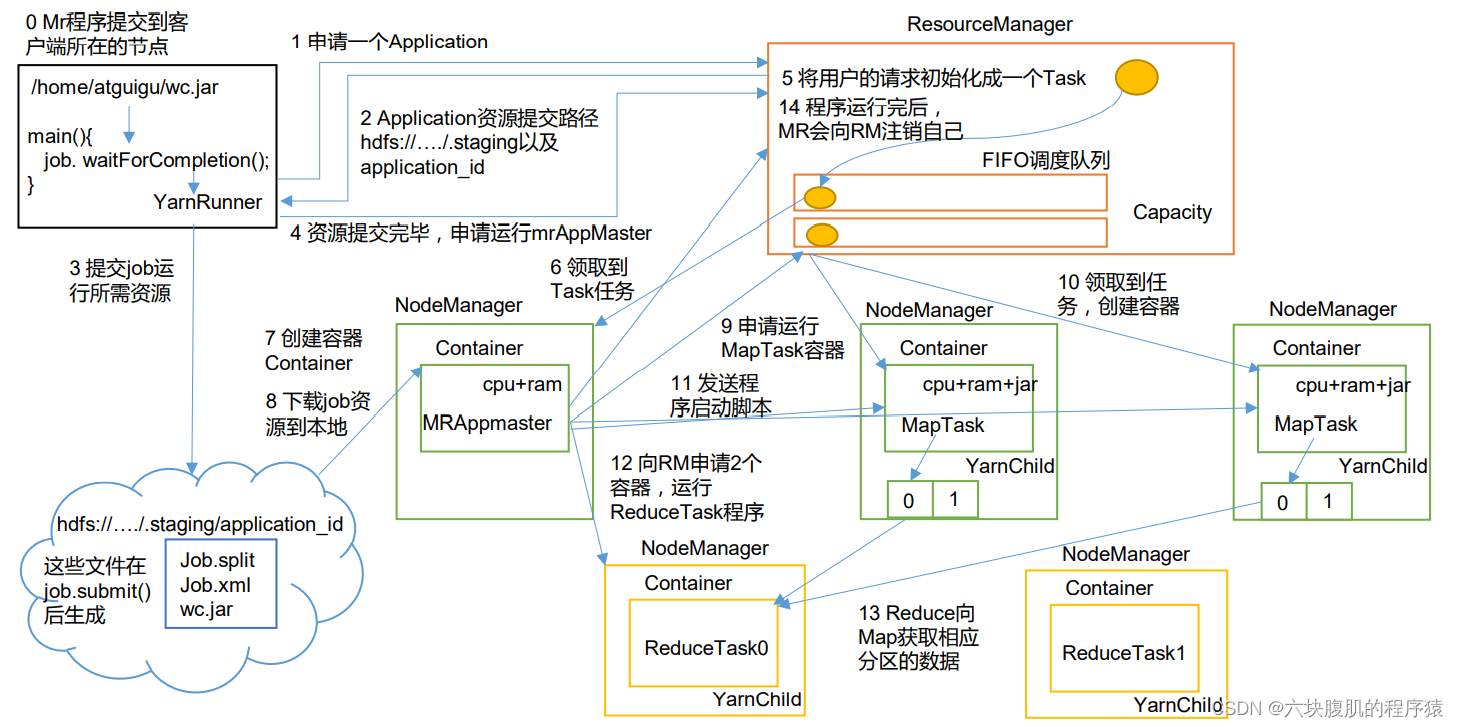
2.YARN源码解析
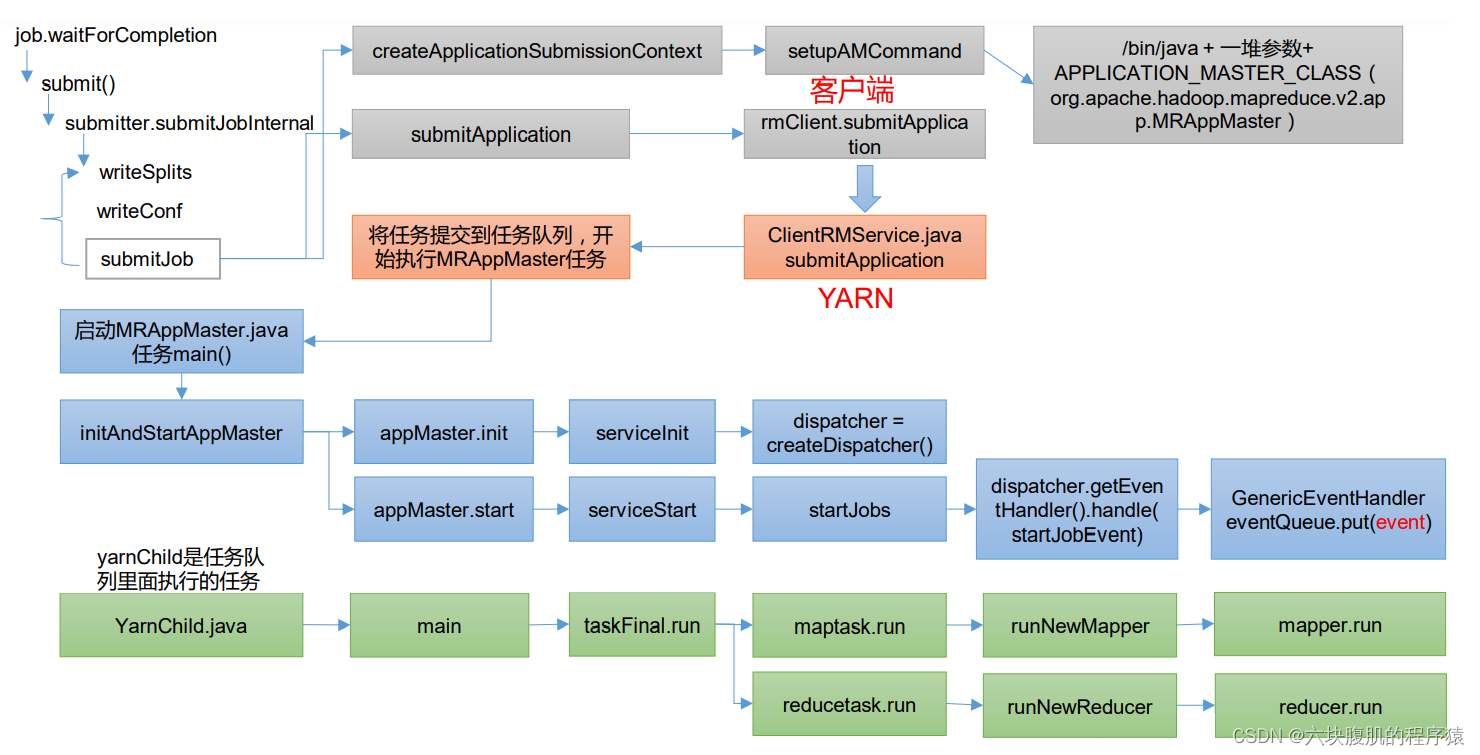
1.前言:之前job任务提交的代码(途中灰色部分)已经讲解,客户端发送request到了客户端部分
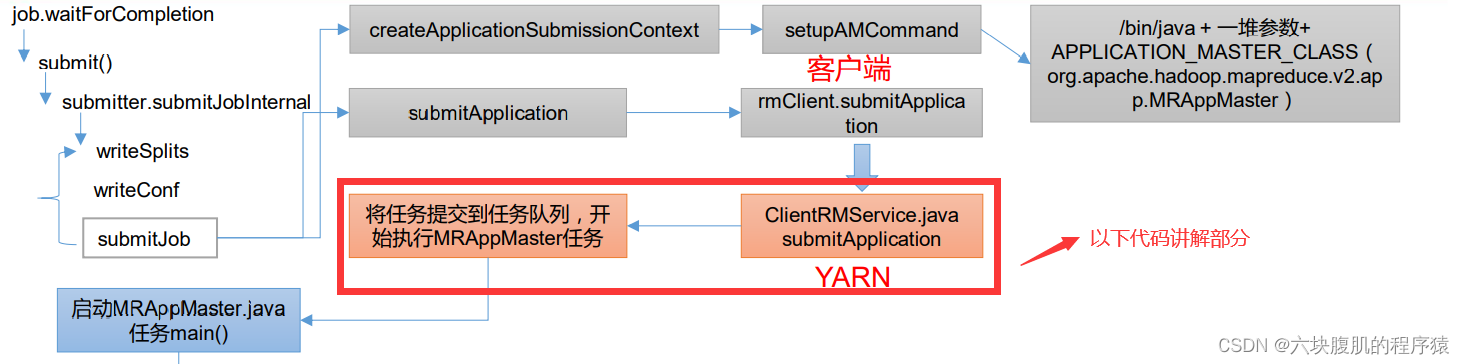
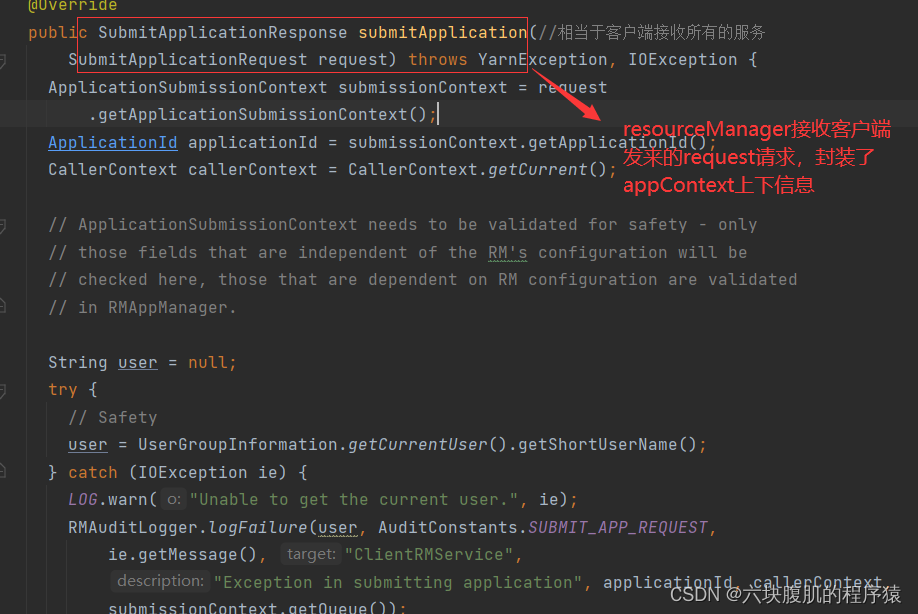
该方法继续往下看
2.resourceManager通过指令命令执行MRAppMaster.java类的main方法
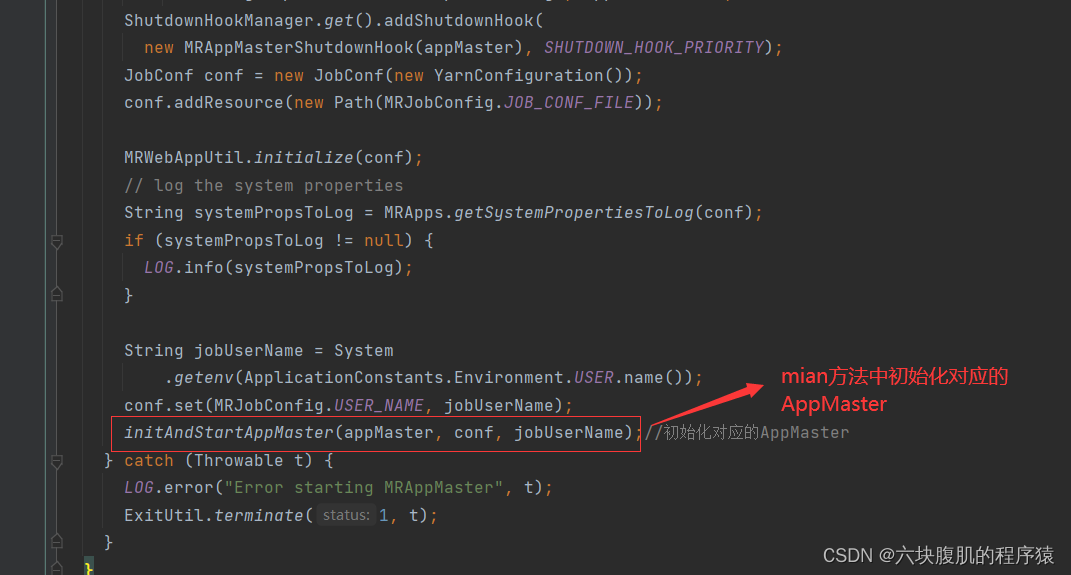
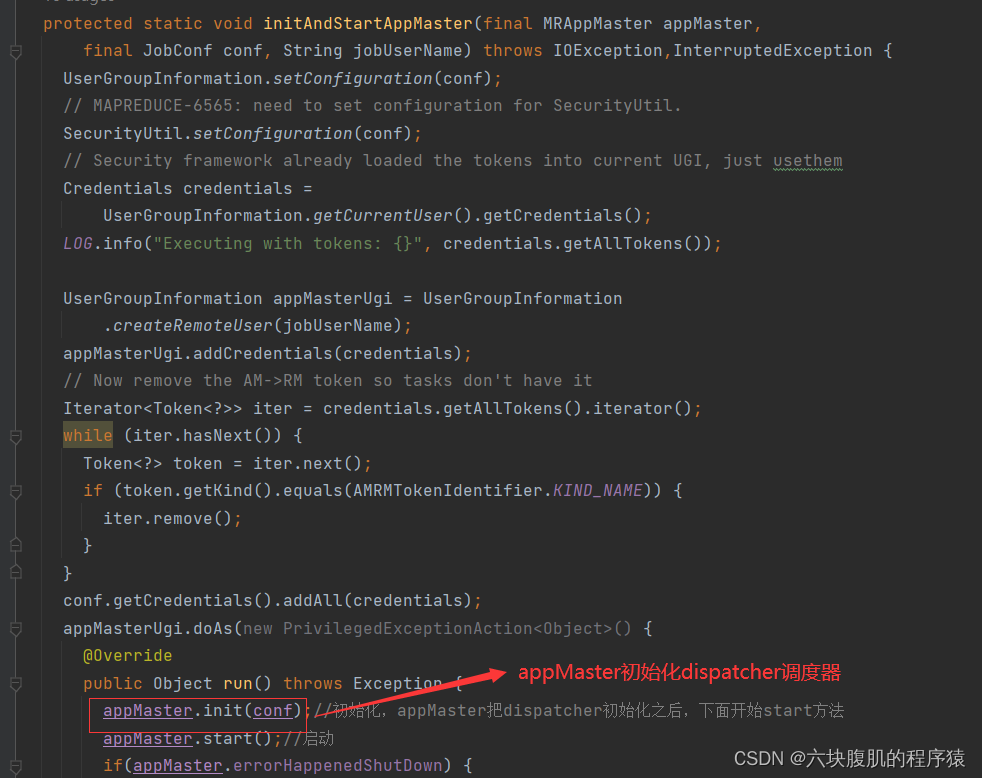
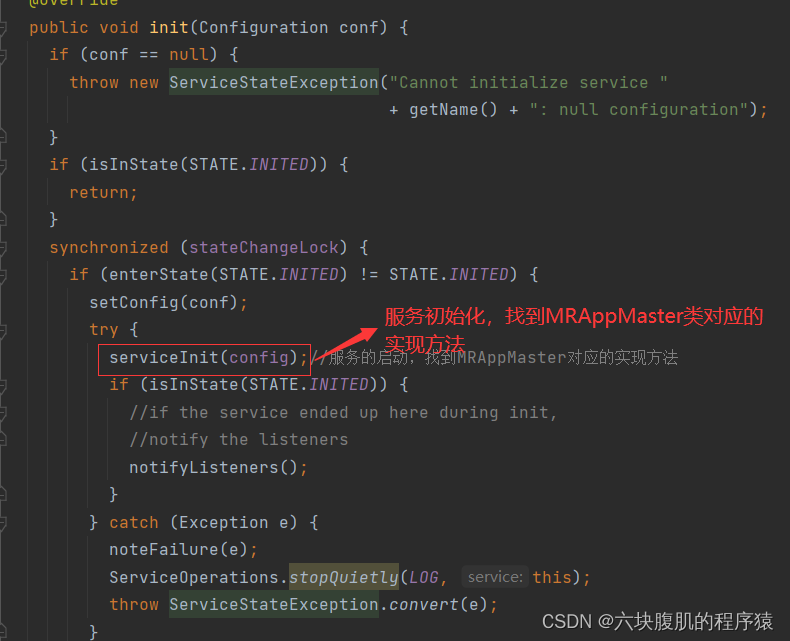
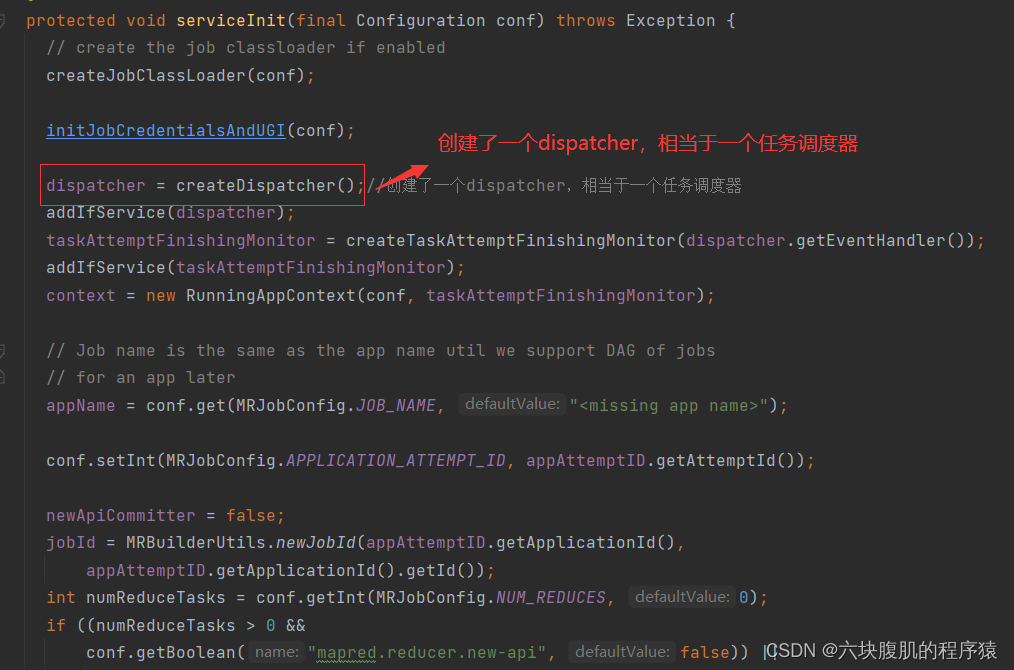
回到initAndStartAppMaster初始化AppMaster方法
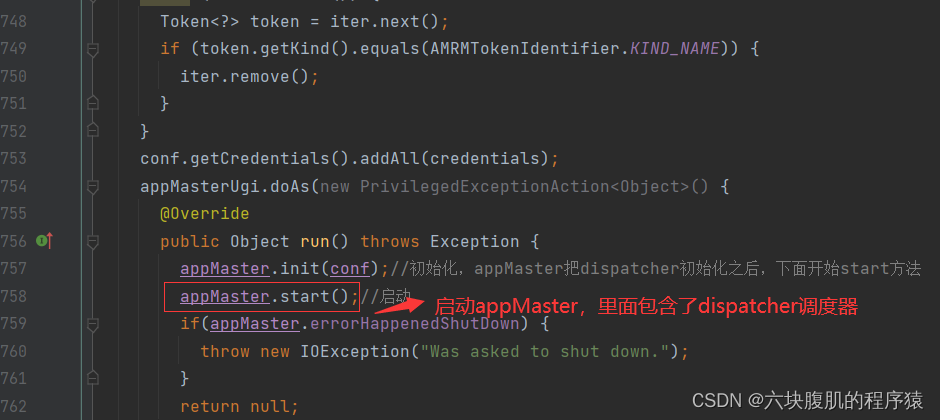
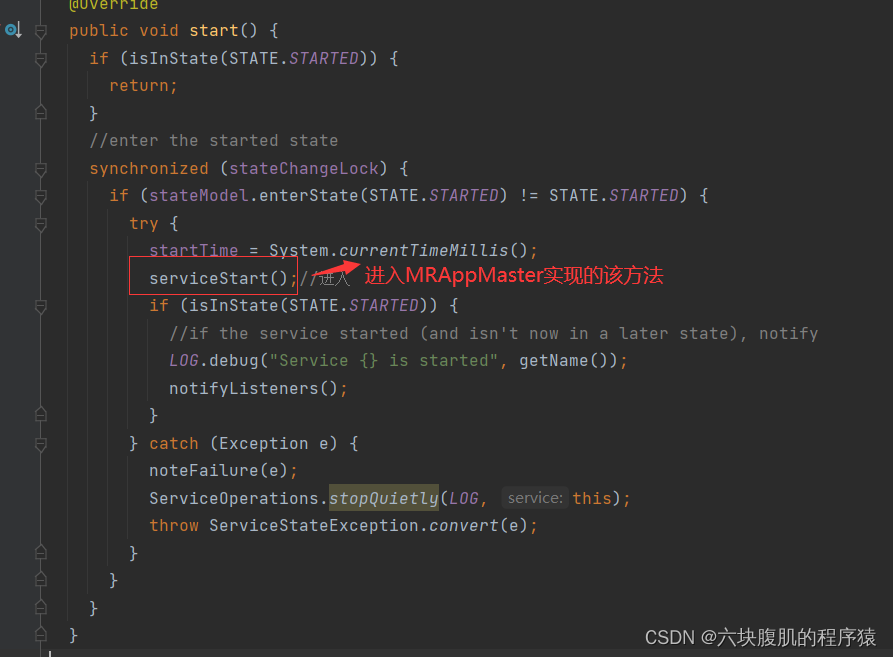
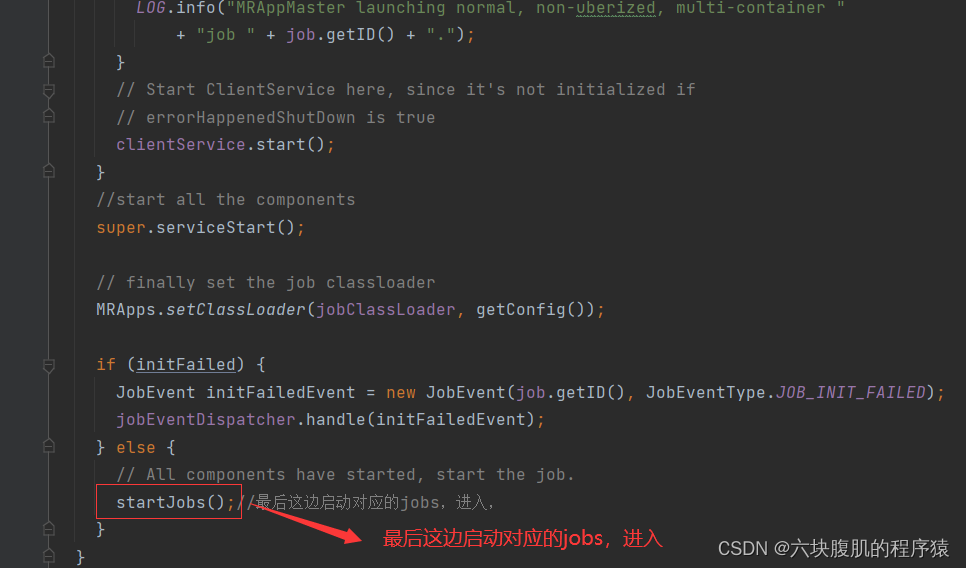
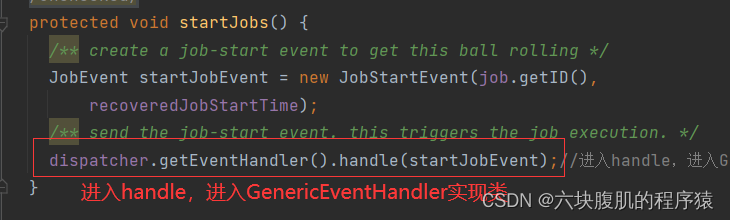
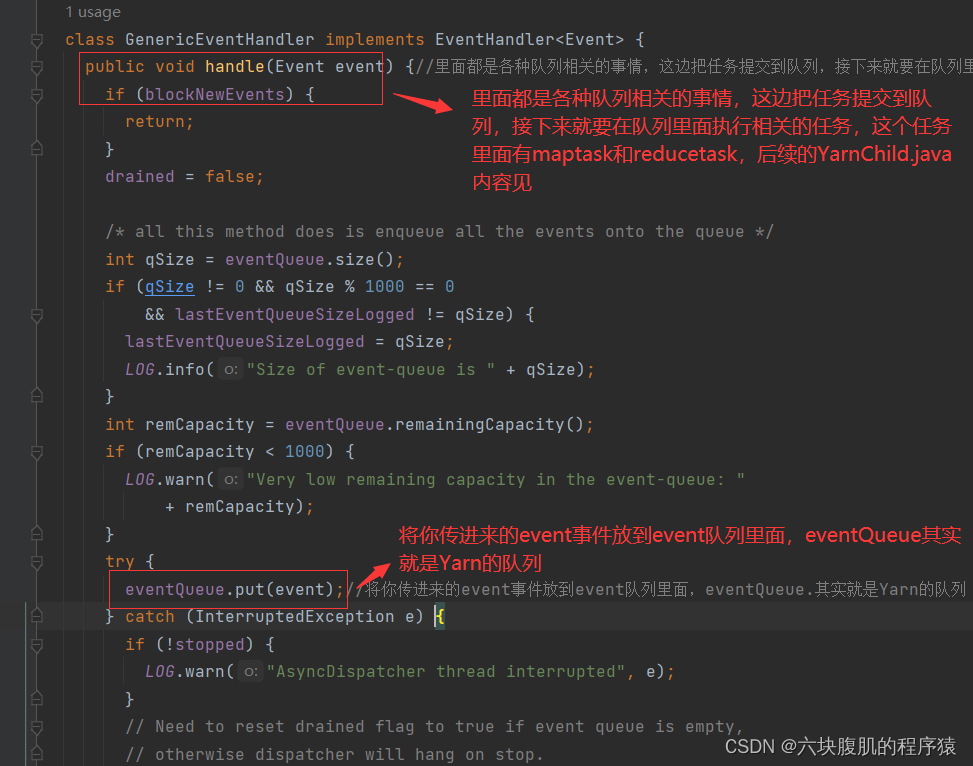
3.YarnChild负责MapReduce任务过程

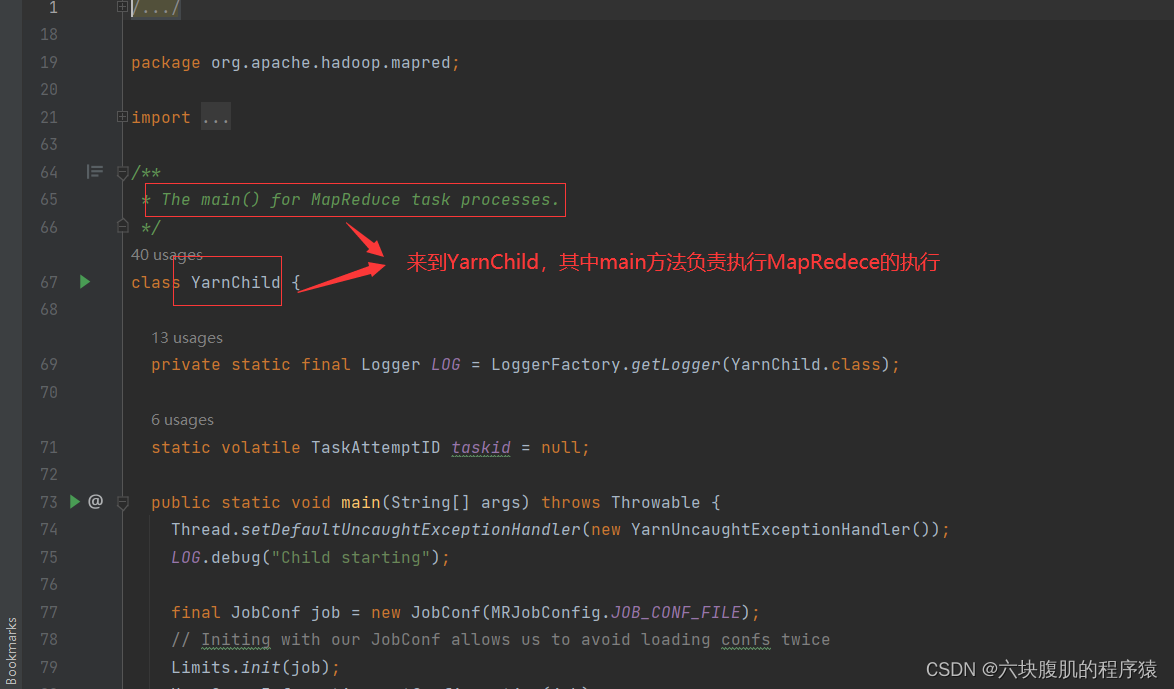
查看main方法
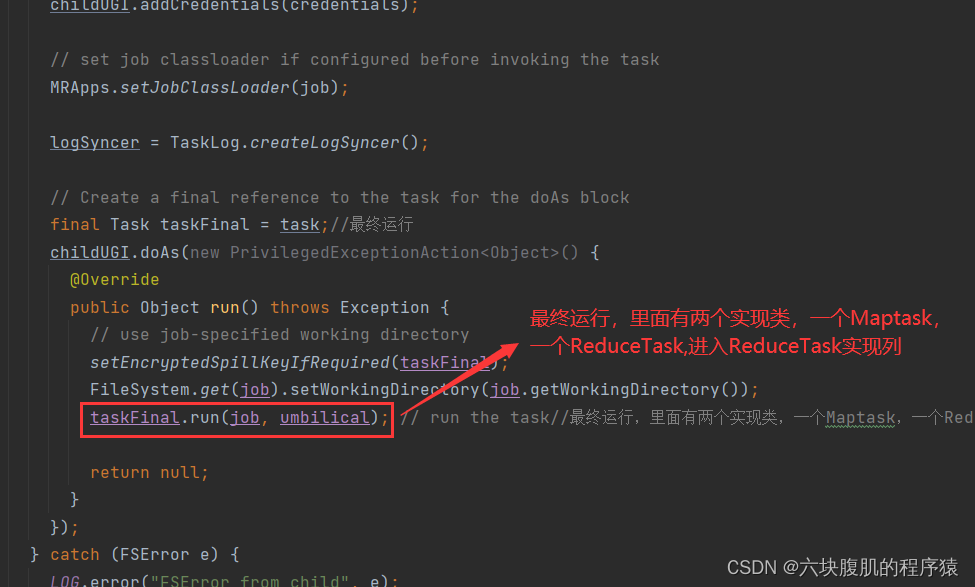
①查看Maptask的run方法
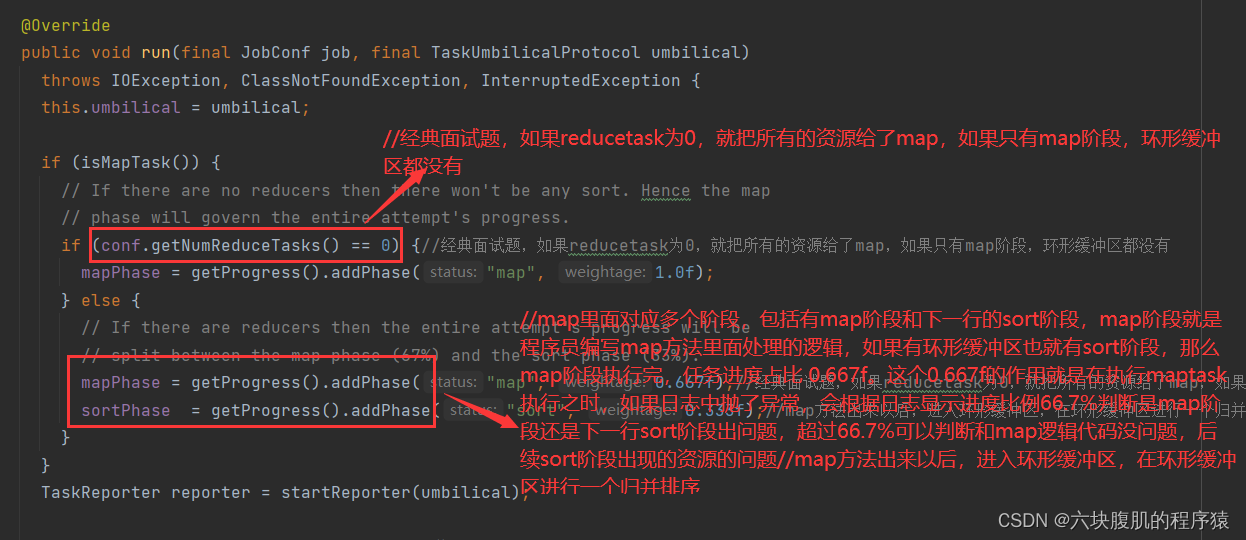
该方法继续往下看
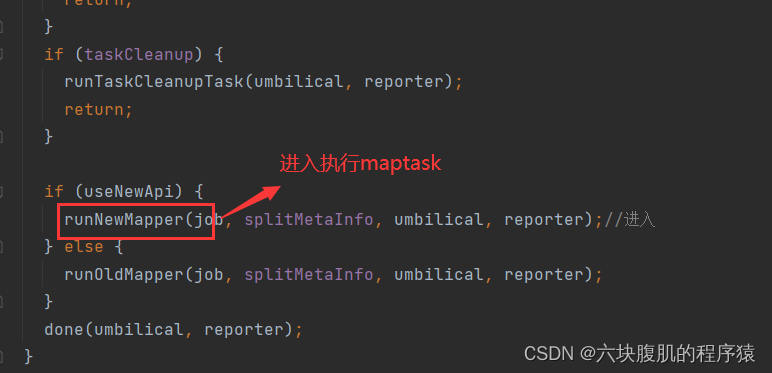
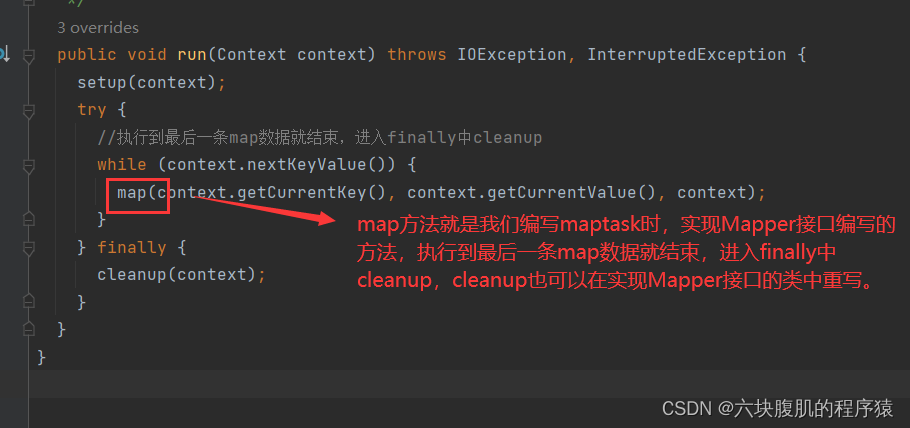
②回到上边此图部分,查看Reudcetask的run方法
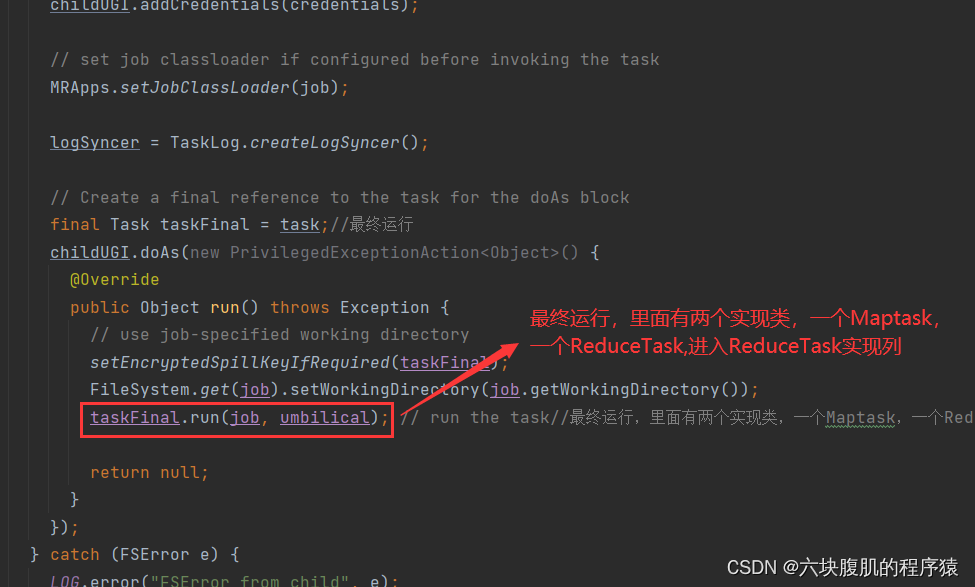
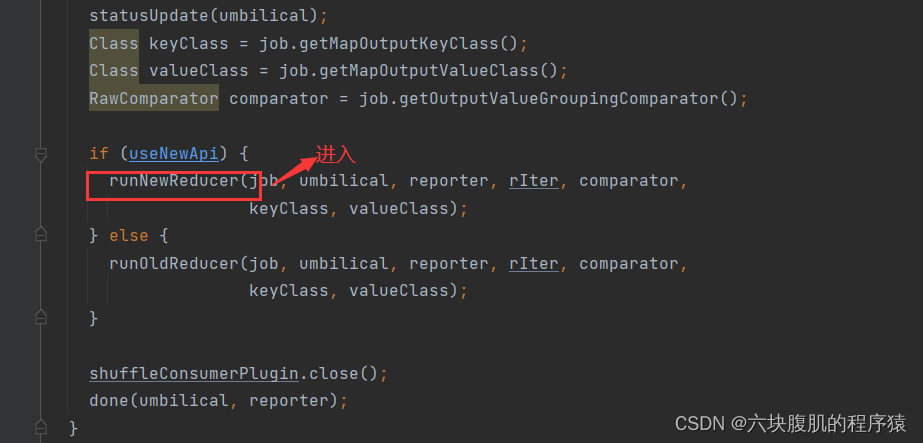
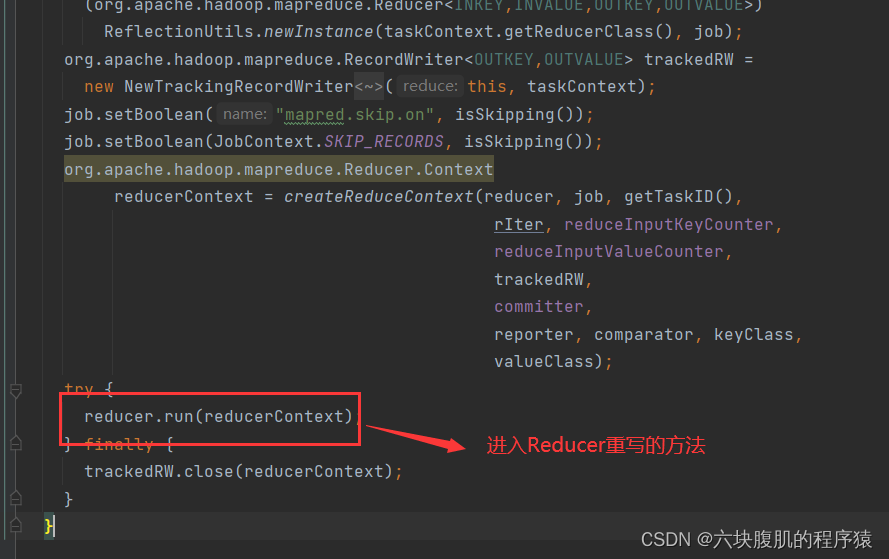
Yarn的ResourceManager负责开始maptask和reducetask的执行开启,接下来讲解mapreduce的执行源码
四、MapTask源码解析
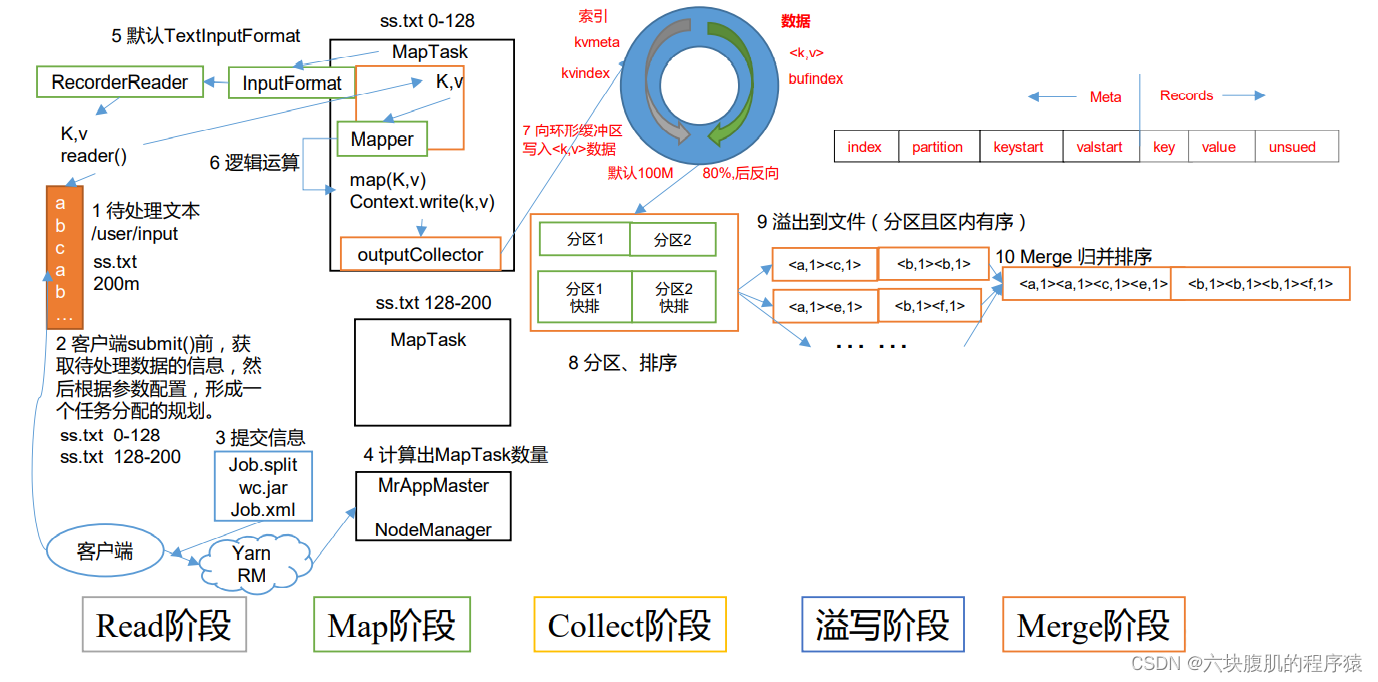
1.MapTask的工作机制
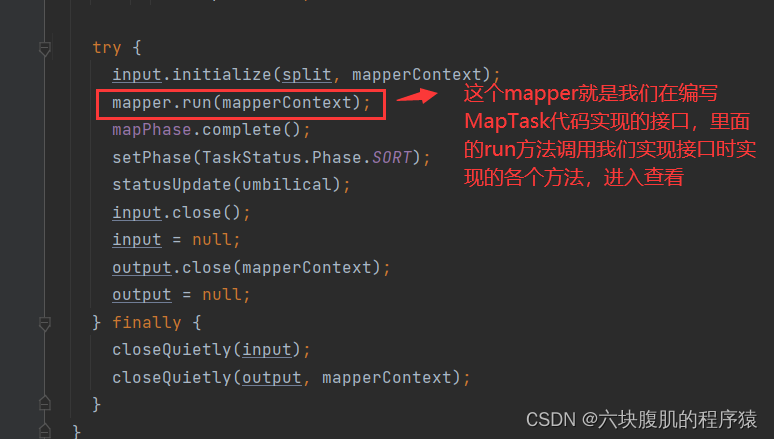
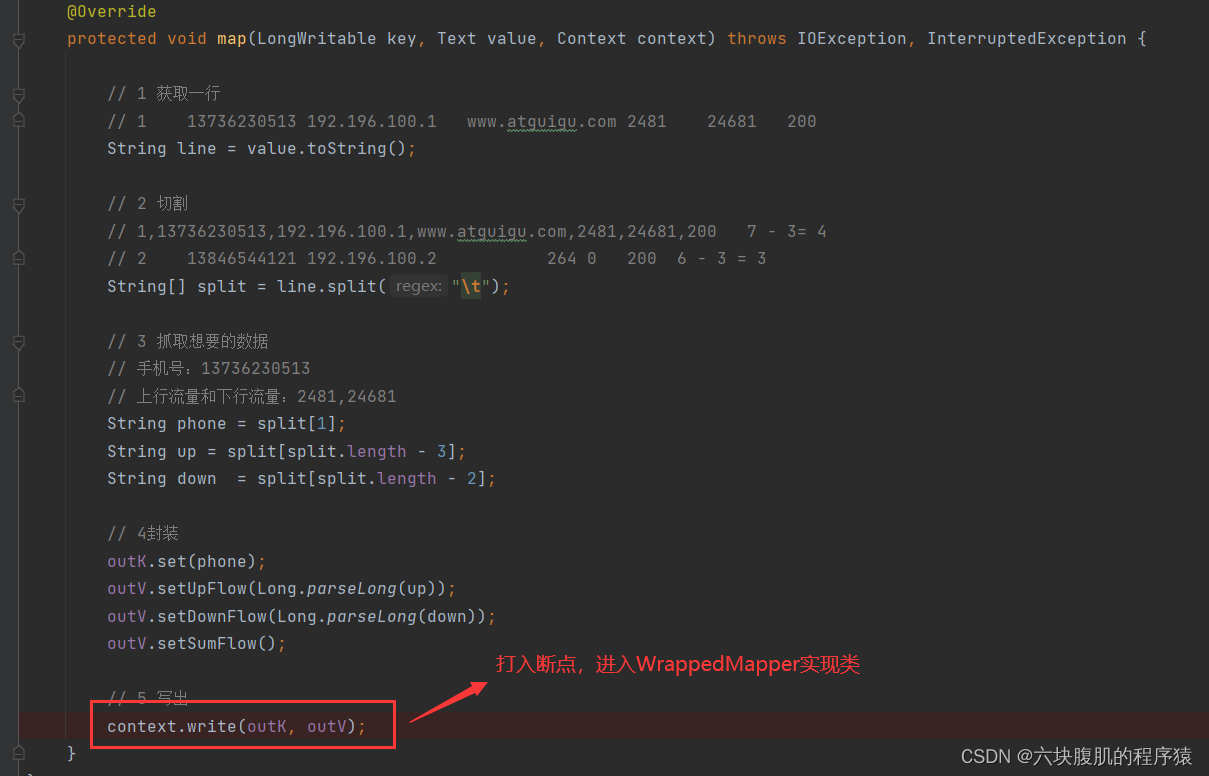
找到自己编写的mapreducetask的代码,从mapper类中context.write打入断点
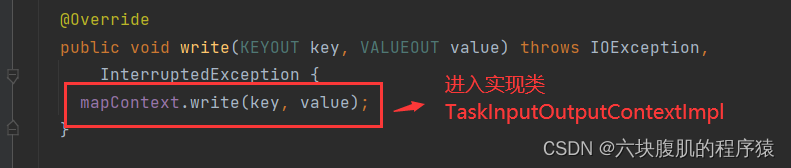
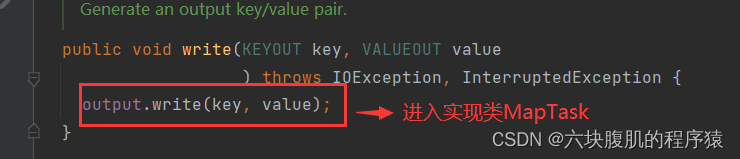
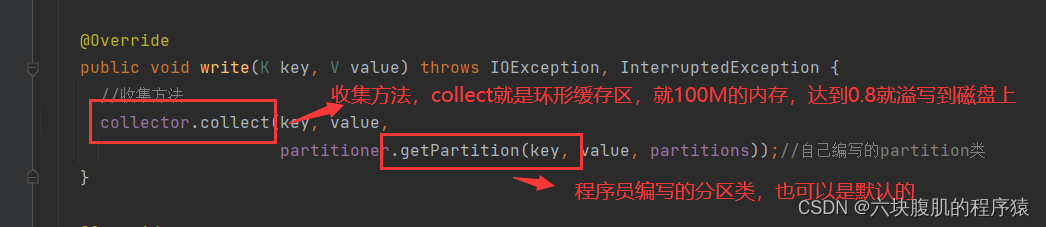
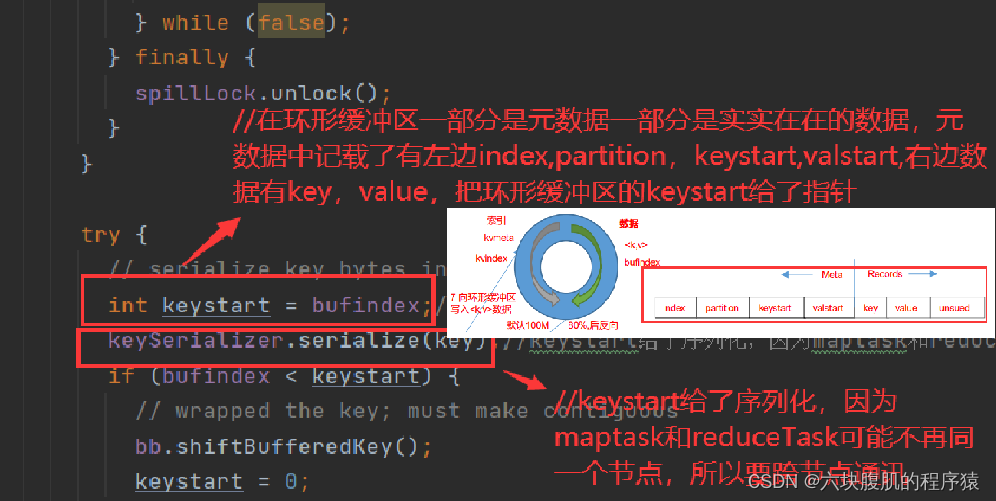
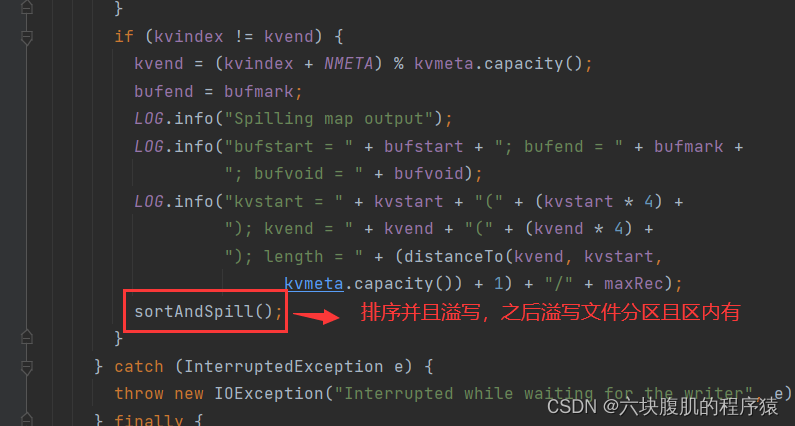
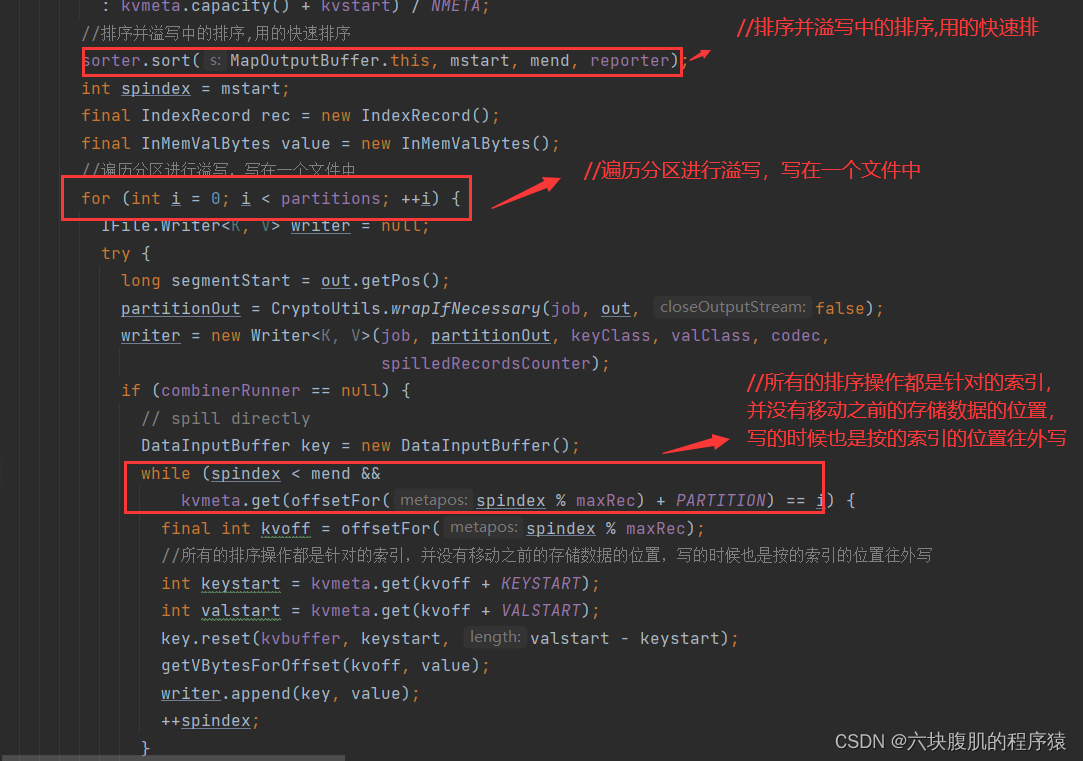
回到上一层flush方法
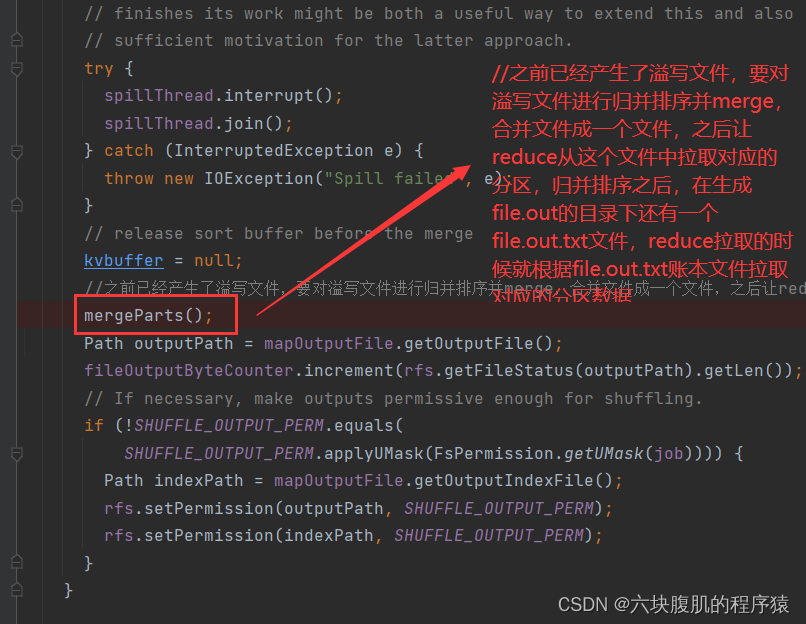
回到之前的close方法
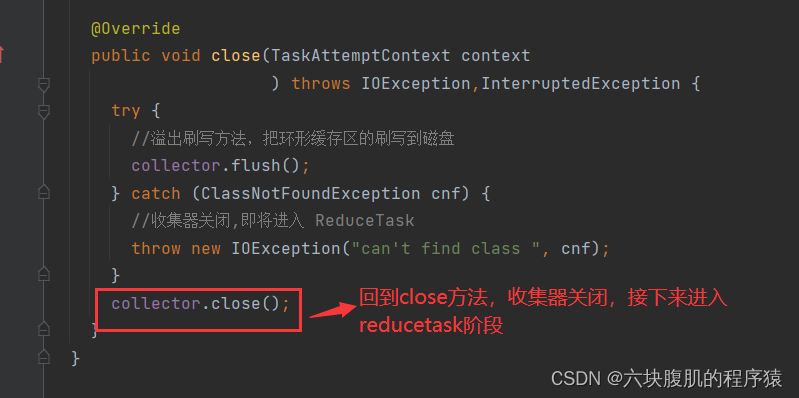
五、ReduceTask源码解析
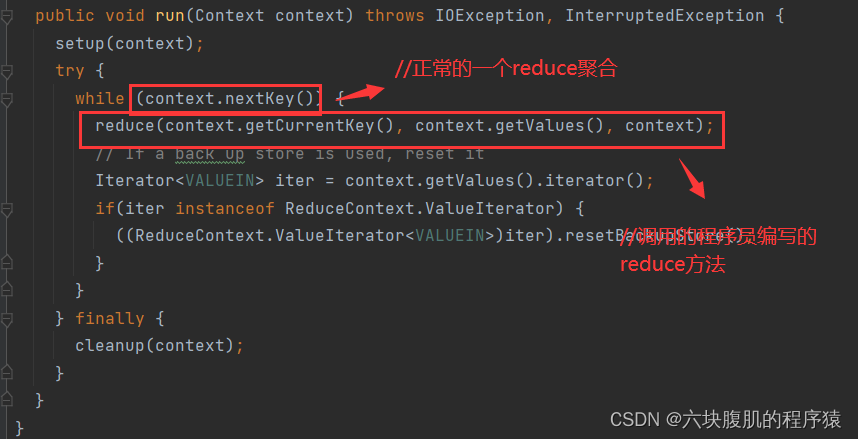
ReduceTask工作机制
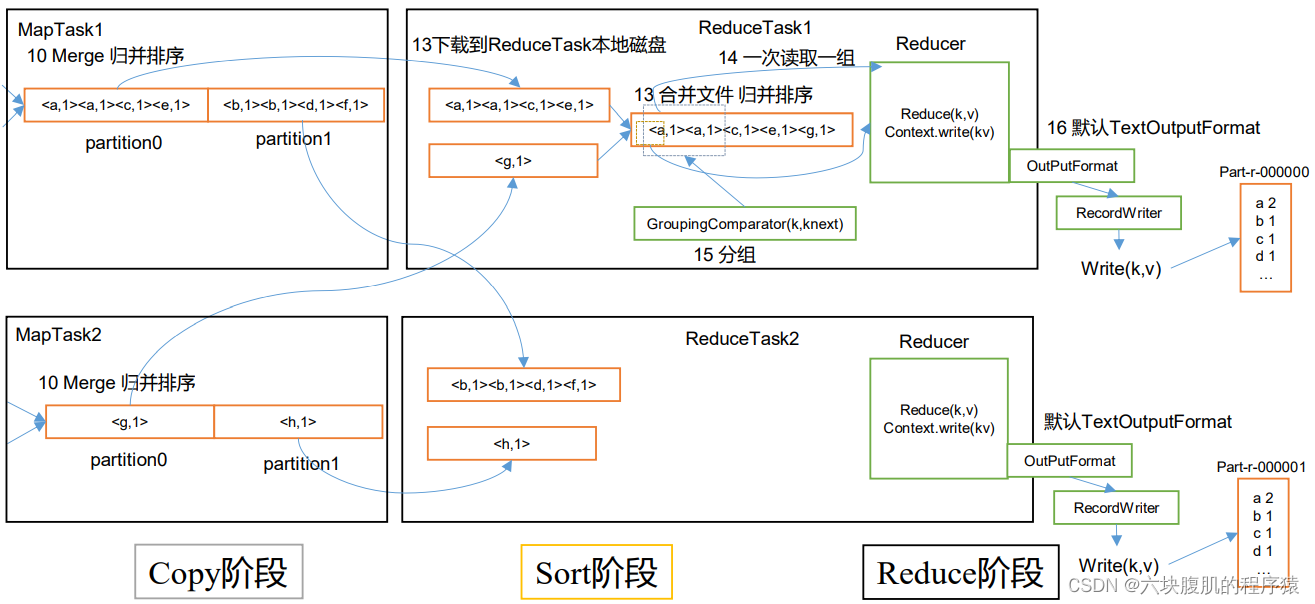
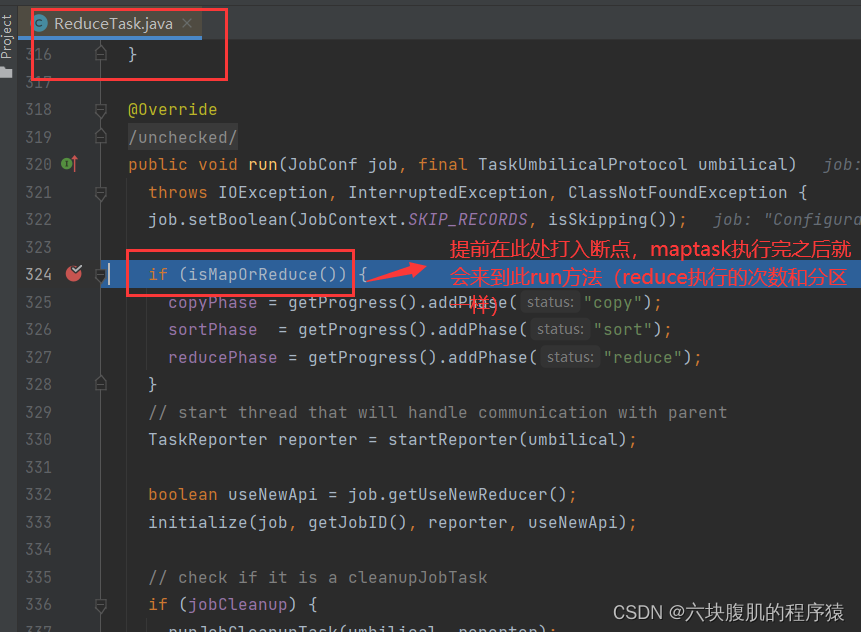
提前在ReduceTask的run方法中打入断点maptask执行完之后就开始执行reducetask
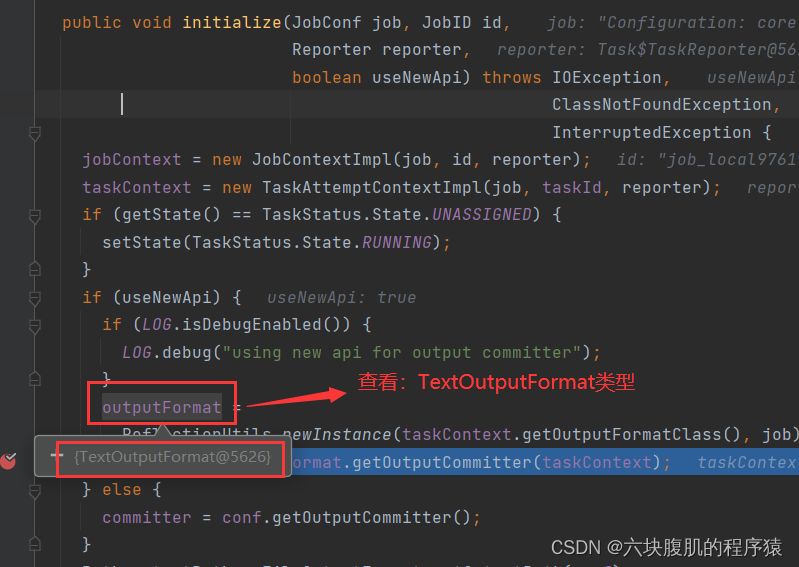
其中初始化了outputFormat对象
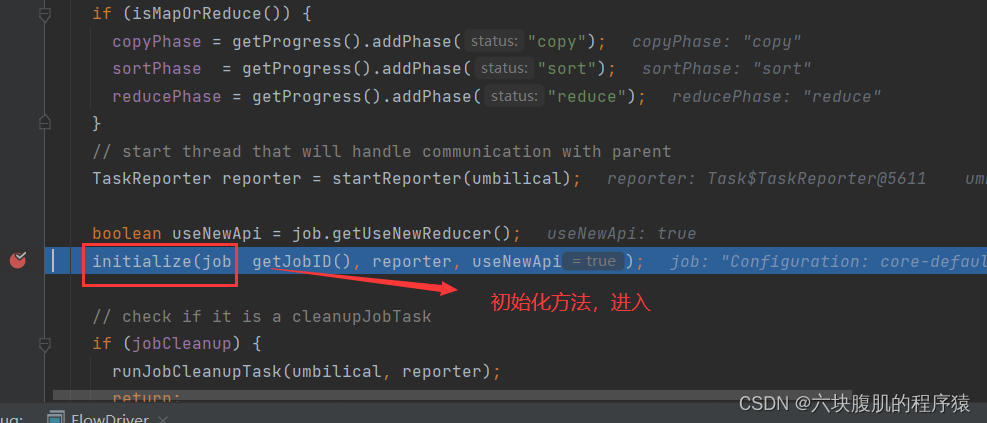
回到ReduceTask的run方法
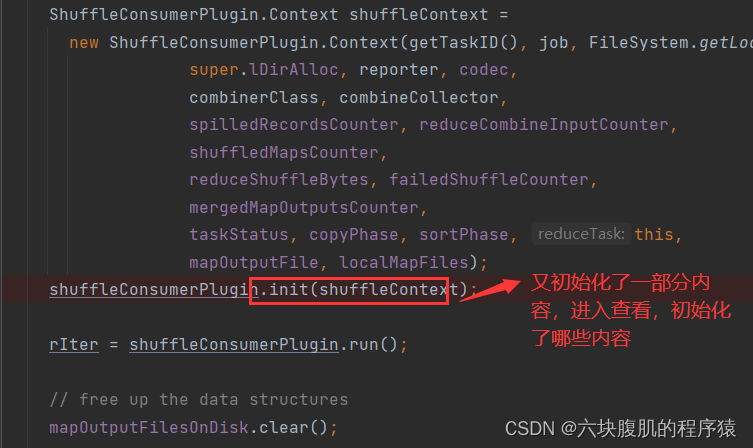
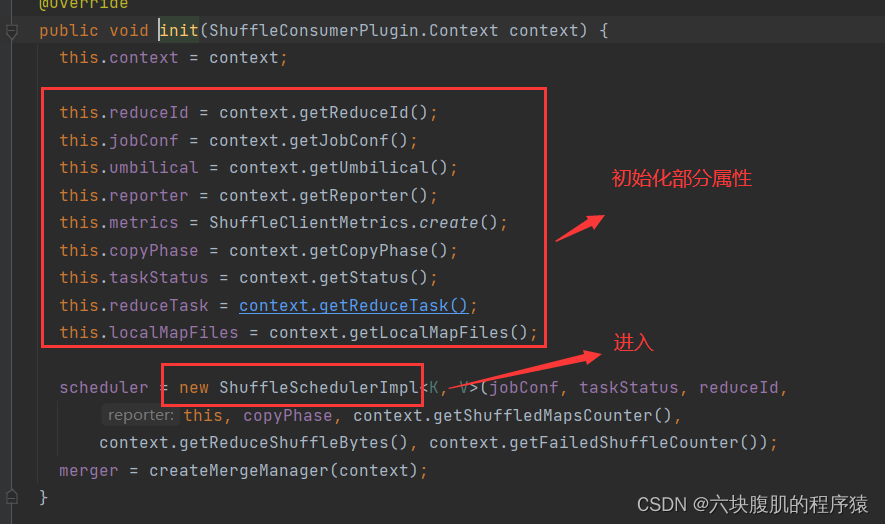
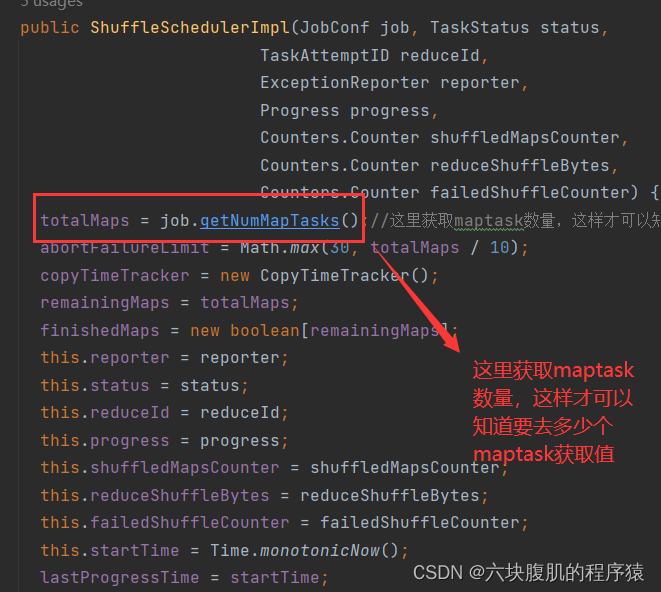
返回上一级方法
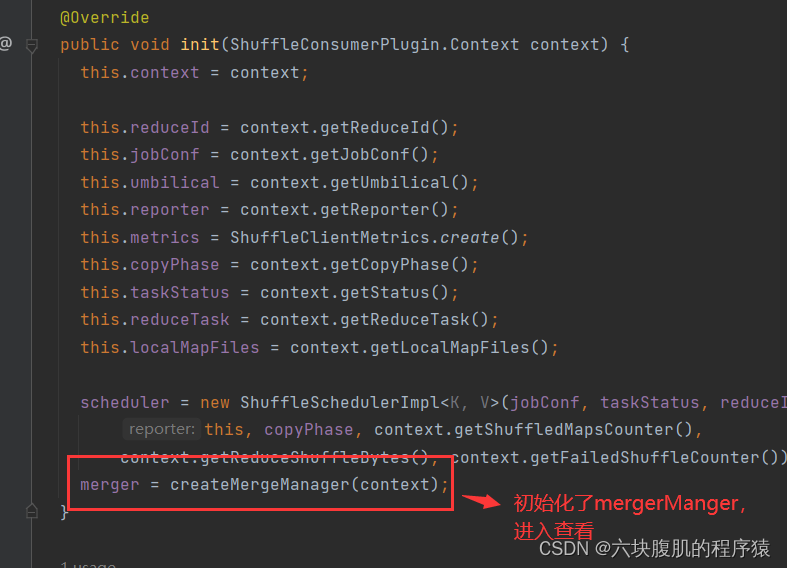
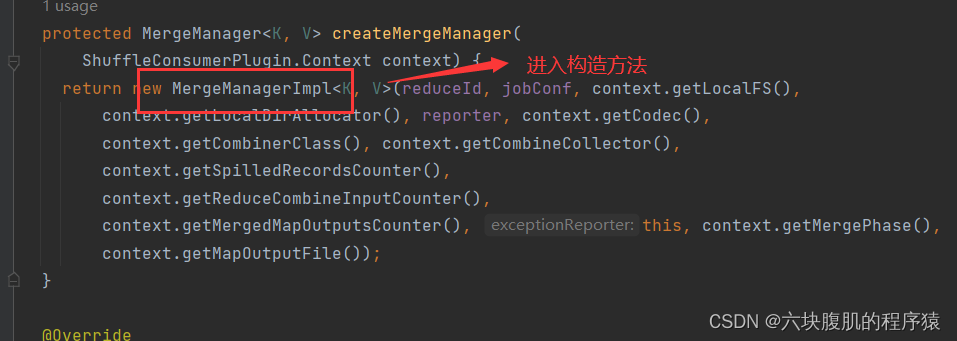
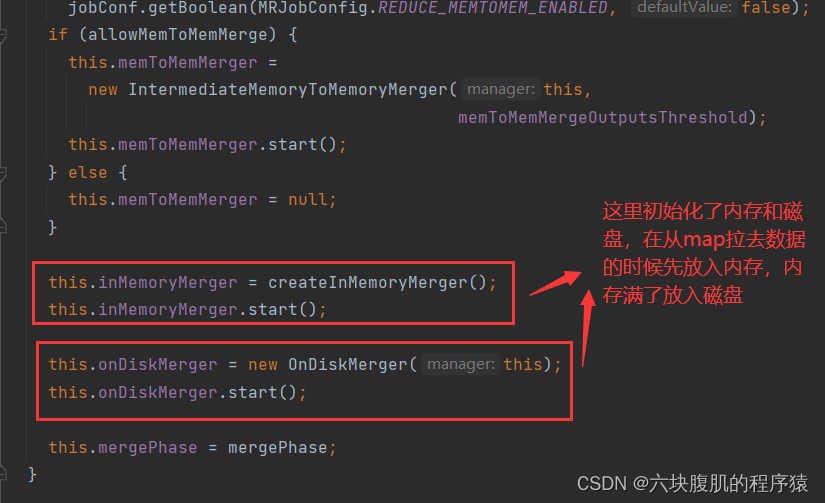
回到ReduceTask的run方法
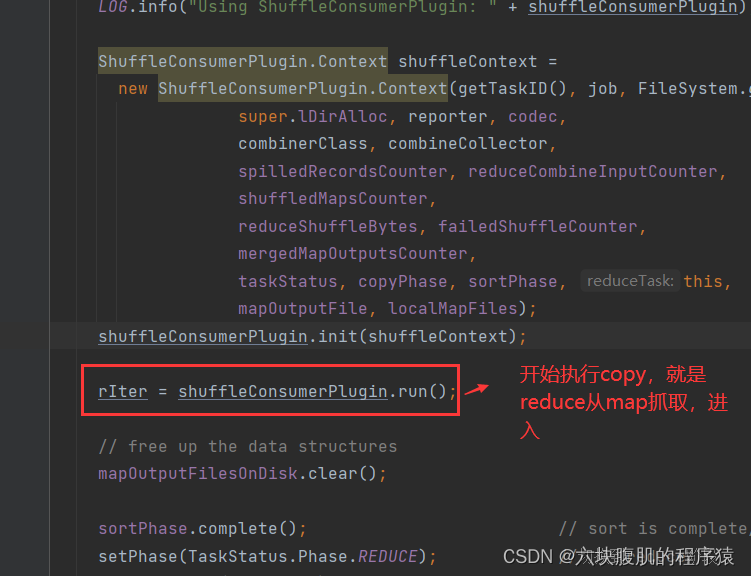
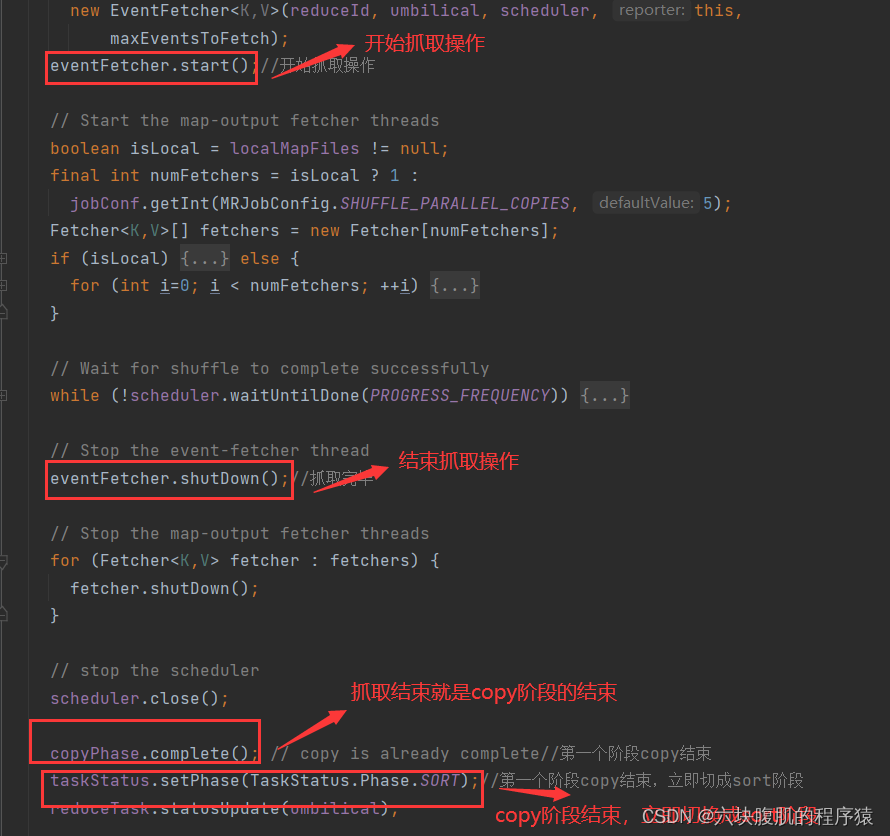
回到ReduceTask的run方法
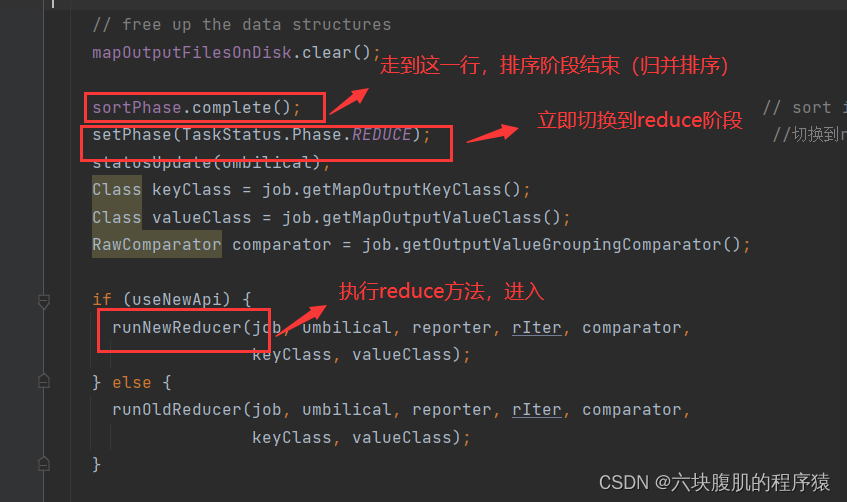
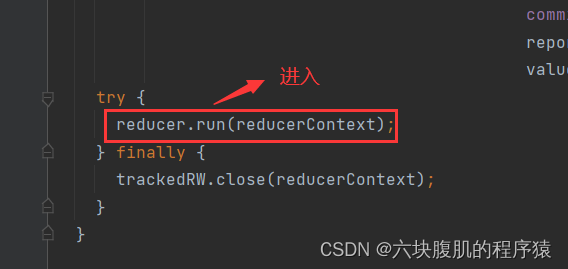
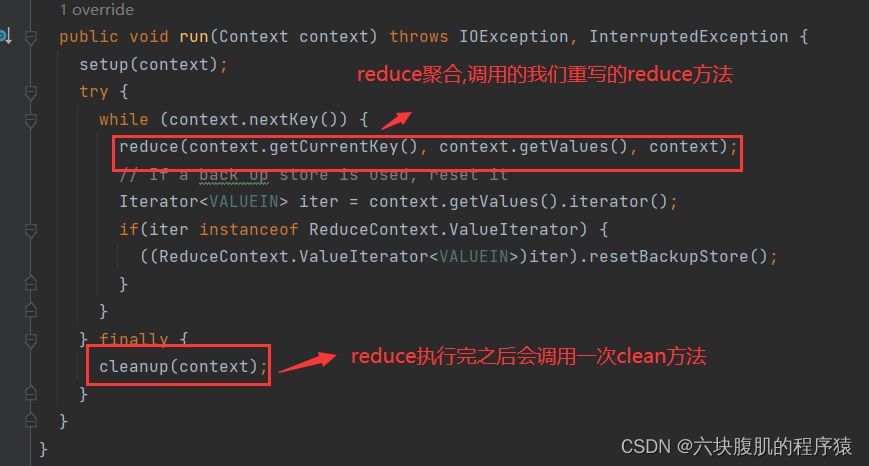
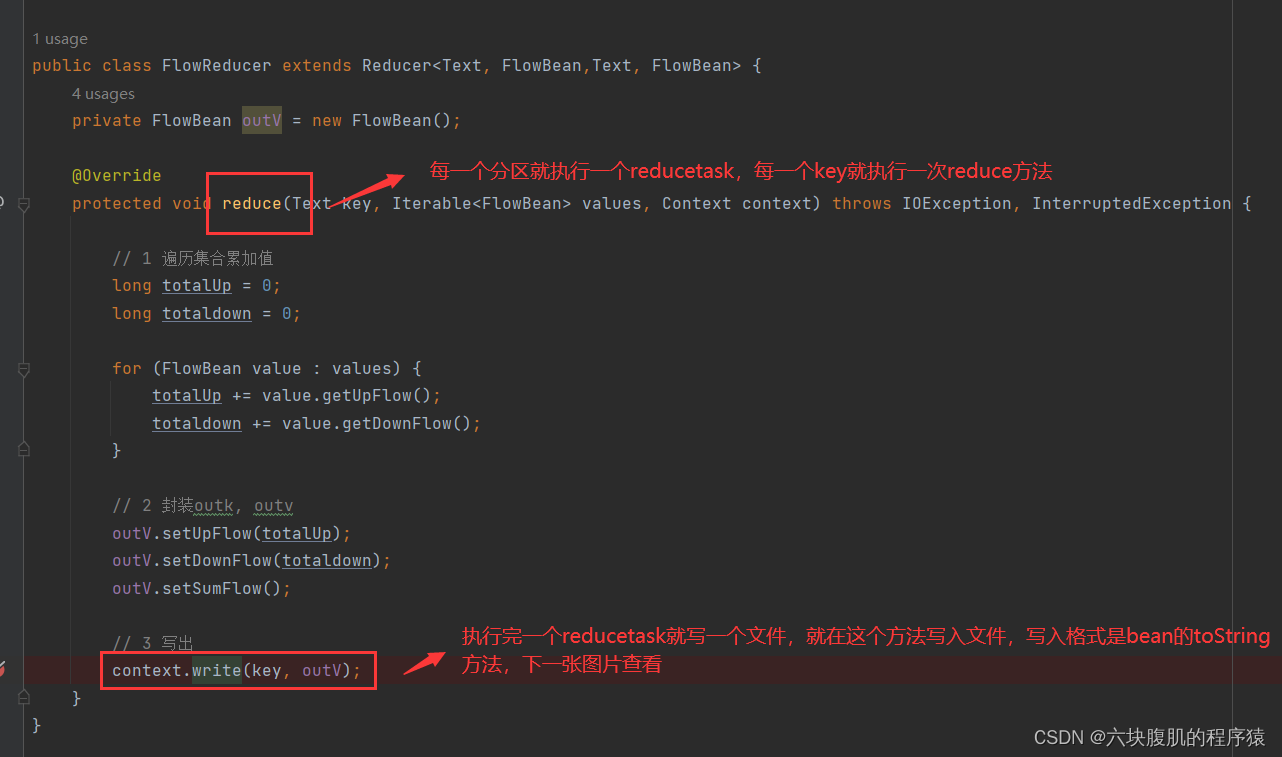
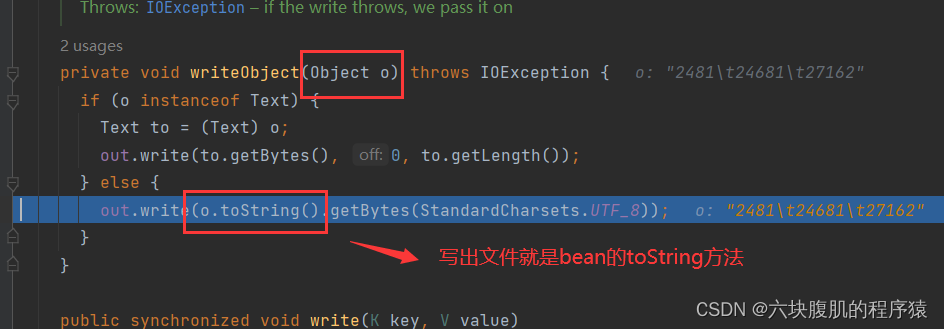
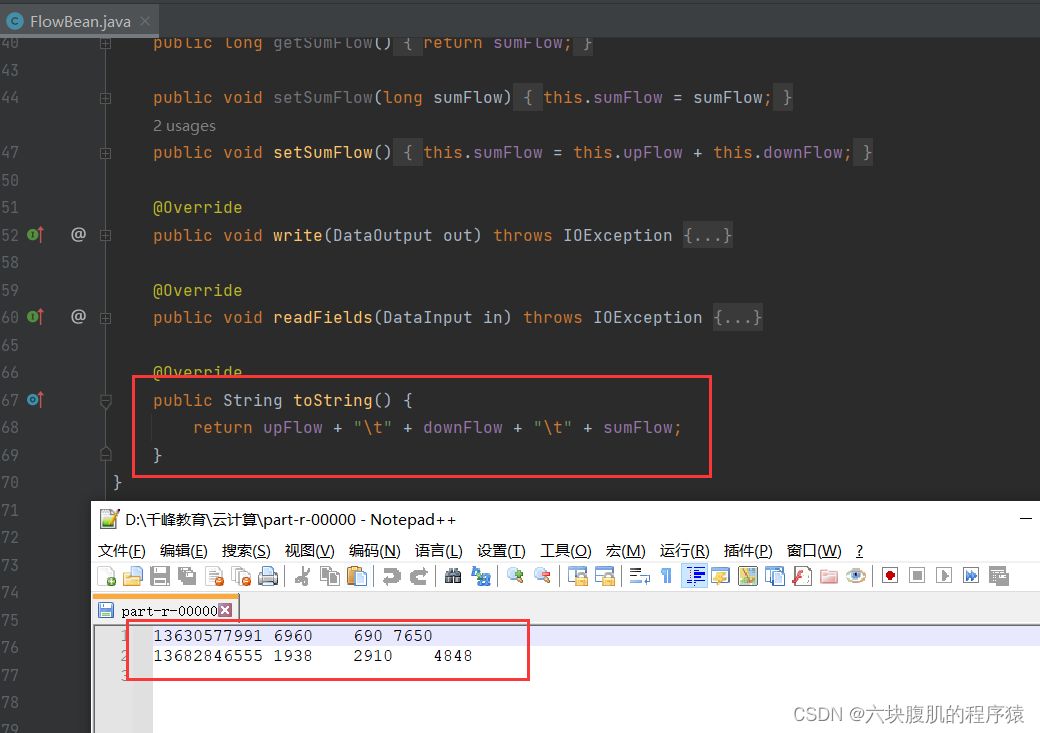
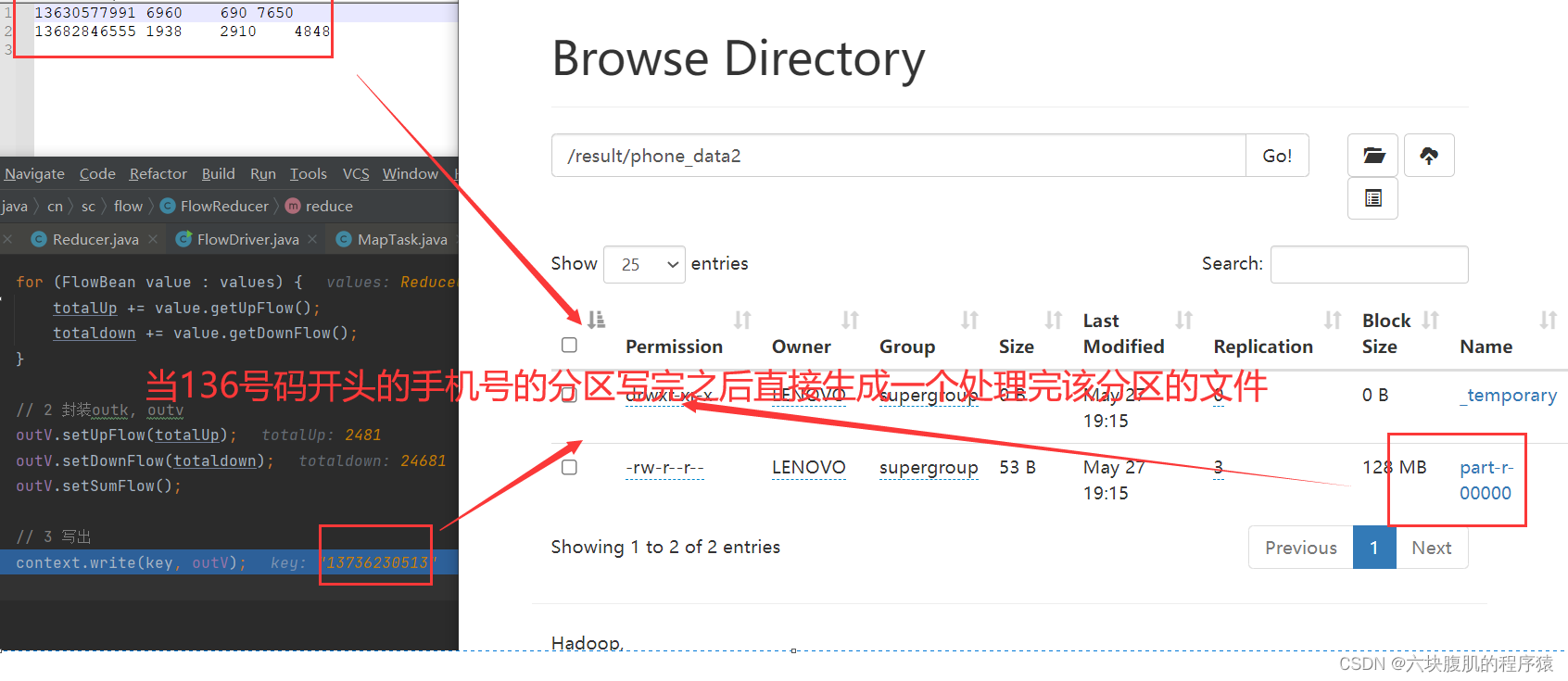
现在调用到我们编写的reduce方法