24年8月来自南京大学、复旦和华为诺亚实验室的论文“EmoTalk3D: High-Fidelity Free-View Synthesis of Emotional 3D Talking Head”。
这是一种合成具有可控情绪 3D talking head 的方法,具有增强的唇部同步和渲染质量。尽管该领域取得了重大进展,但先前的方法仍然存在多视角一致性和缺乏情感表现力的问题。为了解决这些问题,收集包含标定的多视角视频、情感注释和每帧 3D 几何的 EmoTalk3D 数据集。通过在 EmoTalk3D 数据集上进行训练,提出一种“语音-几何-外观”映射框架,该框架首先根据音频特征预测忠实的 3D 几何序列,然后根据预测的几何形状合成由 4D 高斯表示的 3D talking head 外观。外观进一步分解为规范高斯和动态高斯,从多视角视频中学习,并二者融合以渲染任意视角的 talking head 动画。此外,模型能够控制生成的 talking head 情绪,并且可以在宽视角下进行渲染。该方法在捕捉动态面部细节(如皱纹和细微表情)的同时,在唇部运动生成中表现出更好的渲染质量和稳定性。
如图所示:
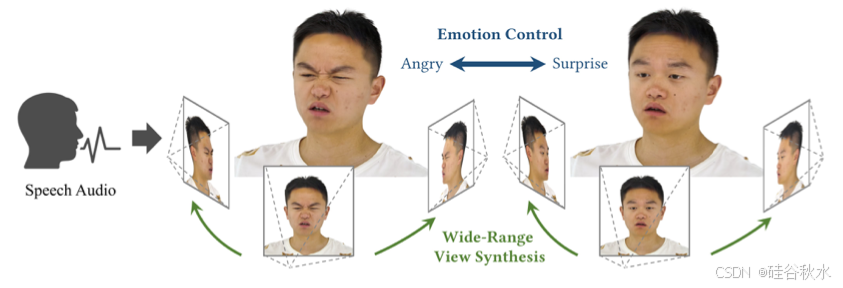
EmoTalk3D 数据集,是一个带有情绪注释的多视角人脸数据集,具有重建的 4D 人脸模型和精确的相机标定。该数据集包含 30 名受试者,每个受试者的数据包含 8 种特定情绪下的 20 句话,每种情绪有两种强度,每个受试者总计大约 20 分钟。收集的情绪包括“中性”、“愤怒”、“蔑视”、“厌恶”、“恐惧”、“快乐”、“悲伤”和“惊讶”。除了“中性”之外,每种情绪都捕捉到两种强度——“轻微”和“强烈”。邀请了专业的表演指导老师来指导受试者表达正确的情绪。
为了采集数据,在与受试者头部相同的水平面上建造了一个圆顶,其中有 11 个摄像机,并以 180 度均匀分布在头部周围,聚焦于正面。所有摄像机都与硬件同步系统进行时间同步,并在拍摄视频之前进行标定。利用最先进的多视图 3D 重建算法 [57] 来重建精确的 3D 三角网格模型,然后将其转换为拓扑均匀的 3D 网格模型 [2]。与每帧相对应的 3D 表面模型 3D 顶点构成 3D 点流,即 4D 点,用于训练 3D 说话脸模型。8种表情及其3D网格模型例子如图所示:

EmoTalk3D 数据集是一个包含情感注释和每帧 3D 面部几何的 talking face 数据集。表 1 比较了该数据集和以前的talking face 数据集的元参数。
如图所示,该视角合成方法由以下模块组成:1)音频编码器,对输入语音中的音频特征进行编码并提取情感标签;2)语音-到-几何网络(S2GNet),根据音频特征和情感标签预测动态 3D 点云;3)静态高斯优化与完成模块,用于建立规范的外观模型;4)几何-到-外观网络(G2ANet),基于动态 3D 点云合成面部外观。上述模块共同构成了用于情感 talking head 合成的“语音-到-几何-到-外观”映射框架。
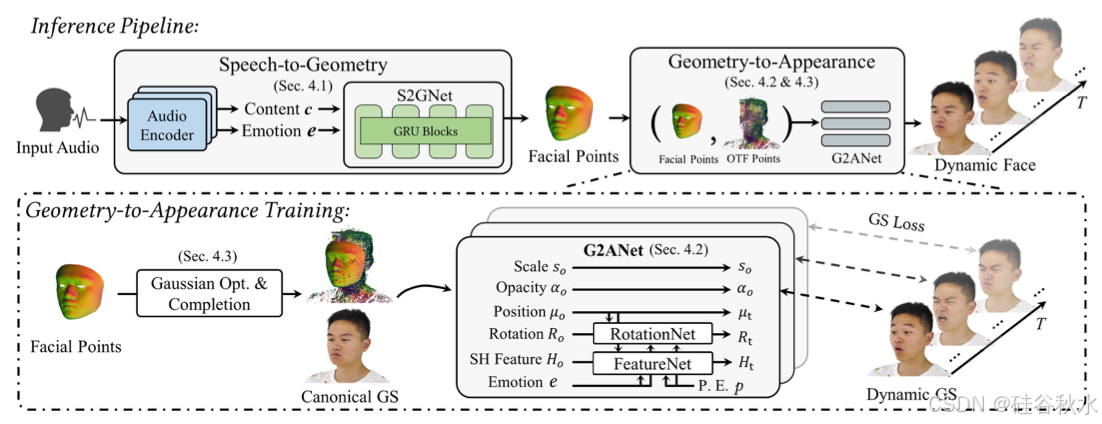
S2GNet 的设计遵循 FaceXHubert [20],一种先进音频-到-网格的预测网络。具体来说,S2GNet 接收提取的情绪标签和编码的音频特征作为输入,根据平均模板网格回归顶点位移,最终生成 4D talking mesh 的序列。
G2ANet 的设计基于两个关键观察。首先,对于特定个体的talking head,面部运动会产生相对较小的外观变化。考虑到这一点,首先在静态、不说话 head训练高斯模型,称为规范高斯模型(Canonical Gaussians)。随后,使用规范高斯模型和 4D 点-衍生的面部运动作为输入,使用神经网络来预测动作引起的外观变化。这些预测的变化被称为动态高斯模型(Dynamic Gaussians)。其次,鉴于语音与头发、颈部和肩膀等非面部特征之间没有直接关联,S2GNet 网络忽略预测这些元素的几何结构。因此,G2ANet 学会复制这些非面部部分的外观,并将它们与面部无缝集成。
按照 3D Gaussian Splatting 法 (3DGS) [26],将静态头部表示为参数化的 3D 点 3D 高斯。每个 3D 高斯由 3D 点位置 μ 和协方差矩阵 Σ 表示,密度函数计算如下:
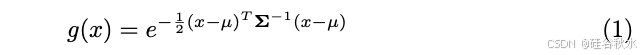
由于三维高斯分布可以表示为三维椭球,因此协方差矩阵 Σ 可以进一步表示为:

3D 高斯函数是可微分的,可以很容易地投影到 2D 平面上进行渲染。在可微分渲染阶段,g(x) 乘以不透明度 α,然后投影到 2D 平面上并混合以构成每个像素的颜色。外观由可优化的 48 维向量 H 建模,该向量表示四个球面谐波带。这样,静态不说话 head 的外观可以表示为 3D 高斯函数 G:

规范高斯记做:
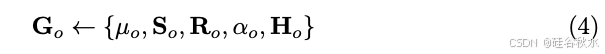
为了使用 3D 高斯函数生成 3D talking face,用动态细节预测 t 时刻的外观。动态细节是指由于说话面部运动而产生的详细外观,例如特定的皱纹和细微的表情。对于特定主体,不透明度 α 和尺度 S 保持不变,分别等于 αo 和 So。t 时刻的高斯函数 Gt 公式如下:
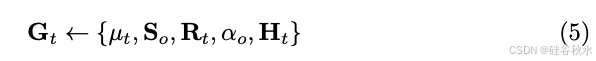
由于 μt 已在语音-到-几何网络中预测,因此只有 Ht 和 Rt 是未知的,分别由 FeatureNet 和 RotationNet 预测:
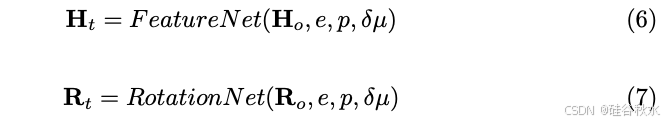
FeatureNet 和 RotationNet 分别是 4 层和 2 层 MLP。
将规范高斯与动态高斯相结合,可以预测高度详细的动态面部外观。这些包括在愤怒或其他表情期间形成的皱纹以及由嘴唇运动导致的细微外观变化。
语音-到-几何网络仅预测人脸的三维点云,而人脸以外的几何形状,如头发、颈部和肩膀,与语音信号相关性不强,因此人脸以外的区域没有准确的初始点来优化高斯分布,因此,通过3DGS优化,在空间中添加85,500个均匀分布的点来构成人脸以外的区域,如图所示。
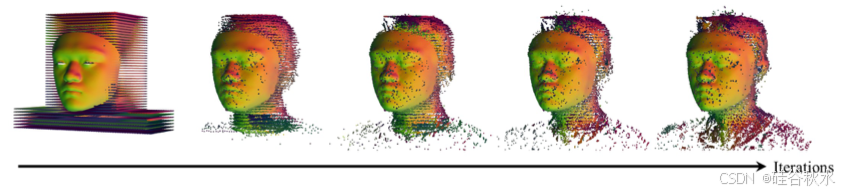
面部区域以外的点(简称 OTF 点),包括头发、颈部和肩膀,应在一定程度上跟随面部点的运动。这些点在远离面部的点(例如肩膀)处趋于静止,而靠近面部的点(例如头发和颈部)会一起移动。
在动态高斯的训练中,如果以与面部相同的方式对头发和肩膀进行高斯训练,则会导致严重的模糊。这是因为面部点在数据集中的位置被准确恢复,因此高斯点可以在视频剪辑的每一帧上更准确地对齐。相比之下,面部以外区域的外观(包括头发、颈部和肩膀)是从随机点优化而来的。这些 OTF 点的 3D 位置不可靠,因此这些点将对应于不同帧的未对齐外观,导致预测的外观模糊。另一方面,规范高斯表示的完整头部是清晰的,然而其外观是静态的。
为了解决这个问题,分别处理动态部分(面部)和静态部分(面部以外的肩膀上方区域),前者使用动态高斯,后者使用规范高斯。具体来说,预定义一个自然过渡的面部权重掩码,将其应用于不透明度α,实现动态和静态部分的自然融合。