接着(上)部分,(下)部分主要介绍了如何在生活中使用因果分析并提出了根据因果这一“幻觉”制造出强“AI”的底层方案。
传送门:
相关与因果的相爱相杀——新书《为什么:因果关系的新科学》解读(下)

4.判断力层级
这节的内容由1个基本问题和6个层次的看法组成,即
你怎么知道一个东西到底是不是真的有效?作者给出了6种层级的解决方法,确实使人脑洞大开。
第一层:
最底层的判断力是“贵”,即材料贵,效果就好这样的原则。有些东西,例如药品的成本大多是普通的材料,真正起到疗效的是配比而不是材料本身。
第二层:
对他人判断力。他人吃了保健品之后认为有效,所以我认为有效。也许保健品与身体恢复发生的时间一致,因此有种“起效果”的错觉。
第三层:
对人群的研究。保健品让某知名大学出一个报告,说吃了这个保健品的人群的身体状况,平均而言,比没吃的人群好。那这个报告能说明这个保健品有效吗?还是不能。保健品卖得挺贵,吃这个保健品的一般都是有点钱的人。这些人的医疗保障、生活环境、饮食结构各方面都比穷人要好,他们的身体状况也许真的就更好,不是保健品的功劳。
以上三种是普通人的分析方法,接下来介绍几种书中提到的“高级”方法。
第四层:
控制混杂因素Z。事情的复杂之处在于,往往会有一个其他因素,Z,既影响了 X 也影响了 Y。因果关系图就如同下面这样 ——
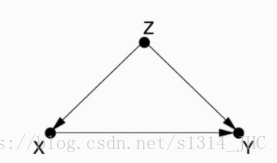
比如说,X 代表每天锻炼身体,Y 是身体健康,Z 是年龄。我们希望证明锻炼身体能促进身体健康,但是你得考虑年龄因素。年轻人更爱锻炼身体,年轻人的身体也更健康。那当你观察到爱锻炼身体的人更健康这个现象,你就不知道到底是 X 导致了 Y,还是因为 Z 同时影响了 X 和 Y。
统计学上管 Z 叫“干扰因素(confounding factor)”,也叫潜在变数。不考虑 Z 就贸然说锻炼对身体有好处,那你就犯了“混杂偏误”,也叫“混淆偏移”,英文是 confounding bias。Z,混杂了X→Y的因果关系。
但是你很容易就能去除 Z 的混杂。比如如果年龄是个干扰因素,那我们可以
只考察同一个年龄段的人,看看其中锻炼和不锻炼的人的健康区别。如果同为50岁,锻炼的人比不锻炼的人身体好,那就说明在年龄之外,锻炼真可能有好处。这就是大多数科学研究所采取的方法。
第五层:
随机试验。大约是1923年,费舍尔在研究肥料对农作物生长的影响。 他可没像某些保健品那样,说这个肥料货真价实用的都是好材料就一定是好肥料。

费舍尔老老实实做实验。弄两块实验田,一块用1号肥料一块用2号肥料,看看哪块田的庄稼长得好,这行不行呢?
问题在于世界上根本没有完全相同的两块田。有些土地的灌溉比较好,有的地方虫害少,不同土地的酸碱度也不一样,所有这些都是干扰因素,你得想办法控制。
费舍尔意识到,不管怎么控制,他都无法排除所有的潜在干扰因素。
最后费舍尔想了一个办法。他说我干脆来个*随机*实验。他找了很多块土地,把土地随机地分成两组,一组用1号肥料,另外一组用2号肥料。
大规模随机分组的好处就在于,因为没有使用任何主观分类标准,那就不管你有什么干扰因素,这个干扰因素在两个组里的强度应该是大致相同的。只要实验的样本量足够大,随机分成的两组之间就不会有本质的差异。
这一设想,能够排除一切干扰因素!不但如此,费舍尔还能用统计方法估算随机实验得出结论的不确定性到底有多大。比如说你可以用 “P值”代表不确定性,(即概率中显著性方法的p值,一般为p<0.05)
第六层:
用简单、准确方法决定该控制谁。
以前、包括现在还有很多研究者写论文,都不知道到底应该控制哪些变量,索性就把所有相关的因素都给控制一遍,连有些不该控制的也给控制了,反而导致结论出错。
因果革命的一个重大突破是在数学上发明了
do-算符。没有这个算符,统计学家永远都说不清到底什么样的因素是干扰因素 —— 干扰因素根本就不是单纯用统计数据能定义的概念。有了这个算符,我们就可以说,所谓“存在干扰因素”,就是 ——
P(Y|X) ≠ P(Y | do(X))。
具体的技术细节不介绍。只要知道根据这个定义,科学家得出了两条判断规则。给定任何一个因果关系图,我们都能使用这两条规则确定,到底哪些变量应该被控制。
第一条规则是“后门”路径的信息传递必须被隔断。所谓后门路径
,就是从 X 到 Y 的一条连通路径,其中起始的箭头指向 X。后门路径中可能包含干扰因素,你需要控制其中一个变量,阻断信息传递。
第二条规则是如果后门路径中有“A → B ← C”这样的“碰撞”结构,那就不要控制了,因为其中的 B 已经阻断了 A 和 C 的信息交流,控制反而会带来干扰。(注意箭头方向)
举几个因果关系图的例子,可以看看这个方法有多简单!
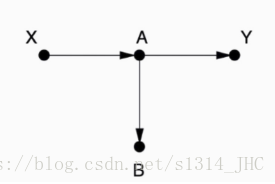
图中没有后门路径,不需要控制任何变量。

X←A→B←D→E→Y 是一条后门路径。很多研究者会控制其中的变量,但那是错的!注意 B 处是一个碰撞结构,它已经阻挡了信息,这张图根本不需要控制变量。

X←B→Y是个后门路径,我们需要控制变量 B。
这个方法将复杂的逻辑结构被变成了简单的数学游戏。这是因果革命的伟大贡献!
5.AI的自由意志
之前用科学的方法研究了因果关系。但归根结底,因果关系是一种主观的观点。也许在最底层的原理上,因果是一种幻觉。但是因果是一个非常有用的幻觉。因此有必要把因果这个幻觉和人的另外一个幻觉联系在一起,那就是自由意志。
因果可能是一个幻觉,但是它作为思维快捷方式很有用。那自由意志,也是一种有用的幻觉吗?自然选择为什么要让大脑产生拥有自由意志的幻觉呢?
这个问题,事关要不要让 AI 也有自由意志的幻觉。作者珀尔还特意举了一个踢足球的例子,比较接如今世界杯的地气。阿根廷队比赛结束之后,教练跟梅西说,当时那个情况你不应该把球传给迪玛利亚,你应该给阿圭罗。这句话就已经假定了梅西有自由意志。教练和梅西都明白这么做是为了赢球,赢球的动机不变,现在只是要做个小调整,为了获得更好的进攻机会。短短一句话背后有太多心照不宣的默认动机。
可是如果假定梅西没有自由意志,你要表达这么一个意思就非常困难。教练需要调用梅西的整个软件系统,把当时场上的情况、以及所有类似的情况的优先级赋值都调整一遍。教练会感到很麻烦,梅西会感到很茫然。

(图没有恶意,只是调侃一下。。希望阿根廷能出线)
所以珀尔说,从交流的效率考虑,如果将来要搞一支机器人足球队,这些机器人最好有自由意志的幻觉。自由意志会让他们的表现更好。那么,怎样才算拥有自由意志呢?
比如说有个烟民,抽烟已经形成习惯了。如果他在毫无意识的情况下,从口袋里掏出烟就抽,那我们可以说他在这件事儿上没有表现出自由意志。他是抽烟的机器,他是烟瘾的奴隶。但是如果这个人把烟拿出来之后,突然停顿了一下,意识到自己现在有个“想抽烟”的动机,他就开启了自由意志。他马上就可以反思这个动机!他可以想到,如果我现在不抽烟,改成吃个苹果,会不会有更好的结果呢?
因此,
自由意志=意识到自己的动机+考虑不一样的行动
人在行事过程中如果能表现出自由意志,他就能够独立自主、他就能自己控制自己,他就值得尊敬。AI 如果有自由意志,它就可以算得上是“强AI”。珀尔说,目前还没有任何一个 AI 程序有这样的功能。
好,那怎么才能让 AI 有自由意志呢?它需要具备三个特点。
- 它需要一个关于世界的因果模型。比如你家有个机器人。有一天晚上你正在睡觉的时候,这个机器人想要打扫房间,它拿着吸尘器就开始吸尘,把你给吵醒了。你就跟它说:“下次不要吵醒我!”这个机器人需要有个因果模型才能理解你这句话。它得知道吸尘会导致噪音,噪音会吵醒你,吵醒你会让你不高兴。它还得会干预分析和反事实分析。它得知道虽然你说了这句话,但是白天它还是可以吸尘。它得知道晚上你要是不在家,它可以吸尘。它得知道如果这个吸尘器是绝对静音的,你就算在睡觉它也可以吸尘。只有因果模型才能帮它做出这些灵活的处置。
- 它需要把自己也当成环境的一部分,考虑自己跟环境的因果互动。一个有意思的论断是机器人永远都无法100%预测自己的行为。为什么呢?因为你要精确预测自己的行为,就得把自己的程序跑一遍 —— 可是你本来就已经在跑自己的程序啊!你不可能开一个子进程,这个子进程里又包括了全部的你 —— 你不能自己嵌套自己!否则就是无限循环。所以 AI 需要一个关于自己的因果关系模型。他对自己的行为特点、对自己的动机会产生什么结果有一个基本的蓝图,这样它才能把自己和环境综合考虑。
- 它还需要一个记忆系统。他得知道自己以前的那些动机都导致了什么样的后果,这样他才能从错误中学习,他才能对自己的行动负责。
这就是强智能AI的底层理论。也是作者从因果关系这个主题中引申出的一个十分有意义的观点。

总结:这两篇总结可能不能完全反应作者的观点,只是抛砖引玉。主要分析了相关性与因果性的关系、因果的本质以及如何使用因果这一分析方法指导生活,希望对各位有启发。
ps:还没有中文版的翻译本,可以购买原版进行阅读。亚马逊图书