目录
我是准备用Ultralytics这个模型做图像分割,分享下我用labelme制作Ultralytics图像分割数据集的过程中踩过的雷和经验吧
一、Ultralytics要求的数据集的格式要求
用于训练YOLO 分割模型的数据集标签格式如下:
1、每幅图像一个文本文件:数据集中的每幅图像都有一个相应的文本文件,文件名与图像文件相同,扩展名为".txt"。
2、每个对象一行:文本文件中的每一行对应图像中的一个对象实例。
3、每行对象信息:每行包含对象实例的以下两个信息:
对象类别索引:代表对象类别的整数(如 0 代表人,1 代表汽车等)
对象边界坐标:遮罩区域周围的边界坐标,归一化后介于 0 和 1 之间
分割数据集txt文件中单行的格式如下:
<class-index> <x1> <y1> <x2> <y2> ... <xn> <yn>
<class-index> 是对象的类的索引,而 <x1> <y1> <x2> <y2> ... <xn> <yn> 是对象的分割掩码的边界坐标。坐标之间用空格隔开。
这里需要注意的两点(也是我踩雷的地方)是,
1、<x1> <y1> <x2> <y2> ... <xn> <yn>需要归一化
2、每个分段标签必须有一个 至少 3 个 xy 点: <class-index> <x1> <y1> <x2> <y2> <x3> <y3>
所以,
第一,你就要注意当你用labelme分割图像,产生的json文件转换成txt文件时,在json2txt代码中要有要有归一化处理。
第二,你用labelme分割图像至少要用到三个点,而且尽量不要用circle和rectangle分割
(因为这两个只有两个点的坐标,后面会介绍到,非要用的话,json2txt代码中应该要有求出第三点的坐标的算法,而且还要考虑怎么告诉Ultralytics这个分割形状是圆形或矩形,这里是我的思考,大家参考一下,对于这里有更好的看法或解决方法,望告知我)
Ultralytics具体格式要求看这里:实例分割数据集概述 -Ultralytics YOLO 文档
二、下载labelme
用anaconda创建自己的虚拟环境(想了解为什么创建点这里),记得下载python版本,因为我们后面要用到pip安装labelme,通常,较新版本的Python安装包中已经包含了pip,只需按照提示完成Python的安装即可。(pip是Python的包管理器,全称为“Pip Installs Packages”,用于安装、升级和卸载Python包及其依赖。)
创建命令:
conda create --name env_labelme python=3.9 示意图如下:

创建完毕后,进入以 env_labelme命名的环境的命令:
conda activate env_labelme示意图如下:

然后在该环境里下载labelme
下载命令:
pip install labelme示意图如下:
下载好labelme后,要用的时候命令行直接输入labelme就可以调用
示意图如下:

三、使用labelme分割图像
1、导入和保存图像
导入:在页眉点击“打开”,是打开一个图像;点击“打开目录”,可以打开你设置目录里的所有图像
分割好后保存图像:在页眉点击“文件”——“更改输出路径”,改成你要保存的路径,最好也要点击自动保存(批量分割的时候省事),还有取消勾选“同时保存图像数据”,我训练Ultralytics时候没用到这个。
2、分割图像
labelme提供了三种shapetype(形状),分别为circle、rectangle、polygon(多边形)【在页眉处点击编辑即可看到这三个选项】,下面说一下为什么不推荐训练Ultralytics模型时使用circle、rectangle的原因:
首先,用circle分割示意图如下,可以看到分割结束后,他只会提供圆心的坐标和圆边一点的坐标,不符合Ultralytics要求的数据格式。
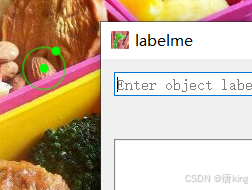
同理,用rectangle分割示意图如下,可以看到分割结束后,他只会提供矩形左上角的坐标和右上角的坐标,也不符合Ultralytics要求的数据格式。
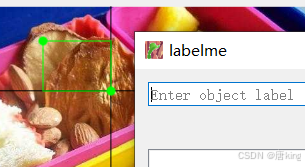
所以,建议大家最好使用polygon分割图像,而且最好三个点以上,并且在分割图像的边缘非直线的地方,标注的点尽可能多,不然最后训练出的效果可能会不太好(这点可能跟我们用的是多边形分割的原因,以直代曲,就要分割得细点,这也是我一开始踩雷的地方),分割示意图如下:
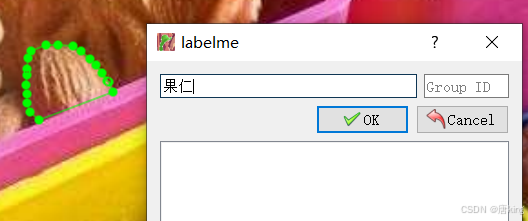
分割完后得到的文件是json文件(用记事本打开示意图如下),非 Ultralytics要求的数据格式,后面要通过json2txt代码,转换。


label即你分割对象的类型,points是你用labelme分割时标注的点的坐标,imageData取消勾选“同时保存图像数据”就会没有,不然会很冗长(这里是因为我没用到,大家视自己情况而定) ,imageHeight和imageWidth即对应整个图像的高和宽
四、json2txt
最后一步,把分割完后得到的文件是json文件转换成Ultralytics要求的数据格式(txt标签),这里是我花的时间最长(踩雷)的地方,json转换成txt,并不是说简单扒下别人代码就能用,首先,要好好看看你的json文件里的内容格式是不是我上面展示的json示意图一致(你是否是用labelme并且用多边形分割的)
直接附上代码
import json
import os
#将坐标归一化到 [0, 1] 范围。
def normalize_points(points, image_width, image_height):
"""Normalize polygon points to be in the range [0, 1]."""
return [(x / image_width, y / image_height) for x, y in points]
#将Labelme JSON标注转换为TXT格式
def labelme_json_to_txt(json_dir, txt_dir):
if not os.path.exists(txt_dir):
os.makedirs(txt_dir)
for filename in os.listdir(json_dir):
if filename.endswith('.json'):
json_file_path = os.path.join(json_dir, filename)
image_name = os.path.splitext(filename)[0]
txt_file_path = os.path.join(txt_dir, f'{image_name}.txt')
with open(json_file_path, 'r', encoding='utf-8') as json_file:
data = json.load(json_file)
shapes = data.get('shapes', [])
image_height = data.get('imageHeight', 0)
image_width = data.get('imageWidth', 0)
with open(txt_file_path, 'w', encoding='utf-8') as out_f:
for shape in shapes:
shape_type = shape.get('shape_type', '')
label = shape.get('label', '')
points = shape.get('points', [])
if shape['shape_type'] == "polygon":
normalized_points = normalize_points(points, image_width, image_height)
# Write the label (if present) followed by normalized points
out_f.write(f"{label} ")
out_f.write(" ".join(f"{x:.6f} {y:.6f}" for x, y in normalized_points))
out_f.write("\n")
else:
print(f'Warning: Unknown shape type "{shape_type}" found in {json_file_path}')
# 使用示例
json_directory = 'C:\\Users\Administrator\Desktop\自己制作的数据集\json'#你要修改的输入json地址
txt_output_directory = 'C:\\Users\Administrator\Desktop\自己制作的数据集\labels'#你要修改的txt保存的地址
labelme_json_to_txt(json_directory, txt_output_directory)这个代码修改输入输出,即可用。成功转换后示意图如下:

这里再附上我整理的数据集(mydataset)的格式,如下:
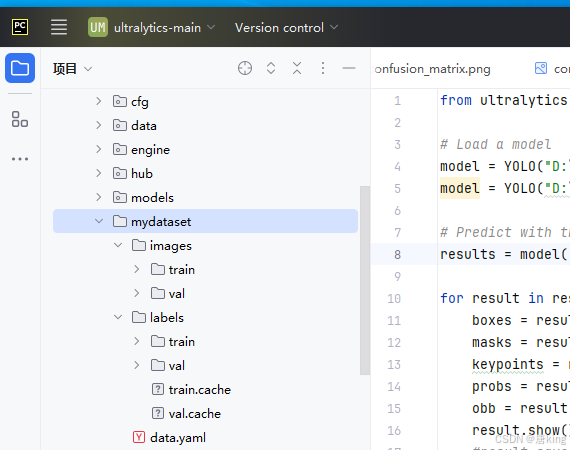
注:其实这里我刚开始不知道用circle、rectangle分割不符合Ultralytics的要求,在json2txt部分,还花蛮多时间弄了circle、rectangle这两种情况,篇幅有限,下篇博客再详细介绍这方面的内容,望大家关注点赞,小小支持一下,谢谢大家喽