引言: 近日,谷歌DeepMind团队在arxiv平台上发表了一项突破性论文,正式推出了GenRM技术,这一创新成果显著提升了AI在复杂任务处理中的能力表现,再次跨越了技术界限,为人工智能的推理能力树立了崭新的标杆。

- 超越传统:
在 AI 行业内,提高大语言模型(LLMs)的主流做法是 best-of-n 模式,即由大语言模型生成的 n 个候选解决方案由验证器进行排序并选出最佳方案。这个简单而有效的策略,显著提升了模型的推理性能,但在涉及复杂推理的问题上仍然存在明显的短板。
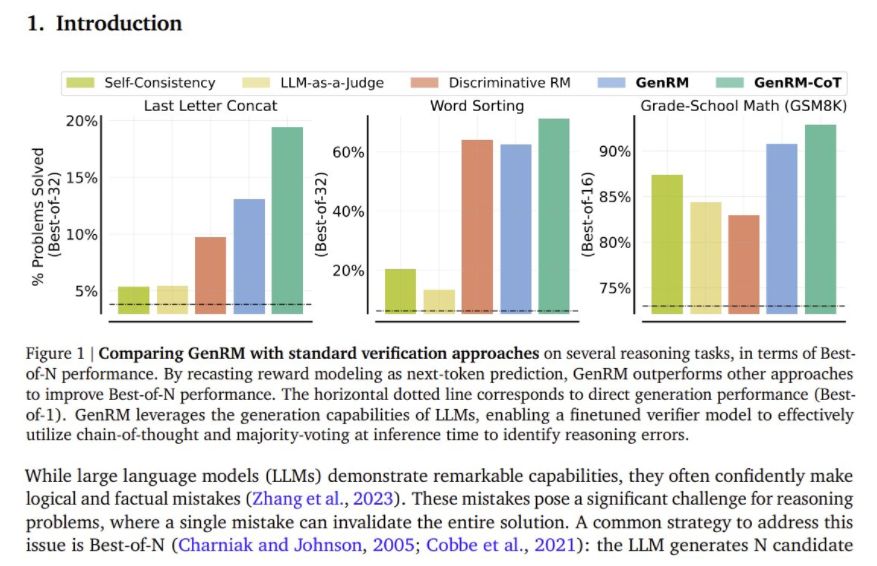
基于LLMs的验证器通常被训练成判别分类器来为解决方案打分,无法利用预训练大语言模型的文本生成能力。这导致模型经常会自信地做出逻辑或事实性错误,对于推理问题尤其具有挑战性。(图:GenRM与其他验证方法在几个推理任务上的性能比较)
- GenRM技术介绍:
GenRM技术的核心在于将验证过程重新定义为一个生成任务,具体来说是将其视为下一个标记预测问题,使AI能够更自然地利用其文本生成能力。该技术还支持Chain-of-Thought(CoT)推理,模型在得出最终结论前生成中间推理步骤,从而不仅评估了解决方案的正确性,还通过更详细和结构化的评估提升了整体推理过程。
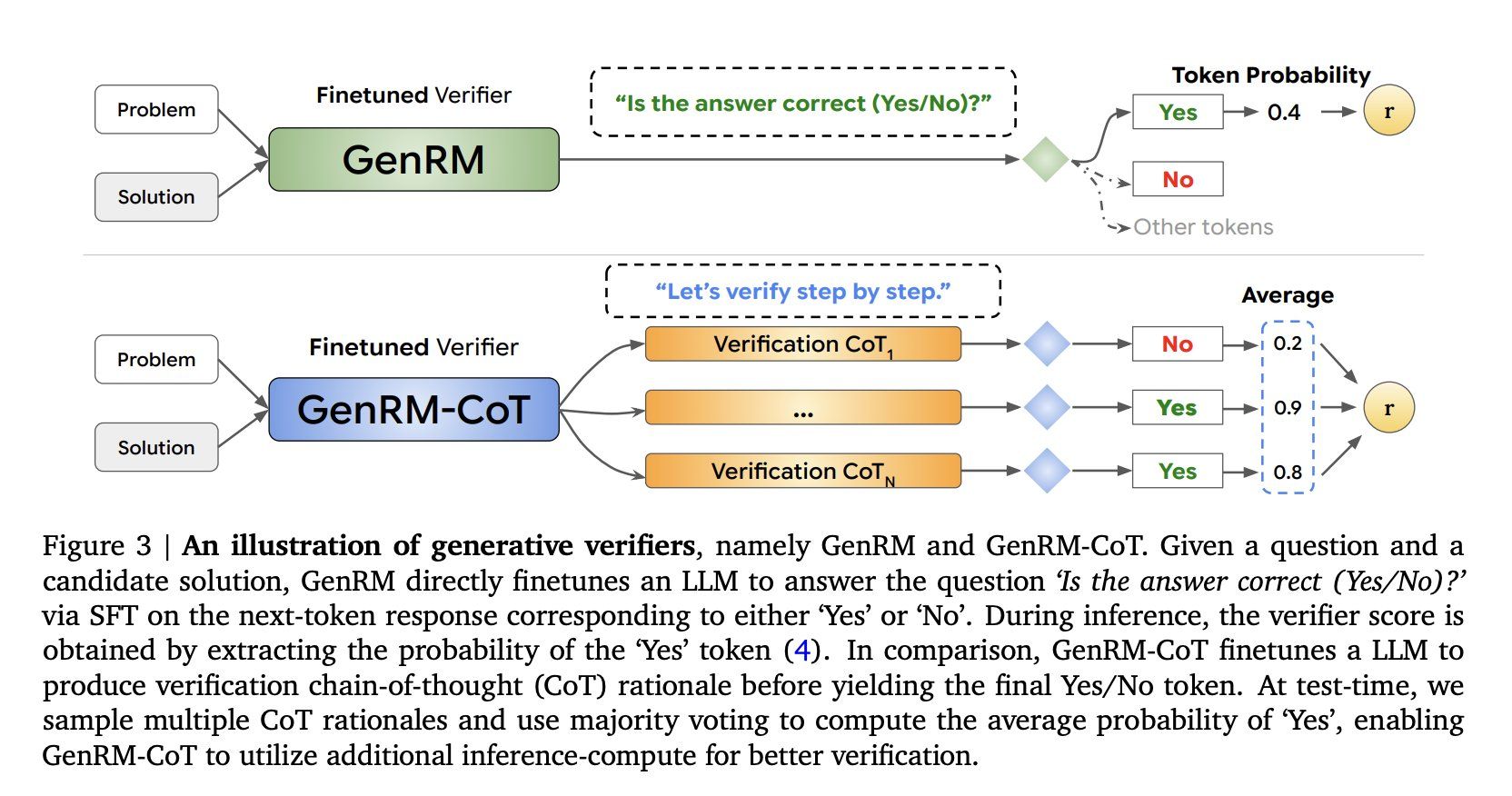
- GenRM的优势
相较于传统的判别式奖励模型,GenRM技术展现出了显著的优势:
思维链(Chain-of-Thought, CoT)推理:GenRM可以自然地生成中间推理步骤,详细解释为什么一个解决方案是正确或错误的。这种能力使得验证器能够捕捉到更细微的推理错误,提高了验证的准确性和可解释性。
推理时计算优化:通过采样多个CoT推理路径并进行多数投票,GenRM-CoT可以在推理时利用额外的计算资源来提高验证准确性。这种方法允许模型探索多种可能的推理路径,从而得出更可靠的结论。
统一训练:GenRM允许将解决方案生成和验证任务统一到同一个模型中进行训练。这种统一训练方法可能会带来正面的知识迁移,提高模型在两个任务上的表现。
指令调优兼容性:由于GenRM基于标准的下一个标记预测,它可以无缝地与指令调优等技术结合,进一步提高模型的性能和通用性。

- 实验验证
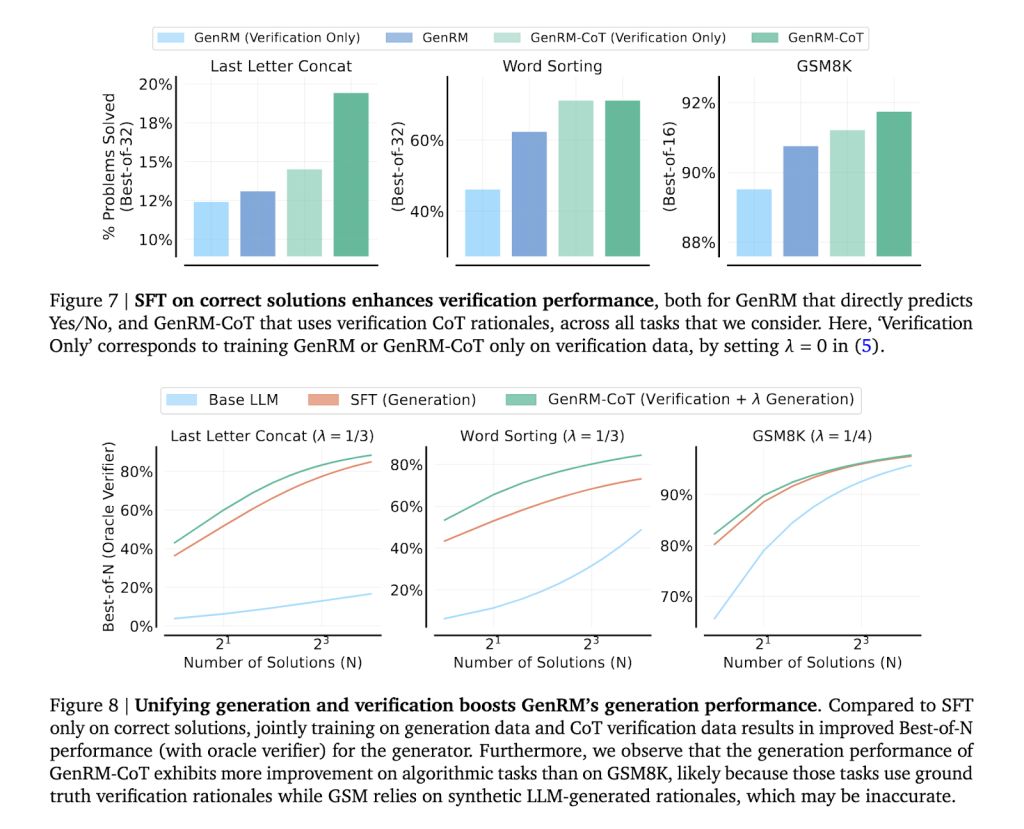
GenRM的卓越性能 在多个推理任务中,GenRM技术展现了其卓越的性能。特别是在算法和小学数学推理任务中,GenRM的性能优于传统验证器和LLM-as-a-Judge验证器,解决问题的成功率提高了16%到64%。
- 实际应用
GenRM的广泛前景 GenRM技术的成功不仅在于实验室内的表现,更在于其在实际应用中的广泛前景。从教育科技到自动化代码审查,从医疗诊断辅助到法律文件分析,GenRM技术有望在多个领域发挥重要作用。
结语: 谷歌DeepMind的GenRM技术是AI推理能力发展的一个重要里程碑。它不仅展示了AI技术的潜力,更为我们打开了通往更智能、更可靠的AI系统的未来之门。随着技术的不断进步,我们期待GenRM技术能够在更多的领域中发挥其独特的价值。