使用 3D 循环卷积自动编码器实现扩散 MRI 中的角度超分辨率
Angular Super-Resolution in Diffusion MRI with a 3D Recurrent Convolutional Autoencoder
代码地址
摘要:高分辨率扩散 MRI (dMRI) 数据通常受到临床环境中扫描时间有限的限制,从而限制了下游分析技术的使用。在这项工作中,我们开发了一种 3D 循环卷积神经网络 (RCNN),能够在角度(q 空间)域中超分辨率 dMRI 体积。我们的方法使用**以目标 b 向量为条件的 3D 自动编码器将角度超分辨率任务表述为补丁式回归。**在网络中,我们使用卷积长短期记忆 (ConvLSTM) 单元来对 q 空间样本之间的关系进行建模。我们将模型性能与基线球谐波插值和模型架构的一维变体进行比较。我们表明,3D模型在不同的子抽样方案和b值中具有最低的错误率。3D RCNN的相对性能在极低角分辨率域中最大。
关键词: 扩散MRI, 深度学习, 角度超分辨率, 循环CNN, 图像合成
- 简介
弥散MRI(dMRI)分析技术的进步继续推动通过非侵入性成像模式可以实现的界限(Zhang等人,2012;拉菲尔特等人,2017;德雷克-P·埃雷斯等人,2018 年)。然而,获取这些更先进的技术所需的高角分辨率扩散成像(HARDI)是一项挑战。HARDI 数据需要采集通常三十个或更多的扩散方向,通常在几个b值(多壳)下,才能有效地使用这些技术。因此,由于获取这种高分辨率数据集的时间限制,从这些进步中受益在临床上是不可行的(HARDI 采集面临的问题,也是研究的出发点)。
减轻采集时间负担的一种方法是使用超分辨率(SR)等图像增强技术。在这里,dMRI 数据具有两个不同但相关的分辨率,可以超分辨率:空间分辨率,或k空间内的采样密度,以及角分辨率,或q空间内的采样密度(Tuch,2004)。空间超分辨率 (SSR) 已在医学成像和自然图像领域广泛涵盖(Li 等人,2021 年;杨等人,2019)。然而,由于dMRI数据具有独特的角度结构,因此在角超分辨率(ASR)域中完成的工作量相对有限 (dmri 角度超分辨现状)。
特别是,**许多方法选择通过对下游分析技术进行推理来限制 ASR 的挑战。这具有简化任务的优点,但限制了超分辨率数据用于不同分析技术的能力(这是直接进行微观参数重建的缺陷)。**Lucena 等人 (2020) 和 Zeng 等人 (2021) 都使用单壳数据和卷积神经网络 (CNN) 架构来推断纤维取向分布 (FOD) 数据,其质量与多壳采集相似(Tournier 等人,2007 年)。同样,Golkov 等人 (2016)、Chen 等人 (2020) 和 Ye 等人 (2020) 开发了深度架构,以从神经突定向色散和密度成像 (NODDI) (Zhang 等人,2012 年)和其他单壳数据将无法获得的模型中推断指标。
直接处理扩散数据的模型通常使用球谐函数 (SH)(Frank,2002)。SH 提供了一组定义在球体表面上的平滑基函数。由于它们形成了完整的正交基,因此可用于描述任何表现良好的球函数。因此,它们通常用于表示 dMRI 信号,该信号是在单位球体表面上的点(b 向量)定义的不同扩散方向上测量的。通常在 dMRI 深度学习中,SH 系数首先适合扩散数据,然后用作输入代替无约束扩散信号。然后可以训练网络来推断其他壳的 SH 系数,因为 SH 框架已经提供了对单个壳内其他数据点的插值。例如,Koppers等人(2016)使用来自单壳dMRI数据的SH系数来推断不同壳的SH系数。然而,这种方法的范围有限,因为只使用大脑内随机采样的白质(WM)体素。Jha等人(2020)随后使用2D CNN自动编码器架构扩展了这一想法,该架构推断了整个大脑的数据。目前,只有Yin等人(2019)提出的另一种深度学习架构在不使用SH的情况下推断原始dMRI数据。这种架构是一维CNN自动编码器,因此不能从dMRI数据中存在的空间关系中受益。
本文提出了通过使用递归CNN(RCNN)自动编码器架构在dMRI数据中实现ASR的新方法。这涉及两个关键创新:1)将网络的维度扩展到3D;2)使用3D卷积长短期记忆(ConvLSTM)单元对q空间关系进行建模。这两项贡献使我们能够利用dMRI数据中存在的空间相关性来有效地推断新的扩散方向,而不受预定义函数(如SH)的限制。 此外,省略SH框架使我们能够探索在深度学习推理中使用无约束dMRI数据的可行性。
我们通过测量dMRI信号在多个扩散方向上与地面实况的偏差来评估所提出的模型的性能。WU-Minn人类连接组项目(HCP)数据集(Van Essen等人,2013)用于训练和定量比较。我们评估不同角度分辨率和b值下的模型性能。此外,我们将我们提出的3D模型的结果与SH框架内的角度插值以及同一模型的一维变体进行了比较。
2. 方法
我们通过以下方式制定ASR的任务:**由3D dMRI 体积和b向量组成的低角分辨率(LAR)数据集用作上下文数据,以生成整个q空间的潜在表示。**然后用目标b向量查询这种潜在表示,以推断以前未见过的dMRI体积。我们在下面列出了所需的预处理步骤和网络实现。
2.1. 预处理
HCP dMRI 数据用于训练和评估,最初使用标准HCP预处理管道进行处理(Glasser等人,2013)。HCP 数据集中每个受试者中的每个 4D dMRI 体积都包含三个 b 值为 1000、2000 和 3000 的外壳。每个壳都经过独立处理,包含 90 个扩散方向,其中 LAR 数据集是从中子采样的。需要几个进一步的预处理步骤才能将数据转换为适当的格式,以便在网络内进行有效训练。首先对dMRI数据进行降噪。假设噪声在整个 4D 体积中是独立的,因此上下文数据集中的噪声不能用于预测目标体积内的噪声。为了缓解这个问题,对数据应用了一种称为“patch2self”的全秩局部线性去噪算法(Fadnavis 等人,2020 年)。接下来,对dMRI数据进行重新缩放,使大部分分布位于[0,1]之间。这是通过将每个体素除以给定其 shell 成员资格的规范化值来完成的。发现 4000、3000 和 2000 分别适用于壳 b = 1000、b = 2000 和 b = 3000 的归一化值(但是这里的归一化会影响到后续的微观参数估计,因为这里的值不仅仅是表示图像的灰度图,还包含着神经纤维的方向信息)。
之后,将dMRI数据分成具有空间维度(10×10×10)的较小斑块。这样做是为了减轻使用 4D 数据的内存限制,如果保持完整大小,则内存要求大得令人望而却步。发现 10*10*10各向同性是一个足够大的补丁大小,可以从非逐点卷积中受益,同时仍然具有合理的内存要求。每个补丁包含至少一个来自大脑提取面具的体素,因此大脑内不包含体素的补丁将被丢弃。
接下来,仅在训练期间,dMRI 补丁和b向量中的q空间维度被洗牌。这是鼓励模型学习测量的dMRI信号与b矢量方向性之间的关系的关键步骤,同时阻止模型收敛于对q空间样本阶数敏感的解决方案。因此,在每个训练时期之后重复洗牌过程。由于训练示例是从整个 90 个方向进行子采样的,因此确保 q 空间洗牌生成在 q 空间球面上大致均匀分布的示例非常重要。为此,随机选择一个初始方向,然后依次选择下一个点,以最小化与先前选择的所有点之间的总角距离。重复此操作,直到点数等于训练样本大小。最后,将洗牌后的数据集分别拆分为大小为 qin 和 qout 的上下文集和目标集。
2.2. 提出的网络
提出的RCNN是一个条件自动编码器,由3D CNN编码器和解码器组成。该架构的图形表示如图 1 所示。
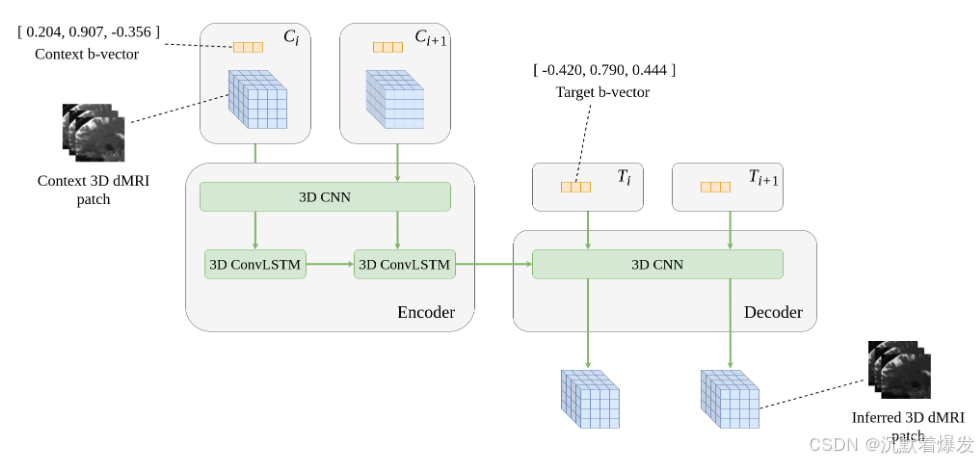
图 1:RCNN 模型设计。这里 q-space 上下文数据 Ci 按顺序提供给编码器,直到看到所有上下文示例 Cqin。接下来,将ConvLSTM的内部隐藏状态与目标数据Ti一起传递给3D CNN解码器,以沿给定扩散方向推断3D dMRI 补丁。
编码器
每个编码器输入由一个上下文集组成,大小为qin,包含dMRI补丁和相应的b向量。**最初在编码器内,b向量集在每个空间维度上重复,然后与dMRI信号逐通道连接,形成“q空间张量”。**接下来,q空间张量通过逐点卷积层,然后传递到两个串联连接的平行卷积块上。之后,输出通过另外两个逐点卷积层,最后传递到 3D ConvLSTM 层。由于编码器内的卷积层包含dMRI信号和b矢量信息,因此编码器网络可以直接学习dMRI数据的q空间表示。
解码器
ConvLSTM 层内隐藏的内部状态以及一组目标 b 向量用作解码器的输入。首先,隐藏状态是重复的 qout 次,其中 qout 是目标 b 向量的数量。然后,与编码器类似,目标b向量在每个空间维度上重复,并与隐藏状态通道连接。之后,得到的张量通过两个逐点卷积层,然后再次与目标b向量连接。最后,它通过两个平行的卷积块,随后通过两个卷积层。
并行卷积块
编码器和解码器中使用并行卷积块。它们由三个卷积层组成,内核大小为 (1 × 1 × 1)、(2 × 2 × 2) 和 (3 × 3 × 3),它们将卷积操作并行应用于同一输入。2*2*2 和 3*3*3 各向同性核在卷积操作之前应用了填充,使得生成的形状等于未填充的输入张量。该块的灵感来自Szegedy等人(2016)所做的工作,并允许不同分辨率的空间信息串联通过该块。然后,三个卷积的输出与额外的残差输入按通道连接在一起。在编码器中,此残差输入是上述 q 空间张量,在解码器中,它是跨空间维度重复的目标 b 向量。通过包含此附加输入,b向量方向性和图像信息在整个网络中具有直接的传播,使模型能够更轻松地学习数据中复杂的q空间关系。(这一块看的不是很明白,也就是这一块困惑住了这个论文中的方法实现)
实施详细信息
所有卷积层,不包括 ConvLSTM 层和解码器中的最后两个卷积层,都由以下内容组成:卷积操作、Swish 激活函数(Ramachandran 等人,2017 年)以及实例或批量归一化。最后两个解码器层没有归一化,由于dMRI严格为正,因此在最后一层中使用整流线性单元(ReLU)激活代替Swish激活。ConvLSTM是Shi等人(2015)中提出的2D ConvLSTM的3D扩展,其中标准长短期记忆(LSTM)单元的密集连接被卷积内核取代。它使用在 LSTM 细胞内发现的标准激活,并且没有标准化。除 ConvLSTM 层外,每个卷积层都将 q 空间维度视为额外的批处理维度,因此在 q 空间样本之间共享参数。所有卷积层都使用 (1 × 1 × 1) 步幅。用于每层的超参数可以在图A.1中找到,并且是通过使用KerasTuner(O’Malley等人,2019)和超带算法(Li等人,2017)的超参数搜索获得的。使用优化器Adam(Kingma和Ba,2014)对模型进行了120个epoch的训练,平均绝对误差(MAE)损失函数和0.001的学习率。用于分析的权重在验证数据集中表现最佳。训练和验证数据集分别由来自 27 个和 3 个 HCP 受试者的数据组成。
2.3.SH Q 空间插值
为了使用 SH 插值 dMRI 数据,使用下面等式 中的伪反最小二乘法找到每个空间体素的第一个 SH 系数 csh,
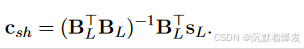
在这里,BL是一个矩阵,表示低角分辨率数据集的SH基,其中每行都包含在给定扩散方向上采样的SH膨胀。sL 是包含在不同扩散方向上测量的信号体素的矢量。全分辨率数据集 sH 仅通过方程 (2) 重建,其中 BH 是包含壳内所有扩散方向的 SH 基矩阵,
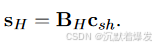
采样以获得 BL 和 BH 的 SH 基函数集是经过修改后的 SH 函数 , ̃ Ym l (θ, φ)首先在(2007) Tournier 等人中定义。 :

其中 Y m l (θ, φ) 定义 l 和 m 阶的 SH 基函数。
3 实验与结果
我们评估了我们的模型在 HCP 数据集中的 8 个以前未见过的受试者上的性能,针对三个扩散壳和不同的 q 空间欠采样率。所列表格中的每个结果都是从单独训练的模型获得的,具有相同的架构和超参数,但 3D RCNN(组合)模型除外。相反,该模型同时使用所有三个 b 值进行训练。作为基线比较,将 RCNN 模型的结果与 SH 插值进行比较。这里,使用最大 SH 阶数 2,因为发现这可以在所使用的子采样比率内产生最准确的重建。均方根误差 (RMSE) 和平均结构相似性指数测量 (MSSIM) 结果是相对于八个受试者测量的扩散方向的基本事实给出的。所列表格中的 RMSE 和 MSSIM 以八个受试者的 q 空间样本的平均值和标准差形式给出。这些误差分布中的每个值都是每个 q 空间样本和受试者内所有空间维度的平均值。
表 1 比较了三种 ASR 模型在不同子采样率下的性能。所提出的 3D RCNN 在 RMSE 和 MSSIM 的所有三个子采样率上均优于 1D 变体和 SH 插值。性能的最大相对增益出现在最低子采样率 qin = 6 时。此处,与 SH 插值相比,3D RCNN 的 RMSE 降低了 34.1%,RMSE 标准差降低了 72.4%。这表明 3D RCNN 模型能够有效地利用补丁内相邻体素之间的关系。值得注意的是,与 SH 插值相比,3D RCNN 的相对性能随着子采样率的增加而降低。这表明在低子采样范围内,学习到的联合 kq 空间分布为 3D 模型提供了 q 空间分布中不存在的附加信息。然而,在较高的采样制度中,联合分布中存在的附加信息相对减少。这意味着超过某个阈值后,可以单独使用 q 空间分布来有效地在点之间进行插值,而不需要 3D 模型提供的附加空间信息。
表 1:不同模型中 b = 1000 的 8 名受试者的 ASR 平均表现。最佳结果以粗体突出显示。

表 2 同样显示,通过单独训练的 3D RCNN 模型获得了最佳性能,这次是在所有 b 值 shell 上。此外,与 SH 插值相比,组合的 3D 模型在所有壳和两个指标上均优于 1D 模型,同时在所有壳中具有更高的 MSSIM,在 b = 2000 和 b = 3000 壳内具有更低的 RMSE。特别是,在 b 值 b = 2000 和 b = 3000 时,SH 插值性能相对于所有三个 RCNN 模型均有所下降。鉴于较高的 b 值产生较低的信噪比,这表明深度学习模型可能更与更简单的 SH 插值模型相比,对噪声具有鲁棒性。通过 RMSE 和 MSSIM 值的差异可以看出较高 b 值下的偏移分布的影响,与模型无关。 RMSE 不是标准化指标,随着 b 值的增加而减小,而标准化 MSSIM 指标中不存在这种关系。
表 2:qin = 10 和 qout = 80 的 8 名受试者的 ASR 平均表现。最佳结果以粗体突出显示。

图 2 显示了不同模型中一位受试者的分数各向异性 (FA) 绝对误差 (AE) 的轴向切片。这里 AE 明显在 3D RCNN 模型中最低,而基线导出的 AE 低于 SH 和 1D 模型。当将轴向切片分割为 WM 和灰质 (GM) 体素并分别分析每种组织类型的性能时,这种趋势也是如此。相对较低的基线误差可能是由于扩散张量成像 (DTI) 不需要 HARDI,因此即使在低 q 空间采样率下也是稳健的。图 B.1 显示了用于推导 FA 图的推断 dMRI 数据的 RMSE,并且与图 2 中的结果一致。特别是,3D 模型中存在的较低相对 WM 错误率对于下游分析技术非常重要,因为需要 HARDI,因为他们经常关注包含高比例 WM 的体素。不同子采样率和 b 值下的 WM 和 GM RMSE 细分可在附录 B 中找到,其中包含与表 1 和 2 中呈现的类似趋势。WM 和 GM 掩模是使用 FSL FAST 生成的(Zhang 等人, 2001),而 DTI 指标是使用 FSL Diffusion Toolbox 生成的。
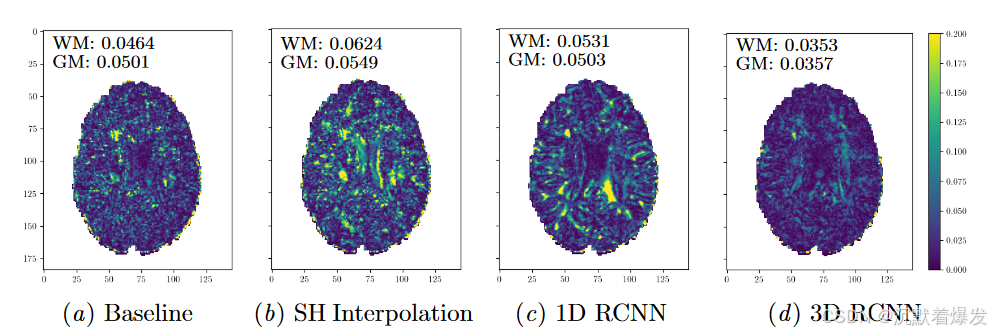
图 2:测试数据集中一名受试者的 FA AE 轴向切片。 ASR 的执行条件为 qin = 6、qout = 84。WM 和 GM 值分别仅在 WM 和 GM 掩模内的体素上进行平均。基线 FA 图是根据 qin 体积计算的,而其他 FA 图是根据 qin 和 qout 数据得出的。
4.结论和今后的工作
我们提出了一种循环的3D卷积架构,用于对弥散MRI数据执行角度超分辨率。我们将这种方法与相关的角度插值技术以及架构的一维变体进行了比较**。我们证明了 3D 模型在各种子采样比率和 b 值下表现最佳。在传统上,我们表明这种架构可用于训练能够同时推断几个不同 B 值的模型,尽管与单独训练的模型相比性能略有降低。**
需要进一步的工作来量化该方法在分布外数据集中的稳健性,例如具有病理学和不同采集参数的数据集,并提供与非复发卷积架构的比较。这项工作的未来扩展将是扩展模型以明确推断其他壳,从而执行多壳角超分辨率。在扩展该模型时,应探索子采样比率对多壳推理的影响。此外,未来的工作应研究角度超分辨率对需要高角分辨率的下游单壳和多壳分析的影响。