
简介:HibernateExample是一个详细的Java应用程序示例,演示了如何使用Hibernate框架进行对象关系映射(ORM)。这个例子全面展示了Hibernate的配置、实体类创建、映射文件定义、数据访问对象(DAO)的实现、以及事务管理。Hibernate框架简化了Java与数据库的交互,通过对象映射,使得开发者可以采用面向对象的方式来操作数据库。本例中的关键知识点包括Hibernate配置、实体类的定义与注解、映射文件或注解方式的映射规则、DAO层的CRUD操作、Session接口的使用、事务管理的实现、Criteria查询与HQL的应用,以及第二级缓存的配置。通过HibernateExample,开发者可以学习到将ORM思想应用于实际项目的方法,并提升开发效率,减少与数据库相关的错误。 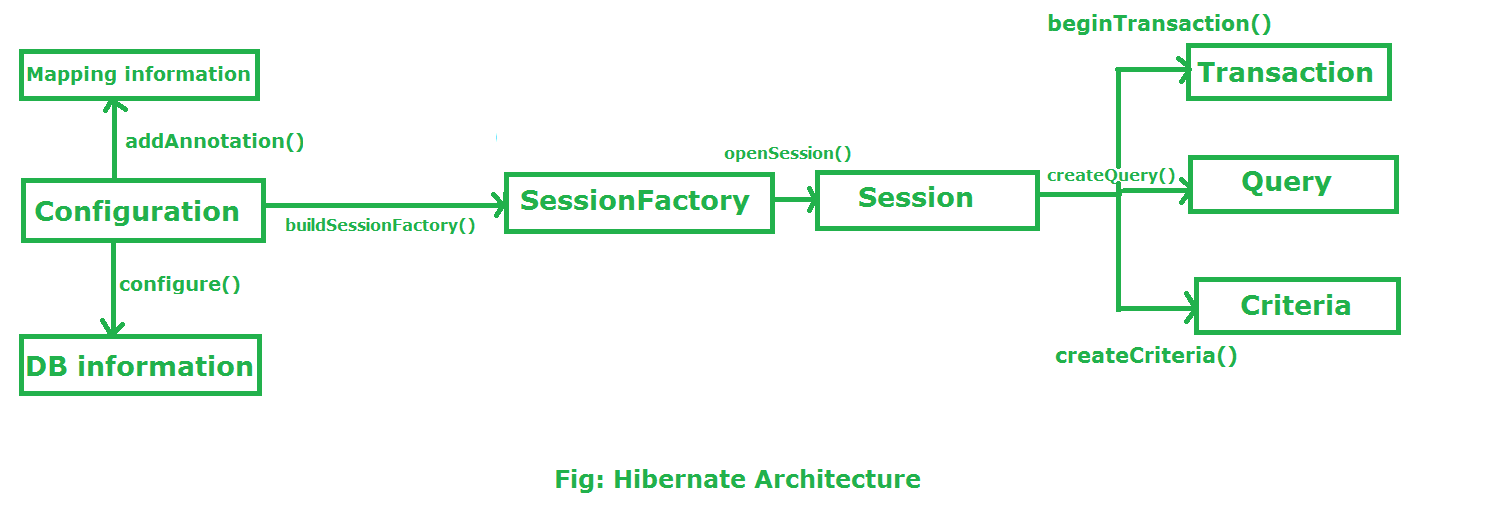
1. Hibernate框架基础
1.1 Hibernate框架概述
Hibernate是一个开源的对象关系映射(ORM)框架,它为Java语言提供了一种优雅的方式来处理关系型数据库。通过Hibernate,开发者可以像操作对象那样,使用Java代码来操作数据库,无需编写大量的SQL语句。这极大地提高了代码的可维护性和项目的开发效率。
1.2 ORM的概念
在深入了解Hibernate之前,需要掌握ORM(对象关系映射)的概念。ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系型数据库中。它实现了数据模型与对象模型之间的解耦,让开发者能够专注于业务逻辑的实现,而不是繁琐的数据操作细节。
1.3 Hibernate的优势
Hibernate框架的优势在于其强大的数据库操作能力和灵活性。它支持主流的数据库系统,并提供了丰富的API和配置选项,使得开发者可以根据具体需求调整数据库操作行为。此外,Hibernate的二级缓存机制能显著提高频繁读取操作的性能,减少了数据库的访问次数。
// 示例代码:一个简单的Hibernate使用例子
// 创建一个实体类
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String name;
// ... 其他属性、getter和setter方法
}
// 使用Hibernate创建session并保存实体
Session session = HibernateUtil.getSessionFactory().openSession();
Transaction transaction = session.beginTransaction();
User user = new User();
user.setName("Example User");
session.save(user);
***mit();
session.close();
以上代码展示了如何使用Hibernate框架创建一个简单的用户实体并将其保存到数据库中。这段代码通过注解的方式定义了实体类的映射关系,创建了一个session并执行了一个事务,最后关闭了session。这种简单的使用方式,是Hibernate框架易用性的一个体现。
2. Hibernate配置细节
2.1 环境搭建与配置文件解析
2.1.1 Hibernate开发环境的搭建
在深入探讨Hibernate配置细节之前,确保我们的开发环境已经正确搭建。Hibernate是一个开源的Java ORM(对象关系映射)框架,它极大地简化了数据库操作,将Java对象映射到数据库表中,从而实现数据的持久化。
首先,您需要确保已经安装了Java开发环境(JDK)和一个适合的IDE(如IntelliJ IDEA, Eclipse等)。之后,我们需要添加Hibernate相关依赖到我们的项目中。如果您使用的是Maven,那么可以在pom.xml文件中添加如下依赖:
<dependencies>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>5.4.30.Final</version>
</dependency>
<!-- 添加其他依赖,例如数据库连接池、日志记录等 -->
</dependencies>
使用Gradle时,可以添加如下依赖:
dependencies {
implementation 'org.hibernate:hibernate-core:5.4.30.Final'
// 添加其他依赖
}
完成这些步骤后,您的基础开发环境就已经搭建好了。接下来,您需要配置Hibernate,以便与数据库进行交云。
2.1.2 Hibernate配置文件结构与关键属性
Hibernate通过配置文件定义与数据库交互的参数。主要配置文件是 hibernate.cfg.xml 。这个文件位于类路径的根目录。
配置文件的基本结构大致如下:
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"***">
<hibernate-configuration>
<session-factory>
<!-- 连接数据库的配置 -->
<property name="connection.driver_class">com.mysql.cj.jdbc.Driver</property>
<property name="connection.url">jdbc:mysql://localhost:3306/your_database</property>
<property name="connection.username">your_username</property>
<property name="connection.password">your_password</property>
<!-- 配置方言,根据使用的数据库调整 -->
<property name="dialect">org.hibernate.dialect.MySQLDialect</property>
<!-- 显示SQL语句 -->
<property name="show_sql">true</property>
<!-- 自动建表 -->
<property name="hbm2ddl.auto">update</property>
<!-- 配置c3p0数据库连接池 -->
<property name="connection.pool_size">10</property>
</session-factory>
</hibernate-configuration>
在上述配置中, connection.driver_class 指定了JDBC驱动, connection.url 、 connection.username 和 connection.password 分别定义了数据库的连接地址、用户名和密码。 dialect 属性则定义了与数据库的方言,Hibernate根据这个方言生成对应的SQL语句。 show_sql 属性设置为 true ,可以让我们看到Hibernate生成的SQL语句,这对于调试非常有用。 hbm2ddl.auto 属性用于控制数据库表的创建和更新。 connection.pool_size 配置了数据库连接池的大小。
这些配置信息的组合构成了Hibernate与数据库进行交互的基础。每个属性都需要根据实际的应用场景进行调整,确保Hibernate可以高效地工作。
2.2 数据源配置与集成
2.2.1 数据源的选择与配置方法
在企业级应用中,直接使用JDBC连接池是不常见的,因为这种方式配置繁琐,代码复杂,扩展性差。通常我们会选择数据源配置与集成的第三方库,以获得更高级的特性,比如连接池、自动重连等。常见的第三方数据源实现包括c3p0、HikariCP和Apache DBCP。
以c3p0为例,它是一个开源的JDBC连接池实现,Hibernate可以与之很好地集成。在 hibernate.cfg.xml 配置文件中,可以使用以下配置来集成c3p0:
<property name="connection.provider_class">org.hibernate.connection.C3P0ConnectionProvider</property>
<property name="c3p0.max_size">20</property>
<property name="c3p0.min_size">5</property>
<property name="c3p0.timeout">1800</property>
<property name="c3p0.max_statements">50</property>
配置中 connection.provider_class 指定了使用c3p0作为连接提供者。c3p0的属性如 max_size 、 min_size 、 timeout 和 max_statements 分别定义了连接池的最大、最小连接数、超时时间和最大缓存语句数。
接下来是集成HikariCP,它是一个性能非常优秀的连接池库。Hibernate同样可以与HikariCP无缝集成。在配置文件中添加如下配置:
<property name="hibernate.connection.provider_class">org.hibernate.hikaricp.internal.HikariCPConnectionProvider</property>
<property name="hibernate.hikari.connectionTimeout">30000</property>
<property name="hibernate.hikari.maximumPoolSize">20</property>
<property name="hibernate.hikari.poolName">HikariCPConnectionPool</property>
通过设置 hibernate.hikari 命名空间下的属性,可以控制HikariCP的行为。这里 connectionTimeout 、 maximumPoolSize 和 poolName 分别定义了连接池的超时时间、最大连接数和连接池的名称。
集成数据源不仅需要在配置文件中添加适当的属性,还需要在项目中添加相应的库。对于Maven项目,添加如下依赖:
<!-- 添加c3p0依赖 -->
<dependency>
<groupId>com.mchange</groupId>
<artifactId>c3p0</artifactId>
<version>*.*.*.*</version>
</dependency>
<!-- 添加HikariCP依赖 -->
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>4.0.3</version>
</dependency>
使用这些高级连接池可以提升应用的性能和稳定性,因为它们提供了高级的连接池管理功能和更优秀的性能。
2.2.2 集成第三方数据库连接池
在企业级应用中,集成第三方数据库连接池是常见的做法,因为它可以提高应用的性能和稳定性。除了c3p0和HikariCP,还有其他多种连接池可供选择,例如Apache DBCP和BoneCP。无论选择哪一种,Hibernate的集成方式都十分灵活。
以Apache DBCP为例,它是一个开源的数据库连接池,通过以下步骤集成:
- 将Apache DBCP添加到项目依赖中。对于Maven项目,添加如下依赖:
<!-- 添加Apache DBCP依赖 -->
<dependency>
<groupId>***mons</groupId>
<artifactId>commons-dbcp2</artifactId>
<version>2.8.0</version>
</dependency>
- 修改
hibernate.cfg.xml文件,将数据源配置为Apache DBCP提供的数据源:
<property name="connection.provider_class">***mons.dbcp2.BasicDataSource</property>
<property name="driverClassName">com.mysql.cj.jdbc.Driver</property>
<property name="url">jdbc:mysql://localhost:3306/your_database</property>
<property name="username">your_username</property>
<property name="password">your_password</property>
<!-- Apache DBCP连接池相关配置 -->
<property name="initialSize">10</property>
<property name="maxTotal">20</property>
<property name="maxIdle">10</property>
<property name="minIdle">5</property>
<property name="maxWaitMillis">30000</property>
在这配置中, initialSize 、 maxTotal 、 maxIdle 、 minIdle 、 maxWaitMillis 等属性定义了Apache DBCP连接池的行为特性。
通过上述步骤,我们已经将Apache DBCP连接池成功集成到Hibernate配置中。集成过程根据选择的连接池而异,但Hibernate提供了一个统一的接口,即 ConnectionProvider ,所有数据源的集成都遵循这一模式。这大大简化了集成过程,同时也保持了Hibernate的灵活性和扩展性。
最后,必须强调的是,选择合适的连接池会根据应用的具体需求而定。例如,如果您非常关注性能,可能会倾向于选择HikariCP。如果您的应用需要更高级的特性,如数据源监控,Apache DBCP可能是更好的选择。无论选择哪种连接池,Hibernate都能提供清晰、灵活的集成方式。
2.3 日志与性能监控
2.3.1 日志配置与管理
日志记录是诊断和监控软件应用中的关键功能。在Hibernate中,它不仅帮助我们理解框架内部的工作机制,同时也是排查应用程序性能问题的重要工具。Hibernate使用SLF4J作为其日志门面,并支持多种日志实现,如Log4j、JUL(Java Util Logging)和Simple等。
在 hibernate.cfg.xml 配置文件中,需要设置 show_sql 属性为 true 以打印所有的SQL语句。为了让日志记录更加详细,我们通常还会设置 format_sql 属性,这使得打印出来的SQL语句格式化,更易于阅读。
<property name="show_sql">true</property>
<property name="format_sql">true</property>
对于日志级别和输出,Hibernate并没有提供内置的配置,我们需要在项目中配置日志框架。以Log4j为例,首先在项目中添加Log4j的依赖:
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.14.1</version>
</dependency>
然后配置 log4j2.xml 文件,来控制日志的输出级别和格式:
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
</Console>
</Appenders>
<Loggers>
<Logger name="org.hibernate" level="debug"/>
<Root level="error">
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
在该配置中,我们定义了一个控制台输出器,日志格式被设置为 %d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n ,这样可以很清晰地看到每个日志条目的时间、线程、级别、日志记录器和消息内容。我们同时将 org.hibernate 包的日志级别设置为 debug ,以捕获Hibernate框架生成的所有调试信息。
2.3.2 性能监控工具和策略
在运行时,性能监控是确保应用程序稳定运行的重要环节。Hibernate提供了一些内置的工具和策略,来帮助我们监控和优化应用性能。
例如,Hibernate允许开发者配置二级缓存,以减少数据库访问次数和提高系统性能。在 hibernate.cfg.xml 中可以启用二级缓存:
<property name="cache.use_second_level_cache">true</property>
<property name="cache.region.factory_class">org.hibernate.cache.ehcache.EhCacheRegionFactory</property>
此外,Hibernate还提供了一些用于监控的工具,例如 Statistics 接口,它可以帮助我们收集关于Hibernate会话和持久化操作的统计信息。获取和使用这个接口的代码示例如下:
import org.hibernate.SessionFactory;
import org.hibernate.stat.Statistics;
// ...
SessionFactory sessionFactory = // 获取SessionFactory
Statistics statistics = sessionFactory.getStatistics();
statistics.setStatisticsEnabled(true); // 启用统计信息
// 运行一段时间的操作以收集统计数据
// 获取统计数据
System.out.println("Total queries: " + statistics.getQueryExecutionCount());
System.out.println("Total inserts: " + statistics.getInsertCount());
System.out.println("Total updates: " + statistics.getUpdateCount());
System.out.println("Total deletes: " + statistics.getDeleteCount());
System.out.println("Cache hit ratio: " + statistics.getQueryCacheHitCount());
通过启用统计信息并运行应用一段时间后,您可以得到关于Hibernate操作的各种统计信息,如查询次数、插入次数、更新次数、删除次数等,这些对于分析系统性能和定位瓶颈非常有用。
对于更深入的性能监控,第三方工具如JProfiler和VisualVM可以提供更丰富的性能监控功能。这些工具能够监控CPU使用率、内存分配、数据库查询时间、锁争用情况等,并提供界面化的方式来展示和分析这些数据。
综上所述,Hibernate已经内建了一些基本的监控和诊断机制,但结合使用更高级的性能监控工具,可以更全面地了解应用程序的运行状况和性能瓶颈。开发者应该根据应用的具体需求和环境,选择合适的工具和技术来构建一个全面的性能监控策略。
通过本章节的介绍,您应该已经掌握如何搭建Hibernate开发环境,以及如何配置和管理Hibernate的配置文件,包括连接数据库和集成第三方数据源。同时,我们也讲解了如何配置日志系统以监控Hibernate的运行状态,以及使用Hibernate内置工具和第三方工具进行性能监控。这些技能是构建高效和稳定的Hibernate应用的基础。
3. 实体类与数据库映射
3.1 实体类的基本概念
3.1.1 实体类的定义与属性映射
在Hibernate中,实体类(Entity Class)是Java中对应数据库表的类。每个实体类实例代表表中的一行数据。实体类的属性和表中的列相对应,并通过反射机制与数据库表的列进行映射。
实体类通常需要遵循以下规范:
- 它应该使用
@Entity注解,以表明这个类是一个实体。 - 实体类中被映射的属性需要使用
@Id来定义主键。 - 其他属性可以使用
@Column等注解来定义如何映射到数据库列。
例如,考虑一个简单的 User 实体类,其映射到名为 users 的数据库表:
import javax.persistence.*;
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "id")
private Long id;
@Column(name = "name")
private String name;
// 其他属性和getter/setter方法
}
在这个例子中, @Entity 声明了类 User 是一个实体。 @Table(name = "users") 指定该实体对应数据库中的 users 表。 @Id 和 @GeneratedValue 定义了主键字段以及主键生成策略。 @Column(name = "name") 则映射了 name 属性到表的 name 列。
3.1.2 主键生成策略及其适用场景
主键生成策略(Primary Key Generation Strategies)是用于在数据库表中生成唯一标识记录的主键值的方法。在Hibernate中, @GeneratedValue 注解可以用来指定主键生成策略。
以下是Hibernate支持的几种主键生成策略:
-
GenerationType.AUTO:由底层数据库自动选择合适的主键生成策略。 -
GenerationType.IDENTITY:使用数据库自增字段作为主键。 -
GenerationType.SEQUENCE:使用数据库序列来生成主键值。 -
GenerationType.TABLE:使用单独的表来维护主键值。
这些策略各有其适用场景:
-
GenerationType.AUTO适合大多数情况,因为它简化了配置。 -
GenerationType.IDENTITY适合于MySQL、PostgreSQL等支持自增字段的数据库。 -
GenerationType.SEQUENCE适用于Oracle等数据库,这些数据库具有序列对象。 -
GenerationType.TABLE可以跨数据库保持一致,但它可能影响性能,因为它需要额外的表操作。
每种策略都有其优缺点,开发者应根据具体需求和数据库特性选择最合适的策略。
3.2 映射文件详解
3.2.1 映射文件结构与元素解析
映射文件是定义实体类和数据库表之间映射的XML文件。它的基本结构和关键元素包括:
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "***">
<hibernate-mapping>
<class name="com.example.model.User" table="users">
<id name="id" column="id">
<generator class="native"/>
</id>
<property name="name" column="name"/>
<!-- 其他映射元素 -->
</class>
</hibernate-mapping>
-
hibernate-mapping:根元素,包含了所有的映射定义。 -
class:定义了实体类和数据库表之间的映射关系。name属性指定实体类的全限定名,table属性指定对应的数据库表名。 -
id:定义了实体类中的主键属性和数据库表中的主键列的映射关系。generator元素用于配置主键生成策略。 -
property:定义实体类中非主键属性与数据库列之间的映射关系。
映射文件中还可以包含许多其他复杂的元素,例如集合映射、继承映射、组件映射等。
3.2.2 复杂关系映射的实现方式
在实体类与数据库之间映射复杂关系时,如一对多、多对多等,可以通过映射文件来实现。这些关系通常需要额外的映射配置来维护。
以一对多关系为例,一个 User 实体可能有多个 Order 实体。在映射文件中,可以这样实现:
<class name="com.example.model.User" table="users">
<!-- 主键映射 -->
<set name="orders" inverse="true" cascade="all" table="orders">
<key column="user_id"/>
<one-to-many class="com.example.model.Order"/>
</set>
</class>
<class name="com.example.model.Order" table="orders">
<!-- 主键映射 -->
<many-to-one name="user" column="user_id" not-null="true"/>
</class>
这里, <set> 元素用于表示一对多关系,其中 <key> 元素定义了外键列, <many-to-one> 元素用于在 Order 类中建立到 User 类的多对一关系。
对于多对多关系,通常需要一个中间关联表来维护关系,映射方式类似于一对多,但会涉及额外的 <map> 、 <join> 元素来定义中间表。
复杂关系映射通过维护额外的数据库表或列,使得Java实体间的关联关系能够在数据库层面得到反映和管理。这些映射文件的配置,确保了实体类对象在持久化时,能够正确地反映出各种业务关系,从而简化了应用层的数据操作逻辑。
4. 映射文件与注解方式
4.1 注解使用详解
4.1.1 常用注解及其属性配置
在Hibernate中,注解是一种简便的方式来定义实体类与数据库表之间的映射关系。注解提供了一种更为直观、易于理解的方式来描述映射,避免了XML映射文件中的繁琐配置。下面是一些常用的注解及其属性配置。
@Entity
@Table(name = "USER")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Column(name = "NAME")
private String name;
@Column(name = "EMAIL")
private String email;
// getters and setters
}
-
@Entity:标识该类为一个实体类。 -
@Table:指定实体对应的数据库表名。 -
@Id:标识实体类的主键。 -
@GeneratedValue:定义主键生成策略,例如自增(GenerationType.IDENTITY)。 -
@Column:映射类属性到数据库表的列。
注解配置可以直接在Java代码中完成,这样在编译时就能够对映射错误进行检查,而不必等到运行时。每一种注解都有丰富的属性可以配置,例如,通过 @Column 注解的 unique 和 nullable 属性可以指定列的唯一性和可空性。
4.1.2 注解与映射文件的对比分析
注解和映射文件各有优缺点,注解的方式更简洁直观,能够直接在实体类中看到所有的映射细节,便于管理,也更加安全。但是注解的缺点是难以全局修改配置,修改时需要重新编译项目。
XML映射文件则提供了更高的灵活性,可以集中管理,方便进行全局配置的修改,也更易于版本控制和维护,尤其是在大型项目中。不过,XML配置更加繁琐,有时需要在两个地方进行配置(Java类和XML文件),容易产生配置不一致的问题。
4.2 注解与XML的集成应用
4.2.1 注解与XML混合使用的场景与方法
在实际开发中,有时候需要结合注解和XML映射文件来实现更复杂的配置。Hibernate支持将这两种方式结合起来使用,通过注解定义基本的映射,再通过XML覆盖或者扩展注解中定义的映射。
例如,可以使用注解来定义基本的字段映射,然后使用XML映射文件来配置复杂的关联关系。下面是一个结合使用的例子:
@Entity
@Table(name = "ADDRESS")
public class Address {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "CITY")
private String city;
// other fields, getters and setters
}
<mapping class="com.example.Address" />
在这里,我们使用注解定义了 Address 类和数据库表的映射,然后在XML文件中指定了该映射类。如果需要对 Address 的映射进行更复杂的配置,可以在XML文件中进行。
4.2.2 应用案例:灵活配置实体关系
为了展示如何灵活配置实体关系,我们假设需要映射 User 和 Address 两个实体,并且 User 实体与 Address 实体之间是一对一的关系。
首先使用注解定义基本的实体和主键:
@Entity
@Table(name = "USER")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "ADDRESS_ID", referencedColumnName = "ID")
private Address address;
// other fields, getters and setters
}
然后在XML映射文件中配置一对一关系的细节:
<hibernate-mapping>
<class name="com.example.User" table="USER">
<id name="id" column="ID">
<generator class="native"/>
</id>
<one-to-one name="address" class="com.example.Address"
constrained="true" cascade="all-delete-orphan"/>
</class>
</hibernate-mapping>
这里通过注解定义了一对一关系,并使用XML映射文件来指定了级联操作和约束,提供了灵活性。这展示了如何结合注解和XML映射文件来完成复杂的映射需求。
5. Hibernate高级应用
5.1 数据访问对象(DAO)实现
数据访问对象(DAO)是一种设计模式,它抽象和封装了所有对数据源的访问,使得业务逻辑与数据访问代码解耦。在Hibernate中实现DAO可以提高代码的可维护性和可测试性。
5.1.1 DAO模式与Hibernate集成
Hibernate提供了一个灵活的DAO框架,通过集成Hibernate的Session API,可以简化数据访问代码的编写。通常,DAO层会包含对特定实体的基本操作,如增加、删除、修改和查询。
public class UserDAO {
private SessionFactory sessionFactory;
public void setSessionFactory(SessionFactory sessionFactory) {
this.sessionFactory = sessionFactory;
}
public void addUser(User user) {
Session session = sessionFactory.getCurrentSession();
session.save(user);
}
public User getUser(Long id) {
Session session = sessionFactory.getCurrentSession();
return session.get(User.class, id);
}
// Other CRUD methods...
}
在上面的例子中, UserDAO 类通过Hibernate的 SessionFactory 获取 Session 对象来执行数据库操作。
5.1.2 框架DAO与自定义DAO的权衡
虽然框架提供的DAO可以加速开发,但自定义DAO提供了更大的灵活性和可定制性。开发者可以根据业务需求定制特定的数据访问方法,而无需依赖于框架提供的抽象。
5.2 Hibernate Session API使用
Hibernate的Session API是与数据库交互的主要接口,它提供了持久化对象的操作方法。
5.2.1 Session生命周期与管理
Session是与数据库交互的单线程单元,它的生命周期从打开到关闭是不可逆的。管理Session的最佳实践是使用 getCurrentSession() 方法,它可以保证Session与线程绑定,避免并发问题。
try {
Session session = sessionFactory.getCurrentSession();
session.beginTransaction();
// 数据操作代码...
session.getTransaction().commit();
} catch (Exception e) {
session.getTransaction().rollback();
throw e;
} finally {
sessionFactory.getCurrentSession().close();
}
5.2.2 事务管理与Session缓存操作
事务管理是保证数据一致性的关键。在Hibernate中,可以通过Session对象的 getTransaction() 方法进行事务管理。同时,Session缓存用于跟踪和管理所有持久化对象的状态。
5.3 事务管理策略
事务管理保证了数据操作的原子性,确保了数据的完整性和一致性。
5.3.1 声明式事务管理的实现与配置
声明式事务管理通过配置实现,不需要在代码中显式声明事务边界。它通常通过Spring框架的 @Transactional 注解实现。
@Transactional
public void updateUserData(User user) {
// 更新用户数据的业务逻辑
}
5.3.2 编程式事务管理的策略与案例
编程式事务管理通过代码来控制事务边界。在Hibernate中,可以通过Session对象的 beginTransaction() , commit() 和 rollback() 方法来实现。
Session session = sessionFactory.openSession();
Transaction tx = null;
try {
tx = session.beginTransaction();
// 执行数据操作...
***mit();
} catch (Exception e) {
if (tx != null) tx.rollback();
throw e;
} finally {
session.close();
}
5.4 Criteria查询机制
Hibernate的Criteria查询提供了一种面向对象的查询API,它允许开发者以编程的方式构建查询,提高了查询的灵活性。
5.4.1 Criteria API的基本使用方法
使用Criteria API,可以按类型安全的方式构建查询。
Session session = sessionFactory.getCurrentSession();
Criteria criteria = session.createCriteria(User.class);
criteria.add(Restrictions.eq("username", "exampleUser"));
List<User> results = criteria.list();
5.4.2 实现复杂查询的策略与技巧
通过Criteria API,可以轻松地添加排序、分页以及连接查询等复杂查询。
5.5 HQL语言应用
HQL(Hibernate Query Language)是一种面向对象的查询语言,它提供了SQL无法比拟的灵活性和对象语义。
5.5.1 HQL语言基础与高级特性
HQL允许开发者使用实体类名称和属性,而不是表名和列名,这使得HQL更具可读性和可维护性。
Session session = sessionFactory.getCurrentSession();
String hql = "FROM User u WHERE u.age BETWEEN :minAge AND :maxAge";
Query query = session.createQuery(hql);
query.setParameter("minAge", 18);
query.setParameter("maxAge", 30);
List<User> results = query.list();
5.5.2 优化HQL查询性能的策略
优化HQL查询包括使用投影减少数据加载量,以及使用二级缓存来提高查询性能。
5.6 第二级缓存配置与优化
Hibernate提供了第二级缓存,可以跨越多个事务和用户会话,提高数据访问的性能。
5.6.1 Hibernate二级缓存的原理与配置
第二级缓存由 SessionFactory 管理,配置第二级缓存需要在配置文件中指定哪些实体类或集合需要被缓存。
<hibernate-configuration>
<session-factory>
<!-- Other configuration settings -->
<property name="cache.provider_class">org.hibernate.cache.HashtableCacheProvider</property>
<property name="cache.use_second_level_cache">true</property>
<property name="cache.region.factory_class">org.hibernate.cache.ehcache.EhCacheRegionFactory</property>
<!-- Other cache configurations -->
</session-factory>
</hibernate-configuration>
5.6.2 二级缓存的使用案例与性能优化
使用二级缓存时,要合理配置缓存策略,如设置合适的超时时间和选择合适的缓存区域配置。
Session session = sessionFactory.getCurrentSession();
session.enableFilter("userFilter").setParameter("userStatus", "active");
List<User> activeUsers = session.createQuery("FROM User u").list();
在以上章节中,我们探讨了Hibernate高级应用,包括数据访问对象的实现、Session API的使用、事务管理策略、Criteria查询与HQL语言的应用,以及二级缓存的配置和优化。这些高级特性能够让Hibernate框架的应用更加高效和灵活。
简介:HibernateExample是一个详细的Java应用程序示例,演示了如何使用Hibernate框架进行对象关系映射(ORM)。这个例子全面展示了Hibernate的配置、实体类创建、映射文件定义、数据访问对象(DAO)的实现、以及事务管理。Hibernate框架简化了Java与数据库的交互,通过对象映射,使得开发者可以采用面向对象的方式来操作数据库。本例中的关键知识点包括Hibernate配置、实体类的定义与注解、映射文件或注解方式的映射规则、DAO层的CRUD操作、Session接口的使用、事务管理的实现、Criteria查询与HQL的应用,以及第二级缓存的配置。通过HibernateExample,开发者可以学习到将ORM思想应用于实际项目的方法,并提升开发效率,减少与数据库相关的错误。