多元时间序列预测的动态模式分解
动态模式分解 (DMD) 是一种数据驱动的降维算法,由Peter Schmid于 2008 年开发
类似于矩阵分解和主成分分析 (PCA) 算法。给定一个多变量时间序列数据集,DMD 计算一组动态模式,其中每个模式都与固定的振荡频率和衰减/增长率相关联。由于每个动态模式的内在时间行为,DMD 确实不同于 PCA 等常用的降维算法。DMD 允许人们用物理上有意义的模式来解释数据的时间行为。一个重要特性是 DMD 能够执行多变量时间序列预测。
在本文中,我们将介绍 DMD 算法的初步知识,并讨论如何使用 Numpy 在 Python 中重现 DMD。并给一个地学实例。
原理
DMD 与向量自回归 (VAR) 模型有很强的联系。VAR 是一种经典统计模型,用于捕捉多元时间序列数据的共同演化模式
其中N是变量数,T是时间步数,那么在任何时间步t中,一阶 VAR 或 VAR(1) 的形式为
在 VAR(1) 模型中,建模目标是找到一个表现良好的系数矩阵,并用它来表示时间相关性。在标准 DMD 模型中,我们也采用 VAR(1) 的形式。要计算系数,首先要将上述方程重写如下,
在 DMD 中,获取 Koopman 矩阵并执行预测任务并不困难。DMD 中最重要的工具是奇异值分解和特征值分解。要计算 Koopman 矩阵,只需遵循两个步骤:
-
对数据矩阵***X1***进行奇异值分解:
其中U*由左奇异向量组成,V由右奇异向量组成,Σ以其对角线上的奇异值组成。
-
实现具有特定预定义秩 r的截断奇异值分解,并通过以下方式计算 Koopman 矩阵
如上所述,DMD 可以通过动态模式探索可解释的时间行为。如果要计算动态模式,请按照以下步骤操作:
-
对 Koopman 矩阵执行特征值分解:
现在,我们有了 VAR(1) 中提到的系数矩阵***A。***因此,可以实现时间序列预测任务。这是 DMD 算法的 Python 代码。我们使用 Numpy 重现它,它将很容易理解。
import numpy as np
def DMD(data, r):
"""Dynamic Mode Decomposition (DMD) algorithm."""
## Build data matrices
X1 = data[:, : -1]
X2 = data[:, 1 :]
## Perform singular value decomposition on X1
u, s, v = np.linalg.svd(X1, full_matrices = False)
## Compute the Koopman matrix
A_tilde = u[:, : r].conj().T @ X2 @ v[: r, :].conj().T * np.reciprocal(s[: r])
## Perform eigenvalue decomposition on A_tilde
Phi, Q = np.linalg.eig(A_tilde)
## Compute the coefficient matrix
Psi = X2 @ v[: r, :].conj().T @ np.diag(np.reciprocal(s[: r])) @ Q
A = Psi @ np.diag(Phi) @ np.linalg.pinv(Psi)
return A_tilde, Phi, A
输出包括库普曼矩阵、特征值和系数矩阵。
地学实例
给一个具体案例,预测土壤水时间序列
首先是DMD方法
import numpy as np
def DMD4cast(data, r, pred_step):
N, T = data.shape
_, _, A = DMD(data, r)
mat = np.append(data, np.zeros((N, pred_step)), axis = 1)
for s in range(pred_step):
mat[:, T + s] = (A @ mat[:, T + s - 1]).real
return mat[:, - pred_step :]
然后是数据
import pandas as pd
data = pd.read_csv('/home/mw/input/geo9882/geo.csv')
data
import matplotlib.pyplot as plt
plt.plot(data['soil_water'])
plt.show()
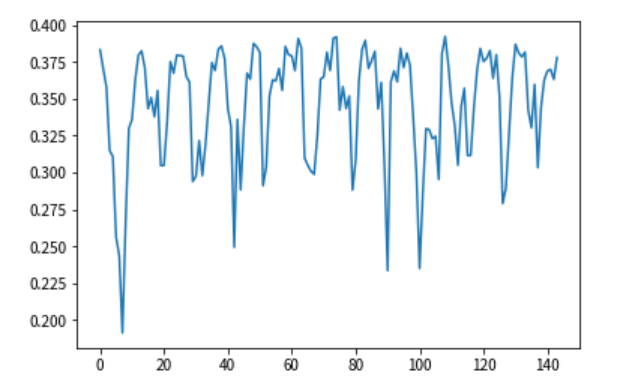
土壤水序列如图,可以看到预测还是相对困难。
我们想要预测序列的后几十个值
data['soil_water'][-13:]
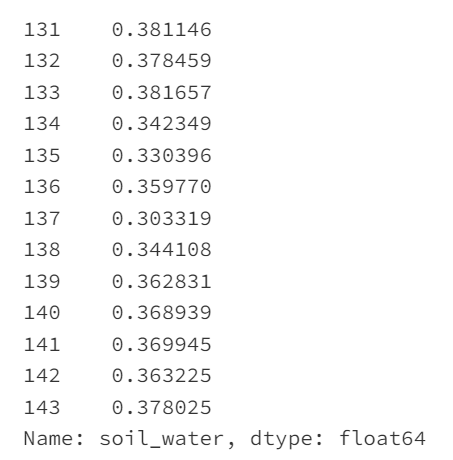
X = np.zeros((2, 131))
X[0, :] = data['soil_water'][:-13]
X[1, :] = data['soil_water'][1:-12]
pred_step = 12
r = 2
mat_hat = DMD4cast(X, r, pred_step)
print(mat_hat)

模型成功返回了结果,基本一致。