python可以让你的报表做得又快又好,今天给大家分享一篇python自动化办公的干货。
总体思路是:
1. 从网上获取科幻电影排行榜数据
2.将获取的数据写入excel,并自动修改excel样式
代码所需要的第三方库为requests,pandas,openpyxl,pywin32。
pip install requests
pip install pandas
pip install openpyxl
pip install pywin32从网上获取科幻电影排行榜数据,主要使用requests库从网页获取数据。
import requests
import pandas as pd
# 获取一页的数据
def get_one_page_data(start: int = 0):
'''
:param start: 每页20条数据,start的值为0,1,2,...
:return:
'''
url = f"https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start={start * 20}&limit=20"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
}
resp = requests.get(url=url, headers=headers)
# 如果请求正确,则返回数据
if resp.status_code == 200:
resp = resp.json()
# 中文字段名,与返回结果的英文字段名要一一对应
columns = ['rank', 'title', 'types', 'regions', 'actors', 'rating', 'cover_url', 'is_playable', 'id', 'url',
'release_date', 'actor_count', 'vote_count', 'score', 'is_watched']
columns_cn = ['排名', '电影名', '类型', '地区', '演员列表', '评价', '背景图片', '可播放', 'id', 'url',
'上映时间', '演员数量', '评价数', '评分', '可观看']
# 构建一个空数据,为了确保返回数据为空时,数据格式保持一致
data = {}
for col in columns:
data[col] = []
# 往data里面添加数据
for res in resp:
for key, value in res.items():
if type(value) == list:
value = ','.join(value)
data[key] = data.get(key, []) + [value]
data = pd.DataFrame(data)
# 将data的行索引改为中文
data.columns = columns_cn
# 将'可播放'字段的true和false改为是、否
data['可播放'] = data['可播放'].map(lambda x: '是' if x else '否')
# 将'可观看'字段的true和false改为是、否
data['可观看'] = data['可观看'].map(lambda x: '是' if x else '否')
return data
raise ValueError("请求错误")
# 获取所有页的数据并写入excel表格
def get_total_data():
datas = []
for i in range(20):
data = get_one_page_data(i)
# 如果返回的数据为空,则表示已经获取完毕
if data.empty:
break
datas.append(data)
sleep(2) # 等待2秒,防止数据获取得太快
datas = pd.concat(datas, axis=0)
datas.to_excel('科幻片排行榜.xlsx', sheet_name='sheet1', index=False)执行get_total_data()方法,生成excel表格。因为设置的excel格式为xlsx,所以在使用pandas写入excel方法时,需要openpyxl引擎。这就是为什么全文都没有看见openpyxl的使用,却依然需要安装openpyxl库。
当你学会了数据抓取,就一定会学数据分析,pands是数据分析最好用的工具。当你想要实现数据永久化,无论是写入数据库还是写入excel,pandas也是你的最佳选择。
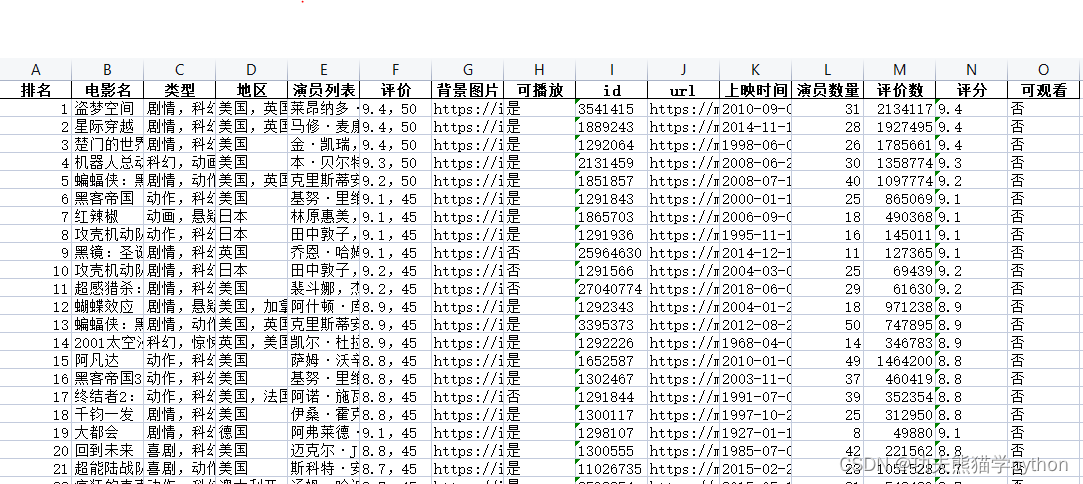
get_total_data()生成的excel效果如下,可以看到生成的excel样式比较丑,所以这里使用pywin32自动化处理excel,使excel更加beautiful。美化需求如下:
1.给excel所有激活的内容添加边框
2.给第一行添加筛选功能
3.冻结第二行第二列窗口,在上下左右拉动的时候,也可以一直看到电影名
4.用红色标注“莱昂纳多”主演的电影,让人一眼就知道男神有哪些电影上榜了
from win32com.client import Dispatch
# 调整excel格式
def adjust_excel_format():
excel = Dispatch('Excel.Application')
excel.Visible = 1
base_path = os.path.dirname(__file__)
wb = excel.WorkBooks.Open(os.path.join(base_path, '科幻片排行榜.xlsx')) # 注意:这里只能传绝对路径,不能传相对路径
ws = wb.Worksheets('sheet1')
rng = ws.UsedRange
cols = rng.Columns.Count
rows = rng.Rows.Count
# 给excel添加边框
rng.Borders.LineStyle = 1
rng.Borders.Weight = 2
# 调整宽度、自动换行
for col in range(1, cols + 1):
ws.Columns(col).AutoFit() # 自动调整宽度
ws.Columns(col).WrapText = True # 自动换行
ws.Columns(2).ColumnWidth = 15
ws.Columns(3).ColumnWidth = 20
ws.Columns(4).ColumnWidth = 20
ws.Columns(5).ColumnWidth = 100
# 冻结excel窗口
ws.Range("C2").Select()
excel.ActiveWindow.FreezePanes = True
# 给第一行添加筛选
ws.Range("A1").CurrentRegion.AutoFilter(1)
# 将”莱昂纳多“主演的电源名标红
target = "莱昂纳多"
for i in range(1, rows + 1):
target_rng = ws.Range(f"E{i}")
if target in target_rng.Text:
ws.Range(f"B{i}").Interior.Color = 255 # 单元格标为红色
wb.Save()
wb.Close()
excel.Quit()执行adjust_excel_format()方法,美化后的效果,是不是比之前的原始版本更nice。


全部代码如下:
import requests
import pandas as pd
from time import sleep
from win32com.client import Dispatch
import os
# 获取一页的数据
def get_one_page_data(start: int = 0):
'''
:param start: 每页20条数据,start的值为0,1,2,...
:return:
'''
url = f"https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start={start * 20}&limit=20"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
}
resp = requests.get(url=url, headers=headers)
# 如果请求正确,则返回数据
if resp.status_code == 200:
resp = resp.json()
# 中文字段名,与返回结果的英文字段名要一一对应
columns = ['rank', 'title', 'types', 'regions', 'actors', 'rating', 'cover_url', 'is_playable', 'id', 'url',
'release_date', 'actor_count', 'vote_count', 'score', 'is_watched']
columns_cn = ['排名', '电影名', '类型', '地区', '演员列表', '评价', '背景图片', '可播放', 'id', 'url',
'上映时间', '演员数量', '评价数', '评分', '可观看']
# 构建一个空数据,为了确保返回数据为空时,数据格式保持一致
data = {}
for col in columns:
data[col] = []
# 往data里面添加数据
for res in resp:
for key, value in res.items():
if type(value) == list:
value = ','.join(value)
data[key] = data.get(key, []) + [value]
data = pd.DataFrame(data)
# 将data的行索引改为中文
data.columns = columns_cn
# 将'可播放'字段的true和false改为是、否
data['可播放'] = data['可播放'].map(lambda x: '是' if x else '否')
# 将'可观看'字段的true和false改为是、否
data['可观看'] = data['可观看'].map(lambda x: '是' if x else '否')
return data
raise ValueError("请求错误")
# 获取所有页的数据并写入excel表格
def get_total_data():
datas = []
for i in range(20):
data = get_one_page_data(i)
# 如果返回的数据为空,则表示已经获取完毕
if data.empty:
break
datas.append(data)
sleep(2) # 等待2秒,防止数据获取得太快
datas = pd.concat(datas, axis=0)
datas.to_excel('科幻片排行榜.xlsx', sheet_name='sheet1', index=False)
# 调整excel格式
def adjust_excel_format():
excel = Dispatch('Excel.Application')
excel.Visible = 1
base_path = os.path.dirname(__file__)
wb = excel.WorkBooks.Open(os.path.join(base_path, '科幻片排行榜.xlsx')) # 注意:这里只能传绝对路径,不能传相对路径
ws = wb.Worksheets('sheet1')
rng = ws.UsedRange
cols = rng.Columns.Count
rows = rng.Rows.Count
# 给excel添加边框
rng.Borders.LineStyle = 1
rng.Borders.Weight = 2
# 调整宽度、自动换行
for col in range(1, cols + 1):
ws.Columns(col).AutoFit() # 自动调整宽度
ws.Columns(col).WrapText = True # 自动换行
ws.Columns(2).ColumnWidth = 15
ws.Columns(3).ColumnWidth = 20
ws.Columns(4).ColumnWidth = 20
ws.Columns(5).ColumnWidth = 100
# 冻结excel窗口
ws.Range("C2").Select()
excel.ActiveWindow.FreezePanes = True
# 给第一行添加筛选
ws.Range("A1").CurrentRegion.AutoFilter(1)
# 将”莱昂纳多“主演的电源名标红
target = "莱昂纳多"
for i in range(1, rows + 1):
target_rng = ws.Range(f"E{i}")
if target in target_rng.Text:
ws.Range(f"B{i}").Interior.Color = 255 # 单元格标为红色
wb.Save()
wb.Close()
excel.Quit()
if __name__ == '__main__':
get_total_data()
adjust_excel_format()