引言
检索增强生成(Retrieval-Augmented Generation, RAG)模型广泛用于生成基于外部知识的文本内容。传统 RAG 模型依赖文本数据进行检索和生成,但在实际应用中,文档的视觉信息(如页面布局、图像、表格)同样重要。为了更有效地处理包含复杂视觉信息的文档,新一代模型如 VisRAG 和 ColPali 应运而生,它们将视觉语言模型(Vision-Language Models, VLM)融入 RAG 管道,直接利用文档图像进行检索与生成。本教程将详细介绍 VisRAG 和 ColPali 的技术架构,并展示如何利用这些模型提升多模态文档的处理能力。
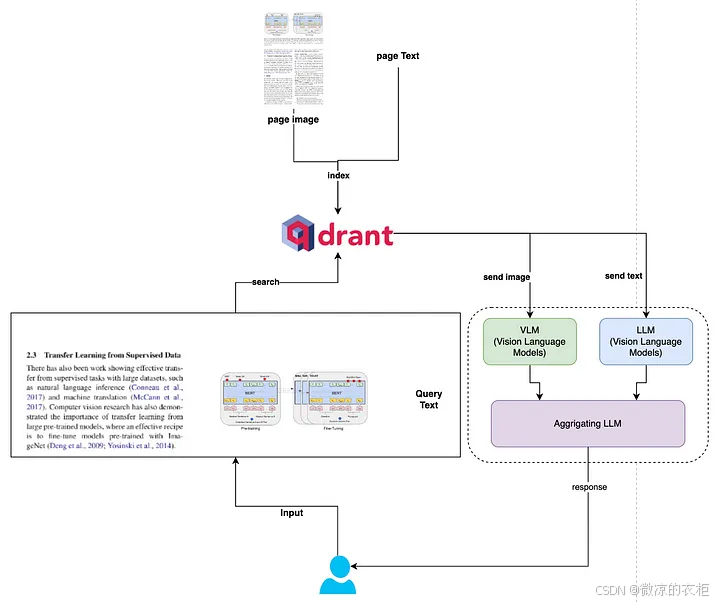
1. 传统 RAG 的局限性与 VisRAG 的创新
传统 RAG 模型只能处理纯文本内容,因此会在解析文档时丢失大量信息。VisRAG 模型提出了一种新方法,通过 VLM 直接将文档图像嵌入为视觉特征,无需依赖文字解析步骤,从而保持文档的完整信息。这一设计在性能上优于传统的文本 RAG,实验表明 VisRAG 在检索和生成上比传统 RAG 管道提升了 25-39%【12†source】。
VisRAG 模型架构
VisRAG 的主要创新在于其视觉嵌入机制:
- 视觉嵌入:文档页面作为图像输入到 VLM,生成高维嵌入向量。
- 增强生成:利用图像嵌入的上下文,生成更具视觉特征的内容。
2. ColPali:优化文档检索的视觉驱动模型
与 VisRAG 相似,ColPali 也利用 VLM 提升文档检索,但它专注于在多领域文档中实现更高效的图像嵌入检索。它特别适用于场景复杂、信息量大的文档数据。ColPali 使用“图像补丁嵌入”技术,将文档页面分割成 32x32 像素块,每个块映射为 128 维向量,从而构建上下文化的嵌入。
ColPali 的架构
- 页面嵌入生成:每个文档页面分割为小像素块,通过 VLM 提取特征,生成上下文化的嵌入。
- 查询文本嵌入:文本查询分词后,生成对应的 128 维向量。
- 晚期交互匹配:查询和文档的嵌入在检索时进行交互匹配,采用点积运算比较所有图像块和查询词嵌入。
这种结构确保在检索到的页面内容丰富且上下文一致,适用于工业、科学、医疗等高需求领域。
3. VisRAG 与 ColPali 的实战应用
以下是如何在 Azure 平台上实现 VisRAG 和 ColPali 管道,以实现多模态文档的高效检索与生成的示例代码:
1. 文档嵌入处理
from azure.search.documents.indexes import SearchIndexClient, SearchIndex
from azure.search.documents.indexes.models import (
SimpleField, SearchFieldDataType, SearchableField, VectorSearch, HnswAlgorithmConfiguration
)
# 创建搜索索引
def create_pdf_search_index(endpoint, key, index_name):
index_client = SearchIndexClient(endpoint=endpoint, credential=AzureKeyCredential(key))
vector_search = VectorSearch(algorithms=[HnswAlgorithmConfiguration(name="myHnsw", parameters={
"m": 4, "efConstruction": 400, "metric": "cosine"})])
fields = [
SimpleField(name="id", type=SearchFieldDataType.String, key=True),
SearchableField(name="title", type=SearchFieldDataType.String),
SearchField(name="embedding", type=SearchFieldDataType.Collection(SearchFieldDataType.Single), vector_search_dimensions=128)
]
index = SearchIndex(name=index_name, fields=fields, vector_search=vector_search)
return index_client.create_or_update_index(index)
2. 查询处理与检索
from openai import AzureOpenAI
client = AzureOpenAI(api_key='your_api_key', azure_endpoint='your_azure_endpoint')
def process_query(query, model):
inputs = model.tokenize(query)
embeddings = model.forward(inputs)
return embeddings
4. VisRAG 与 ColPali 的性能分析
VisRAG 和 ColPali 的应用表现优异,尤其在维多利亚(ViDoRe)数据集上测试时,ColPali 达到了 0.81 的 NDCG@5,显著优于传统的文本检索方法。两者的架构消除了文本提取中的信息丢失,并通过视觉-语言嵌入保留了页面的视觉上下文【15†source】。
优势与挑战
- 优势:显著提高多模态文档的检索与生成质量,能够利用视觉特征生成更丰富的内容。
- 挑战:计算资源需求较高,尤其在大规模数据集上执行多模态检索时,GPU 性能至关重要。
结论
随着 VisRAG 和 ColPali 等视觉驱动模型的兴起,文档处理技术进入了一个多模态智能检索的新阶段。未来,随着 VLM 的发展,我们可以期待更高效的文档检索与生成模型,这将进一步提升文档处理的智能化水平。