目录
倒排索引
为什么叫倒排索引:
在没有搜索引擎时,我们是直接输入一个网址,然后获取网站内容,这时我们的行为是:
document -> to -> words
通过文章,获取里面的单词,这是正向索引——forward index.
后来,我们希望能够输入一个单词,找到含有这个单词,或者和这个单词有关系的文章:
word -> to -> documents
于是我们把这种索引,成为inverted index,直译过来,应该叫「反向索引」,国内翻译成「倒排索引」,有点委婉了。
倒排索引的创建过程:
1.给文本分词
文本1:“我住在成都,他也住在成都”
文本2:“你住在上海”
分词器根据语法会将无关紧要的连接词去掉,文本分词出来:
文本1:我 成都 你 成都
文本2:你 上海
2.生成倒排索引
| 单词 | 频率 | 文档id | 倒排列表((DocID;TF;<POS>)) |
|---|---|---|---|
| 成都 | 2 | 1 | (1;1;<2>),(1;1;<3>) |
| 我 | 1 | 1 | (1;1;<1>) |
| 你 | 2 | 1,2 | (1;1;<3>),(2;1;<1>) |
DocID:文档id
TF:词汇出现频率
POS:在文档中的位置
lucene核心概念
倒排索引虽然实现了分词到文档之间的映射,实现了通过分词查找文档。但是分词分出来的单词是海量的,建立了倒排索引后还要考虑海量单词的存储查询问题。
term dictionary:
这种海量单词的查询最简单的能想到:二分查找。
将单词按序排列组成一个term dictionary,利用term dictionary来进行二分查找。

term index:
很明显term dictionary会很大,内存放不下,只有放在磁盘上。磁盘上访问速度很慢,所以还要考虑给term dictionary再加上一层类索引的结构。将部分词项抽出来构成目录树,这样可以知道词所在的大概位置,去那个起始位置做少量搜索即可。这棵树叫term index:

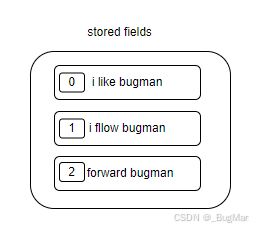
stored fields:
stored fields是拿来存储真实文档的结构,是个行式存储。
doc values:
前面的内容解决了倒排索引的实现问题和文档实体的实际存储问题。但倒排索引是解决了如何高效的通过词查找到文档,但是解决不了排序问题。比如文档有createtime字段,倒排索引起到的无非是根据某个值去找createtime是这个值的文档。要排序就要把所有文档都读出来然后去找这个createtime字段来排序,很明显太慢了。所以还要对排序进行优化,就是doc values。简单来说就是把文档里可能要排序排序的字段单独存在doc values中。
-
所有支持 Doc Values 的字段类型(如 keyword、long)默认启用。
-
text 字段默认禁用 Doc Values(需使用 fielddata)。
可以手动禁用doc value:
PUT /my_index
{
"mappings": {
"properties": {
"log_message": {
"type": "text",
"doc_values": false // 禁用 Doc Values
}
}
}
}
segment:
term dictionary、term index、stored files、doc values里面有好几个内容都是存在磁盘上的,为了实现高并发的写入,采用lsm tree的思想,将一套内容写在一个segment单元,当一个segment写满了再落磁盘。落盘的segment会进行合并,这些思想和lsm tree都是一样的。

lucene和ES
es的内核就是lucene,es是基于lucene内核的扩展。单个lucene和高并发高可用是不沾边的,要引入es的index、分片、集群等才能实现。每个index对应一个lucene:

单个index可能过大,于是可以将一个index拆成多个分片(shard),一个分片对应一个lucene:
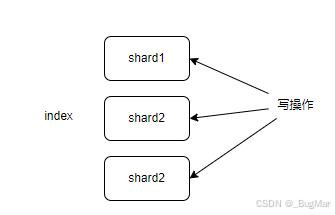
为了高可用,单个分片所在的Node挂了还能有备用,出现了分片机制,分片分为primary shard和replica shard:

replica shard的数据来自primary shard的同步,primary shard能读能写,replica shard只能读,primary shard挂了后replica shard会顶上去变为primary shard。

节点选举:
raft算法(每个Node节点都有raft,是去中心化的)