
简介:卡尔曼滤波是一种在噪声存在的情况下用于逼近系统真实状态的优化算法。它基于概率统计理论,在导航、控制、信号处理等领域具有广泛的应用。本资源包详尽介绍了卡尔曼滤波的原理、步骤和应用实例,特别通过Simulink模块的搭建来加深理解。资源内容包括滤波器的预测和更新机制、线性高斯假设、系统和观测模型构建、卡尔曼增益计算以及迭代过程。同时,提供了流程图以直观展示算法步骤,并涵盖多种滤波方法。Simulink模块的搭建可帮助用户直观地观察滤波过程并调试参数,实现学习和应用卡尔曼滤波的目的。 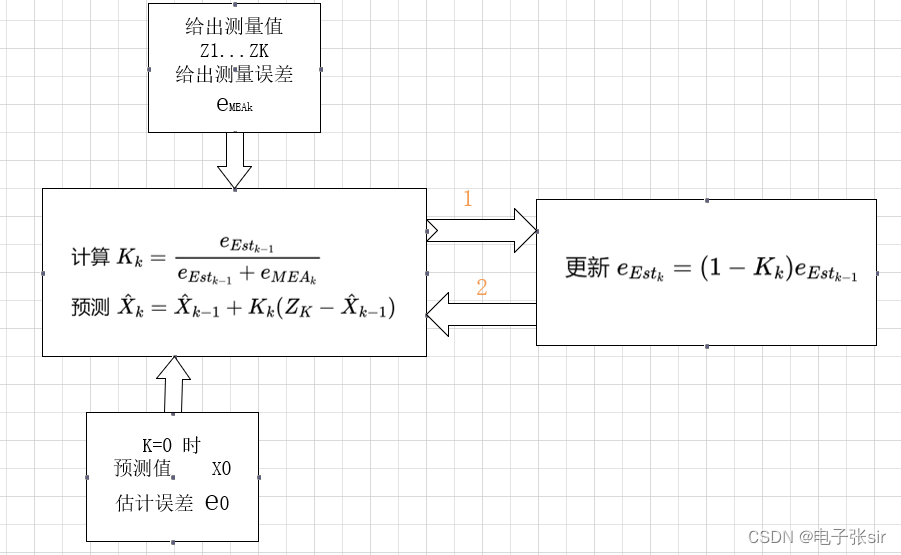
1. 卡尔曼滤波基础概念
1.1 卡尔曼滤波简介
卡尔曼滤波是一种高效的递归滤波器,它能够从一系列的含有噪声的测量数据中估计动态系统的状态。作为一种自回归算法,卡尔曼滤波器在控制、信号处理、经济学等诸多领域有着广泛的应用。
1.2 滤波器的工作原理
其核心思想是利用系统模型来预测状态变量的未来值,并根据实际测量值对这些预测值进行修正。卡尔曼滤波通过优化误差的协方差来减少估计误差,以达到最优化状态估计的目的。
1.3 滤波过程的数学基础
卡尔曼滤波涉及到概率统计、线性代数等数学领域的知识。通过构造数学模型,我们可以用状态方程和观测方程描述系统的动态行为和观测过程,从而实现对系统状态的最优估计。
本章介绍了卡尔曼滤波的基本概念,为理解后续章节中更深入的数学模型和应用实例奠定了基础。
2. 预测和更新机制
2.1 预测机制的数学模型
2.1.1 状态预测方程
在卡尔曼滤波中,状态预测方程是用于基于已知的系统动态和过去的估计来预测当前系统状态的基础公式。假设我们有一个线性系统,可以用以下差分方程来描述:
[ x_{k} = F_{k} x_{k-1} + B_{k} u_{k} + w_{k} ]
其中: - ( x_{k} )是当前时刻( k )的系统状态。 - ( x_{k-1} )是前一个时刻( k-1 )的系统状态。 - ( F_{k} )是状态转移矩阵,它体现了系统在不同时间的状态之间的关系。 - ( B_{k} )是控制输入矩阵,它将控制输入( u_{k} )转化为状态变化。 - ( w_{k} )是过程噪声,它通常假定为高斯白噪声,具有零均值和协方差矩阵( Q_{k} )。
状态预测方程给出了系统在没有新的测量值时如何随时间演化的一个预测。这个预测是基于过去的状态估计和对系统行为的理解。
import numpy as np
# 假设的参数,F是状态转移矩阵,B是控制输入矩阵,u是控制输入向量,w是过程噪声
F = np.array([[1, 1], [0, 1]]) # 一个简单的状态转移矩阵示例
B = np.array([[0.5], [1.0]]) # 控制输入矩阵
u = np.array([[2.0]]) # 控制输入向量
w = np.array([[0.1], [0.1]]) # 过程噪声
# 初始状态
x_prev = np.array([[1.0], [0.0]])
# 预测新的状态
x_pred = F @ x_prev + B @ u + w
print("预测的状态:", x_pred)
在上述代码块中,我们定义了状态转移矩阵、控制输入矩阵和初始状态,并执行了状态预测方程的计算。请注意,过程噪声 w 在这个例子中被明确添加以模拟不确定因素的影响。
2.1.2 误差协方差预测方程
除了预测状态本身,卡尔曼滤波还需要预测状态估计的不确定性,这通常通过协方差矩阵( P_{k} )来表示。误差协方差( P_{k} )的预测方程如下:
[ P_{k}^{-} = F_{k} P_{k-1} F_{k}^T + Q_{k} ]
这里的( P_{k}^{-} )表示预测的误差协方差,( F_{k}^T )是( F_{k} )的转置矩阵,( Q_{k} )是过程噪声协方差矩阵。
误差协方差( P_{k}^{-} )反映了在没有新的测量值进入之前,我们对当前状态估计的不确定性的量化。如果( P_{k}^{-} )较大,则表明对当前状态的估计不确定性较高;如果较小,则表明不确定性较低。
# 假设的协方差矩阵和过程噪声协方差矩阵
P_prev = np.array([[1.0, 0.0], [0.0, 1.0]]) # 初始误差协方差矩阵
Q = np.array([[0.01, 0.0], [0.0, 0.01]]) # 过程噪声协方差矩阵
# 计算预测的误差协方差
P_pred = F @ P_prev @ F.T + Q
print("预测的误差协方差:", P_pred)
在这个代码块中,我们计算了预测的误差协方差矩阵。初始误差协方差矩阵 P_prev 和过程噪声协方差矩阵 Q 是我们设置的假设值,而状态转移矩阵 F 则用于预测误差协方差。
2.2 更新机制的数学模型
2.2.1 状态更新方程
卡尔曼滤波中的更新机制,即根据新的测量值( z_{k} )来修正预测状态( x_{k}^{-} ),是通过状态更新方程来实现的:
[ x_{k} = x_{k}^{-} + K_{k}(z_{k} - H_{k} x_{k}^{-}) ]
在这个方程中: - ( x_{k}^{-} )是通过状态预测方程获得的预测状态。 - ( K_{k} )是卡尔曼增益,它是当前时刻的关键变量,用于权衡预测值和测量值。 - ( H_{k} )是观测矩阵,它将系统状态映射到观测空间。 - ( z_{k} )是当前时刻的测量值。
状态更新方程的作用是结合预测值和测量值,给出更精确的系统状态估计。
2.2.2 误差协方差更新方程
当更新状态估计后,也需要相应地更新误差协方差,以反映新的估计的不确定性:
[ P_{k} = (I - K_{k} H_{k})P_{k}^{-} ]
其中: - ( I )是单位矩阵。 - ( K_{k} )是卡尔曼增益。 - ( H_{k} )是观测矩阵。 - ( P_{k}^{-} )是更新前的预测误差协方差。
这个更新过程确保了在融合新的测量值后,误差协方差矩阵能够反映出新的估计的不确定性水平。
# 假设的观测矩阵和测量值
H = np.array([[1, 0]]) # 观测矩阵
z = np.array([[1.1]]) # 测量值
# 计算卡尔曼增益K_k
S = H @ P_pred @ H.T + R # S是测量误差协方差的预测
K_k = P_pred @ H.T @ np.linalg.inv(S)
# 更新状态和协方差
x = x_pred + K_k @ (z - H @ x_pred)
P = (np.eye(2) - K_k @ H) @ P_pred
print("更新后的状态估计:", x)
print("更新后的误差协方差:", P)
在这段代码中,我们首先定义了观测矩阵 H 和测量值 z 。然后,我们计算了卡尔曼增益 K_k 和更新后的状态估计 x ,以及误差协方差 P 。注意,测量误差协方差 R 是我们设置的假设值,在实际应用中需要根据具体的测量误差来确定。
3. 系统模型构建
3.1 线性系统模型
3.1.1 状态方程
线性系统模型的状态方程通常用来描述系统在没有外部输入时状态的变化。在离散时间下,状态方程可以表示为:
x_{k} = A x_{k-1} + B u_{k} + w_{k}
其中, x_{k} 是 k 时刻的系统状态, A 是状态转移矩阵, B 是控制输入矩阵, u_{k} 是 k 时刻的控制输入, w_{k} 是过程噪声,通常假设为白噪声,并且满足 E[w_{k}] = 0 和 E[w_{k}w_{j}^T] = Q_k \delta_{kj} ,其中 Q_k 是过程噪声协方差矩阵, \delta_{kj} 是克罗内克函数。
3.1.2 观测方程
观测方程则描述了系统状态与观测之间的关系,可以表示为:
z_{k} = H x_{k} + v_{k}
在这里, z_{k} 是 k 时刻的观测值, H 是观测矩阵, v_{k} 是观测噪声,也是白噪声,并且假设其满足 E[v_{k}] = 0 和 E[v_{k}v_{j}^T] = R_k \delta_{kj} ,其中 R_k 是观测噪声协方差矩阵。
在实际应用中,线性系统模型提供了一种简洁的方式来模拟和预测系统的动态行为。尽管现实世界中许多系统本质上是非线性的,但在局部或者小范围内,系统的行为可以通过线性化近似为线性系统,使得卡尔曼滤波能够被应用。
3.2 非线性系统模型
3.2.1 状态转移函数
对于非线性系统,状态方程和观测方程将不再遵循上述线性形式。非线性系统的状态转移函数可以描述如下:
x_{k} = f(x_{k-1}, u_{k}, w_{k})
其中, f 代表非线性函数,该函数能够表示系统状态的复杂变化。
3.2.2 观测函数
同样,观测函数将呈现出非线性特征:
z_{k} = h(x_{k}, v_{k})
在这里, h 代表观测非线性函数。非线性系统的建模需要更复杂的数学工具,例如泰勒级数展开或数值方法来处理非线性项。在工程实践中,扩展卡尔曼滤波(EKF)和无迹卡尔曼滤波(UKF)等算法通常被用于处理非线性问题。
下面是一个简单的扩展卡尔曼滤波的例子,用于处理非线性系统模型:
假设一个简单的一维非线性状态转移函数为:
import numpy as np
def f(x):
return 0.5 * x + np.sin(x)
观测函数定义如下:
def h(x):
return np.exp(-0.5 * x**2)
在一个非线性卡尔曼滤波过程中,我们首先需要线性化这些函数。对于上述函数,可以使用雅可比矩阵的泰勒级数展开进行线性化。
这些模型构建的实际应用将涉及到一系列复杂的数学运算和计算方法,目的是为了在现实世界中的非线性环境中,尽可能准确地对系统的状态进行估计。
4. 卡尔曼增益计算
4.1 卡尔曼增益的作用
卡尔曼增益是卡尔曼滤波器中的一个核心概念,它决定了在滤波过程中预测值和观测值之间的权重。理解卡尔曼增益的作用,是深入理解整个卡尔曼滤波算法的关键。
4.1.1 权衡预测和观测数据
在实际应用中,系统的状态往往不能直接观测到,需要通过观测值间接获取。卡尔曼增益正是在这一过程中起到关键作用。它根据预测误差和观测误差的协方差动态调整,以决定在某个特定时刻,应该更多地依赖于预测值还是观测值。这种动态权重分配机制是卡尔曼滤波器能够准确估计系统状态的关键。
4.1.2 影响滤波性能的关键因子
卡尔曼增益的大小直接影响滤波器的性能。一个适中的卡尔曼增益可以使得滤波器在预测和观测之间找到最佳平衡,以达到最优估计。过大的增益可能导致滤波器过度依赖观测数据,对噪声敏感;而过小的增益则可能使得滤波器过于依赖预测,反应迟钝。因此,卡尔曼增益的计算和调整是滤波器设计中的重要环节。
4.2 卡尔曼增益的计算过程
4.2.1 数学推导
卡尔曼增益的计算基于最小均方误差准则。其数学表达式如下:
[ K_k = P_{k|k-1} H^T (H P_{k|k-1} H^T + R)^{-1} ]
其中,( K_k ) 是第 ( k ) 次迭代的卡尔曼增益;( P_{k|k-1} ) 是预测误差协方差;( H ) 是观测矩阵;( R ) 是观测噪声协方差。
这一表达式体现了对当前预测误差协方差的依赖,并通过观测噪声协方差来调整依赖度。增益 ( K_k ) 是一个矩阵,其大小和维度依赖于状态向量和观测向量的维度。
4.2.2 算法实现步骤
以下是计算卡尔曼增益的步骤,包括详细的代码实现和参数说明:
- 状态预测误差协方差 ( P_{k|k-1} ) 的计算 :这一过程需要根据系统的状态转移矩阵来预测下一时刻的误差协方差。
# Python代码示例
import numpy as np
# 假设 F 是状态转移矩阵,P 是初始误差协方差
F = ... # 状态转移矩阵
P = ... # 初始误差协方差
# 预测下一时刻的误差协方差
P_pred = F @ P @ F.T + Q # Q 是过程噪声协方差矩阵
- 观测矩阵 ( H ) 的定义 :观测矩阵 ( H ) 将系统状态空间映射到观测空间。
# 假设 H 是观测矩阵
H = ... # 观测矩阵
- 计算卡尔曼增益 ( K_k ) :这一过程涉及到矩阵的逆运算,需要确保矩阵可逆。
# 计算卡尔曼增益
K = P_pred @ H.T @ np.linalg.inv(H @ P_pred @ H.T + R) # R 是观测噪声协方差矩阵
通过上述步骤,我们可以计算得到当前时刻的卡尔曼增益 ( K_k )。这一增益将用于更新滤波器的状态估计。
为了更好地理解卡尔曼增益的作用和计算过程,我们可以通过一个简单的例子来详细解读。假设有一个一维的运动模型,我们试图估计其位置和速度。我们的状态向量 ( x_k ) 可能就包含了这两个变量,而观测向量 ( z_k ) 可能只是位置的观测值。
- 在上述情况下,状态转移矩阵 ( F ) 描述了从一个时间步到下一个时间步状态如何变化,如果系统是匀速直线运动,状态转移矩阵可能就只有 1 和 0 两个元素,表示位置随时间增加而增加,速度保持不变。
- 观测矩阵 ( H ) 将会是一个行向量,因为我们的观测只包括位置信息,因此 ( H ) 可能就是 ( [1, 0] )。
- 状态估计的预测 ( x_{k|k-1} ) 是基于上一时刻的状态估计 ( x_{k-1|k-1} ) 和状态转移矩阵 ( F ) 计算得到的。
- 误差协方差 ( P_{k|k-1} ) 的预测是基于上一时刻的误差协方差 ( P_{k-1|k-1} ) 和状态转移矩阵 ( F ) 计算的,同时还需要加上过程噪声协方差 ( Q )。
在计算出卡尔曼增益 ( K_k ) 后,我们将根据观测值 ( z_k ) 和卡尔曼增益来更新状态估计 ( x_{k|k} ) 和误差协方差 ( P_{k|k} ):
# 更新状态估计和误差协方差
x_kk = x_pred + K @ (z_k - H @ x_pred)
P_kk = (np.eye(len(H)) - K @ H) @ P_pred
在这里,( x_kk ) 是经过当前观测值修正后的状态估计,( P_kk ) 则是在考虑到当前观测信息后对误差协方差的更新。通过这种方式,卡尔曼滤波器逐步迭代,最终得到对系统状态的最优估计。
在上述例子中,我们通过逐步分析和解释代码块,逐行解读了如何计算卡尔曼增益以及如何使用它来更新状态估计。需要注意的是,实际应用中的系统可能会更加复杂,包含多维状态和观测变量,但计算的基本原理和步骤是类似的。对于复杂的系统模型,可能需要借助数学软件和高级编程库来处理矩阵运算和优化。
接下来,我们将进入卡尔曼滤波的另一个重要环节——滤波过程的迭代。我们将介绍如何设置初始状态,以及如何逐步迭代更新状态估计。
5. 滤波过程迭代
5.1 初始状态设置
在卡尔曼滤波算法的迭代过程中,初始状态的设定对于算法的收敛速度和滤波效果有着重要的影响。初始状态包括初始估计和初始误差协方差,下面将详细讨论这两部分的设置方法。
5.1.1 初始估计
初始估计是算法开始迭代时对系统状态的首次猜测,这个初始猜测是基于对系统行为的先验知识或者前期数据的分析得出的。在实际应用中,初始估计可以通过多种途径获得,例如:
- 系统的历史数据平均值
- 专家的经验判断
- 辅助传感器的直接测量值
- 等等
选择一个合理的初始估计是确保滤波器能够有效工作的关键。如果初始估计过于离散实际状态,可能会导致滤波器在迭代初期无法快速收敛。
5.1.2 初始误差协方差
初始误差协方差矩阵代表了初始估计的不确定性大小,它直接影响算法对数据的权重分配。一个较小的初始误差协方差会使得卡尔曼增益相对较大,这将导致算法更多地依赖于观测数据,反之亦然。
通常情况下,初始误差协方差可以设定为一个较大的值,或者根据经验设定为一个合理的方差范围,表示对初始估计的不自信。随着迭代过程的进行,误差协方差会根据新观测数据动态调整,最终达到收敛状态。
5.2 迭代滤波的步骤
5.2.1 预测步骤
在获得初始状态后,卡尔曼滤波的迭代过程即进入预测步骤。这一阶段主要由以下两个公式组成:
-
状态预测方程 :根据系统的状态转移模型,计算出下一个时间点的状态估计。 [ \hat{x} {k|k-1} = F_k \hat{x} {k-1|k-1} + B_k u_k ] 其中,( \hat{x} {k|k-1} ) 是在时间点k的预测状态估计,( F_k ) 是状态转移矩阵,( \hat{x} {k-1|k-1} ) 是时间点k-1的状态估计,( B_k ) 是控制输入矩阵,( u_k ) 是控制输入。
-
误差协方差预测方程 :预测误差协方差表示预测状态的不确定性。 [ P_{k|k-1} = F_k P_{k-1|k-1} F_k^T + Q_k ] 其中,( P_{k|k-1} ) 是预测误差协方差,( Q_k ) 是过程噪声协方差矩阵。
预测步骤可以看作是状态估计的“预测器”,为下一步的更新步骤提供基础。
5.2.2 更新步骤
当新的观测数据到来时,滤波器进入更新步骤,主要包含以下两个公式:
-
状态更新方程 :结合预测状态和新观测数据,更新状态估计。 [ \hat{x} {k|k} = \hat{x} {k|k-1} + K_k (z_k - H_k \hat{x} {k|k-1}) ] 其中,( \hat{x} {k|k} ) 是更新后的状态估计,( K_k ) 是卡尔曼增益,( z_k ) 是观测数据,( H_k ) 是观测矩阵。
-
误差协方差更新方程 :在状态更新的同时,也需要更新误差协方差以反映新的不确定性水平。 [ P_{k|k} = (I - K_k H_k) P_{k|k-1} ] 其中,( P_{k|k} ) 是更新后的误差协方差,( I ) 是单位矩阵,( K_k H_k ) 表示卡尔曼增益与观测矩阵的乘积。
更新步骤实际上是利用观测数据校正预测状态,获得更为准确的状态估计,并为下一周期的预测做准备。
示例代码块及其解释
下面是一个简化的卡尔曼滤波迭代过程的Python代码示例:
import numpy as np
# 初始状态估计和协方差
x_hat_k_minus_1 = np.array([0.0]) # 初始估计
P_k_minus_1 = np.array([[1.0]]) # 初始误差协方差
# 迭代参数
F_k = np.array([[1.0]]) # 状态转移矩阵
B_k = np.array([[0.0]]) # 控制输入矩阵,此处无控制输入,故为零矩阵
H_k = np.array([[1.0]]) # 观测矩阵
Q_k = np.array([[0.1]]) # 过程噪声协方差矩阵
R_k = np.array([[1.0]]) # 测量噪声协方差矩阵
K_k = np.zeros((1, 1)) # 卡尔曼增益
# 模拟观测数据
z_k = np.array([0.0]) # 观测数据
# 预测步骤
x_hat_k = F_k.dot(x_hat_k_minus_1)
P_k = F_k.dot(P_k_minus_1).dot(F_k.T) + Q_k
# 更新步骤
K_k = P_k.dot(H_k.T) / (H_k.dot(P_k).dot(H_k.T) + R_k)
x_hat_k = x_hat_k + K_k.dot(z_k - H_k.dot(x_hat_k))
P_k = (np.eye(1) - K_k.dot(H_k)).dot(P_k)
# 打印更新后的状态估计和协方差
print("Updated State Estimate:", x_hat_k)
print("Updated Covariance:", P_k)
在上述代码中,我们首先初始化了状态估计和误差协方差矩阵。然后,我们定义了模型的参数矩阵,包括状态转移矩阵 F_k ,控制输入矩阵 B_k ,观测矩阵 H_k ,以及过程和测量噪声协方差矩阵 Q_k 和 R_k 。通过模拟产生的观测数据 z_k ,我们完成了预测和更新步骤,最后打印出了更新后的状态估计和协方差矩阵。注意,在实际应用中,控制输入矩阵 B_k 和观测矩阵 H_k 需要根据具体的系统特性来设定。
通过对每个步骤的分析和代码实现,我们可以看到卡尔曼滤波在迭代过程中是如何逐步优化状态估计的。这个过程对IT专业人士来说,展示了算法的实际应用场景和内部工作机制,提供了一个从理论到实践的完整学习案例。
6. 流程图解析
在卡尔曼滤波算法的实现和优化中,流程图的应用是至关重要的。流程图可以清晰地展示算法的执行逻辑,使得理解和调试过程更为直观。本章将详细介绍流程图的设计方法、逻辑结构,以及如何使用流程图描述卡尔曼滤波过程和解释算法原理。
6.1 流程图的设计
6.1.1 流程图的基本元素
流程图是由各种图形符号组成的,这些符号代表了算法中的不同操作和数据流向。基本元素包括:
- 矩形框 :代表一个过程或操作步骤。
- 菱形框 :代表一个判断或决策点。
- 椭圆形框 :代表开始或结束。
- 箭头 :指示控制流方向。
6.1.2 流程图的逻辑结构
卡尔曼滤波算法的流程图需要反映算法中预测和更新的迭代逻辑。通常包括初始化、预测、更新等步骤。逻辑结构应该包括:
- 初始化 :设置初始状态向量和初始误差协方差矩阵。
- 循环开始 :滤波循环的开始,通常是由一个判断框开始,用于决定是否进行滤波过程。
- 预测步骤 :包括状态预测和误差协方差预测。
- 更新步骤 :通过测量值更新状态估计和误差协方差。
6.2 流程图在滤波中的应用
6.2.1 描述滤波过程
流程图能够详细地展示卡尔曼滤波算法的每个步骤,包括状态预测和更新过程。举一个具体的例子:
graph LR
A((开始)) --> B[设置初始值]
B --> C{是否进行迭代?}
C -->|是| D[状态预测]
D --> E[误差协方差预测]
E --> F{是否进行更新?}
F -->|是| G[计算卡尔曼增益]
G --> H[状态更新]
H --> I[误差协方差更新]
I --> C
C -->|否| J((结束))
6.2.2 解释算法原理
流程图不仅能够描述卡尔曼滤波算法的操作步骤,还能够解释其背后的算法原理。例如,预测步骤是如何处理系统噪声和过程噪声的,更新步骤是如何融合新的测量值来调整估计值的。
通过流程图的展示,我们可以清晰地看到卡尔曼滤波算法的每一项计算是如何基于数学模型进行的,并且能够直观地理解其动态调整权重以实现最优估计的过程。
例如,通过卡尔曼增益的计算,算法根据预测和测量的误差来调整状态估计,流程图中可以通过一个专门的分支来展示这一过程的逻辑,帮助理解增益如何在不同条件下改变状态估计的权重。
flowchart LR
K[计算卡尔曼增益] -->|根据误差| L[调整状态估计]
L --> M[更新误差协方差]
通过这样的可视化展示,卡尔曼滤波算法的动态特性得以直观呈现,便于用户理解并应用到实际问题中去。
7. 卡尔曼滤波的扩展算法
7.1 扩展卡尔曼滤波(EKF)
卡尔曼滤波(EKF)是经典卡尔曼滤波在处理非线性系统时的一种扩展方法。其核心思想是利用泰勒级数展开对非线性函数进行线性化处理,从而将非线性系统转化为近似线性系统,使得卡尔曼滤波算法能够应用。
7.1.1 非线性系统中的应用
在许多实际应用中,如导航系统、机器人定位等场景,系统动态和观测方程往往是非线性的。这时,直接使用经典卡尔曼滤波算法会导致滤波结果不准确,甚至发散。通过EKF,系统和观测模型可以表示为:
[ f(x_t, u_t) \approx f(\hat{x} {t|t-1}, u_t) + F(x_t - \hat{x} {t|t-1}) ]
其中,( f ) 是非线性状态转移函数,( F ) 是雅可比矩阵,它表示 ( f ) 关于 ( x_t ) 的偏导数矩阵。类似地,对于非线性观测函数 ( h ),可以得到观测模型的线性近似:
[ h(x_t) \approx h(\hat{x} {t|t-1}) + H(x_t - \hat{x} {t|t-1}) ]
其中,( H ) 是雅可比矩阵,它表示 ( h ) 关于 ( x_t ) 的偏导数矩阵。
7.1.2 EKF的实现细节
EKF的实现需要对状态转移函数和观测函数进行泰勒展开,求得相应的雅可比矩阵。然后,使用这些雅可比矩阵更新卡尔曼滤波中的相关公式。
EKF的关键步骤包括:
- 状态预测 :使用非线性状态转移函数 ( f ) 预测下一状态,并计算雅可比矩阵 ( F )。
-
误差协方差预测 :根据 ( F ) 更新误差协方差的预测值。
-
状态更新 :使用非线性观测函数 ( h ) 进行测量更新,并计算雅可比矩阵 ( H )。
-
误差协方差更新 :根据 ( H ) 更新误差协方差的更新值。
代码示例:
import numpy as np
def predict_next_state(x_pred, u_t, F):
# 预测下一状态
return f(x_pred, u_t) + F @ (x_pred - x_pred)
def update_state(measurement, x_pred, P_pred, H):
# 更新状态
y = measurement - h(x_pred)
S = H @ P_pred @ H.T + R
K = P_pred @ H.T @ np.linalg.inv(S)
x = x_pred + K @ y
P = (np.eye(K.shape[0]) - K @ H) @ P_pred
return x, P
# 示例使用雅可比矩阵进行预测和更新的函数
# 注意:这里只是示意,实际应用中需要具体的函数实现和雅可比矩阵计算
7.2 无迹卡尔曼滤波(UKF)
无迹卡尔曼滤波(UKF)是一种不需要对非线性模型进行线性化的滤波技术。其思想是通过选择一组确定的采样点(sigma点),将它们通过非线性函数映射,以此来估计统计特性(均值和协方差)。
7.2.1 UKF的基本思想
UKF通过对系统的均值和协方差进行采样,获得一组sigma点,并将这些点通过非线性函数进行传播,以获取更新后状态的均值和协方差。具体来说:
-
选择sigma点 :选择一组点来表示状态变量的均值和协方差。
-
点传播 :将这些点通过非线性函数进行传播。
-
权重计算 :通过传播后的点,计算得到更新后的状态均值和协方差。
7.2.2 UKF在复杂系统中的优势
UKF不需要对非线性模型进行泰勒展开,因此避免了线性化带来的误差。尤其在模型非常复杂时,EKF的线性化误差可能会变得很大,而UKF则可以提供更好的滤波精度。
代码示例:
import numpy as np
def unscented_transform(Wm, Wc, X, fun):
# 初始化输出均值和协方差
n = X.shape[0]
m = np.zeros(n)
P = np.zeros((n, n))
# 对每个sigma点应用非线性函数并计算新的均值和协方差
for i in range(2 * n + 1):
m_i = fun(X[i, :])
m += Wm[i] * m_i
P += Wc[i] * np.outer((m_i - m), (m_i - m))
return m, P
# 示例使用无迹变换计算均值和协方差的函数
# 注意:这里只是示意,实际应用中需要具体的函数实现
7.3 粒子滤波(PF)
粒子滤波(PF)是一种基于蒙特卡洛方法的序列蒙特卡洛滤波算法,适用于解决非线性非高斯系统的问题。PF通过一组随机样本(粒子)来表示概率密度函数,并通过对粒子进行重采样、预测和更新来逼近后验概率密度。
7.3.1 粒子滤波的概念
粒子滤波的核心思想是将系统的后验概率密度分解为一系列粒子的概率权重,每个粒子都代表了系统可能的状态。通过粒子的演化过程,可以对系统状态进行滤波估计。
7.3.2 粒子滤波的实现过程
-
初始化粒子 :生成一组随机粒子,并为每个粒子分配初始权重。
-
预测 :根据系统模型预测每个粒子的状态。
-
更新 :根据观测数据更新粒子权重。
-
重采样 :对权重低的粒子进行重采样,复制权重高的粒子,以避免粒子退化。
代码示例:
import numpy as np
def particle_filter(state_particles, weights, measurement):
# 预测步骤
for i in range(len(state_particles)):
state_particles[i] = predict_state(state_particles[i])
# 更新步骤
for i in range(len(state_particles)):
weights[i] *= evaluate_observation(state_particles[i], measurement)
# 归一化权重
weights /= np.sum(weights)
# 重采样步骤(简化版)
# ...(此处省略重采样过程)
return state_particles, weights
# 示例使用粒子滤波的函数
# 注意:这里只是示意,实际应用中需要具体的函数实现
以上章节我们探讨了卡尔曼滤波的扩展算法,包括扩展卡尔曼滤波(EKF)、无迹卡尔曼滤波(UKF)和粒子滤波(PF)。这些算法扩展了经典卡尔曼滤波器的应用范围,使其能够适应更加广泛、复杂的情况。通过具体的数学推导和代码示例,我们可以看到这些算法在处理非线性系统时的有效性和应用细节。
简介:卡尔曼滤波是一种在噪声存在的情况下用于逼近系统真实状态的优化算法。它基于概率统计理论,在导航、控制、信号处理等领域具有广泛的应用。本资源包详尽介绍了卡尔曼滤波的原理、步骤和应用实例,特别通过Simulink模块的搭建来加深理解。资源内容包括滤波器的预测和更新机制、线性高斯假设、系统和观测模型构建、卡尔曼增益计算以及迭代过程。同时,提供了流程图以直观展示算法步骤,并涵盖多种滤波方法。Simulink模块的搭建可帮助用户直观地观察滤波过程并调试参数,实现学习和应用卡尔曼滤波的目的。