文章目录
Mysql中的数据类型
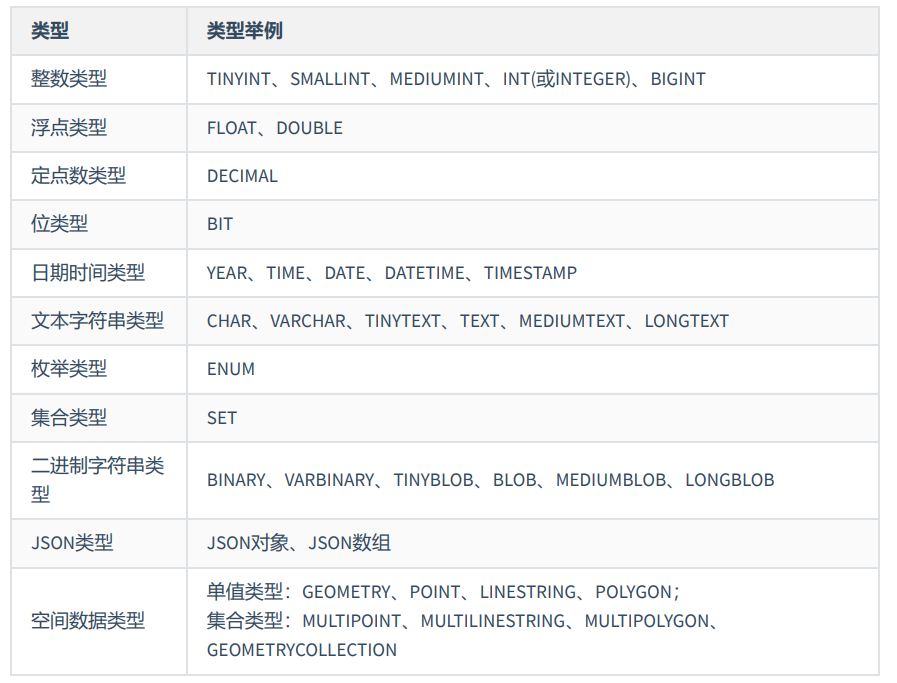
整数类型
为什么一个字节,无符号取值范围是0-255(256个数)因为一个字节是8位,每位可以有两个选择0和1,所以8位的话就有2的8次方中组合对应十进制就是256个元素

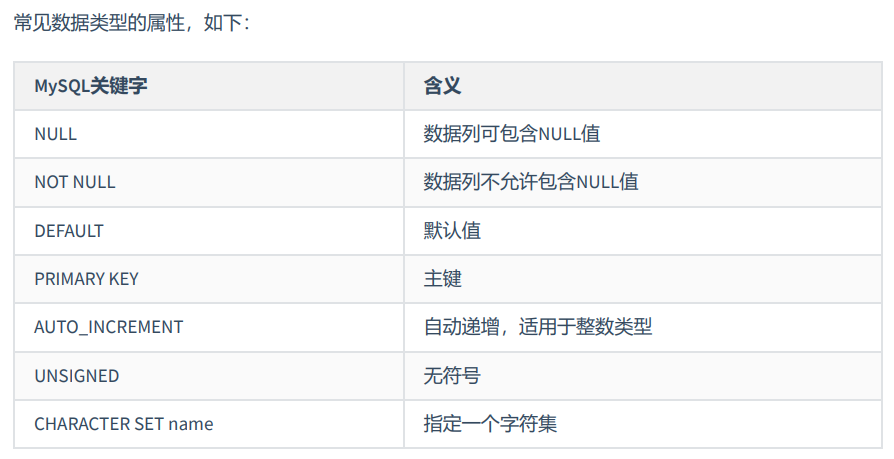
可选属性
整数类型的可选属性有三个:
M
M:的意思是表示显示宽度,M的取值范围是(0, 255)。例如,int(5):当数据宽度小于5位的时候在数字前面需要用 字符填满宽度。该项功能需要配合“ ZEROFILL ”使用,表示用“0”填满宽度,否则指定显示宽度无效。
如果设置了显示宽度,那么插入的数据宽度超过显示宽度限制,会不会截断或插入失败?
答案:不会对插入的数据有任何影响,还是按照类型的实际宽度进行保存,即显示宽度与类型可以存储的值范围无关 。从MySQL 8.0.17开始,整数数据类型不推荐使用显示宽度属性。
举例:
CREATE TABLE test_int1 ( x TINYINT, y SMALLINT, z MEDIUMINT, m INT, n BIGINT );
查看表结构 (MySQL5.7中显式如下,MySQL8中不再显式范围)
mysql> desc test_int1;
+-------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+-------+
| x | tinyint(4) | YES | | NULL | |
| y | smallint(6) | YES | | NULL | |
| z | mediumint(9) | YES | | NULL | |
| m | int(11) | YES | | NULL | |
| n | bigint(20) | YES | | NULL | |
+-------+--------------+------+-----+---------+-------+
5 rows in set (0.00 sec)
TINYINT有符号数和无符号数的取值范围分别为-128-127和0~255,TINYINT默认的显示宽度为4。这里的4指的就是位数- 1 2 8四位,其他的也是类似,默认显示宽度与其有符号数的最小值的宽度相同
这个显示宽度一般和ZEROFILL联合使用,如果你指定了显示宽度数据没达到设置的宽度,它会自动通过0来补全
CREATE TABLE test_int2(
f1 INT,
f2 INT(5),
f3 INT(5) ZEROFILL
)
DESC test_int2;
INSERT INTO test_int2(f1,f2,f3)
VALUES(1,123,123);
INSERT INTO test_int2(f1,f2)
VALUES(123456,123456);
INSERT INTO test_int2(f1,f2,f3)
VALUES(123456,123456,123456);
+--------+--------+--------+
| f1 | f2 | f3 |
+--------+--------+--------+
| 1 | 123 | 00123 |
| 123456 | 123456 | NULL |
| 123456 | 123456 | 123456 |
+--------+--------+--------+
UNSIGNED
UNSIGNED : 无符号类型(非负),所有的整数类型都有一个可选的属性UNSIGNED(无符号属性),无符号整数类型的最小取值为0。所以,如果需要在MySQL数据库中保存非负整数值时,可以将整数类型设 置为无符号类型。
int类型默认显示宽度为int(11),无符号int类型默认显示宽度为int(10)。
有符号数什么意思呢?
就是说符号(“+”,“-”)占据一位
int型默认显示宽度为显示11位,那无符号数其实就是没有符号位,那它表示的就都是正数,所以减去一位符号位就剩10位了
CREATE TABLE test_int3(
f1 INT UNSIGNED
);
mysql> desc test_int3;
+-------+------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+------------------+------+-----+---------+-------+
| f1 | int(10) unsigned | YES | | NULL | |
+-------+------------------+------+-----+---------+-------+
1 row in set (0.00 sec)
ZEROFILL
ZEROFILL : 0填充,(如果某列是ZEROFILL,那么MySQL会自动为当前列添加UNSIGNED属性),如果指 定了ZEROFILL只是表示不够M位时,用0在左边填充,如果超过M位,只要不超过数据存储范围即可。
原来,在 int(M) 中,M 的值跟 int(M) 所占多少存储空间并无任何关系。 **int(3)、int(4)、int(8) 在磁盘上都 是占用 4 bytes 的存储空间,数字只是表示的为显示的宽度。**也就是说,int(M),必须和UNSIGNED ZEROFILL一起使用才有意义。如果整 数值超过M位,就按照实际位数存储。只是无须再用字符 0 进行填充。
适用场景

如何选择?

浮点类型
浮点数和定点数类型的特点是可以 处理小数 ,你可以把整数看成小数的一个特例。因此,浮点数和定点 数的使用场景,比整数大多了。 MySQL支持的浮点数类型,分别是 FLOAT、DOUBLE、REAL。
- FLOAT 表示单精度浮点数
- DOUBLE 表示双精度浮点数

FLOAT 和 DOUBLE 这两种数据类型的区别是啥呢?
FLOAT 占用字节数少,取值范围小;DOUBLE 占用字节数多,取值范围也大
为什么浮点数类型的无符号数取值范围,只相当于有符号数取值范围的一半,也就是只相当于 有符号数取值范围大于等于零的部分呢?
MySQL 存储浮点数的格式为: 符号(S) 、 尾数(M) 和 阶码(E) 。因此,无论有没有符号,MySQL 的浮 点数都会存储表示符号的部分。因此, 所谓的无符号数取值范围,其实就是有符号数取值范围大于等于 零的部分。
数据精度说明
对于浮点类型,在MySQL中单精度值使用 4 个字节,双精度值使用 8 个字节。

CREATE TABLE test_double1(
f1 FLOAT,
f2 FLOAT(5,2),
f3 DOUBLE,
f4 DOUBLE(5,2)
);
INSERT INTO test_double1
VALUES(123.456,123.456,123.4567,123.45);
SELECT * FROM test_double1;
超出标度会自动进位
mysql> SELECT * FROM test_double1;
+---------+--------+----------+--------+
| f1 | f2 | f3 | f4 |
+---------+--------+----------+--------+
| 123.456 | 123.46 | 123.4567 | 123.45 |
+---------+--------+----------+--------+
1 row in set (0.00 sec)
精度误差说明
浮点数类型有个缺陷,就是不精准
0.47 + 0.44 + 0.19 = 1.1
CREATE TABLE test_double2(
f1 DOUBLE
);
INSERT INTO test_double2
VALUES(0.47),(0.44),(0.19);
mysql> SELECT SUM(f1)
-> FROM test_double2;
+--------------------+
| SUM(f1) |
+--------------------+
| 1.0999999999999999 |
+--------------------+
1 row in set (0.00 sec)
mysql> SELECT SUM(f1) = 1.1,1.1 = 1.1
-> FROM test_double2;
+---------------+-----------+
| SUM(f1) = 1.1 | 1.1 = 1.1 |
+---------------+-----------+
| 0 | 1 |
+---------------+-----------+
1 row in set (0.00 sec)
查询结果是 1.0999999999999999。看到了吗?虽然误差很小,但确实有误差。 你也可以尝试把数据类型 改成 FLOAT,然后运行求和查询,得到的是, 1.0999999940395355。显然,误差更大了。
为什么会出现这样的问题呢?
MySQL 用 4 个字节存储 FLOAT 类型数据,用 8 个字节来存储 DOUBLE 类型数据。无论哪个,都是采用二 进制的方式来进行存储的。比如 9.625,用二进制来表达,就是 1001.101,或者表达成 1.001101×2^3。如 果尾数不是 0 或 5(比如 9.624),你就无法用一个二进制数来精确表达。进而,就只好在取值允许的范 围内进行四舍五入。
在编程中,如果用到浮点数,要特别注意误差问题,因为浮点数是不准确的,所以我们要避免使用“=”来 判断两个数是否相等。同时,在一些对精确度要求较高的项目中,千万不要使用浮点数,不然会导致结 果错误,甚至是造成不可挽回的损失。那么,MySQL 有没有精准的数据类型呢?当然有,这就是定点数 类型: DECIMAL 。
定点数类型
类型介绍
MySQL中的定点数类型只有 DECIMAL 一种类型。
| 数据类型 | 字节数 | 含义 |
|---|---|---|
| DECIMAL(M,D),DEC,NUMERIC | M+2字节 | 有效范围由M和D决定 |
-
使用 DECIMAL(M,D) 的方式表示高精度小数。其中,M被称为精度,D被称为标度。0<=M<=65, 0<=D<=30,D
-
DECIMAL(M,D)的最大取值范围与DOUBLE类型一样,但是有效的数据范围是由M和D决定的。 DECIMAL 的存储空间并不是固定的,由精度值M决定,总共占用的存储空间为M+2个字节。也就是 说,在一些对精度要求不高的场景下,比起占用同样字节长度的定点数,浮点数表达的数值范围可 以更大一些。
-
定点数在MySQL内部是以
字符串的形式进行存储,这就决定了它一定是精准的 -
当DECIMAL类型不指定精度和标度时,其默认为DECIMAL(10,0)。当数据的精度超出了定点数类型的 精度范围时,则MySQL同样会进行四舍五入处理。
-
浮点数 vs 定点数
- 浮点数相对于定点数的优点是在长度一定的情况下,浮点类型取值范围大,但是不精准,适用 于需要取值范围大,又可以容忍微小误差的科学计算场景(比如计算化学、分子建模、流体动 力学等)
- 定点数类型取值范围相对小,但是精准,没有误差,适合于对精度要求极高的场景 (比如涉 及金额计算的场景)
-
举例
CREATE TABLE test_decimal1(
f1 DECIMAL,
f2 DECIMAL(5,2)
);
INSERT INTO test_decimal1(f1,f2)
VALUES(123.123,123.456);
mysql> SELECT * FROM test_decimal1;
+------+--------+
| f1 | f2 |
+------+--------+
| 123 | 123.46 |
+------+--------+
1 row in set (0.00 sec)
由于 DECIMAL 数据类型的精准性,在我们的项目中,除了极少数(比如商品编号)用到整数类型 外,其他的数值都用的是 DECIMAL,原因就是这个项目所处的零售行业,要求精准,一分钱也不能 差
位类型:BIT

CREATE TABLE test_bit1(
f1 BIT,
f2 BIT(5),
f3 BIT(64)
);
INSERT INTO test_bit1(f1)
VALUES(1);
#Data too long for column 'f1' at row 1
INSERT INTO test_bit1(f1)
VALUES(2);
INSERT INTO test_bit1(f2)
VALUES(23);
在向BIT类型的字段中插入数据时,一定要确保插入的数据在BIT类型支持的范围内
日期与时间类型

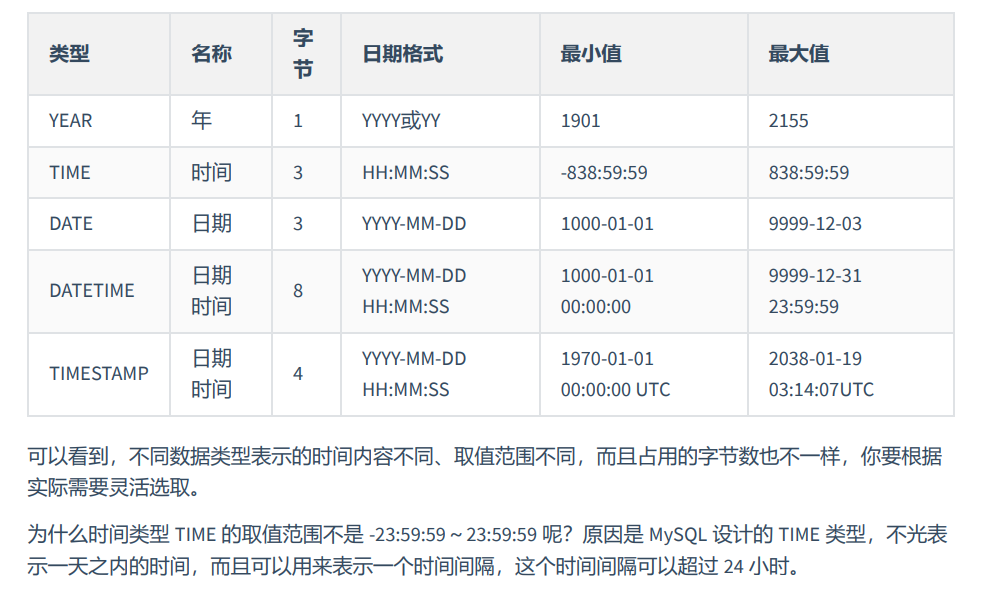
YEAR类型

CREATE TABLE test_year(
f1 YEAR,
f2 YEAR(4)
);
mysql> DESC test_year;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| f1 | year(4) | YES | | NULL | |
| f2 | year(4) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
2 rows in set (0.00 sec)
INSERT INTO test_year
VALUES('2020','2021');
mysql> SELECT * FROM test_year;
+------+------+
| f1 | f2 |
+------+------+
| 2020 | 2021 |
+------+------+
1 rows in set (0.00 sec)
INSERT INTO test_year
VALUES('45','71');
INSERT INTO test_year
VALUES(0,'0');
mysql> SELECT * FROM test_year;
+------+------+
| f1 | f2 |
+------+------+
| 2020 | 2021 |
| 2045 | 1971 |
| 0000 | 2000 |
+------+------+
3 rows in set (0.00 sec)
DATE类型

CREATE TABLE test_date1(
f1 DATE
);
Query OK, 0 rows affected (0.13 sec)
INSERT INTO test_date1
VALUES ('2020-10-01'), ('20201001'),(20201001);
INSERT INTO test_date1
VALUES ('00-01-01'), ('000101'), ('69-10-01'), ('691001'), ('70-01-01'), ('700101'),
('99-01-01'), ('990101');
INSERT INTO test_date1
VALUES (000301), (690301), (700301), (990301);
INSERT INTO test_date1
VALUES (CURRENT_DATE()), (NOW());
SELECT *
FROM test_date1;
mysql> SELECT *
-> FROM test_date1;
+------------+
| f1 |
+------------+
| 2020-10-01 |
| 2020-10-01 |
| 2020-10-01 |
| 2000-01-01 |
| 2000-01-01 |
| 2069-10-01 |
| 2069-10-01 |
| 1970-01-01 |
| 1970-01-01 |
| 1999-01-01 |
| 1999-01-01 |
| 2000-03-01 |
| 2069-03-01 |
| 1970-03-01 |
| 1999-03-01 |
| 2022-07-28 |
| 2022-07-28 |
+------------+
TIME类型
别写的花里胡哨的,就按照标准的来写
HH:MM:SS

CREATE TABLE test_time1(
f1 TIME
);
Query OK, 0 rows affected (0.02 sec)
INSERT INTO test_time1
VALUES('2 12:30:29'), ('12:35:29'), ('12:40'), ('2 12:40'),('1 05'), ('45');
INSERT INTO test_time1
VALUES ('123520'), (124011),(1210);
INSERT INTO test_time1
VALUES (NOW()), (CURRENT_TIME());
SELECT * FROM test_time1;
mysql> SELECT * FROM test_time1;
+----------+
| f1 |
+----------+
| 60:30:29 |
| 12:35:29 |
| 12:40:00 |
| 60:40:00 |
| 29:00:00 |
| 00:00:45 |
| 12:35:20 |
| 12:40:11 |
| 00:12:10 |
| 21:57:29 |
| 21:57:29 |
+----------+
11 rows in set (0.00 sec)
DATETIME类型
同上,不写的花里胡哨的就行

TIMESTAMP类型

TIMESTAMP和DATETIME的区别:
- TIMESTAMP存储空间比较小,表示的日期时间范围也比较小
- 底层存储方式不同,TIMESTAMP底层存储的是毫秒值,距离1970-1-1 0:0:0 0毫秒的毫秒值。
- 两个日期比较大小或日期计算时,TIMESTAMP更方便、更快。
- TIMESTAMP和时区有关。TIMESTAMP会根据用户的时区不同,显示不同的结果。而DATETIME则只能
- 反映出插入时当地的时区,其他时区的人查看数据必然会有误差的。
开发中经验
用得最多的日期时间类型,就是 DATETIME
在实际项目中,尽量用 DATETIME 类型。因为这个数据类型 包括了完整的日期和时间信息,取值范围也最大,使用起来比较方便。毕竟,如果日期时间信息分散在 好几个字段,很不容易记,而且查询的时候,SQL 语句也会更加复杂。
此外,一般存注册时间、商品发布时间等,不建议使用DATETIME存储,而是使用 时间戳 ,因为 DATETIME虽然直观,但不便于计算。
mysql> SELECT UNIX_TIMESTAMP();
+------------------+
| UNIX_TIMESTAMP() |
+------------------+
| 1635932762 |
+------------------+
1 row in set (0.00 sec)
这个就是表示1970年到现在的毫秒数
文本字符串类型
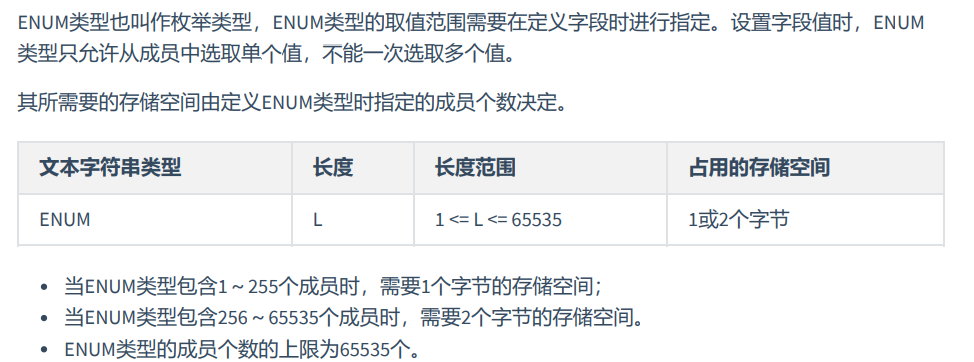
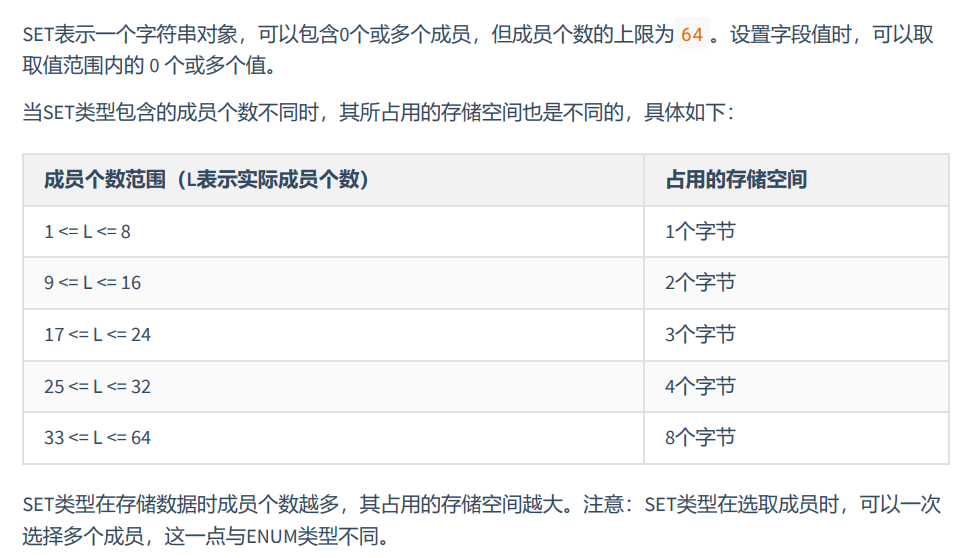
MySQL中,文本字符串总体上分为 CHAR 、 VARCHAR 、 TINYTEXT 、 TEXT 、 MEDIUMTEXT 、 LONGTEXT 、 ENUM 、 SET 等类型。
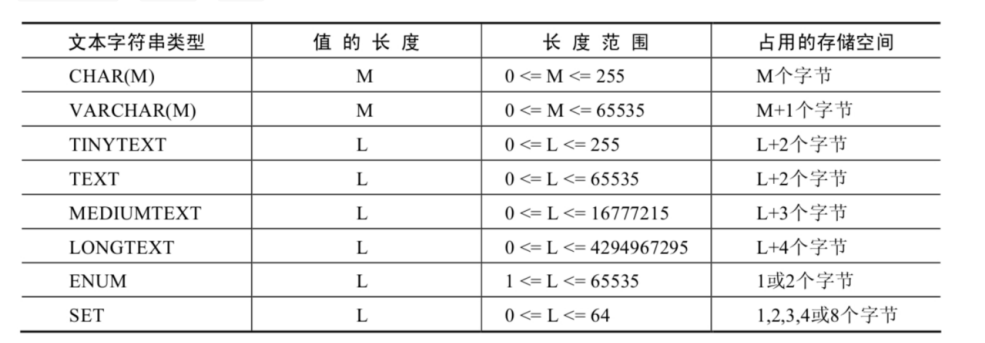
CHAR与VARCHAR类型

mysql> DESC test_char1;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| c1 | char(1) | YES | | NULL | |
| c2 | char(5) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
2 rows in set (0.00 sec)
设置的长度是几位就是几,多了就报错。这个和int(M)不一样,M是显示宽度一般配置ZEROFILL使用(显示宽度与类型可以存储的值范围无关)
mysql> INSERT INTO test_char1
-> VALUES('a','Tom456');
ERROR 1406 (22001): Data too long for column 'c2' at row 1
VARCHAR类型:
- VARCHAR(M) 定义时,
必须指定长度M,否则报错。 - MySQL4.0版本以下,varchar(20):指的是20字节,如果存放UTF8汉字时,只能存6个(每个汉字3字
- 节) ;MySQL5.0版本以上,varchar(20):指的是20字符。
- 检索VARCHAR类型的字段数据时,会保留数据尾部的空格。VARCHAR类型的字段所占用的存储空间
- 为字符串实际长度加1个字节。
哪些情况使用 CHAR 或 VARCHAR 更好

情况1:存储很短的信息。比如门牌号码101,201……这样很短的信息应该用char,因为varchar还要占个 byte用于存储信息长度,本来打算节约存储的,结果得不偿失。
情况2:固定长度的。比如使用uuid作为主键,那用char应该更合适。因为他固定长度,varchar动态根据
长度的特性就消失了,而且还要占个长度信息。
情况3:十分频繁改变的column。因为varchar每次存储都要有额外的计算,得到长度等工作,如果一个
非常频繁改变的,那就要有很多的精力用于计算,而这些对于char来说是不需要的。
情况4:具体存储引擎中的情况:
MyISAM数据存储引擎和数据列:MyISAM数据表,最好使用固定长度(CHAR)的数据列代替可变长度(VARCHAR)的数据列。这样使得整个表静态化,从而使 数据检索更快 ,用空间换时间。MEMORY存储引擎和数据列:MEMORY数据表目前都使用固定长度的数据行存储,因此无论使用CHAR或VARCHAR列都没有关系,两者都是作为CHAR类型处理的。InnoDB存储引擎,建议使用VARCHAR类型。因为对于InnoDB数据表,内部的行存储格式并没有区分固定长度和可变长度列(所有数据行都使用指向数据列值的头指针),而且主要影响性能的因素是数据行使用的存储总量,由于char平均占用的空间多于varchar,所以除了简短并且固定长度的,其他考虑varchar。这样节省空间,对磁盘I/O和数据存储总量比较好。
TEXT类型

开发中经验:
TEXT文本类型,可以存比较大的文本段,搜索速度稍慢,因此如果不是特别大的内容,建议使用CHAR, VARCHAR来代替。还有TEXT类型不用加默认值,加了也没用。而且text和blob类型的数据删除后容易导致 “空洞”,使得文件碎片比较多,所以频繁使用的表不建议包含TEXT类型字段,建议单独分出去,单独用 一个表。
ENUM类型
CREATE TABLE test_enum(
season ENUM('春','夏','秋','冬','unknow')
);
INSERT INTO test_enum
VALUES('春'),('秋');
# 忽略大小写
INSERT INTO test_enum
VALUES('UNKNOW');
# 允许按照角标的方式获取指定索引位置的枚举值
# 相当于插入的就是元素对应的索引值,这里索引从1开始
INSERT INTO test_enum
VALUES('1'),(3);
# Data truncated for column 'season' at row 1
INSERT INTO test_enum
VALUES('ab');
# 当ENUM类型的字段没有声明为NOT NULL时,插入NULL也是有效的
INSERT INTO test_enum
VALUES(NULL);
SET类型
CREATE TABLE temp_mul(
gender ENUM('男','女'),
hobby SET('吃饭','睡觉','打豆豆','写代码')
);
INSERT INTO temp_mul VALUES('男','睡觉,打豆豆'); #成功
# Data truncated for column 'gender' at row 1
INSERT INTO temp_mul VALUES('男,女','睡觉,写代码'); #失败
# Data truncated for column 'gender' at row 1
INSERT INTO temp_mul VALUES('妖','睡觉,写代码');#失败
INSERT INTO temp_mul VALUES('男','睡觉,写代码,吃饭'); #成功
二进制字符串类型

CREATE TABLE test_binary1(
f1 BINARY,
f2 BINARY(3),
f4 VARBINARY(10)
);
INSERT INTO test_binary1(f1,f2)
VALUES('a','a');
INSERT INTO test_binary1(f1,f2)
VALUES('尚','尚');#失败
INSERT INTO test_binary1(f2,f4)
VALUES('ab','ab');
mysql> SELECT LENGTH(f2),LENGTH(f4)
-> FROM test_binary1;
+------------+------------+
| LENGTH(f2) | LENGTH(f4) |
+------------+------------+
| 3 | NULL |
| 3 | 2 |
+------------+------------+
2 rows in set (0.00 sec)
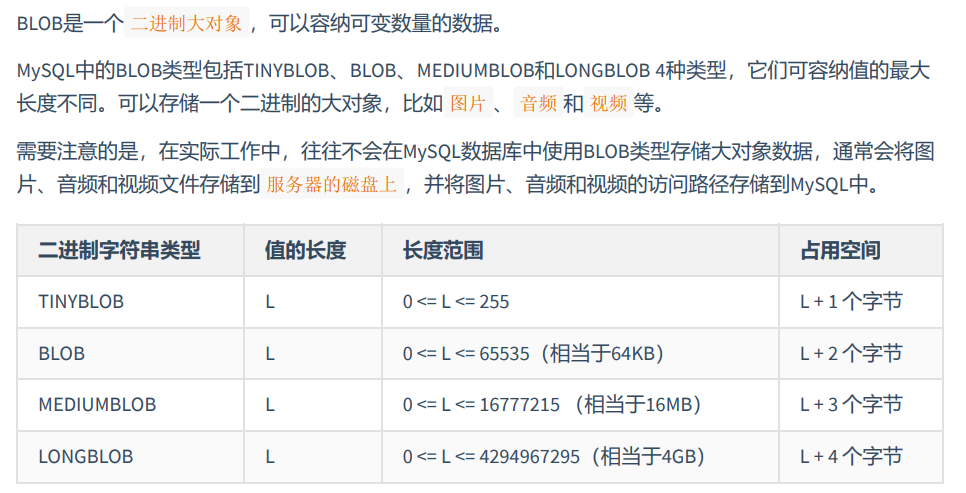
BLOB类型
JSON 类型

CREATE TABLE test_json(
js json
);
INSERT INTO test_json (js)
VALUES ('{"name":"songhk", "age":18, "address":{"province":"beijing",
"city":"beijing"}}');
mysql> SELECT *
-> FROM test_json;

当需要检索JSON类型的字段中数据的某个具体值时,可以使用“->”和“->>”符号。
mysql> SELECT js -> '$.name' AS NAME,js -> '$.age' AS age ,js -> '$.address.province'
AS province, js -> '$.address.city' AS city
-> FROM test_json;
+----------+------+-----------+-----------+
| NAME | age | province | city |
+----------+------+-----------+-----------+
| "songhk" | 18 | "beijing" | "beijing" |
+----------+------+-----------+-----------+
1 row in set (0.00 sec)
通过“->”和“->>”符号,从JSON字段中正确查询出了指定的JSON数据的值
空间类型


小结及选择建议
在定义数据类型时,如果确定是 整数 ,就用 INT ; 如果是 小数 ,一定用定点数类型 DECIMAL(M,D) ; 如果是日期与时间,就用 DATETIME 。
这样做的好处是,首先确保你的系统不会因为数据类型定义出错。不过,凡事都是有两面的,可靠性 好,并不意味着高效。比如,TEXT 虽然使用方便,但是效率不如 CHAR(M) 和 VARCHAR(M)。
- 任何字段如果为非负数,必须是 UNSIGNED
- 【 强制 】小数类型为 DECIMAL,禁止使用 FLOAT 和 DOUBLE。
- 说明:在存储的时候,FLOAT 和 DOUBLE 都存在精度损失的问题,很可能在比较值的时候,得到不正确的结果。如果存储的数据范围超过 DECIMAL 的范围,建议将数据拆成整数和小数并分开存储。
- 【 强制 】如果存储的字符串长度几乎相等,使用 CHAR 定长字符串类型。
- 【 强制 】VARCHAR 是可变长字符串,不预先分配存储空间,长度不要超过 5000。如果存储长度大
- 于此值,定义字段类型为 TEXT,独立出来一张表,用主键来对应,避免影响其它字段索引效率。