四、神经网络
4.1 神经元
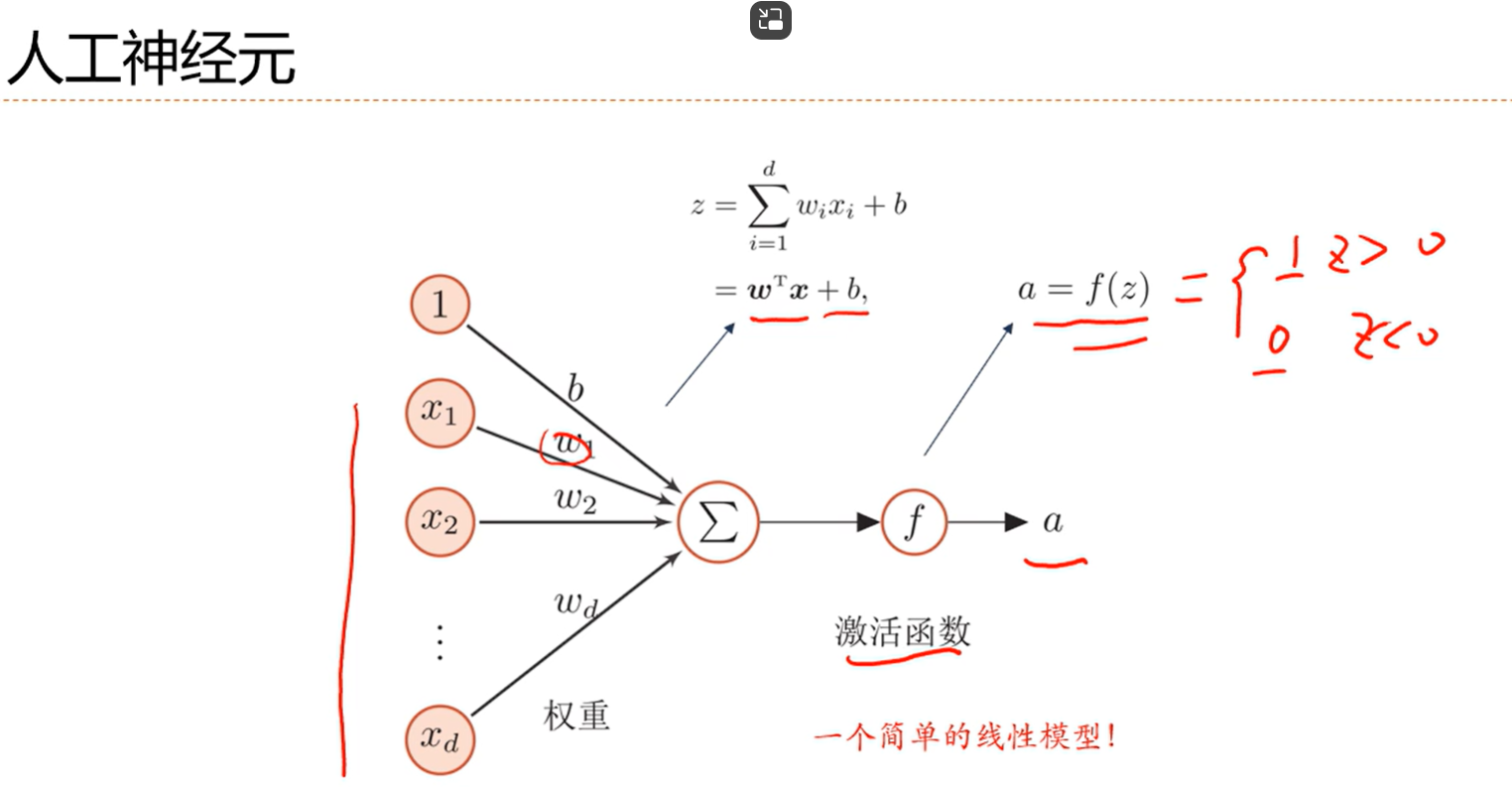
w表示每一维(其他神经元)的权重,b可以用来调控阈值,z
经过激活函数得到最后的值a来判断神经元是否兴奋,1就兴奋,0就不兴奋
这就相当于一个简单的线性模型

第二点要求函数和导函数尽可能简单是因为,我们的网络可以设计的比较复杂,所以函数就设计的比较简单,有利于提高网络计算效率
最后一点,函数并不一定是单调递增的,可能局部会递减,但是我们希望的是a可以反映出z的变化
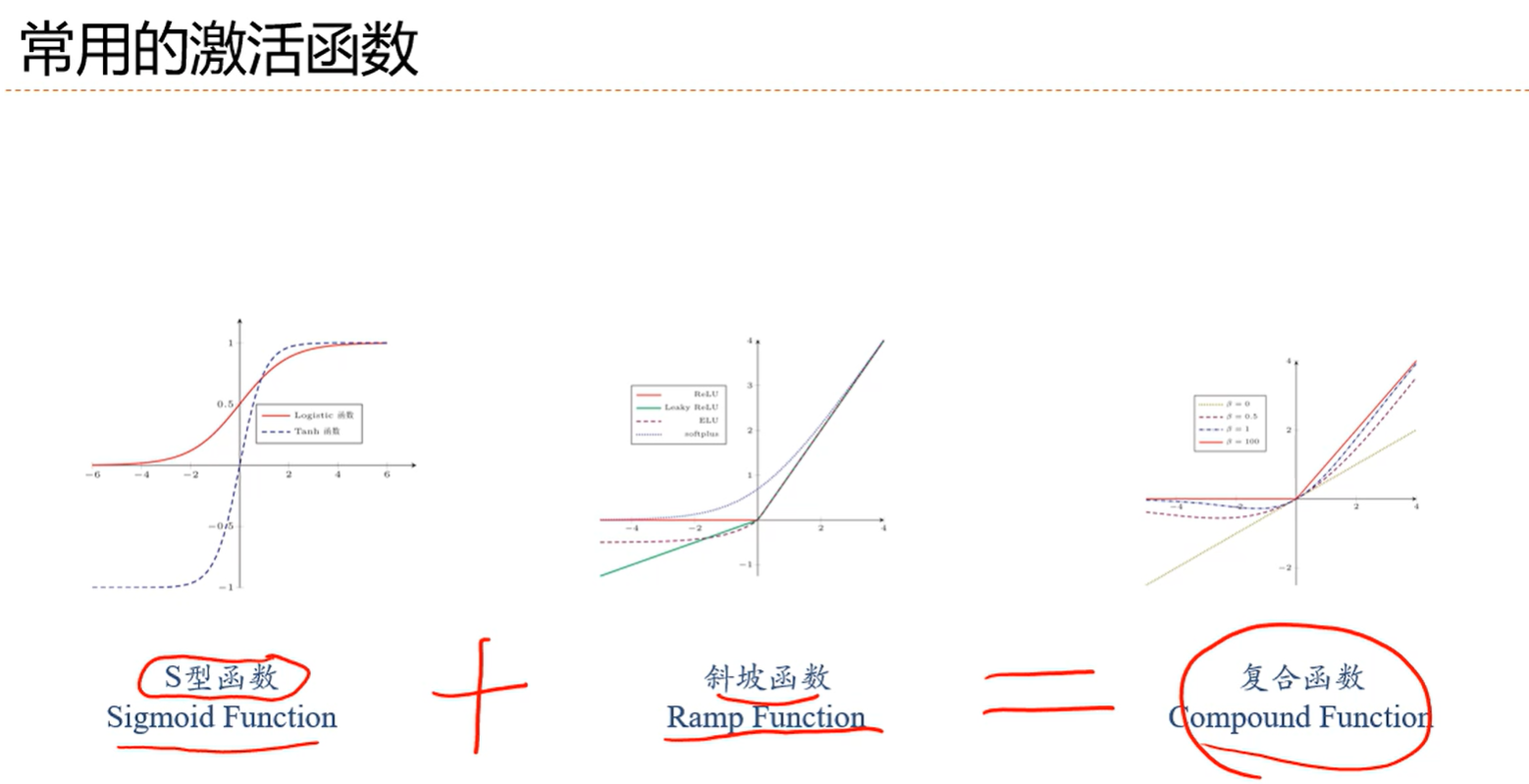
现在复合用的挺多的
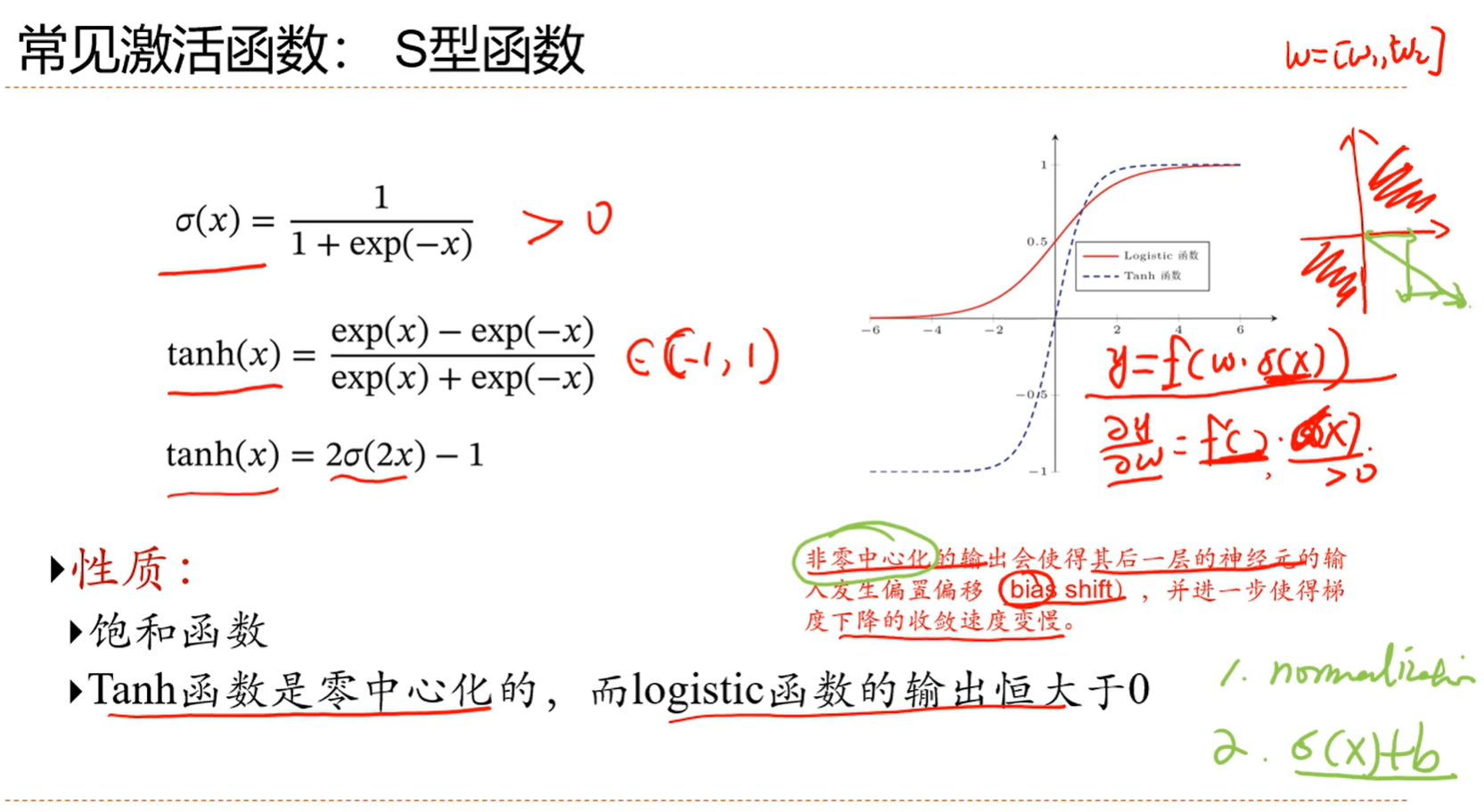
非零中心化去w求导,前面是标量,后面seigema (x)是大于0的,导致导函数都大于0或者小于0,有些地方的梯度优化就取不到了
减少非零中心化带来的影响:1.规划一下2.给原来的函数加一个偏置b,使得它变得中心化

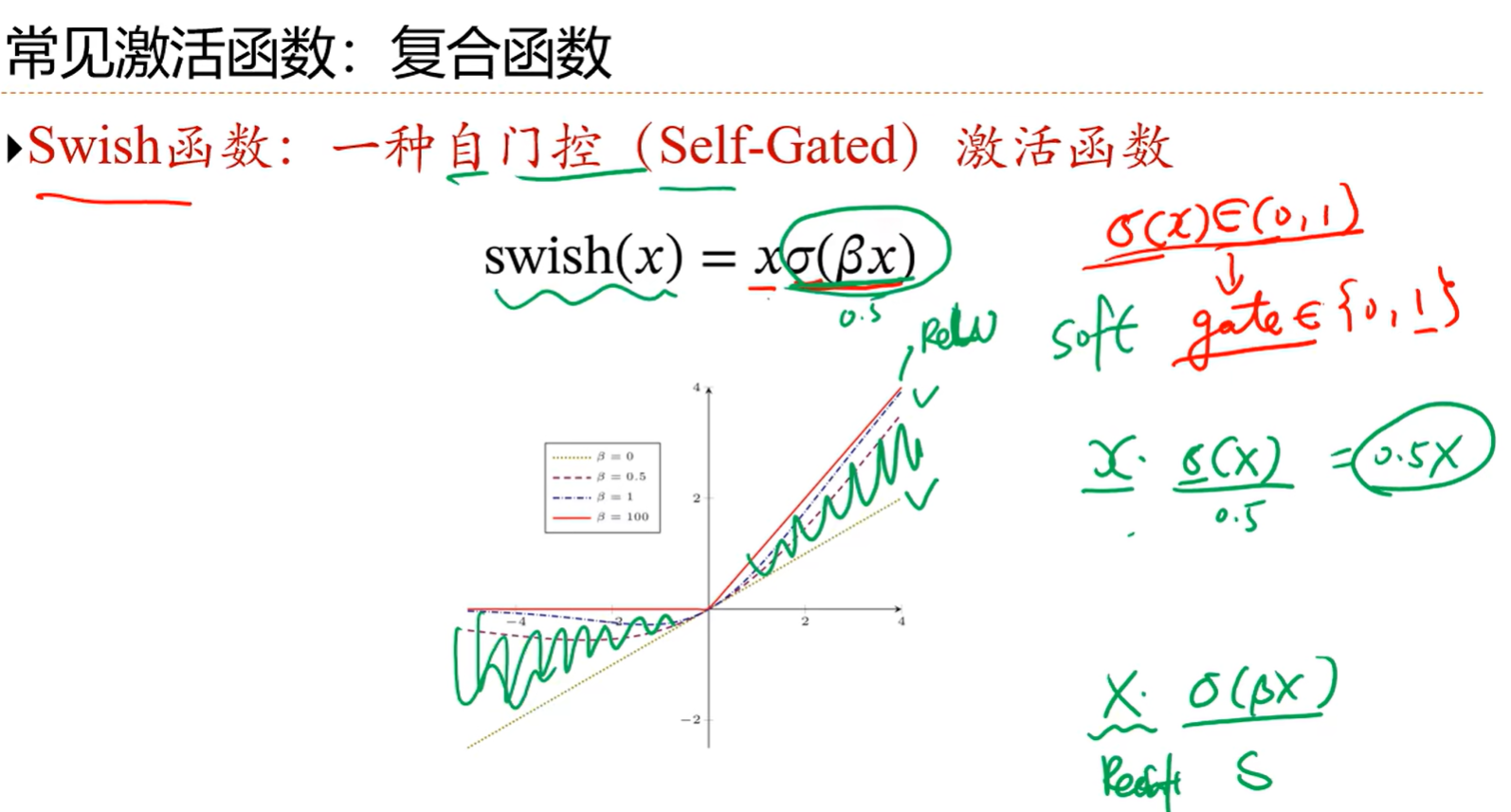
ReLU函数有上述好处之外,有一个缺点就是死亡ReLU问题
就是说,由于左边x小于0,那么如果数据集选的时候过于集中,都是小于0的话,那函数值一直是0,那就一直都不会兴奋了,就产生了问题
解决方法:
1.进行规划,就是说选数据集不要过于集中,并且参数也要精心的进行初始化
2.改进ReLU函数LeakyReLU,也就是x小于0的时候乘上一个很小的数,让他不为0
然后ReLU也是一个非零中心化的函数,那也存在上面的问题,可以用ELU函数进行优化
最后还有一个更加平滑的版本Rectifier

常见激活函数及其导函数

4.2 神经网络

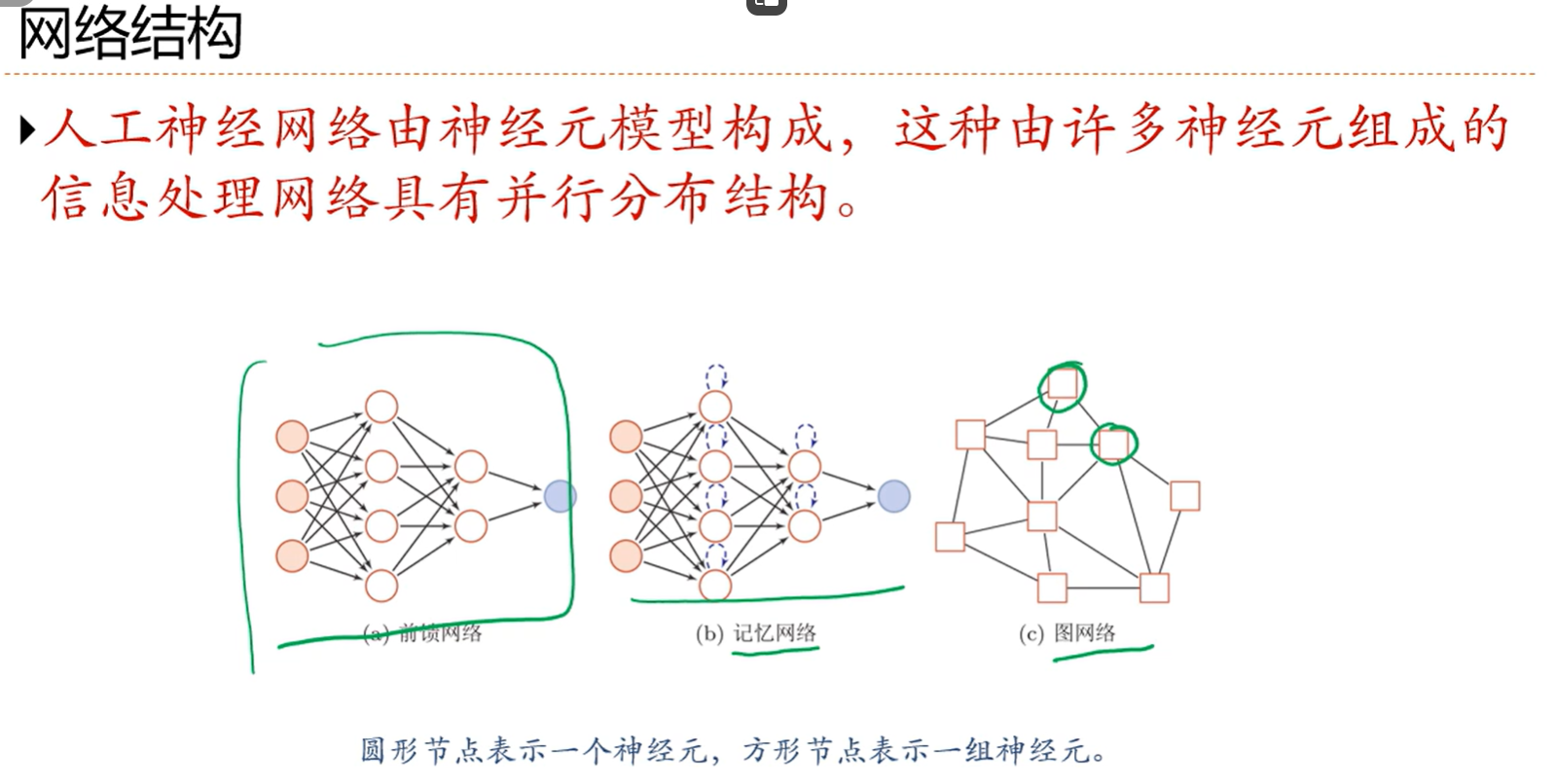
前馈网络是信息都是从前往后传递的没有循环边
记忆网络允许循环边的存在,说明一定要记录历史状态,说明这种网络具有记忆功能
图网络中每个方框是一组神经元而不是一个,否则就太复杂了
一般我们用的都是复合形式的网络而不是单个

信息表示是分布式:如果把神经元看做信息的载体,那么一个信息可以分散存储在多个神经元上由它们共同表示这个信息,而不是像符号主义一个符号就表示一组信息
记忆和知识存储在单元之间的连接上:也可以说是神经元的连接上的,它的连接权重定义了它的知识
通过逐渐改变单元之间的连接强度来学习新的知识
4.3 前馈神经网络
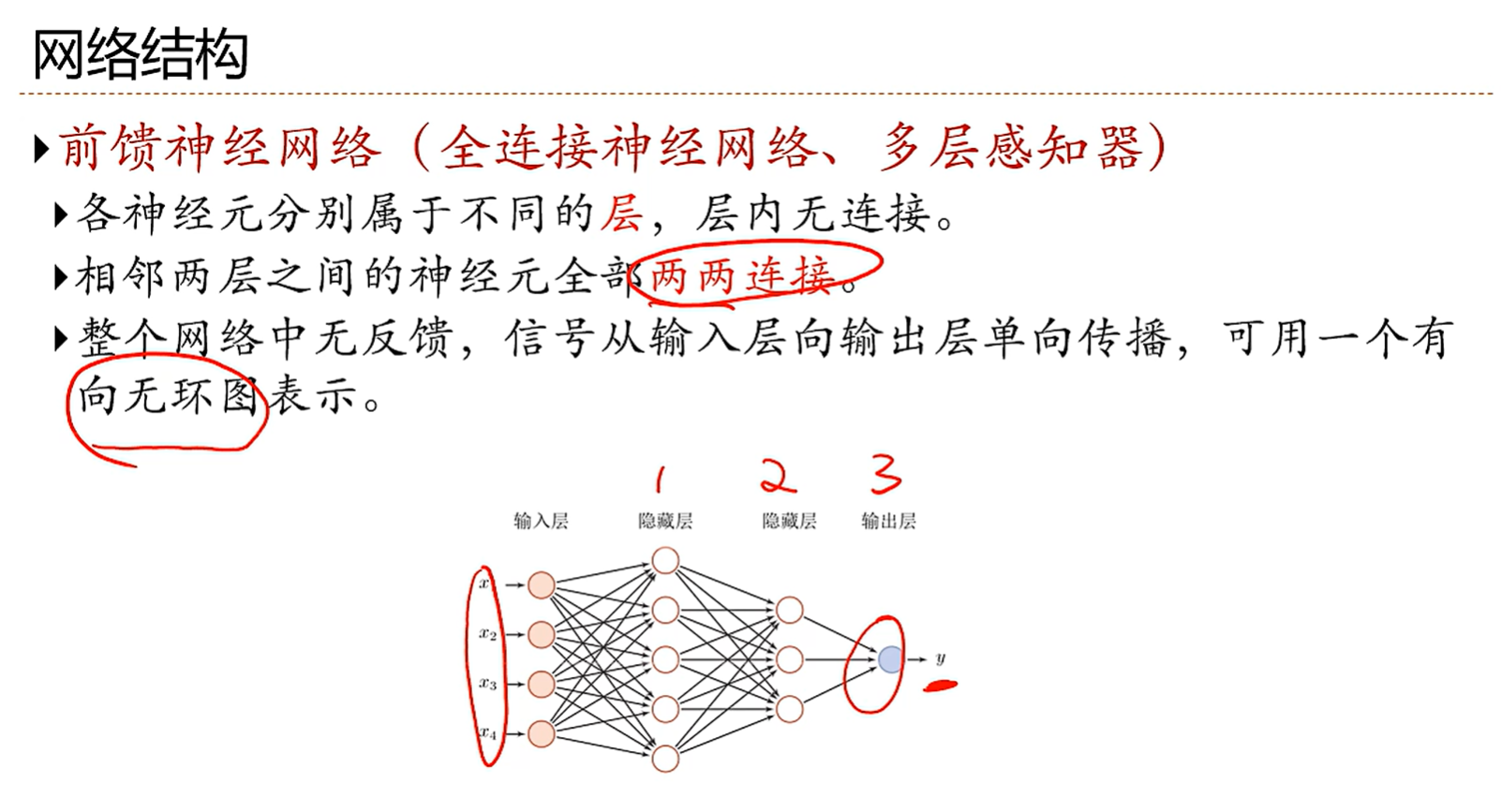
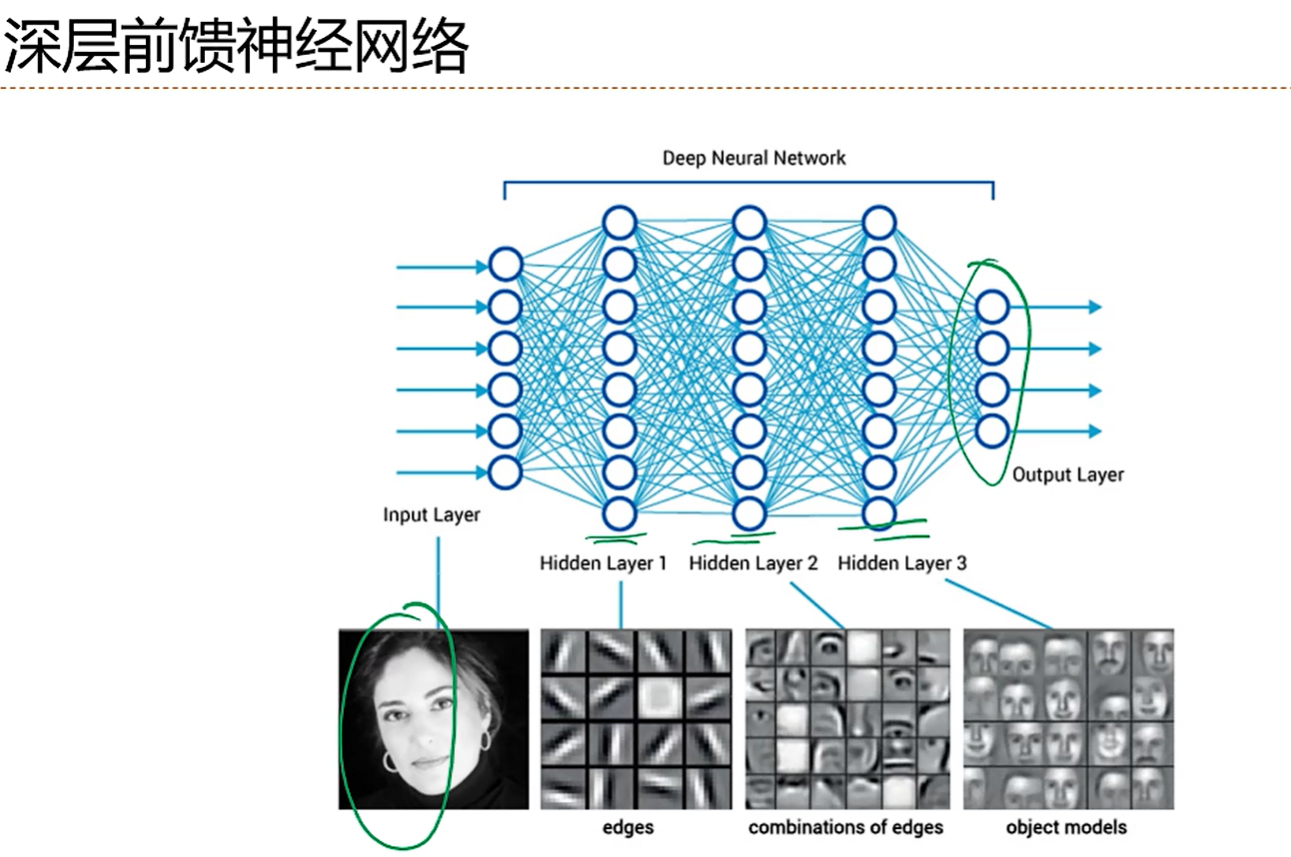
定义网络层数的时候一般不算输入层,从输入层下一层开始算是第一层。所以输入层也可以叫第0层,图中的网络层数就是3层
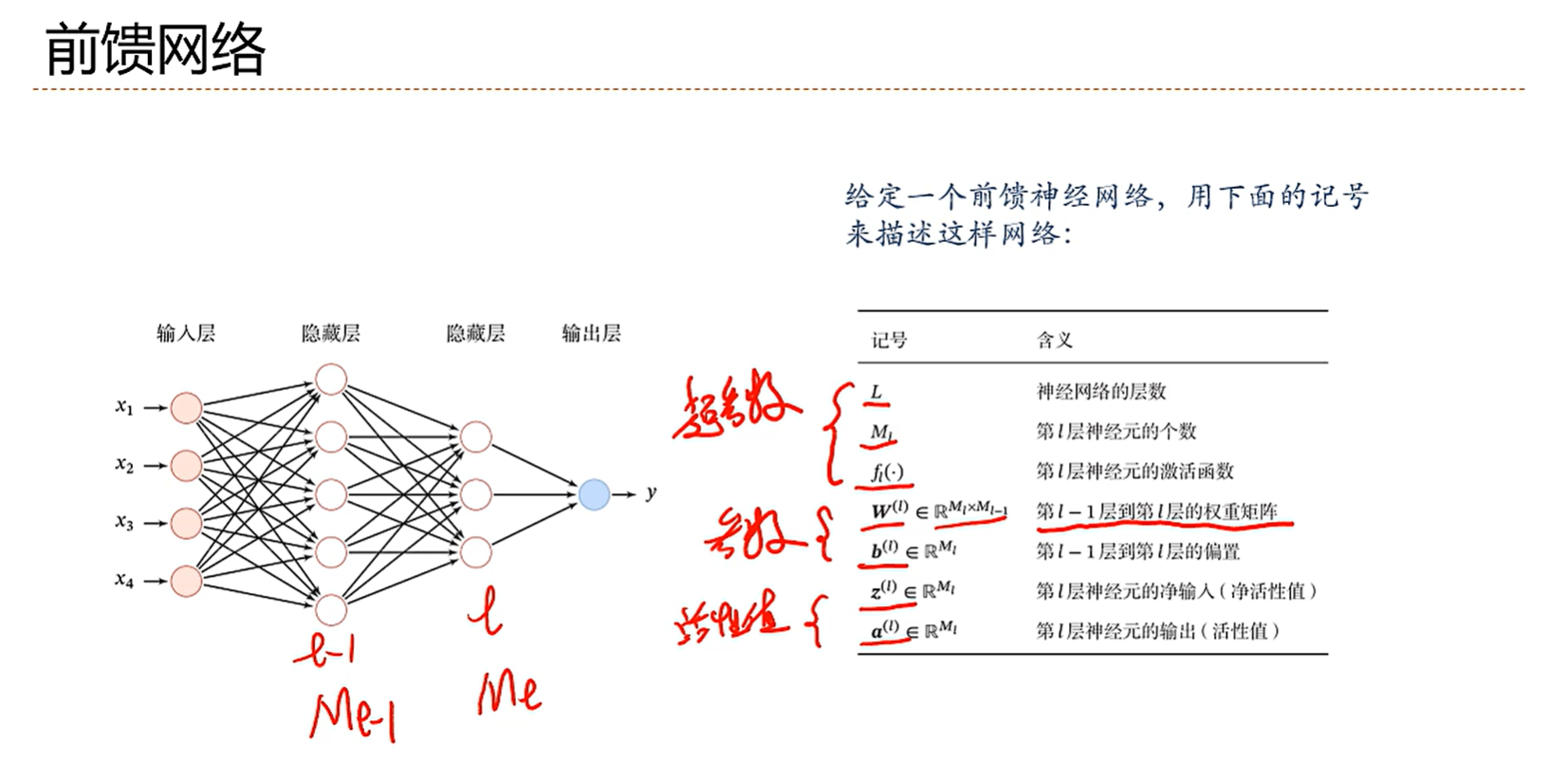
前三个是超参数,我们自己输入的
4-5这两个是参数,是要学习的东西
剩下两个是活性值,是动态的,对于每组不同的x进来之后,这两个值是不同的,其实就是之前的z(x)和激活函数f算出来的结果a

就简单来说就是前一层的结果是后一层的自变量,带入进去进行学习就是了

通用近似定理:根据通用近似定理,对于具有线性输出层和至少一个使用“挤压”性质的激活函数的隐藏层组成的前馈神经网络,只要其隐藏层神经元的数量足够,它可以以任意的精度来近似任何从一个定义在实数空间中的有界闭集函数;
感觉其实就是一个函数必然可以用多层神经网络来无限逼近;即神经网络可以作为一个“万能”函数来使用,可以用来进行复杂的特征转换,或逼近一个复杂的条件分布。
关于该定理的内容了解即可
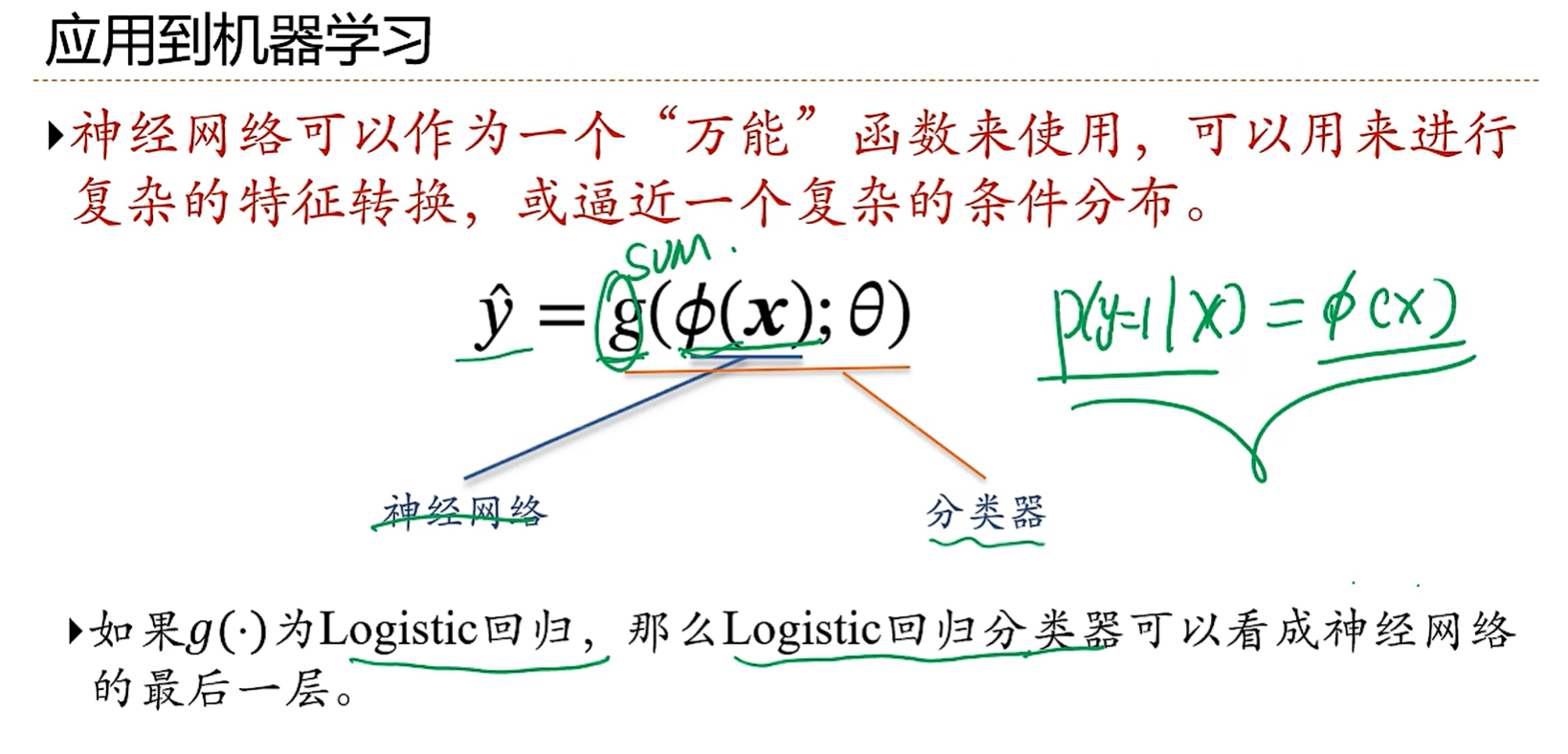
可以把神经网络看做一个非常复杂的分类器来使用,用神经网络进行之前学过的那些模型的参数进行学习,最后再套一层分类器g(),就把神经网络和该分类器和二为一了
看一个例子,我们输入一张图片,经过三个隐藏层,分别提取不同的特征,越到后面的隐藏层越是提取高级的特征,然后把结果给到最后一层的分类器,最后进行分类

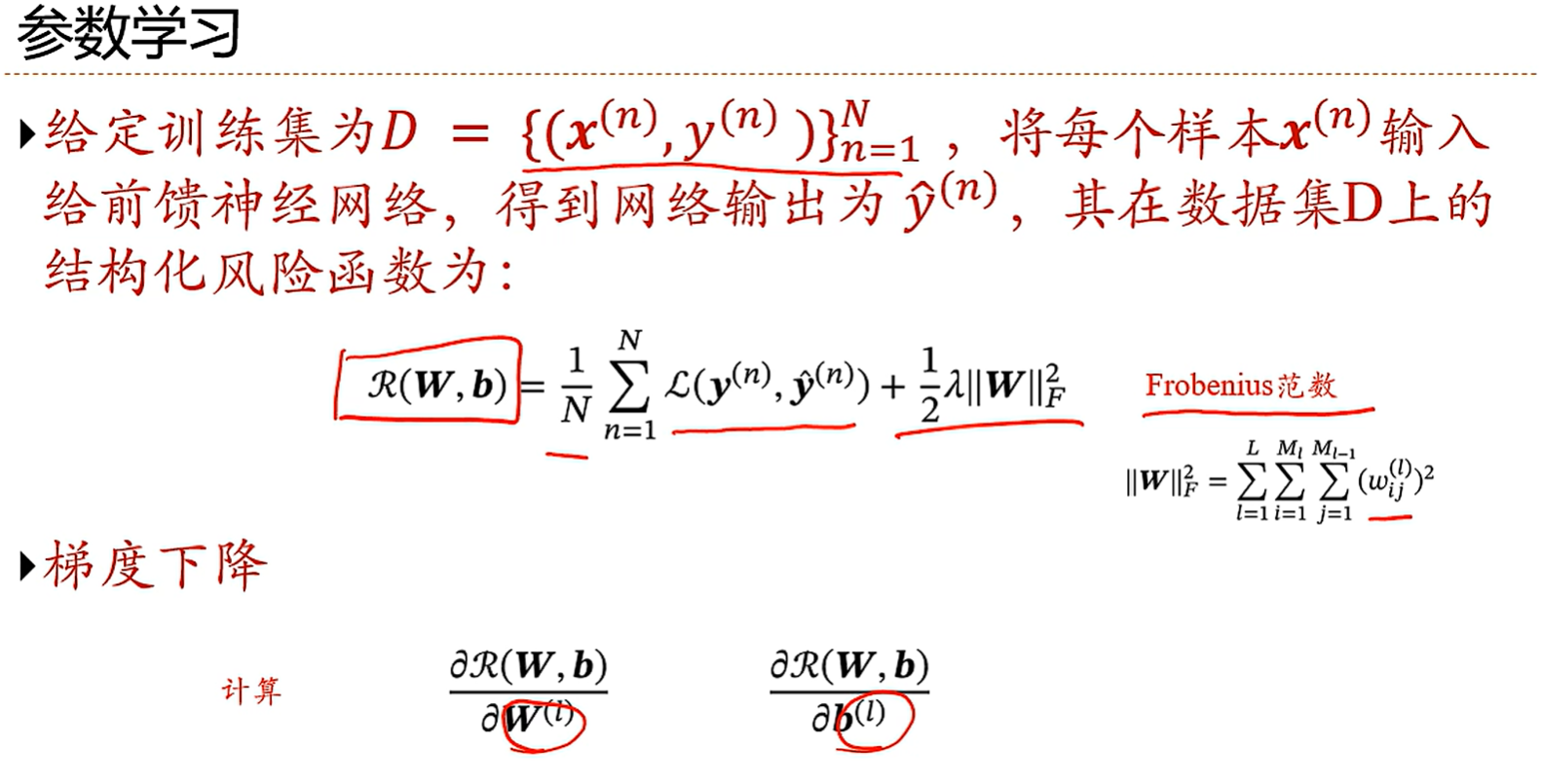
学习的是z(x)中的权重w和偏置b

由于反向传播算法是根据前馈神经网络特点设计的,所以当网络变得复杂之后,不太适用,又提出了自动微分
4.4 反向传播算法
这玩意的数学推导有点难搞,笔者就记了大概意思以应付考试,要更加深入的读者可以去看视频

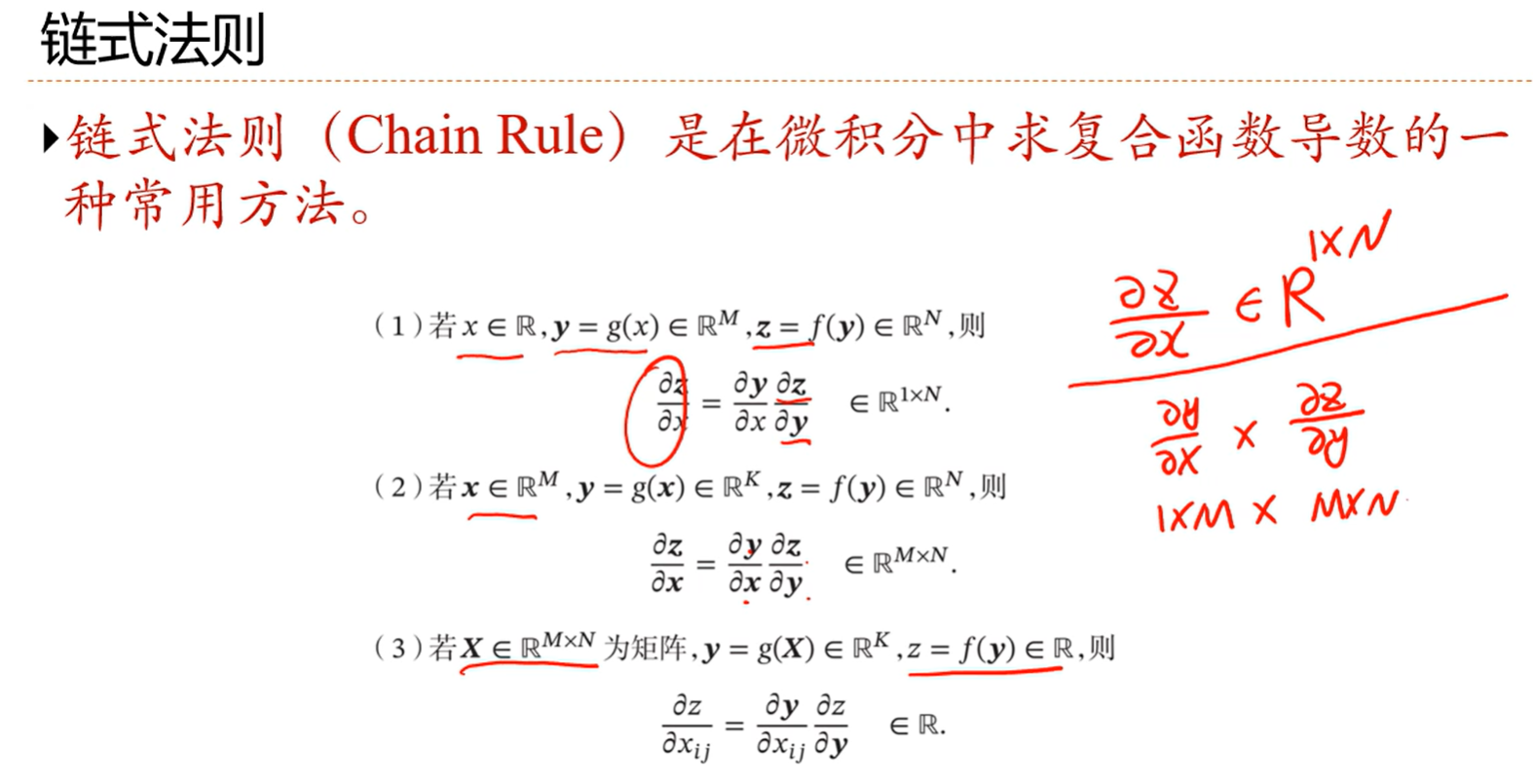
链式法则(Chain Rule)是在微积分中求复合函数导数的一种常用方法。
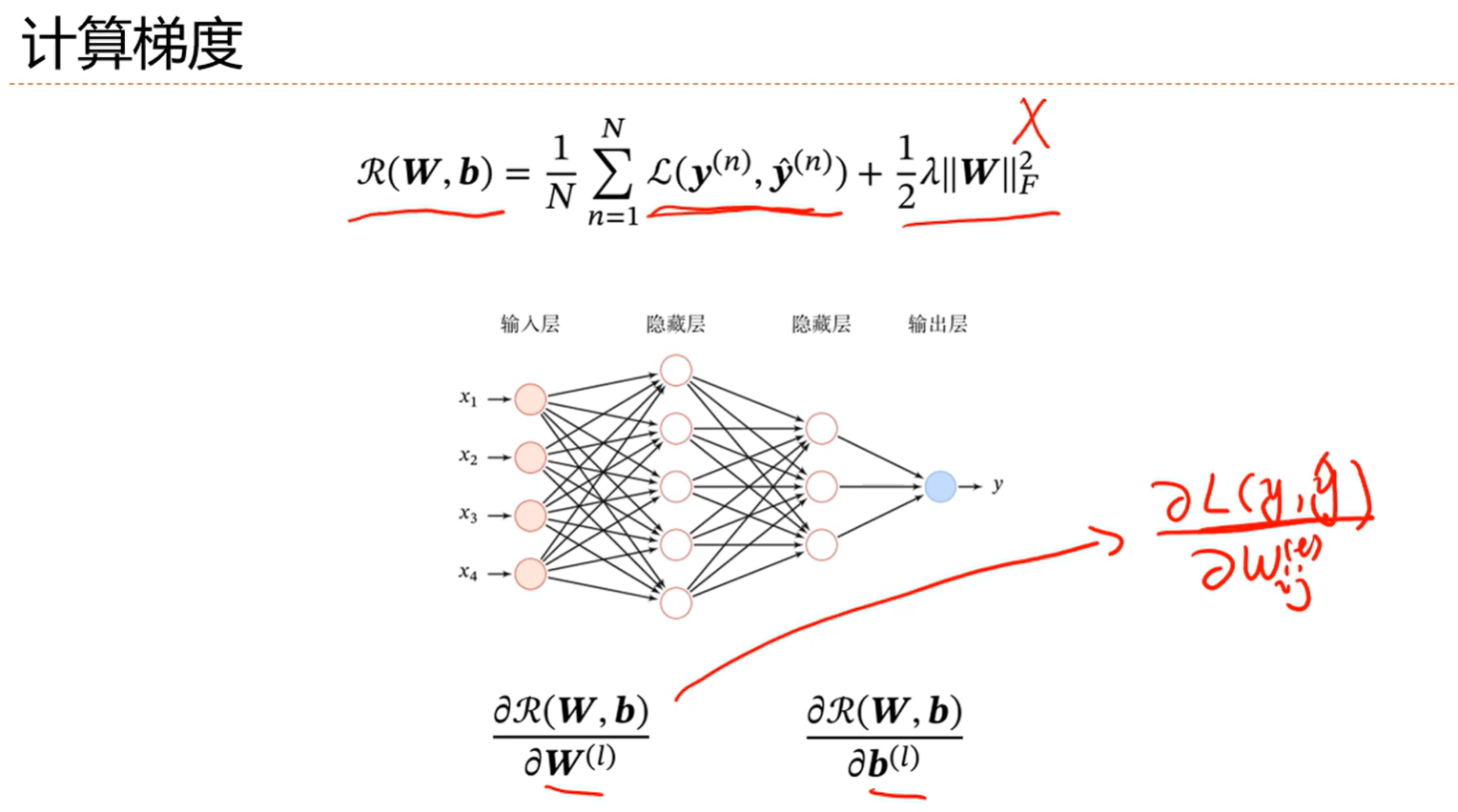
先计算矩阵中某个向量的导数,然后再给拼回来,这样就回避了求导比较难的问题
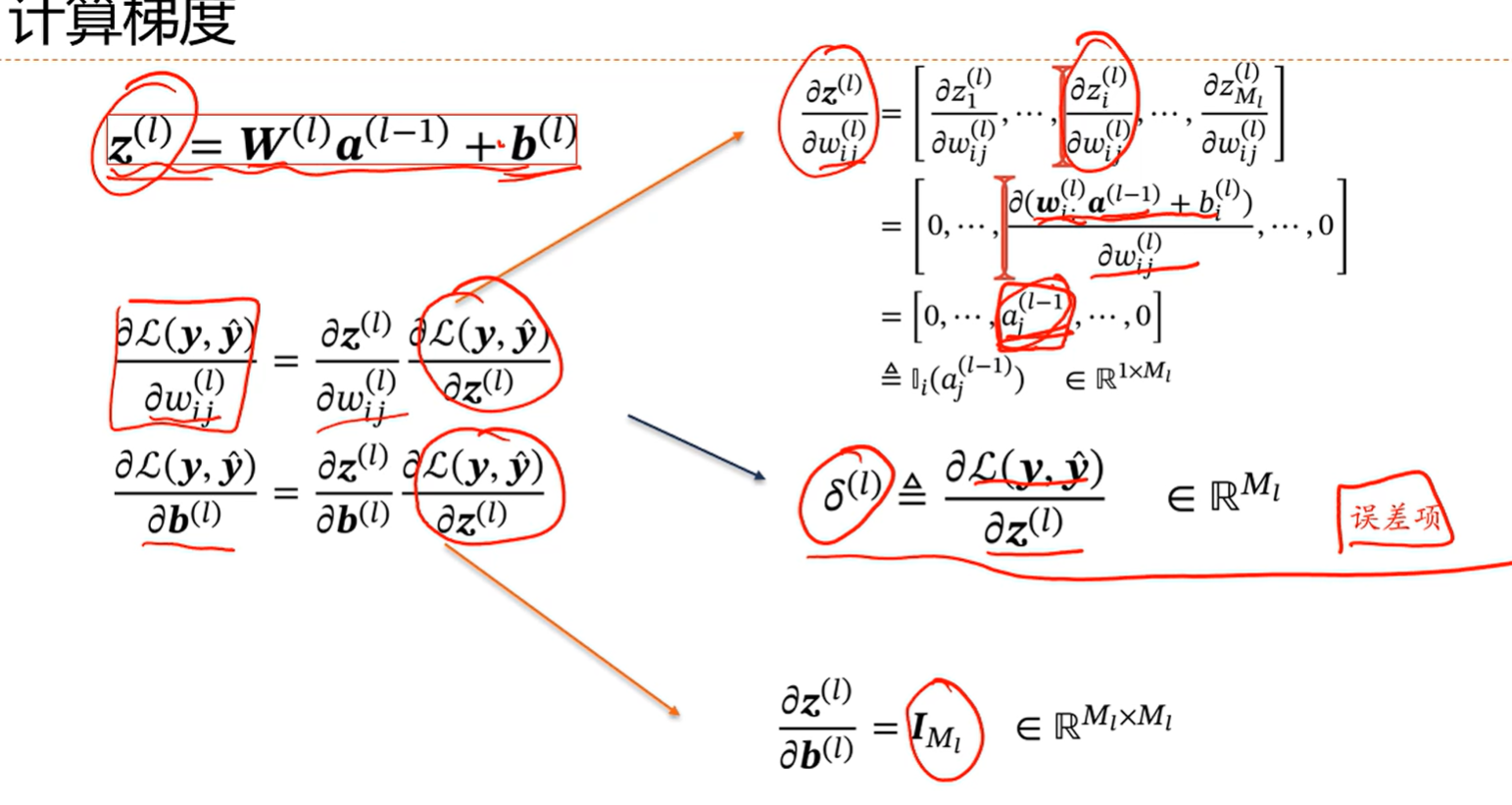
计算出这三个偏导就可以算出要求的两个偏导,第一个和第三个已经有了,所以核心就是怎么求这个误差项
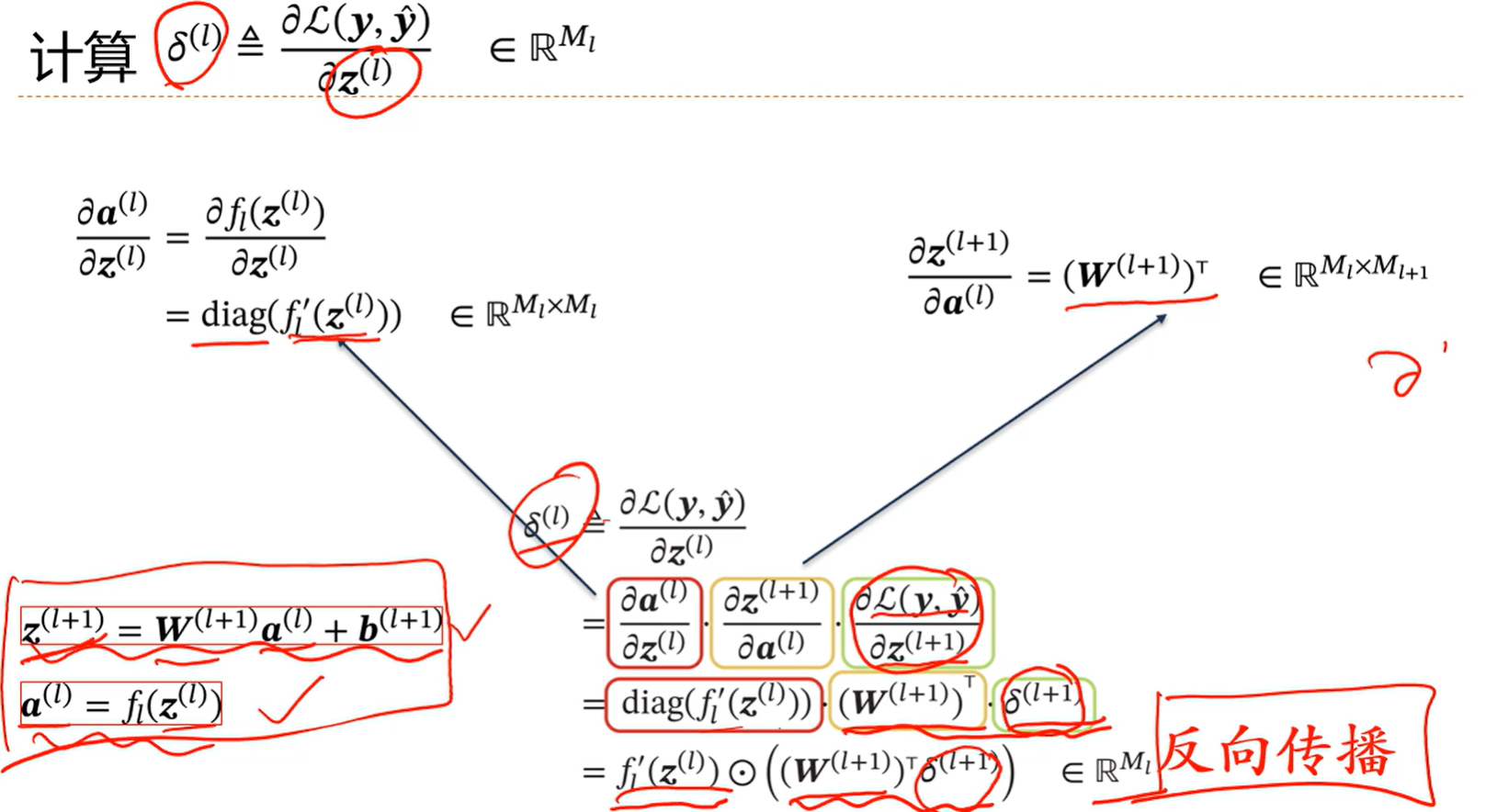
可以看到第l层的误差项是可以由第l+1层的误差项乘以l+1层权重矩阵再乘以激活函数的导数得到,那么这个过程就是反向传播
对于计算一个任何参数的偏导数,可以算损失函数对于最后一层的偏导数,就是最后一层的误差项,计算出来后,然后一层一层迭代往前传递
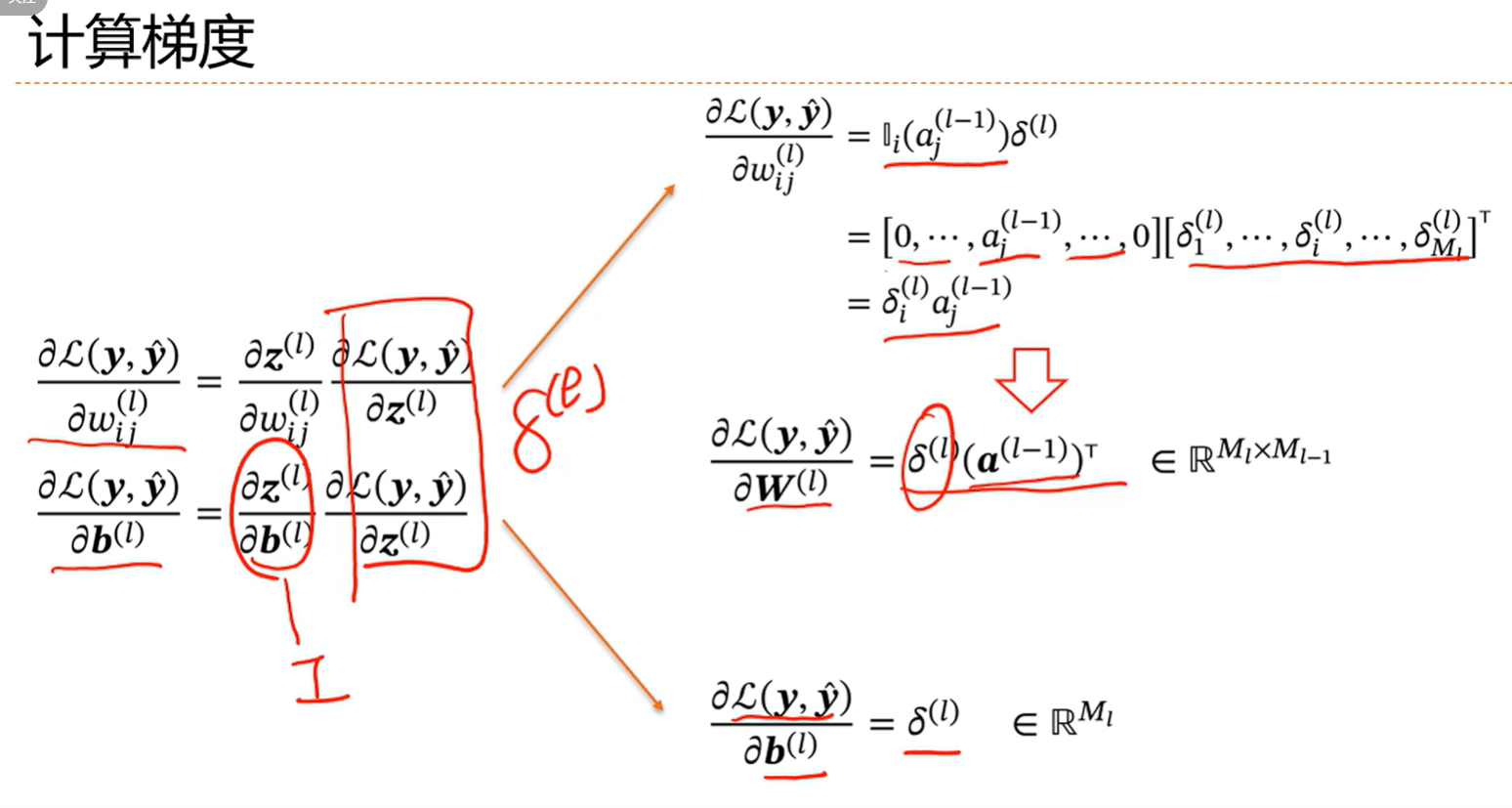
有了误差项,就可以结合那三个算出损失函数关于参数的偏导数了

4.5 计算图与自动微分
反向传播算法缺点就是梯度是需要手工计算的,并且这个计算比较复杂,容易出错,特别是网络复杂的时候
下面是更加高效的方法:不用手工而是用程序完成计算
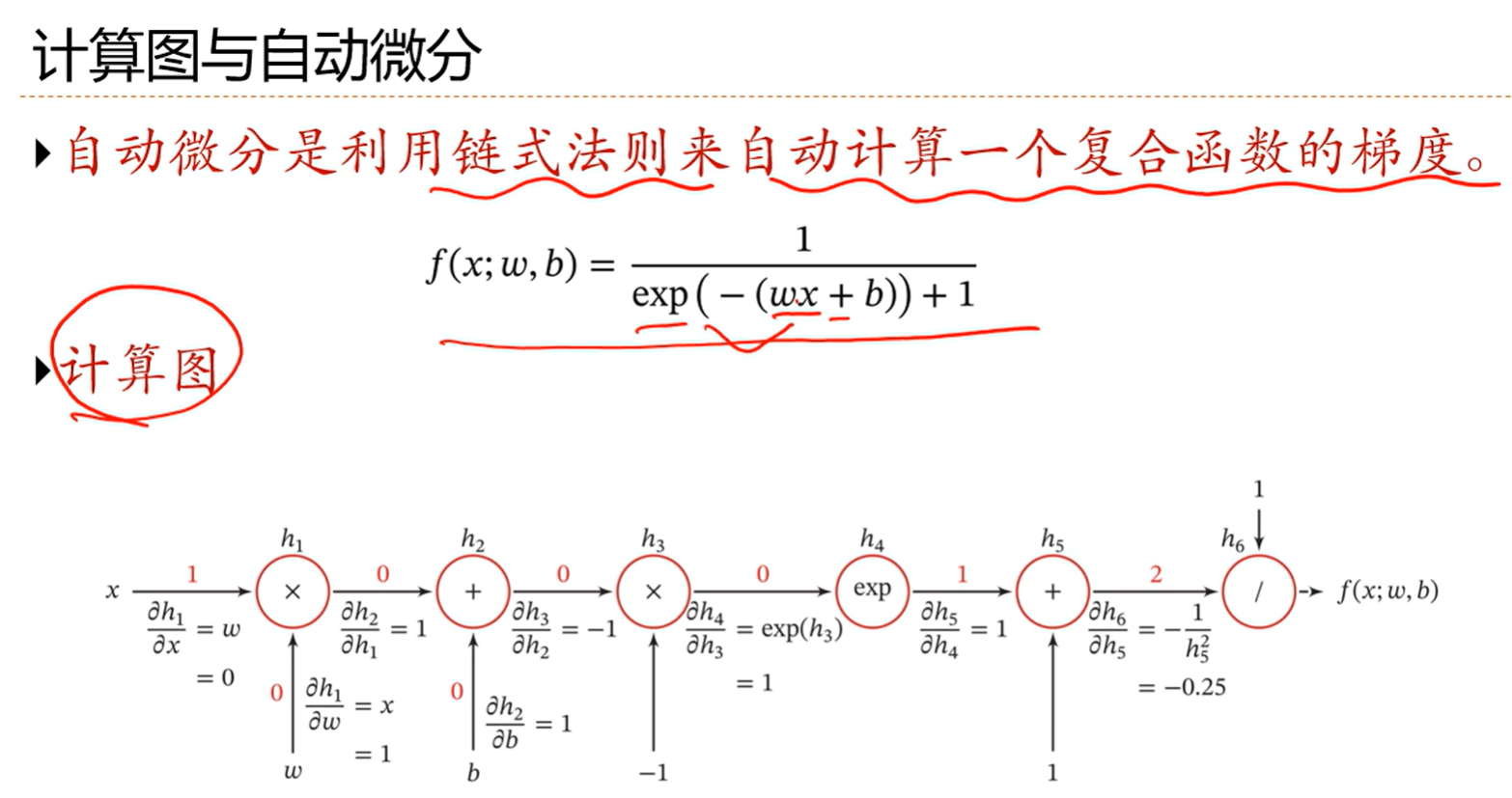
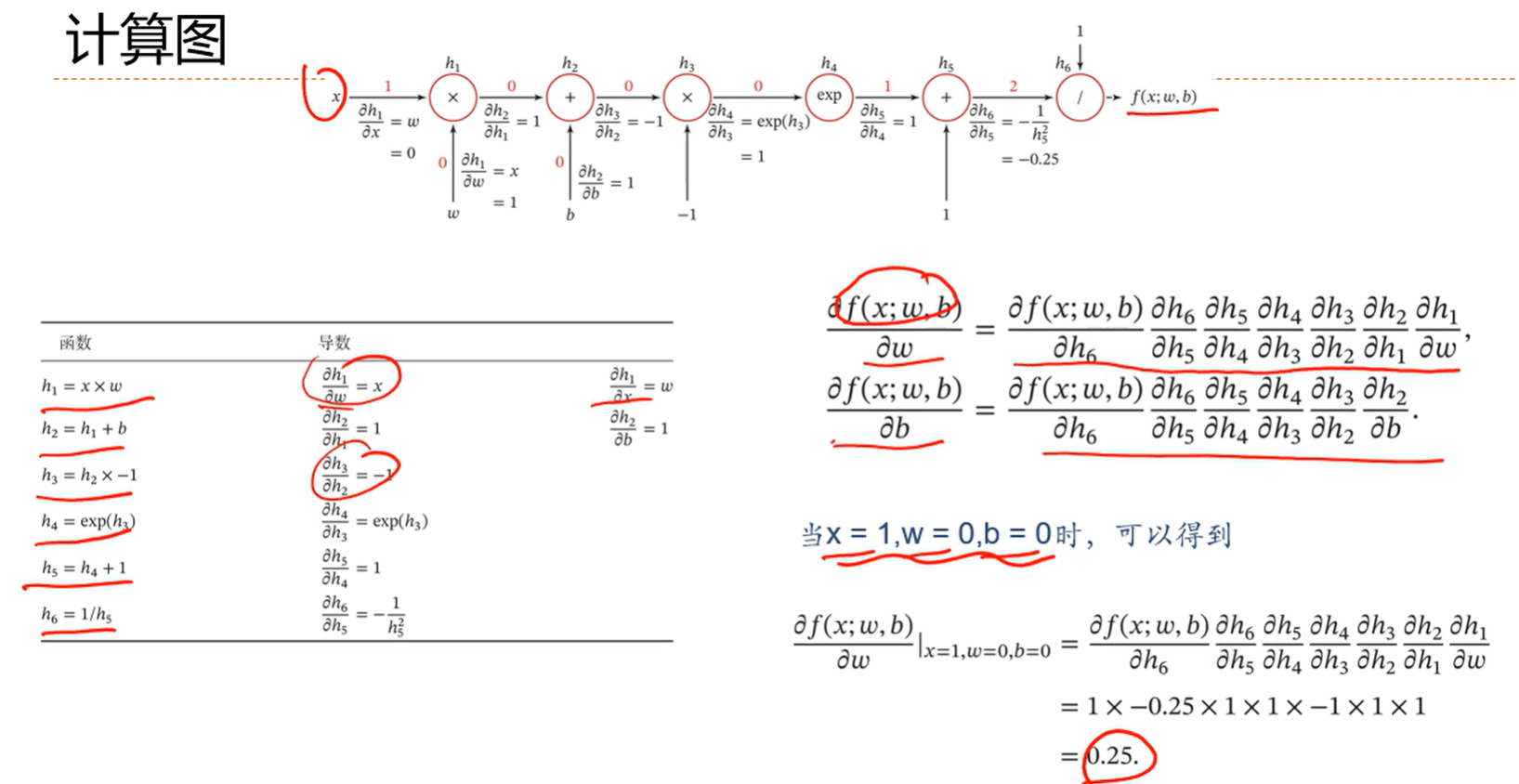
就是利用算子把每一阶段的导数都算出来存储了,相当于把递归给转换成备忘录了,比如h6对h5的导数,并不会关心h5内部怎么实现,是什么函数,而只关心h6和h5的关系;
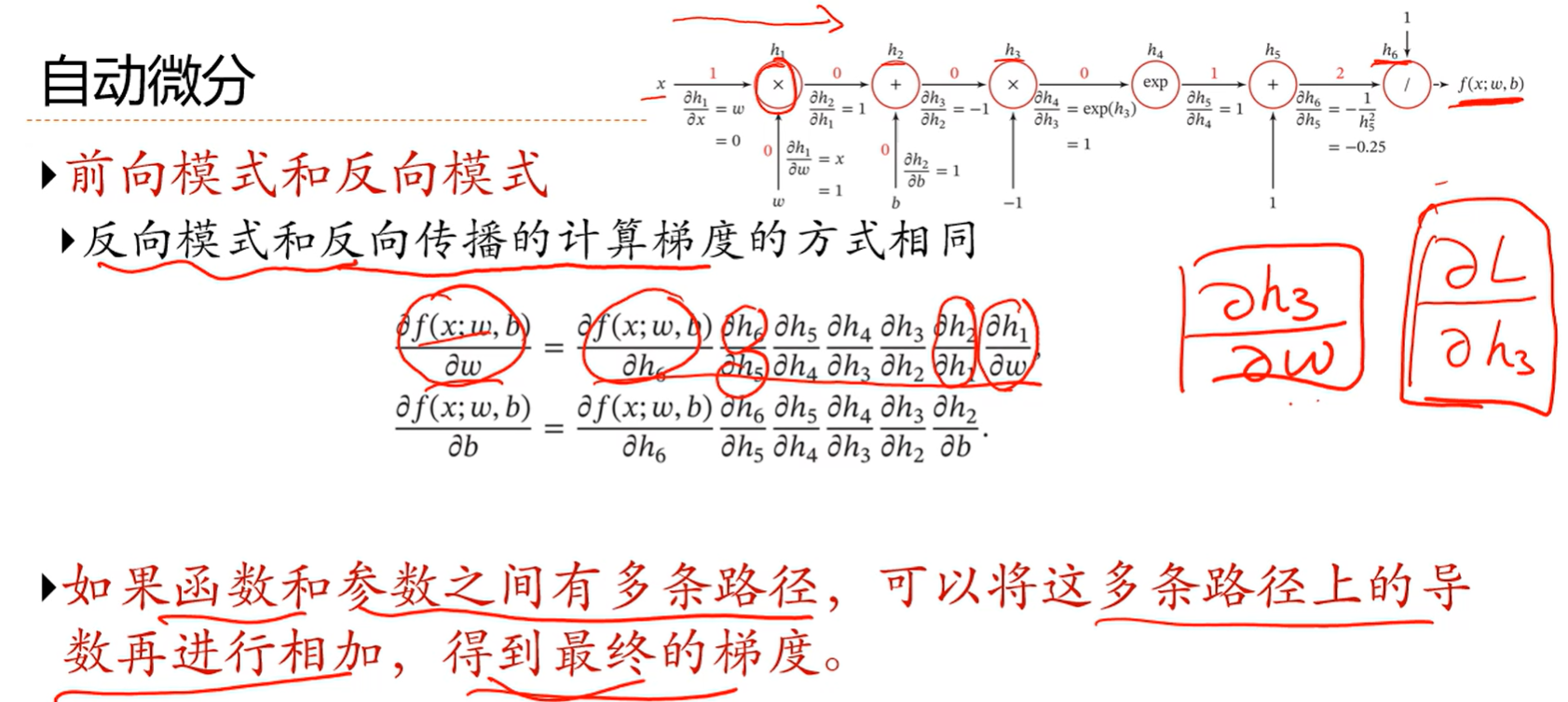
反向模式就是把h6,h5,h4到h1全都算出来再去求偏导
前向模式就是从h1对w的偏导一直往后计算
由于前向模式要保存的中间变量很多,占用内存很大,所以一般使用反向模式


如果网络结构一开始并不可以确定,就适合用动态计算图
而梯度计算的问题计算机程序会帮我们搞定
4.6 优化问题
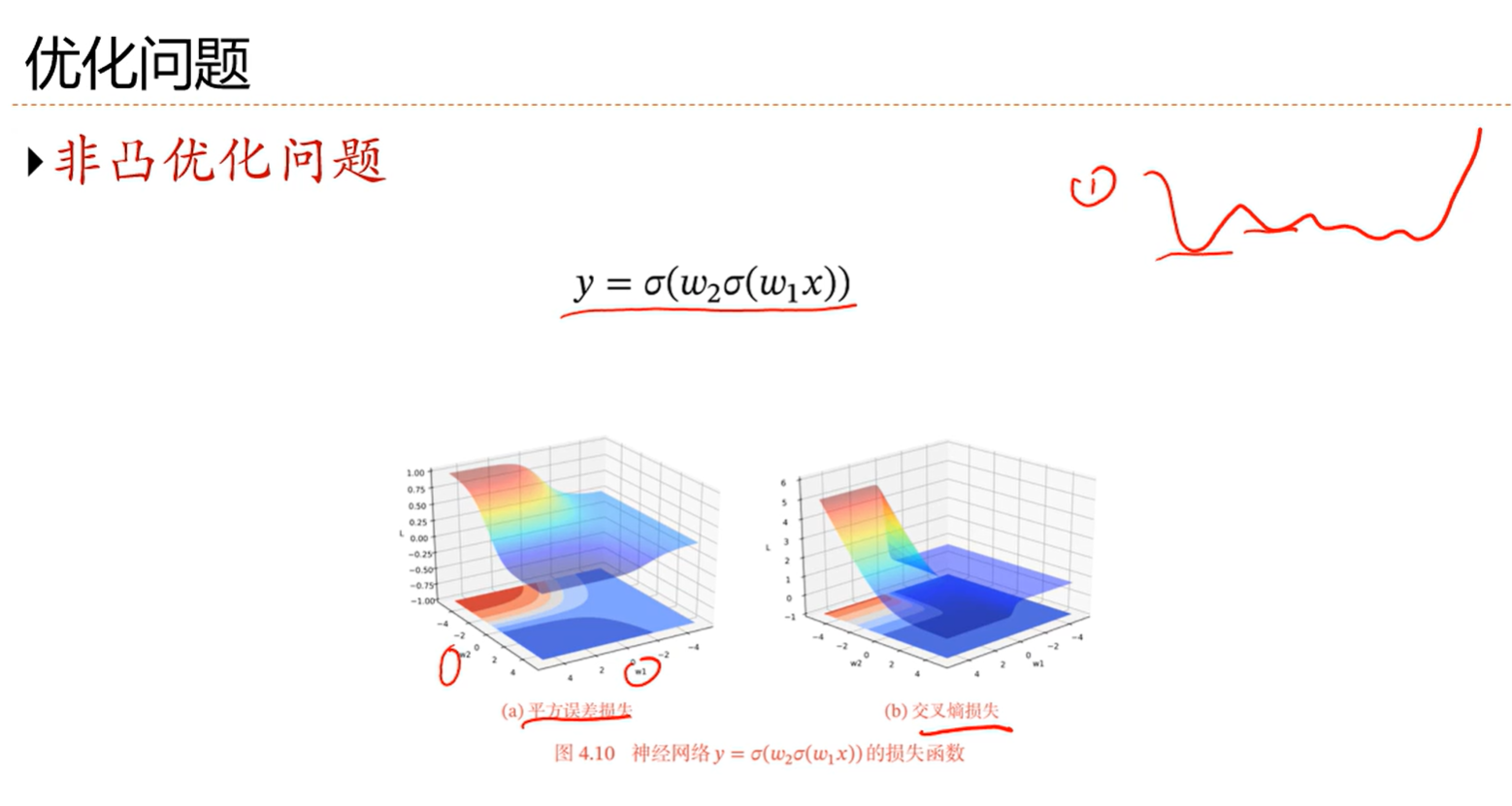
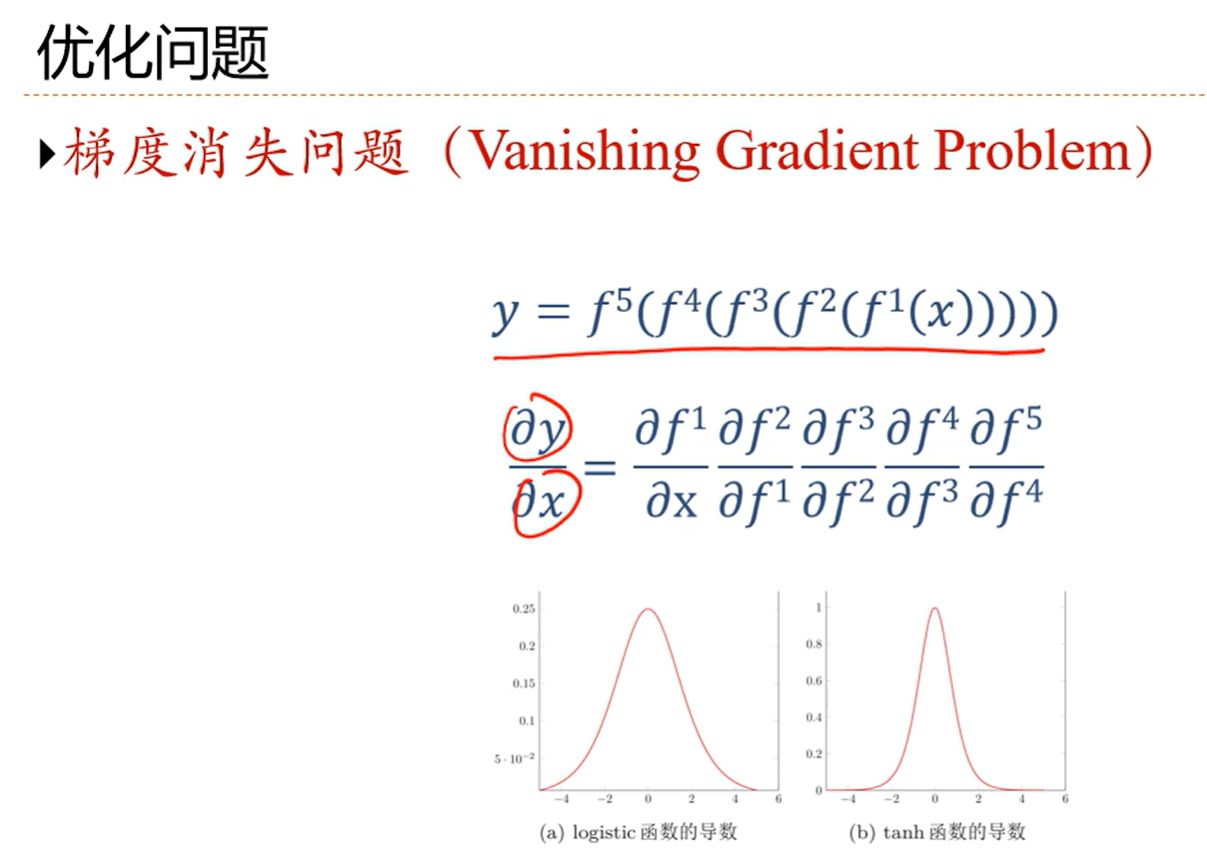
就是每一项都属于(0,1)这个区间,那么很多项连乘导致梯度趋近于0,这就是梯度消失问题
当网络很深的时候呢,那么后面的梯度就为0了,那么更新起来就很奋费劲,就很难学习
所以激活函数导数最好能在1附近,因为不管怎么连乘都还是1
用ReLU也是因为在其一端,它的梯度一直为1

参数过多,可能比训练集还要多,那很大可能导致过拟合,而且参数解释也很困难,我们不知道哪个参数更加重要